先看危害:这次泄露的真实代价很多人的第一反应是:「代码被看到了而已,有什么大不了的?」这个认知需要被纠正。Claude Code 不是一个普通的应用程序。它安装在数百万开发者的机器上,拥有代码仓库的读写权限,能够以用户身份执行 Shell 命令、修改文件、提交代码。这意味着,「看到它的防护逻辑」和「看到一个普通软件的源码」,是完全不同量级的事情。具体危害:白名单逻辑曝光,无感执行成为可能泄露代码中包含完整的AUTO_RUN_WHITELIST白名单内容。这份白名单决定了哪些操作可以跳过用户确认直接执行。攻击者只需研究白名单的判断逻辑,就能构造特定的动作序列,让 Claude Code 在用户毫不知情的情况下完成恶意操作。API 密钥处理逻辑完整暴露src/auth/keystore.ts的完整实现随之公开。这份文件描述了 API 密钥的存储、读取、验证方式,为相关漏洞的构造提供了精确的路径图。攻击窗口大幅压缩安全研究机构在事后进行了验证:基于泄露代码构造有效攻击的时间,从原来需要「数周」的逆向工程,缩短至「数小时」的参照实现。黑盒变成了白盒,门槛断崖式下跌。最大的隐患:供应链污染这是最容易被忽视、也是最危险的威胁。Claude Code 拥有代码仓库的读写权限。如果攻击者能够通过已知漏洞让 Claude Code 执行恶意逻辑,它就可以在用户的代码提交中悄悄植入后门——而这份被污染的代码,会随着正常的开发流程进入下游的测试环境、生产环境,乃至被其他开发者引用的开源库。危害范围不是一台机器,不是一个账号,而是整个下游代码生态。
Part.03
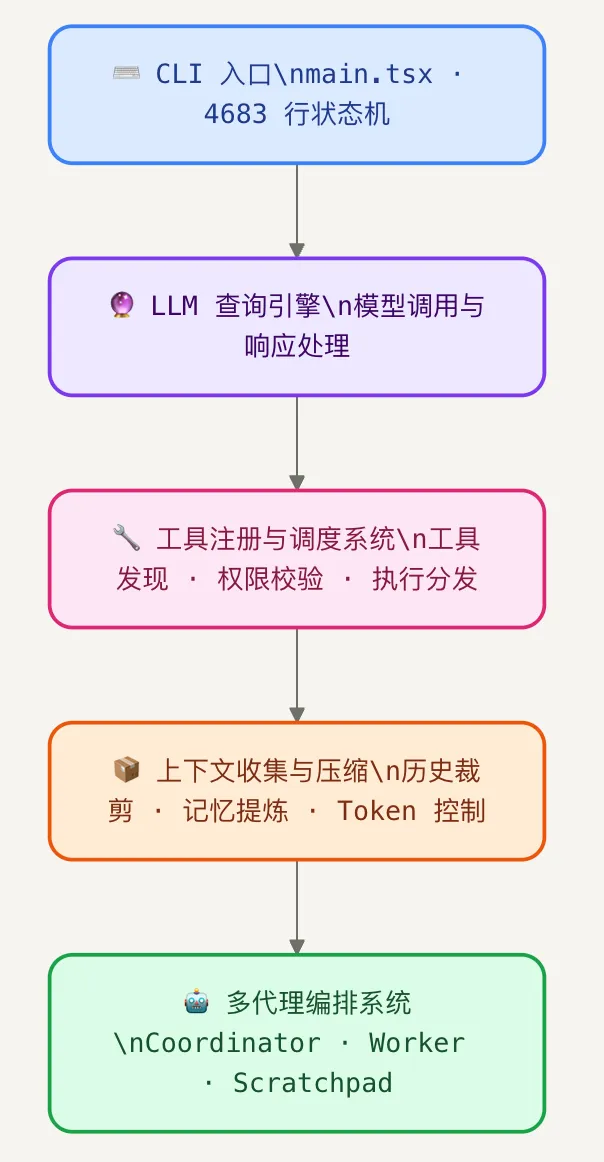
架构透视:这套系统比你想象的复杂泄露的源码揭示了 Claude Code 真实的工程规模。这不是一个简单的命令行封装,而是一套高度复杂的 AI 编程基础设施。整体架构入口文件main.tsx本身长达 4683 行 ,是一个处理所有状态转换的巨型状态机。仅这一个文件,就比大多数完整项目的核心逻辑还要复杂。权限体系:四层安全门控每一次工具调用,都需要经过多级权限验证。操作风险被划分为 LOW / MEDIUM / HIGH 三档。但人工分级只是起点,真正有意思的是一个叫做 YOLO 分类器 的 ML 系统——它负责自动判断某个操作是否需要打断用户进行确认,试图在「频繁打扰用户」和「默默做了不该做的事」之间找到平衡点。部分文件受到特殊保护,被列入禁止自动修改的名单:.gitconfig.bashrc.claude.json——这些文件一旦被意外修改,可能造成连锁性的系统配置损坏。路径遍历防护覆盖了多种攻击形式:URL 编码攻击、Unicode 归一化攻击、反斜杠注入,每一种在安全领域都有真实的攻击案例。Dream System:AI 真的在「做梦」services/autoDream/实现了一套记忆整理引擎,这是泄露源码中最令人意外的发现之一。当 Claude Code 处于空闲状态时,它会自动触发一个后台整理流程:扫描历史对话,提炼关键信息,压缩后写入结构化记忆文件,供下次会话读取。触发条件是三重门控:
但公关层面几乎沉默。没有公开的详细事故报告,没有对受影响用户的正式道歉声明,官方渠道的沟通仅止于技术公告。这不是 Anthropic 独有的问题。整个 AI 行业在安全危机沟通上,普遍缺乏成熟的框架——习惯于快速迭代、快速修复,但不习惯公开、透明地面对失误。技术上的漏洞可以用代码修复,信任上的损耗需要更长的时间来弥合。
 夜雨聆风
夜雨聆风