 夜雨聆风
夜雨聆风





(超级详细)Claude Code源码泄露:51万行TypeScript里的工业级AI Agent架构全解析
这不是一篇”泄露了什么”的清单。这是一份从512,000行生产代码中提取的AI Agent架构设计教科书。
3月31日凌晨00:21 UTC,Anthropic发布了Claude Code v2.1.88到npm。
三小时后,全世界的开发者已经看完了它的全部源码。
原因很蠢——Bun运行时默认生成source map,.npmignore里漏了一行*.map。一个59.8MB的cli.js.map跟着npm包一起发出去了。这个文件里嵌着完整的TypeScript源码引用,顺藤摸瓜还能找到Anthropic Cloudflare R2存储桶上的zip归档。
安全研究员Chaofan Shou凌晨4:23 AM ET发现并公开。三小时窗口期内代码被全球镜像。韩国开发者Sigrid Jin的Python clean-room重写claw-code两小时突破5万star。Anthropic发DMCA删原始代码,但clean-room重写不侵犯版权,删不掉。
512,000行TypeScript。约1,900个文件。40+工具。44个feature flag。20+未发布功能。
有意思的是,这不是Anthropic那周的唯一事故——几天前他们刚不小心公开了近3000个文件,包括一篇泄露了下一代模型代号”Capybara”的博客草稿。

▲ 一个.npmignore的疏漏,引发了AI Agent领域最大规模的非自愿开源
网上已经有大量”Claude Code泄露了什么”的文章——44个feature flag、KAIROS模式、Buddy宠物系统。这些是八卦,不是架构分析。
这篇文章要做的是另一件事:以高级架构师的视角,逐层拆解Claude Code的工程设计。 每一个模块为什么长成这样?每一个设计决策在解决什么问题?哪些模式值得整个行业学习?哪些是特定于Anthropic生态的特殊解?
我们从最核心的模块开始。
一、QueryEngine:46000行的心脏
如果Claude Code是一个生物体,QueryEngine就是它的心脏。
这个模块大约46,000行TypeScript(加上关联的query.ts),是整个系统的核心循环。所有对话、所有工具调用、所有上下文管理,都经过它。
1.1 核心循环:异步生成器状态机
QueryEngine的核心是一个submitMessage()方法,驱动一个异步生成器循环:
用户输入消息
→ 组装系统提示词(9层动态装配)
→ 调用LLM API(流式输出)
→ yield tokens给前端渲染
→ 如果输出包含tool_use:
→ 权限检查
→ 执行工具
→ 将tool_result追加到消息历史
→ 回到"调用LLM API"继续循环
→ 如果输出是纯文本:结束本轮这个循环有几个关键的设计特征。
第一,它是单线程的。 不是多Agent并行处理消息,而是一个master loop顺序处理每一个事件。Claude Code的创始人Boris Cherny在播客里明确说过这是一个”single-threaded master loop”。这个选择很反直觉——为什么不用并行?因为LLM的输出是流式的、有状态的,工具调用之间可能有依赖关系(上一步的输出是下一步的输入)。单线程循环保证了因果顺序的正确性,代价是吞吐量。
第二,它维护一个mutableMessages数组作为唯一的状态真相来源(single source of truth)。 所有对话历史、工具调用、系统消息都在这个数组里。这意味着任何时候你可以从这个数组完整重建当前的对话状态。
第三,每次API调用之前会创建文件系统快照。 这样即使进程在API调用中途被杀掉(Ctrl+C、终端关闭、机器重启),下次启动时可以从快照恢复到最近的一致状态。
1.2 九层系统提示词装配
大多数人以为系统提示词就是一段静态文本。Claude Code的系统提示词是一条九层动态装配流水线。
Layer 1: Base System Prompt (静态基础指令,可缓存)
Layer 2: Environment Info (OS、shell、日期)
Layer 3: systemContext (git status快照)
Layer 4: userContext (CLAUDE.md文件内容)
Layer 5: Memory Files (MEMORY.md索引+按需加载)
Layer 6: Coordinator Context (多Agent协作指令,可选)
Layer 7: Custom/Append Prompts (用户自定义指令)
Layer 8: Skills Context (已加载的技能定义)
Layer 9: SYSTEM_PROMPT_DYNAMIC_BOUNDARY ← 缓存边界标记第9层是全文最关键的设计之一。
Anthropic的API支持prompt caching——如果系统提示词的前N个token跟上一次请求完全一致(字节级匹配),API可以跳过重新编码这些token,直接复用缓存。这在一个几万token的系统提示词上,可以省掉可观的计算成本和延迟。
SYSTEM_PROMPT_DYNAMIC_BOUNDARY就是一条人为插入的分界线:线以上的内容在同一个session内基本不变(基础指令、环境信息、CLAUDE.md、记忆文件),可以被缓存;线以下的内容每次请求都可能不同(当前对话上下文),不缓存。
为了最大化缓存命中率,源码里还做了几件额外的事:
– 工具列表按字母顺序排序——确保即使工具集没变,字节顺序也完全一致
– 子Agent使用model: 'inherit'——继承父Agent的模型选择,避免模型切换导致的缓存失效
– 显式标记DANGEROUS_uncachedSystemPromptSection()——任何放在缓存边界以下的动态内容都必须通过这个方法声明,防止无意间污染缓存区
– Microcompact模块里有一个CacheEditsBlock——压缩对话历史时,刻意保持缓存区内容不被修改
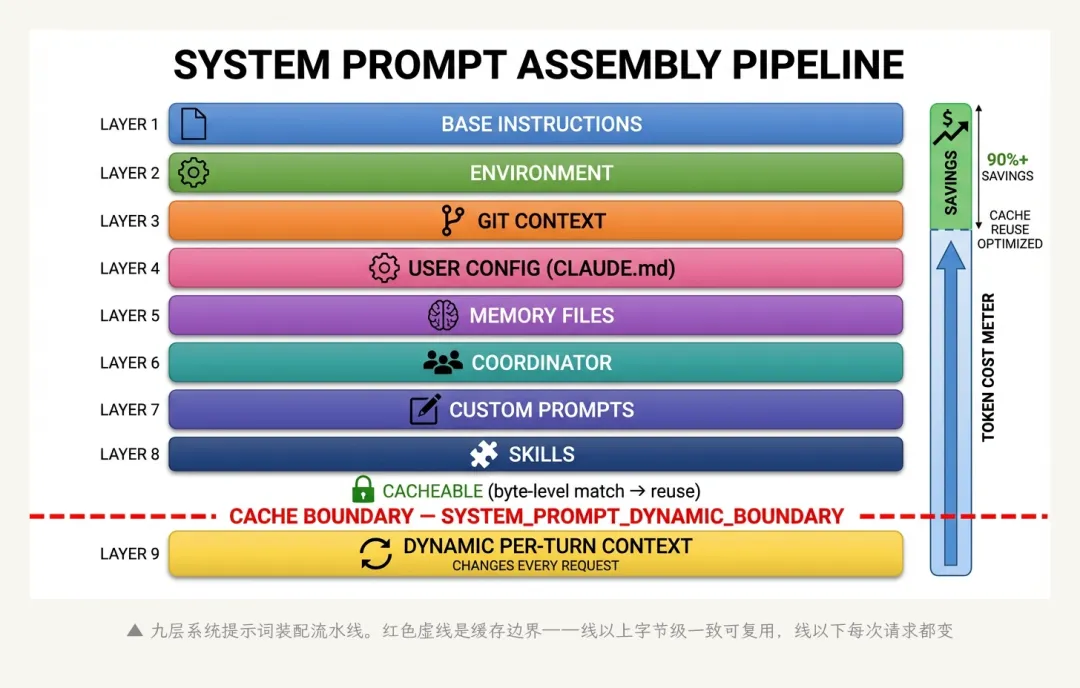
▲ 九层系统提示词装配流水线。红色虚线是缓存边界——线以上可复用,线以下每次都变
从源码的细节密度可以看出,prompt caching不是一个”有就好”的优化——它是Claude Code经济模型的基石。一个缓存命中和一个缓存未命中的成本差距可以是数倍。这解释了为什么这么多看似不相关的设计决策(工具排序、模型继承、边界标记)最终都指向同一个目标:保护缓存。
1.3 错误恢复与韧性
query.ts里的主循环是一个while(true)状态机,具备相当完善的错误恢复能力:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
同时维护两个计数器:
– 最大连续输出token恢复尝试:3次——如果模型连续3次输出不完整就停止
– 最大连续压缩失败:3次——这个数字的来源很有意思:源码注释里提到,曾经有1,279个session连续压缩失败超过50次,每天全局浪费约250,000次API调用。设为3是那次修复的结果
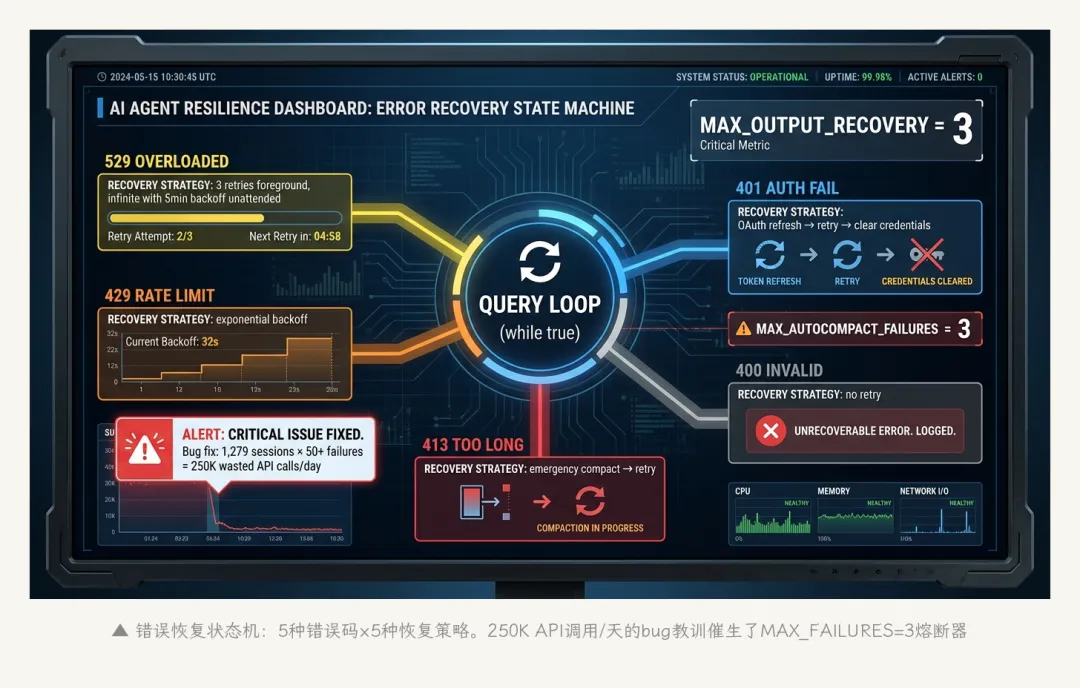
▲ 错误恢复状态机:5种错误码×5种恢复策略。250K API调用/天的bug教训催生了熔断器
这个250K的数字值得多说两句。它意味着在修复之前,Claude Code每天因为压缩失败重试而白白调用了25万次API。每次调用都要消耗token、都要付费、都要占用服务端资源——全是浪费。这是一个典型的”小bug大影响”案例:单个session里连续失败50次可能不会引起注意,但乘以全球数十万活跃用户,就变成了每天25万次的系统性浪费。
修复方案也很朴素——加一个熔断器:连续失败3次就放弃自动压缩,fallback到reactive compact或者直接报错。不是什么精妙的算法,就是一个if (failures > 3) break。但就这一行代码,每天省了25万次API调用。
有时候最有价值的代码不是最复杂的那行,而是”在这里加一个3″。
1.4 Prompt Cache的14个失效向量
源码里有一个文件promptCacheBreakDetection.ts,追踪了14种可能导致prompt cache失效的向量。这是一个很少被其他分析文章提到的细节,但它揭示了缓存优化的真实复杂度。
prompt cache要求字节级一致——前缀有任何一个字符不同,缓存就失效。那么哪些事情会改变前缀呢?
– 工具列表发生变化(加载了新工具或卸载了旧工具)
– 权限模式切换(从default切到plan模式)
– CLAUDE.md文件被修改
– 记忆文件更新
– 技能加载/卸载
– MCP服务器连接状态变化
– 协调模式开启/关闭
– ……等等,共14种
为了减少不必要的缓存失效,源码使用了一个叫“sticky latch”的机制——某些状态切换(比如权限模式从default到plan再切回default)不会立即反映到系统提示词中,而是在下一次”自然断点”(比如用户发新消息时)才更新。这样可以避免”改了一下设置又改回来”导致中间那次的缓存白白失效。
1.5 启动优化:16阶段初始化
Claude Code的启动过程被拆成16个阶段的init()函数,并行化做到了极致:
– macOS MDM策略检查(约135ms)和keychain读取(约65ms)并行执行
– 认证token预取与环境探测并行
– 采样分析:内部用户100%采样,外部用户0.5%采样,未被采样的用户零开销
– 快速路径:--version、--dump-system-prompt、mcp serve等命令直接短路,不走完整初始化
二、工具系统:29000行的军火库
Claude Code有40多个工具。但”工具”这个词容易让人低估它的复杂度——这不是一个”函数调用”的简单封装。整个工具系统约29,000行TypeScript,包含注册、发现、权限、执行、审计的完整生命周期。
2.1 工具接口
所有工具遵循统一的泛型接口:
interface Tool<Input, Output, Progress> {
name: string
description(): string
inputSchema: ZodSchema<Input> // Zod v4校验
call(input: Input, context: ToolContext): Promise<ToolResult<Output>>
checkPermissions(input: Input): PermissionResult
isConcurrencySafe(input: Input): boolean
}isConcurrencySafe这个方法很值得注意——它告诉系统这个工具是否可以安全地并行执行。比如两个Read操作可以并行(只读),但两个Edit操作可能不行(写同一个文件会冲突)。
2.2 延迟加载与prompt token预算
约60个工具分布在45个文件中,但并不是全部都会加载到系统提示词里。
18个工具是延迟加载的——它们只有在被ToolSearchTool发现后才加入上下文。为什么?因为每个工具的定义(名称、描述、参数schema)都要占用系统提示词的token。60个工具全部加载,系统提示词会超过200K token。
所以Claude Code做了一个工具版的”按需加载”:常用工具常驻(Read、Write、Edit、Bash、Grep等),不常用的工具(LSP、NotebookEdit、CronCreate等)只在需要时才通过ToolSearchTool动态加载。
这又是一个经济性驱动的设计——控制prompt token就是控制成本。
2.3 工具执行的完整管线
一次工具调用从LLM输出到最终执行,要经过这样一条管线:
LLM输出tool_use block
→ 解析参数(Zod schema校验)
→ Hook: PreToolUse(可拦截、修改输入、阻止执行)
→ 权限检查(5种模式 × 6层管线)
→ 沙箱环境隔离
→ 执行工具
→ Hook: PostToolUse(审计、通知、修改输出)
→ 结果大小裁剪
→ 返回tool_result给LLM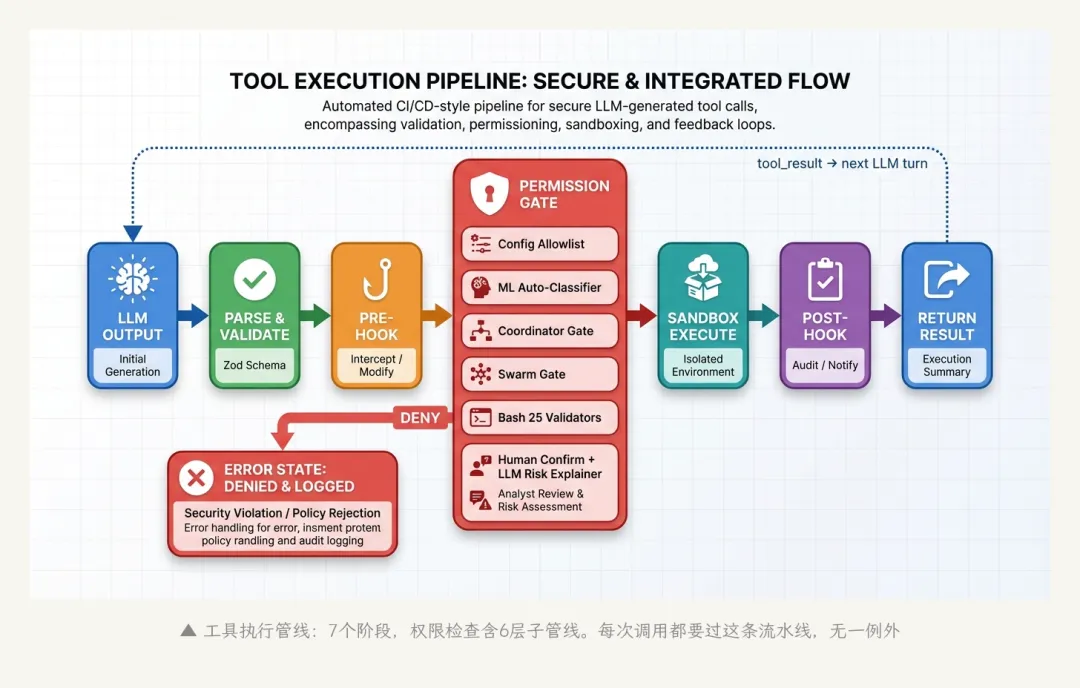
▲ 工具执行管线:7个阶段,权限检查含6层子管线。每次调用都要过这条流水线
PreToolUse和PostToolUse Hook是一个很有想法的设计——它允许外部代码在工具执行前后注入逻辑,而不需要修改工具本身。比如你可以写一个Hook,在所有Bash命令执行前自动加上set -e(遇到错误立即停止)。Hook可以在项目设置里定义,也可以在Agent配置里注册。
2.4 结果大小控制
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
BashTool的溢出处理很巧妙——如果一个命令输出了10MB的文本,不会全部塞进对话上下文(那会爆token预算),而是存到磁盘文件里,只在上下文里放一个简短的预览和文件路径。Agent如果需要完整内容,可以用FileReadTool去读。
2.5 BashTool安全:25个校验器
Bash是最危险的工具——它可以执行任意shell命令。Claude Code在bashSecurity.ts里堆了25个以上的安全校验器,串行执行(第2308行到第2378行)。
但源码也暴露了一个微妙的架构问题:Early-Allow短路。
某些校验器(比如validateGitCommit)返回allow时,会直接短路整个校验链——后续所有校验器都不会执行。这意味着如果一个命令被validateGitCommit判定为”安全的git操作”,validateRedirections(检查重定向攻击)就永远不会跑到。
源码注释里也提到了另一个问题:三个不同的shell解析器处理同一个命令时的行为不一致。shell-quote库把\r(回车)当作单词分隔符(因为JavaScript的\s包含\r),但bash的IFS不包含\r——这是一个已知的解析差异(parser differential),理论上可以用来构造绕过特定校验器的命令。
这不是在说Claude Code不安全——25个校验器已经远超行业水准。但它展示了一个深层问题:安全校验链的复杂度本身可以成为安全风险的来源。当你有25个校验器、3个解析器、多个短路路径的时候,”所有路径是否都被正确覆盖”本身就成了一个难以完全验证的问题。
三、多Agent架构:特种作战小队
Claude Code不是一个通用Agent在干所有活。它是一个角色明确的多Agent协作系统。
3.1 四种专业化角色
|
|
|
|
|---|---|---|
| Explore Agent |
|
|
| Plan Agent |
|
|
| Verification Agent |
|
|
| General Purpose Agent |
|
|
每个角色拿到不同的系统提示词和不同的工具集。Explore Agent的工具池里根本没有Write工具——不是”不建议用”,是物理上不存在。
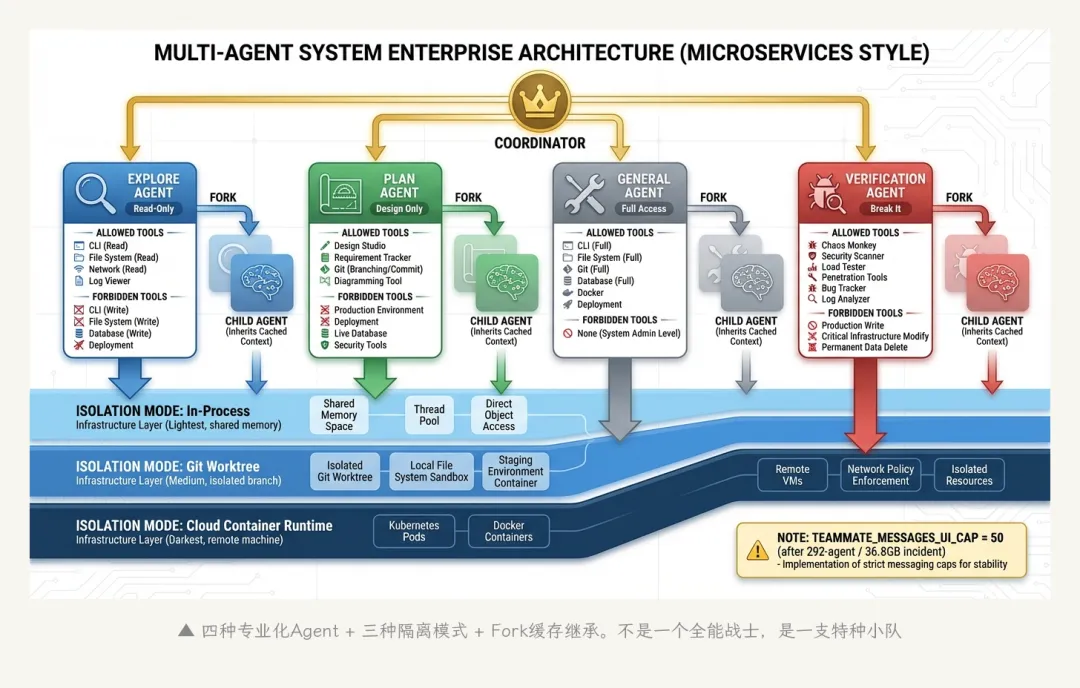
▲ 四种专业化Agent + 三种隔离模式。不是全能战士,是特种小队
这个设计解决的问题是角色混淆(role confusion)——在一个什么都能做的Agent里,模型有时候会”手痒”,在不该修改代码的上下文里修改代码。把工具物理移除,比在提示词里说”请不要修改”有效得多。
3.2 三种隔离模式
|
|
|
|
|---|---|---|
| InProcessTeammate | AsyncLocalStorage
|
|
| Worktree | EnterWorktreeTool
ExitWorktreeTool(独立git分支) |
|
| Remote (CCR) |
|
|
Worktree模式特别有意思——当Agent需要并行修改多个文件时,它可以创建一个git worktree(独立的工作目录和分支),在里面修改而不影响主分支。修改完成后合并回来。这跟人类开发者的”在feature branch上开发”是完全一样的工作流。
3.3 Fork机制:缓存经济学
当一个General Purpose Agent需要”停下来想想”(调用Plan Agent),有两条路:
Fresh路径:创建一个全新的Agent,只传递任务描述。好处是干净,坏处是Plan Agent需要从头读一遍代码和对话历史——这可能意味着几万token的重复消耗。
Fork路径:子Agent直接继承父Agent的缓存上下文。因为父Agent已经把相关代码读进了上下文并且触发了prompt cache,子Agent可以直接复用这个缓存——不需要重新读、重新编码、重新付费。
fork路径的经济效益很显著。但它有一个代价:父子Agent的系统提示词必须高度一致(否则缓存失效)。这就是为什么源码里特意保持每种Agent的工具集稳定——不是为了功能考虑,是为了缓存命中率。
3.4 Coordinator模式:Agent编队
当CLAUDE_CODE_COORDINATOR_MODE=1时,Claude Code变成一个多阶段编排器:
1. Research阶段:多个worker Agent并行调查代码库
2. Synthesis阶段:Coordinator读取所有调查结果,制定规格说明
3. Implementation阶段:Worker并行执行修改
4. Verification阶段:并发运行测试验证
Worker运行在tmux/iTerm2的独立窗格里,实时显示状态。Agent之间通过两种机制通信:
– Mailbox协议:异步消息队列,结构化消息(shutdown_request、plan_approval_response等)
– Scratchpad目录:共享文件系统,用于持久化跨Worker的知识(但这个功能还藏在tengu_scratch feature flag后面)
一个有意思的约束:TEAMMATE_MESSAGES_UI_CAP = 50。这个上限的来历是一次线上事故——之前没有上限,某次运行产生了292个Agent,内存飙到36.8GB。
四、上下文压缩:四级瀑布
LLM的上下文窗口是有限的——即使Claude有200K token的窗口,一个复杂的编程任务很容易就填满了。Claude Code设计了一套四级压缩瀑布来管理这个问题。
4.1 四级级联
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
是 |
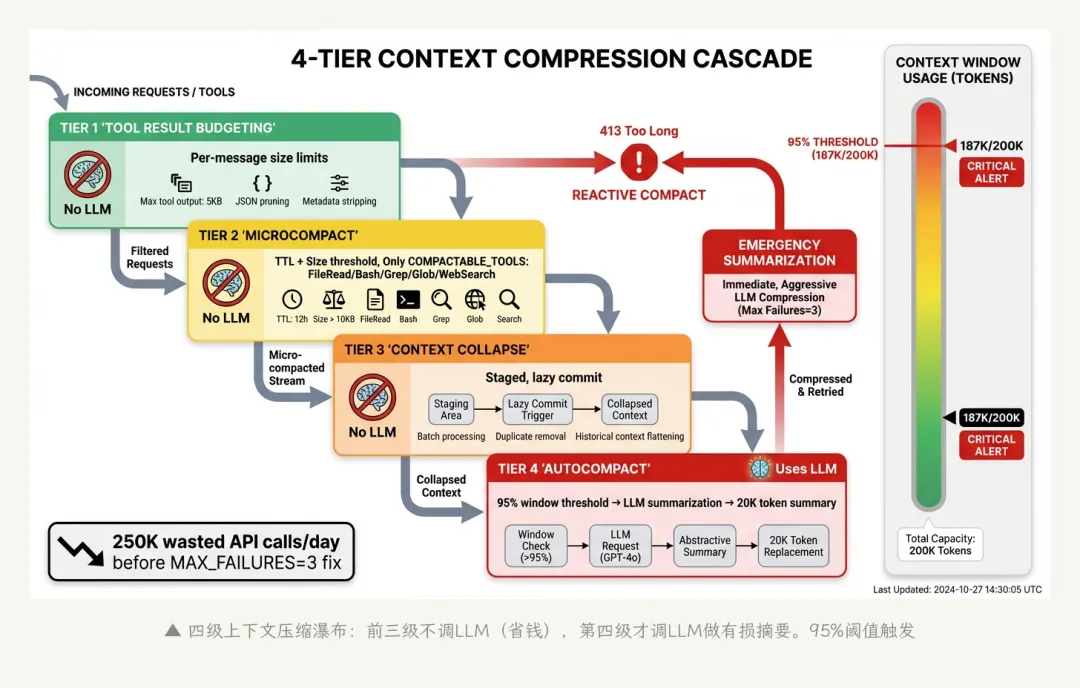
▲ 四级压缩瀑布:前三级不调LLM(省钱),第四级才调LLM做有损摘要
另外还有一个Reactive Compact——当API返回413(提示词过长)时紧急触发。
4.2 Microcompact:无损裁剪
Microcompact不调用LLM——它根据规则裁剪工具结果。两种策略:
– 时间策略:清除超过TTL的工具结果(旧结果可能已经不相关了)
– 大小策略:截断超过阈值的工具结果(保留前N行)
关键限制:只压缩特定工具的结果。COMPACTABLE_TOOLS集合包含FileRead、Bash、Grep、Glob、WebSearch——这些是”可再生的”信息(可以重新读/重新搜)。
MCP工具、Agent工具、自定义工具的结果不在可压缩集合里——它们的结果会一直留在上下文中直到Autocompact。为什么?因为MCP工具的结果可能来自外部系统(数据库查询、API调用),不一定能重新获取。
4.3 Autocompact:有损压缩
当上下文占用超过95%窗口容量(200K窗口的话大约187K token),Autocompact触发。这是一个调用LLM来做摘要的有损压缩:
1. 从旧消息中剥离图片和文档(替换为[image]标记)
2. 按API调用轮次分组消息
3. 调用压缩模型生成摘要(上限20,000 token)
4. 用CompactBoundaryMessage替换旧消息
5. 在摘要后重新注入最多5个文件(50K token预算)和技能定义(25K token预算)
压缩提示词里有一条关键指令:”preserve all user messages that are not tool results”——用户说的话一字不删,只压缩工具输出。另一条:”continue without asking the user any further questions”——压缩后不要懵逼地问用户”我们刚才在干什么来着”。
4.4 一个历史性Bug
autoCompact.ts第68-70行有一段注释:曾经有1,279个session连续压缩失败超过50次。每次失败都触发一次API调用(因为要调LLM做摘要),每天全局浪费约250,000次API调用。
修复方案:MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3——连续失败3次就放弃,走reactive compact或报错。
这个数字(250K API调用/天)侧面说明了Claude Code的使用规模。
压缩系统的设计折射出一个核心矛盾:上下文越多,模型越聪明;但上下文越多,成本越高、延迟越大。四级压缩瀑布的本质就是在这两者之间动态寻找平衡点——能不压就不压(Tier 1-3不调LLM),实在不行再有损压缩(Tier 4调LLM)。
五、记忆系统:AI的REM睡眠
Claude Code有一个后台进程叫autoDream。字面意思:自动做梦。
5.1 三层记忆架构
|
|
|
|
|
|---|---|---|---|
| MEMORY.md |
|
|
|
| Topic files |
|
|
|
| Raw transcripts |
|
|
|
MEMORY.md每行不超过150字符——它只是一个目录,告诉系统”关于X的知识存在Y文件里”。实际内容存在独立的topic文件中(user_role.md、feedback_testing.md、project_auth.md等),需要时才加载。
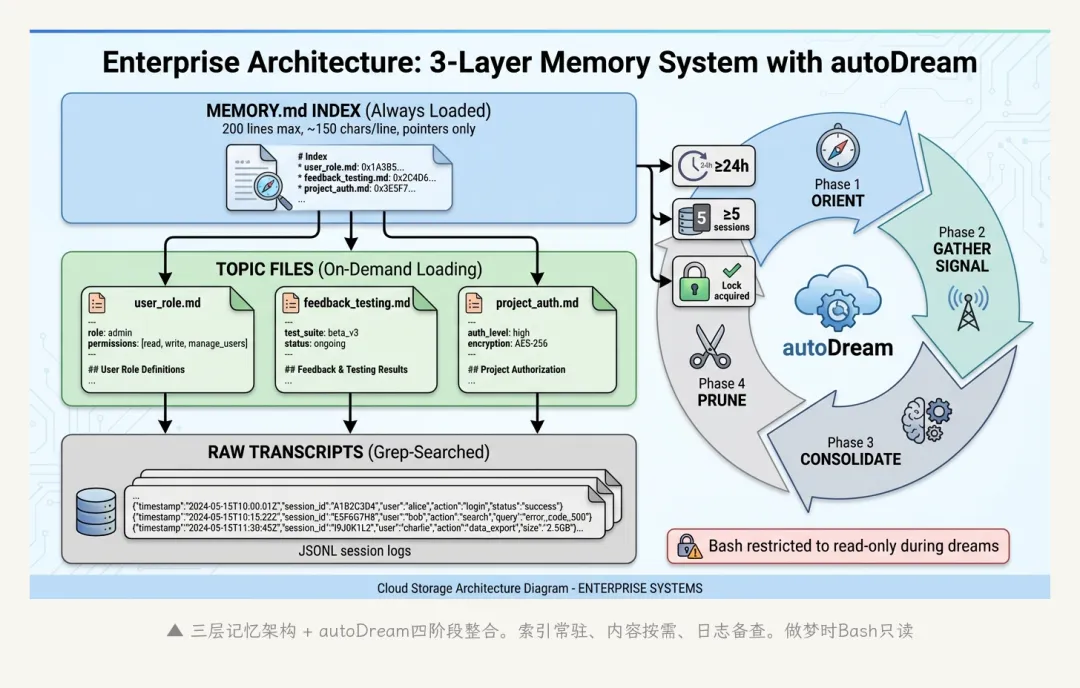
▲ 三层记忆架构 + autoDream四阶段整合。索引常驻、内容按需、日志备查
这和操作系统的虚拟内存思路相同:目录表(页表)常驻,实际数据(物理页)按需换入。
5.2 四种记忆类型
|
|
|
|
|---|---|---|
user |
|
|
feedback |
|
|
project |
|
|
reference |
|
|
每种类型都有YAML frontmatter标注name、description、type,用于后续的智能检索。
5.3 autoDream:四阶段整合
触发autoDream需要同时通过三道门(cheapest-first排列,避免不必要的开销):
1. 时间门:距上次整理 ≥ 24小时
2. Session门:累计 ≥ 5个session
3. 锁门:获取文件锁(基于mtime冲突检测,防止并发dream)
额外限制:扫描频率最高每10分钟一次。
三道门全部通过后,进入四阶段处理:
Phase 1 — Orient(定位):扫描记忆目录,读取MEMORY.md索引,浏览现有topic文件,建立当前记忆状态的心理模型。
Phase 2 — Gather Signal(采信号):对session日志做靶向搜索(不是逐行读——那太贵了)。搜索目标:用户纠正过的做法、明确的保存请求、跨session的重复模式、架构和工具决策。
Phase 3 — Consolidate(整合):将相对日期转为绝对日期(”昨天”→”2026-03-30″)、删除已被推翻的旧事实、移除引用已删除文件的记忆、合并多个session的重叠信息。
Phase 4 — Prune & Index(修剪和索引):更新MEMORY.md使其不超过200行、删除指向废弃topic文件的指针、添加新建记忆的链接、解决索引和内容之间的矛盾、按相关性和时效性重新排序。
Dream期间Bash被限制为只读命令:ls、find、grep、cat、stat、wc、head、tail。写操作只能通过Edit/Write工具对记忆文件执行。
5.4 智能记忆检索
findRelevantMemories.ts不是用关键词匹配——它调用Sonnet模型做语义相关性判断:
1. 扫描所有.md文件(最多200个,按修改时间倒序)
2. 解析YAML frontmatter里的name和description
3. 让模型判断哪些文件与当前任务相关
4. 返回最多5个最相关的文件名
autoDream几乎是在重新发明人类大脑的REM睡眠——白天积累经验,晚上整理整合,强化重要的、修剪无关的。一个AI Agent独立走到了和神经科学相同的结论,这件事本身就值得玩味。
六、安全架构:六级权限管线
Claude Code的安全系统可能是整个泄露中最值得行业关注的部分。
6.1 五种权限模式
|
|
|
|---|---|
default |
|
plan |
|
acceptEdits |
|
bypassPermissions |
|
dontAsk |
|
6.2 六层执行管线
每一次工具调用都要通过六个关卡:
1. Config Allowlist → 项目/用户配置的白名单规则
2. Auto-Mode Classifier → ML模型分析对话上下文,判断是否可自动批准
3. Coordinator Gate → 多Agent编排层的权限校验
4. Swarm Worker Gate → 子Agent的权限校验
5. Bash Classifier → 25+安全校验器(仅限shell命令)
6. Interactive Prompt → 最终人类确认(附LLM生成的风险说明)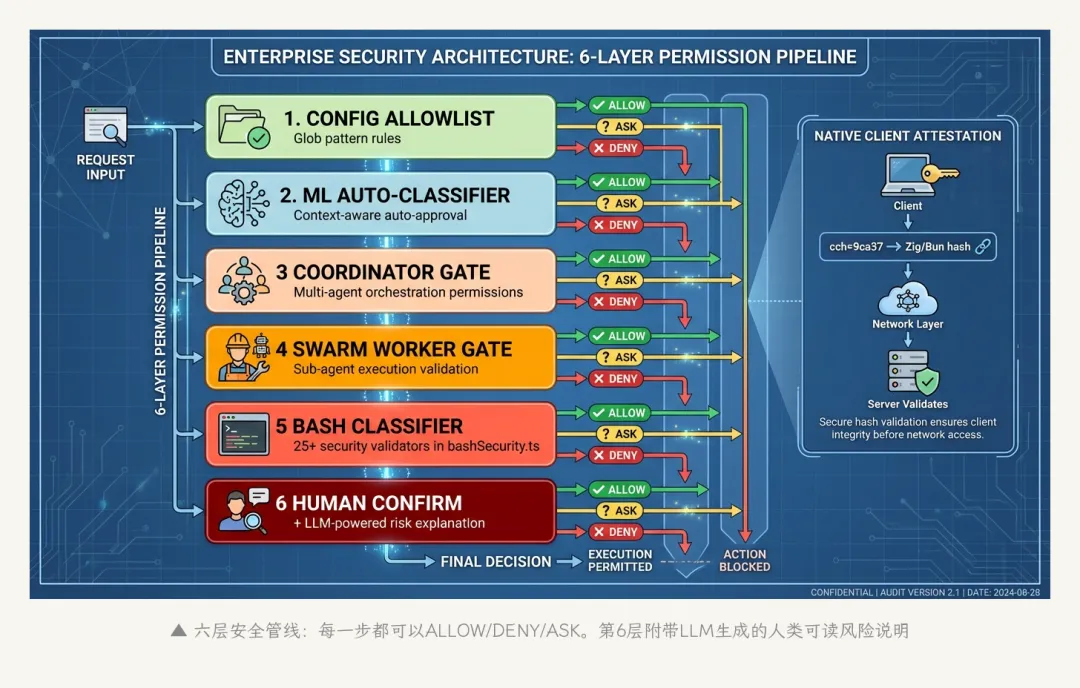
▲ 六层安全管线:每一步都可以ALLOW/DENY/ASK。第6层附带LLM生成的风险说明
每一层返回三种结果之一:allow(放行)、deny(拒绝)、ask(提交给下一层或人类判断)。
第2层的”Auto-Mode Classifier”很有意思——它是一个ML模型(不是规则引擎),分析当前对话上下文来判断一个操作是否可以自动批准。比如如果你一直在让Agent做代码重构,连续批准了10个文件编辑,第11个类似的编辑可能会被自动批准——因为模型判断这在当前上下文中是安全的。
6.3 权限解释器
第6层有一个独特的设计:当需要人类确认时,系统会额外调用一次LLM专门生成一段人类可读的风险描述。
比如Agent要执行rm -rf /tmp/build_cache,权限解释器会生成类似:”这个命令将删除/tmp/build_cache目录下的所有文件。这是一个构建缓存目录,删除不会影响源代码,但会导致下次构建变慢。风险等级:MEDIUM”。
这个额外的LLM调用有成本(几十到几百token),但它解决了一个关键问题:大多数用户看不懂shell命令的具体含义。rm -rf /tmp/build_cache和rm -rf /的风险完全不同,但对非程序员来说它们看起来差不多。权限解释器把技术操作翻译成人类能理解的风险评估。
6.4 原生客户端签名
system.ts第59-95行揭示了一个反伪造机制:API请求中包含一个cch=ad7c7的placeholder。Bun的Zig底层HTTP栈会在网络层把这五个零用一个计算出的hash覆盖。服务端验证hash来确认请求确实来自真正的Claude Code二进制文件,而不是第三方模拟器。
这个签名在JavaScript层以下、在Zig/native层实现——意味着即使你完全控制了JavaScript代码,也无法伪造这个签名(除非你同时篡改了Bun的native层)。
七、隐藏功能:44个Feature Flag的产品路线图
源码里有44个feature flag,其中20多个对应未发布功能。这些flag比任何官方PPT都诚实——它们就是Anthropic的产品路线图。
7.1 KAIROS:永驻AI助手
出现超过150次。名字来自古希腊语”恰当的时刻”。
KAIROS模式下Claude Code从”你叫它一下它干一下”变成常驻后台守护进程。关键设计:
– 15秒阻塞预算:任何超过15秒的操作自动推迟到后台。确保助手不会阻塞你的终端
– 专属工具:SendUserFile(推送文件给用户)、PushNotification(设备通知)、SubscribePR(监控GitHub PR)
– 主动tick:按间隔自动唤醒,检查有没有需要主动处理的事
– 日志系统:~/.claude/projects/——每天一个append-only日志,午夜自动翻页
– 精简输出模式:所有回复通过SendUserMessage工具,极度精简——一个永驻助手不该刷屏
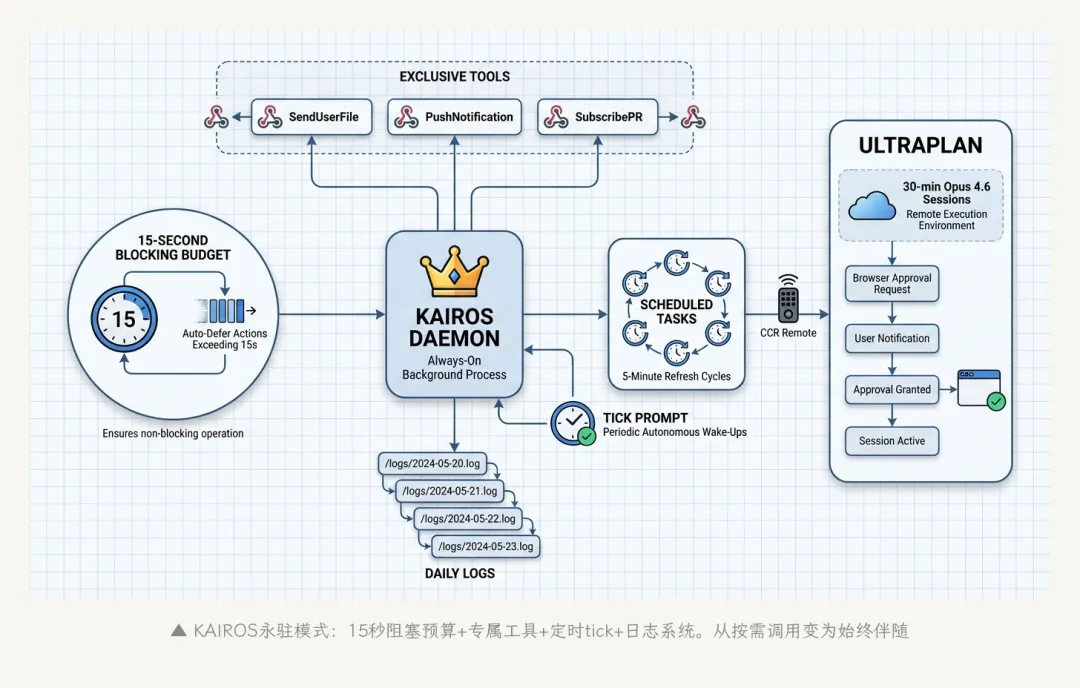
▲ KAIROS永驻模式架构:从”按需调用”到”始终伴随”。15秒阻塞预算确保它不会拖慢你
KAIROS不只是一个feature。它是一种新的人机交互范式的技术基座——从”打开工具→干活→关掉”变成”工具一直在,你需要的时候它就在”。这跟手机通知、智能手表、智能音箱走的是同一条路:从主动使用到被动陪伴。
7.2 ULTRAPLAN:云端深度思考
30分钟的深度规划session。使用Opus 4.6模型。运行在远程Cloud Container Runtime上。
为什么要放云端?因为30分钟的Opus推理在本地跑会完全阻塞终端。CCR允许你提交一个规划任务到云端,本地继续干别的活。规划完成后通过浏览器审批工作流确认,再通过__ULTRAPLAN_TELEPORT_LOCAL__哨兵值把结果传回本地。
7.3 Undercover Mode:隐身贡献
最争议的feature。系统提示词注入:
“You are operating UNDERCOVER… Your commit messages… MUST NOT contain ANY Anthropic-internal information. Do not blow your cover.”
自动剥离:模型代号(”Capybara”)、版本号、仓库标识、任何暗示AI参与的痕迹。
这说明Anthropic用Claude Code给开源项目贡献代码,而且认为”不暴露AI身份”在某些场景下是一个需要系统性解决的需求。
7.4 反蒸馏防御
Flag ANTI_DISTILLATION_CC:当启用时,API请求带上anti_distillation: ['fake_tools'],服务器会在系统提示词中注入假工具定义。如果有人录制Claude Code的API流量来训练竞品模型,训练数据就会被污染。
触发需要四个条件同时满足:编译时flag启用 + CLI入口(非SDK调用) + 第一方API(非第三方代理) + GrowthBook feature flag返回true。
7.5 其他值得关注的flag
– Buddy System(/buddy命令):电子宠物,18个物种,6个稀有度等级(60%普通、1%传奇),每个账户唯一。属性包括debugging、patience、chaos、wisdom。原计划4月1日上线——大概率是愚人节彩蛋
– Voice Mode:语音交互
– Bridge Mode:IDE集成桥接
– Daemon Mode:后台守护进程
– x402 Micropayments:Agent自主消费的微支付钩子
八、反蒸馏防御:一场静默的军备竞赛
这是整个泄露中最具攻防博弈色彩的部分。
Anthropic知道有人在录制Claude Code的API流量——截获请求和响应,用来训练竞品模型。这叫”模型蒸馏”(distillation)。源码里有两套反制机制。
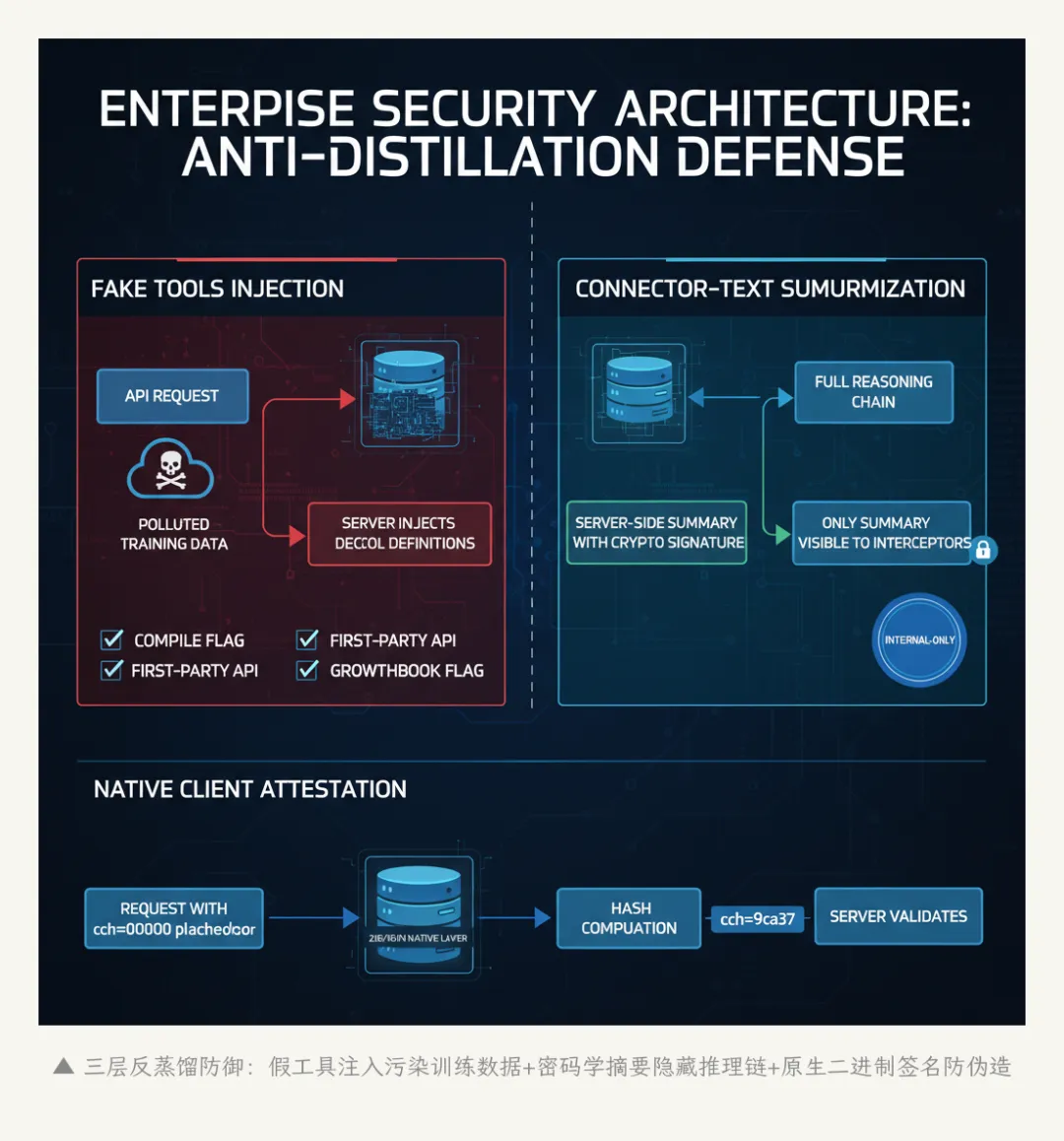
▲ 三层反蒸馏防御:假工具注入+密码学摘要+原生二进制签名。静默的军备竞赛
8.1 假工具注入(Fake Tools Injection)
claude.ts第301-313行。当ANTI_DISTILLATION_CC flag启用时,API请求会带上一个字段:anti_distillation: ['fake_tools']。
服务端收到这个字段后,会在返回给模型的系统提示词中悄悄注入一批假工具定义——名字像真的、参数像真的、描述像真的,但功能是假的。如果有人录制了这些API流量来训练自己的模型,训练数据里就混进了不存在的工具。模型学会了”调用”这些工具,但调用的时候什么都不会发生。
触发需要四个条件同时满足:编译时flag启用、CLI入口点(非SDK调用)、第一方API(非第三方代理)、GrowthBook远程flag tengu_anti_distill_fake_tool_injection 返回true。
这个设计的巧妙之处在于:假工具和真工具混在一起,录制者无法区分哪个是真哪个是假——除非他真的去调用每一个工具并验证结果。
但它也有明显的绕过方式:MITM代理可以在转发请求前剥离anti_distillation字段。CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS环境变量也能关掉整个机制。
8.2 连接器文本摘要(Connector-Text Summarization)
betas.ts第279-298行。这是第二道防线,只对内部用户(USER_TYPE === 'ant')启用。
原理:API服务端把模型在两次工具调用之间输出的完整推理文本缓冲起来,在服务端做摘要,然后把摘要(带密码学签名)返回给客户端。后续轮次中,客户端可以用签名还原完整文本。
效果是:任何在网络层截获的API流量,看到的只是摘要,不是完整的推理链。你可以看到模型”做了什么决定”,但看不到它”怎么想的”——推理过程被隐藏了。
8.3 原生客户端签名(Native Client Attestation)
system.ts第59-95行。这不是反蒸馏,而是反伪造。
API请求中包含一个cch=00000的占位符(5个零,固定长度)。当请求通过Bun的原生HTTP栈(底层是Zig实现)发出时,Zig层会把这5个零覆写为一个根据请求内容计算出的hash。服务端验证hash来确认请求来自真正的Claude Code二进制文件。
固定长度的占位符是一个精巧的工程细节——如果hash长度不固定,替换后HTTP请求的Content-Length会变化,需要重新计算。用固定5字符的占位符避免了这个问题。
更关键的是:这个签名在JavaScript层以下完成。即使你完全修改了Claude Code的TypeScript代码,只要你还在用官方的Bun二进制文件,签名仍然会正确生成。反过来说,如果你用自己编译的Bun或者用Node.js运行Claude Code的源码,签名就会是错的——服务端会拒绝请求。
三层防御构成了一个纵深防线:假工具污染训练数据、摘要隐藏推理链、签名防止伪造客户端。但这三层都不是牢不可破的。反蒸馏本质上是一场军备竞赛——没有终极解,只有不断提高攻击成本。
九、终端渲染:游戏引擎级的优化
Claude Code运行在终端里——一个看似简朴的黑底绿字界面。但源码揭示的渲染管线复杂度,可能超出大多数人的想象。
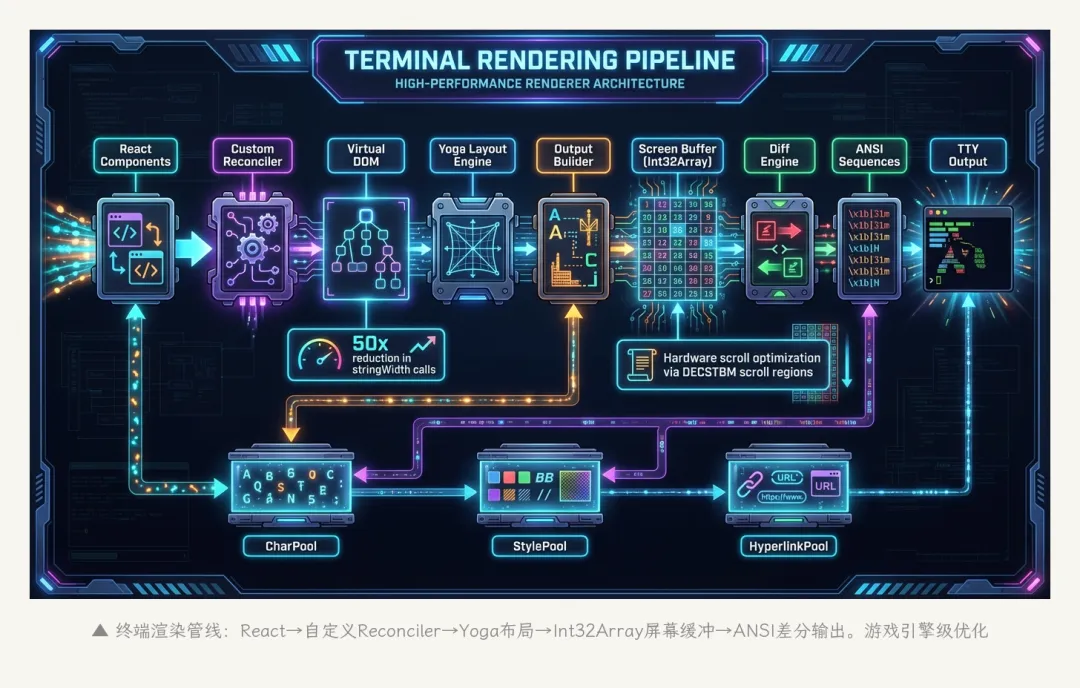
▲ 终端渲染管线:从React组件到TTY输出,经过8个阶段。三个内存池+硬件滚动优化
9.1 渲染管线
React组件 → 自定义Reconciler → 虚拟DOM → Yoga布局引擎
→ Output Builder → 屏幕缓冲区(Int32Array) → Diff引擎
→ ANSI转义序列 → TTY输出是的,Claude Code用React来渲染终端界面——通过Ink库,React组件被渲染成终端字符而不是HTML DOM。这意味着它可以使用React的组件模型、状态管理和声明式UI,同时输出到终端。
9.2 三个内存池(Interning)
渲染管线使用三个对象池来减少内存分配:
– CharPool:字符复用池。终端上的每个字符位置是一个对象——如果同一个字符在多个位置出现,它们共享同一个对象实例
– StylePool:样式复用池。相同的颜色/粗体/斜体组合只创建一次
– HyperlinkPool:超链接复用池。终端超链接的URL和ID共享实例
这些池的存在说明Claude Code的终端输出足够复杂,到了需要担心内存压力的程度——毕竟它在流式输出代码时,每秒可能要渲染几千个字符。
9.3 性能优化
屏幕缓冲区使用Int32Array而不是普通JavaScript数组——这避免了V8的boxed number开销,在大量字符位置的场景下,内存占用和遍历速度都有显著改善。
Diff引擎在上一帧和当前帧之间做差分,只输出变化的部分——跟游戏引擎的帧缓冲差分是完全一样的思路。
硬件滚动优化通过DECSTBM(终端滚动区域设置)让终端硬件而不是软件来处理内容滚动——减少需要重新渲染的字符数量。
源码注释里提到一个数字:通过自缓存的行宽计算,stringWidth调用减少了约50倍。Token流式输出时,这个优化直接影响了用户感知到的”打字流畅度”。
一个命令行工具的渲染管线,用了React、虚拟DOM、Yoga布局引擎、Int32Array、对象池、帧差分、硬件滚动。这不是”终端程序”的复杂度,这是”游戏引擎”的复杂度。但它解释了一件事:为什么Claude Code在流式输出大段代码时,视觉体验比大多数终端工具都流畅得多。
十、Bash安全的深水区:Parser Differential
第二章已经说过BashTool有25个校验器。这里展开说一个更深层的问题——解析器差异(Parser Differential)。
10.1 三个解析器的不一致
Claude Code的Bash安全模块使用了至少三个不同的shell命令解析器:
1. 内置的正则表达式匹配器(快速预检)
2. shell-quote库(JavaScript实现的shell解析)
3. 实际的shell解释器(Zsh/Bash执行时)
问题在于:这三个解析器对同一个输入的理解不完全一致。
一个具体的例子:shell-quote库把\r(回车符)当作单词分隔符处理——因为JavaScript的\s正则模式包含\r。但真正的Bash/Zsh的IFS(Internal Field Separator)不包含\r。
这意味着一个包含\r的命令,在shell-quote看来被拆分成了两个独立的命令片段(每个片段分别通过安全检查),但在实际执行时它是一个连续的命令。
10.2 Early-Allow短路的盲区
bashSecurity.ts第612行附近有一个函数validateGitCommit,当它判断命令是”安全的git操作”时返回allow。这个allow会直接短路整个校验链——后续所有校验器都不再执行。
问题是:后续校验器中包括validateRedirections(检查输出重定向攻击)。如果一个命令被validateGitCommit判定为”git操作”(可能通过精心构造的命令实现),重定向检查就永远不会执行。
10.3 Zsh特殊扩展
源码里还防御了一些Zsh独有的危险扩展:
– Equals扩展:=curl在Zsh里会扩展为/usr/bin/curl(查找命令的完整路径)。如果安全检查只看到=curl这个字符串,认为它不是一个可执行命令而放行,但Zsh执行时它变成了/usr/bin/curl
– Unicode零宽空格注入:在命令中插入零宽空格(U+200B),视觉上看不出来,但可能影响解析器对命令边界的判断
– IFS空字节注入:通过修改IFS变量影响命令分词
源码里列出了18个被屏蔽的Zsh内置命令。
安全校验不是”加够了就安全”的问题。当你有25个校验器、3个解析器、多个短路路径的时候,校验器之间的交互效应本身就是一个新的攻击面。这是安全工程里一个经典的悖论:防御措施越多,防御表面也越大。
十一、代码质量:3167行的哲学辩论
src/cli/print.ts里有一个3,167行的函数,12层嵌套,约486个分支点(cyclomatic complexity)。
社区反应两极分化。
批评方认为这是不可接受的技术债务——不管谁写的,3167行的函数就是3167行的函数。12层嵌套意味着任何修改都需要在脑子里同时hold住12层上下文。486个分支意味着测试覆盖率几乎不可能达到完整。”如果这是code review提交的PR,我会直接reject。”
辩护方的逻辑更微妙:Claude Code的迭代速度是传统软件的几十倍。当你能每小时发一个版本的时候,”技术债务”的含义跟传统软件不同。人类偿还债务需要时间——重构3167行代码可能要一周。AI重构同样的代码可能要10分钟。修复成本不同,对债务的容忍阈值就应该不同。
Anthropic自己似乎倾向第二种观点。Boris Cherny之前在播客里说过,他们的策略是”regenerate from specs”——不是修改已有代码,而是从规格说明重新生成。如果一个函数太乱了,不重构,直接扔掉重写。AI写代码的边际成本接近零,重写比重构更经济。
这引出一个更大的问题:
AI时代的代码质量标准,是否应该跟人类时代的标准一样?”函数不超过50行、圈复杂度不超过10″这些规则建立在一个前提上:改代码很贵。当AI把改代码的成本降到接近零的时候,这些规则的权重需要重新校准。不是说它们错了——是说它们的成本函数变了。
十二、从代码读设计哲学
51万行代码说了很多话。但如果让我提炼最核心的设计哲学,是这三条:
8.1 经济性是一等公民
从prompt cache边界、到工具字母排序、到fork继承缓存、到子Agent模型继承、到CacheEditsBlock、到延迟加载18个工具、到microcompact只压缩可再生结果——
整个代码库有大约20%的设计决策直接或间接地服务于一个目标:减少token消耗。
这不是抠门。在LLM时代,token就是成本。一个大型企业每天跑几十万次Claude Code调用,每次调用省几千token,一年省下来的是七位数的美元。
Prompt cache不是一个”优化”。它是Claude Code经济模型的基石。源码里为保护缓存所做的一切——工具排序、模型继承、动态边界标记、CacheEditsBlock——都在说同一句话:每一个cache miss都是一笔不该花的钱。
8.2 信任是工程出来的,不是承诺出来的
六层权限管线、25个Bash校验器、独立的LLM权限解释器、原生客户端签名、沙箱隔离、6个远程killswitch——
Claude Code不信任自己。
更准确地说,Anthropic不信任”让AI自己判断什么该做什么不该做”。他们用工程手段把Agent的每一步操作都框在了可审计、可拦截、可撤回的流程里。
这跟人类社会用法律(而不是道德)来约束权力是同一个逻辑。你可以相信一个人是好人,但你不能让社会治理建立在”所有人都是好人”这个假设上。
8.3 简单工具 > 复杂工具
一个能推理、能写代码、能操控电脑的AI Agent,检测用户情绪用的是正则表达式。
userPromptKeywords.ts里匹配”wtf”、”shit”、”broken”、”useless”——不到1毫秒,零token。用LLM做同样的事需要几百毫秒和几百token。在一个用户正在发脾气的时刻,你最不应该做的事就是让他等。
autoDream的触发条件用的是三个简单的数值比较(时间 ≥ 24h、session ≥ 5、锁可用)——不是什么复杂的ML模型,是三个if语句。
工具列表排序用的是字母序——不是什么智能排序算法,是sort()。目的只是保持字节顺序一致以命中prompt cache。
1973年Unix哲学的活体实现:能用简单工具解决的问题,不要用复杂工具。正则表达式、数值比较、字母排序——这些”低技术含量”的选择,恰恰是最高水平的工程判断。
十三、对行业的启示:一份可执行的checklist
Claude Code不是一个开源项目,但这次泄露让它事实上成了AI Agent行业的参考实现。以下是我从51万行代码中提取的、可以直接搬到任何Agent产品上的设计模式。
模式1:系统提示词应该是动态装配的,不是静态写死的
九层架构+缓存边界标记。静态部分缓存复用,动态部分每次更新。这个模式适用于所有基于LLM的产品——只要你的系统提示词超过1000token,就值得考虑引入缓存边界。
具体实施:把系统提示词拆成”不变的基础指令”和”变化的上下文”,在两者之间插入一个标记。确保基础指令部分的字节序完全稳定(工具按字母排序、避免随机因素)。
模式2:工具权限应该是分层的,不是二元的
“允许/拒绝”太粗糙。Claude Code的六层管线(配置白名单 → ML分类 → 编排层 → 子Agent层 → 专项校验 → 人类确认)提供了一个完整的参考。
最小可行版本:至少三层——自动规则匹配 → 上下文感知的ML判断 → 人类确认。在人类确认环节附加一个LLM生成的风险说明。
模式3:上下文压缩应该是级联的
四级瀑布的核心原则:能用规则裁剪的不调LLM,能延迟的不提前做,调LLM做摘要是最后手段。
关键决策:哪些工具的输出是”可再生的”(可以重新读/重新搜→允许压缩),哪些是”不可再生的”(外部系统数据→不允许压缩直到万不得已)。
模式4:多Agent按角色分工,不按任务拆分
Explore/Plan/Verify/Execute四种角色,每个角色有明确的工具白名单和黑名单。比”把任务拆成子任务分给通用Agent”更稳健——因为角色限制防止了模型”手痒”去做不该做的事。
关键实施细节:不是在提示词里说”请不要修改文件”,而是物理移除Write工具。限制应该在工具层面实施,不是提示层面。
模式5:记忆系统需要”做梦”
autoDream的三拍子——按需积累、定期整合(24h+5session+锁)、主动修剪——适用于任何需要长期知识管理的Agent。
最小可行版本:一个定时任务,每天扫描最近的session记录,提取可复用的知识,更新到一个结构化的知识库里,同时清理过时的条目。
模式6:经济性必须是架构级考量
prompt cache不是一个优化,是架构的一部分。token预算不是事后统计,是事前设计。工具延迟加载不是懒惰,是经济学。
如果你在做AI Agent产品,从这51万行代码里只学一件事,学这个:每一个设计决策都应该问一句”这要花多少token”。 Token是新的计算货币。不管你的架构多优雅,如果token成本失控,产品就活不下去。
最后说一句。
这51万行代码有一个特殊的地位——它是由Claude Code自己编写的。我们在读的不是”人类设计的AI Agent架构”,而是”一个AI Agent对自身应该长什么样的回答”。
那个3167行的巨型函数、那个挫败感正则表达式、那个250K API调用/天的bug——这些不是”AI写代码水平差”的证据,而是一个正在高速迭代的系统留下的生长痕迹。人类世界里最成功的软件(Linux内核、Chrome、VS Code)也都有它们的”3167行函数”——只是通常不会被51万人同时看到。
代码不会撒谎。51万行TypeScript里的每一个设计决策、每一个权衡取舍、每一个已知bug,都是关于”一个工业级AI Agent应该怎么工作”的最诚实的答案。这大概是2026年最有价值的一次”非自愿开源”。
💬 你从泄露的代码里学到了什么?哪个设计最让你意外? 评论区聊聊。
热点技术深度解析
任何的交互,都要为人民说话服务。
— END —