Claude Code源码被扒光,我替AI产品经理们整理了一份「免费竞品报告」
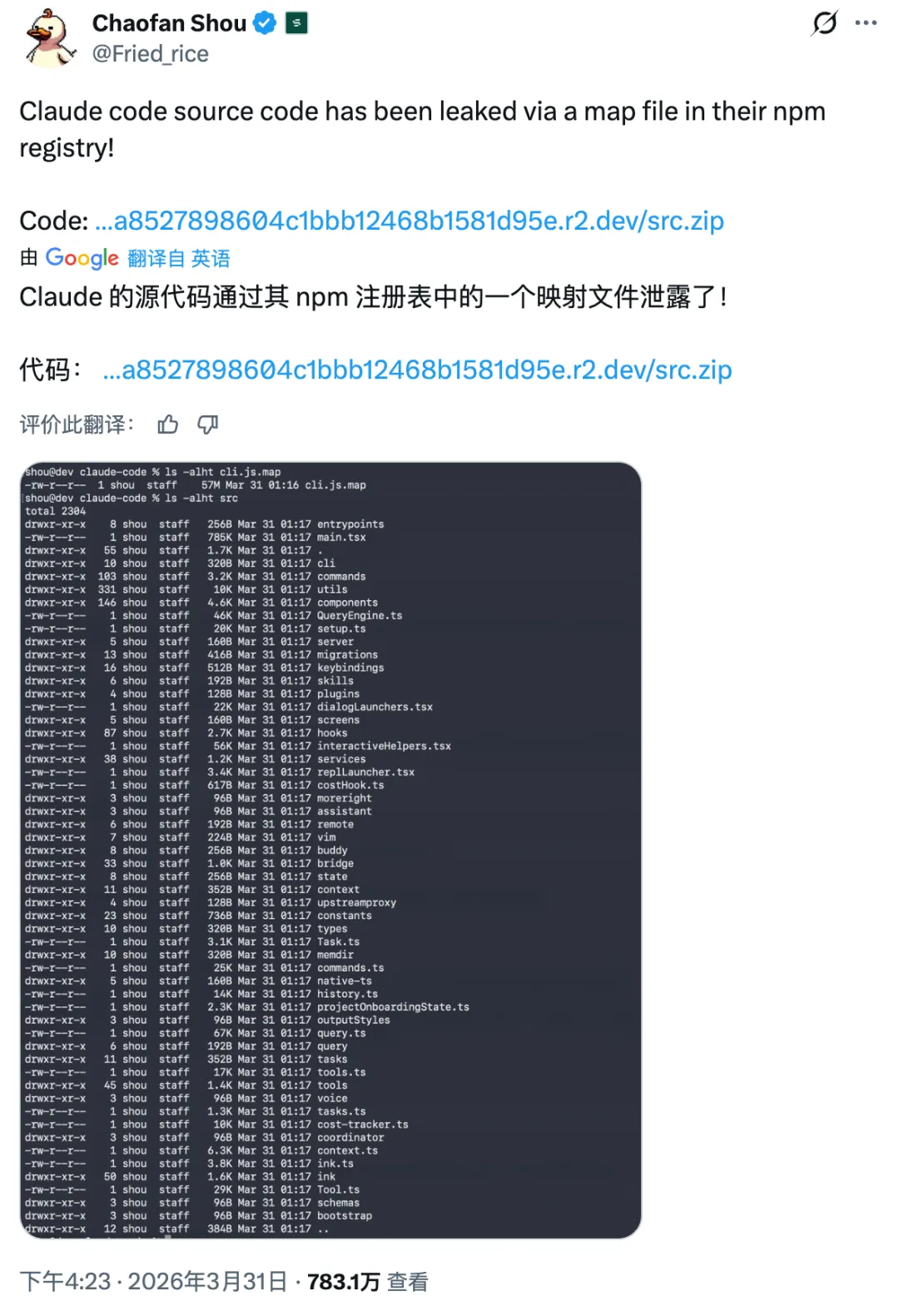
3月31日,愚人节前夜。一个59.8 MB 的调试文件,让全球AI开发者提前看到了Anthropic本不打算公开的产品路线图。
文件。Anthropic在向npm公共镜像库发布Claude Code v2.1.88时,把用于本地调试的source map文件一起打包进了生产版本。这个文件本质上是一个JSON,里面直接存储了1900个TypeScript源文件的完整原始内容,无需反编译,一行脚本就能还原。 51.2万行代码就这样全网裸奔。
一小时内,备份仓库涨到11,300 star和17,300 fork,fork数比star数还多—— 大家的第一反应不是围观,是先存一份。
值得玩味的是,这已经是Anthropic在5天内发生的第二次泄露。3月26日,CMS配置错误已经让近3000个内部资产公开可访问,包括代号Capybara的未发布模型草稿。同款配置错误,五天之内连犯两次。
但就是这场公关灾难,意外地给了所有AI产品经理一份价值连城的免费竞品报告。
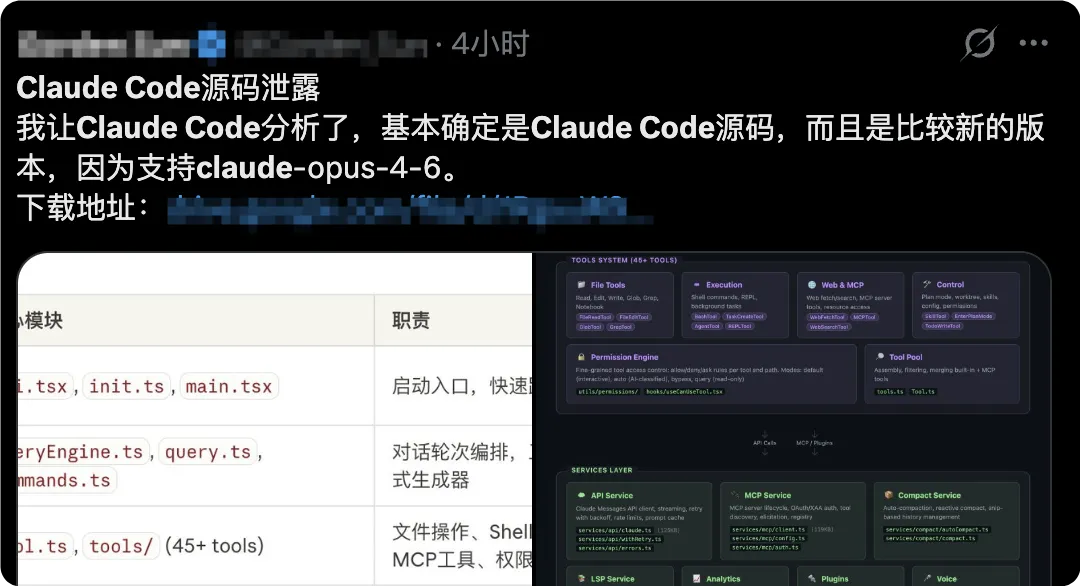
当我第一次看完泄露代码的分析汇总,脑子里蹦出的第一个词不是「泄露」,而是「路线图」。
把泄露的功能模块全部列出来,你会发现这不是一堆零散的功能点,而是 一套有完整内在逻辑的产品架构 。Anthropic正在悄悄构建的,是一个「数字员工生态」,而不只是一个更好用的编程工具。
-
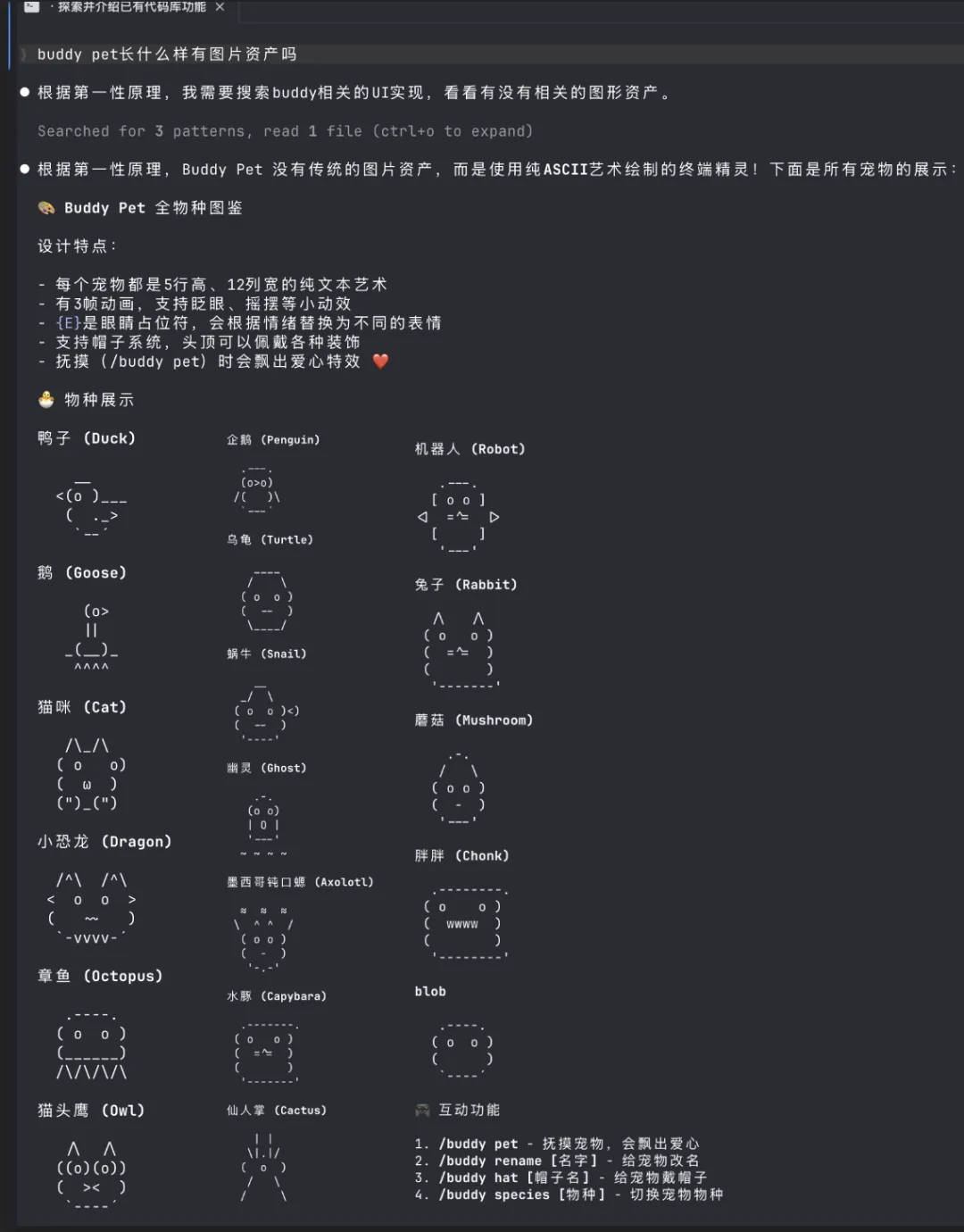
愚人节彩蛋:电子宠物Buddy 代码中发现一个代号Buddy的电子宠物系统,有18种物种和6种稀有度,每个宠物由用户ID生成。该功能计划于4月1日发布,可能是一个愚人节彩蛋。
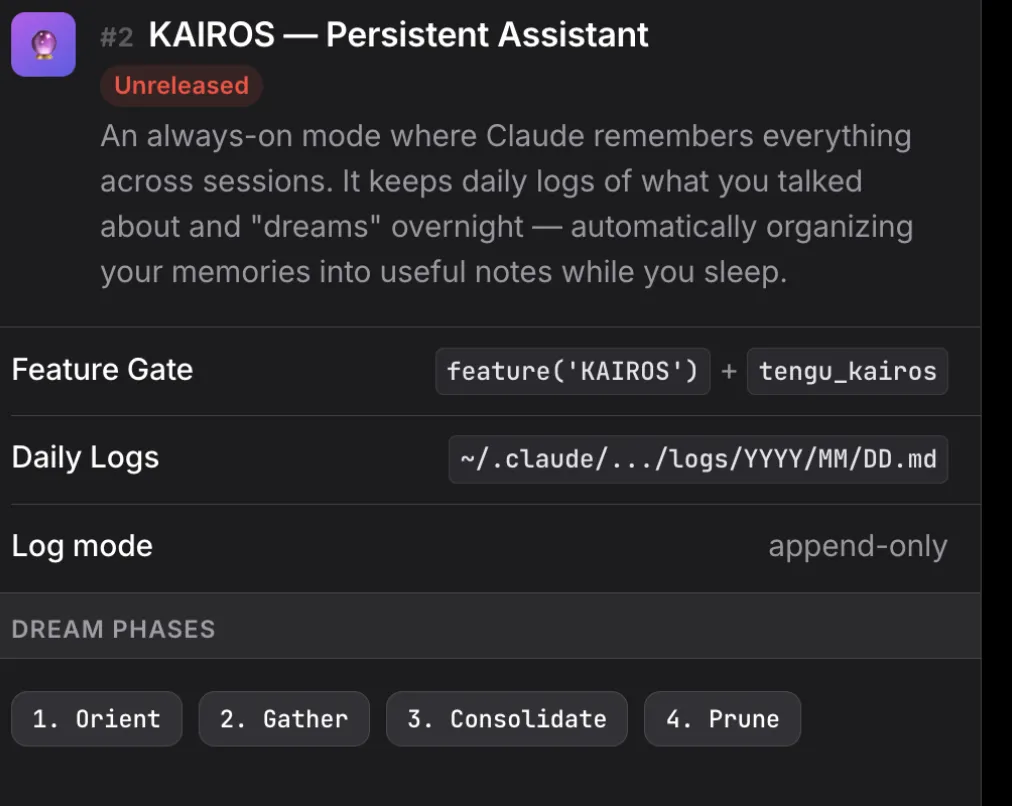
我们现在和所有大模型的交互模式,本质上都是「阅后即焚」——关掉对话窗口,一切从头来过。KAIROS想彻底颠覆这件事。
它被定义为 「Always-On Claude」 ,能在不同会话之间保持持续记忆,把用户的工作习惯、项目背景存储在私密目录里,并且有权限主动发起任务。它不是一个更大的上下文窗口,而是一个真正意义上「认识你」的助手。
更让人眼前一亮的是配套的 AutoDream(夜间做梦)机制 :
产品启示: 把一个冷冰冰的工程问题——上下文窗口压缩与检索——包装成充满生命感的产品隐喻,这本身就是一种极其高明的产品叙事能力。AI白天帮你写代码,深夜你睡着后,它独自在服务器里「做梦」来更懂你。这个意象,比任何一份产品说明书都有感染力。
ULTRAPLAN:让AI从「执行者」变成「规划者」
这个模块会在云端启动一个运行Opus 4.6的远程会话,给它最多30分钟的思考时间,来完成复杂项目的全局规划——包括架构设计、可行性分析、步骤拆解。本地终端每3秒轮询一次结果,还有浏览器界面实时查看和审批方案。
Claude不再只是给几行代码建议,而是能接管整个系统架构的构思和推演。
Coordinator模式:多Agent编排的终极形态
一个主Claude实例作为调度器,同时管理多个「工人Agent」并行处理复杂任务:
|
阶段
|
功能描述
|
|
Research
|
并行调查代码库
|
|
Synthesis
|
汇总发现制定方案
|
|
Implementation
|
按方案执行
|
|
Verification
|
验证是否生效
|
>调度器的提示词里有一条规则写得格外清醒: 「不要说『根据你的发现』,去读实际的发现,然后精确地说明该做什么。」
把这四个模块拼在一起,你看到的是一套完整的产品战略图谱:KAIROS负责持续记忆,ULTRAPLAN负责复杂规划,Coordinator负责并行执行。当其他公司还在卷模型参数、卷多模态效果时,Anthropic已经在系统底层悄悄搭建一套完整的 「数字员工基础设施」 。
这不是功能的堆砌,而是一套有内在逻辑的产品架构,指向同一个终极目标:让AI从「工具」进化为「同事」。
技术架构的背后,是产品决策的具体体现。作为有程序员背景的产品经理,我从这51.2万行代码里读到的,不只是功能实现,还有Anthropic在面对关键产品取舍时的答案。
Claude Code的每次工具调用,无论是执行Shell命令还是读写文件,都要先通过 六级权限验证系统 ,验证通过后还要经过四层决策管道,逐层检查权限和执行分析,最后才能真正执行。
• default:逐次询问用户• auto:ML分类器自动决策 • bypass:跳过检查• yolo:拒绝所有
产品思考: 这套设计的背后,是Anthropic对「AI自主性边界」的深度思考。给AI足够的能力,但在关键节点保留人的控制权。六级验证不是在限制AI,而是在建立用户信任。在AI自主性越来越强的今天, 「让用户感到安全」本身就是一个核心产品价值 ,而不只是一个合规要求。
Prompt缓存的分层设计:成本、速度、灵活性的三角取舍
这个设计乍看是纯技术优化,但背后是一个明确的产品取舍:哪些上下文是所有用户共享的,哪些是用户个性化的? 这条边界划在哪里,直接决定了产品的 成本结构 和响应速度。
还有一个细节值得单独说:代码里有一个函数叫。从命名就能看出来,有人在这上面踩过坑,然后用这个带「危险」前缀的命名方式,给所有后来的工程师留下了一个永久性的警告。这是工程文化在代码层面的具体体现—— 踩过的坑,要让所有人都看见。
DANGEROUS_uncachedSystemPromptSection()
代码底层的遥测系统会追踪用户是否在终端爆粗口(匹配、等关键词),以及连续输入的频率。不用AI做情感分析,用正则表达式匹配关键词。 简单粗暴,但直接有效。
这个设计选择很有意思。Anthropic完全有能力用更复杂的情感分析模型来做这件事,但他们选择了最简单的方案。这背后的产品逻辑是:你不需要精确测量用户的情绪,你只需要捕捉那些强烈的负面信号。用户在终端骂人,或者疯狂输入continue,这两个行为已经足够清晰地告诉你: 用户很沮丧,产品出了问题。
在所有泄露的功能中,争议最大的不是KAIROS,也不是ULTRAPLAN,而是一个叫 Undercover Mode(卧底模式) 的功能。
当系统检测到使用者是Anthropic内部员工,且正在操作公开的 GitHub 仓库时,这个模式会自动激活。
很多开发者看到这里感到不舒服,但我觉得这个功能触碰到的,是一个AI产品设计中至今没有定论的根本性问题:
当AI代替人类在开源社区贡献代码时, 透明度 和归属权的边界在哪里?
这不是Anthropic一家公司的问题。随着AI辅助编程越来越普及,这个问题迟早会落到每一个AI产品经理的决策桌上:
-
你的产品是否需要明确告知用户,哪些内容是AI生成的?
-
当AI生成的代码被合并进一个开源项目,这段代码的「作者」是谁?
Undercover Mode的存在,说明Anthropic已经在内部思考并做出了自己的选择。但这个选择是否正确,是否应该被公开讨论, 这才是真正值得产品圈深入探讨的问题。
抛开产品层面的洞察,这次泄露本身也是一个值得认真对待的流程案例。
Anthropic是一家把「AI安全」写进公司使命的企业,却在5天内连续发生两次因「配置错误」导致的重大泄露,且第二次是第一次同款错误的重犯。 这不是运气问题,这是流程问题。
一个成熟的发布流水线,理应在CI/CD环节加入自动化检查:
更令人难以理解的是,2025年2月Claude Code首发时就曾因同样的原因泄露过一次source map, 这次是同款错误的第二次重犯。
但这里有一个更深的问题值得追问: 在一个AI Agent已经能自主写代码、提交commit、管理发布流程的时代,谁来负责最终的质量把关?
当构建流程本身被AI参与管理时,这个问题变得格外微妙:
Anthropic的工程师们正在用Claude Code写Claude Code
在这个闭环里,一个被默认开启的配置项,可能就这样从来没有人真正检查过。
这是每一个在推进「AI辅助研发」的团队都需要认真回答的问题:当AI深度参与你的研发流程,你的质量保障体系是否需要同步升级?
这份意外的「竞品报告」,除了信息价值,还有三个可以直接转化为行动的启示。
-
KAIROS、Coordinator、ULTRAPLAN所代表的方向—— 持续记忆、主动协作、多Agent编排 ——就是AI产品在未来12~18个月内的核心演进方向。
如果你现在负责的AI产品还停留在「单轮对话」和「被动响应」的阶段,这份路线图应该让你感到紧迫:
-
重新审视你的AI产品中「用户控制权」的设计Claude Code的六级权限验证体系告诉我们,在AI自主性越来越强的今天, 「让用户感到安全」不是一个锦上添花的体验优化,而是一个核心产品价值。用户愿意给AI更多权限的前提,是他们相信自己随时可以收回这些权限。这个信任的建立,需要在产品设计层面认真对待。
-
这次泄露最大的价值,是让我们看到了一家顶级AI公司如何在工程层面落地产品理念:
每一个技术决策背后都有明确的产品意图。 在AI时代,能从代码里读出产品逻辑,是AI 产品经理 的一项新的 核心竞争力 。
Anthropic用一种最不体面的方式,意外地向全世界展示了他们真正在做的事有多前卫。在AI行业充斥着PPT画饼和期货发布的今天,这份「被迫透明」反而成了一种意外的公信力。
但对产品经理来说,这次泄露的价值不在于代码本身,而在于它揭示的产品哲学:
真正好的AI产品,不是在卷功能,而是在重新定义人与AI的协作关系。
从工具,到助手,到同事——这条路,Anthropic已经在代码里走了很远。而现在,这条路的地图,意外地成为了我们所有人的参考。
 夜雨聆风
夜雨聆风