 夜雨聆风
夜雨聆风





Claude Code 源码泄露:顶级 Agent 的核心早已不是“模型+提示词”
最近 Anthropic 旗下的 Claude Code 源码意外流出,引发了开发者圈的深度复盘。大家最初的兴奋点在于翻找 System Prompt 或工具集,但深入代码逻辑后会发现,这些只是表象。 注意到这次泄露的价值不在代码本身,而是在于 Claude Code 演示了如何将 AI Agent 从“对话补全器”重构成一套工业级系统工程。过去,行业对 Agent 的普遍理解是“LLM + Prompt + Tool”,而 Claude Code 的实现思路已经进化到了“AI 操作系统”的范畴。
它背后的五个核心逻辑,揭示了顶级 Agent 的壁垒究竟在哪里。
1. 提示词的本质是“运行时编排”
在普通开发者眼中,Prompt 是为了让模型变聪明的“文案”;但在 Claude Code 里,Prompt 是一套动态拼接的配置系统。
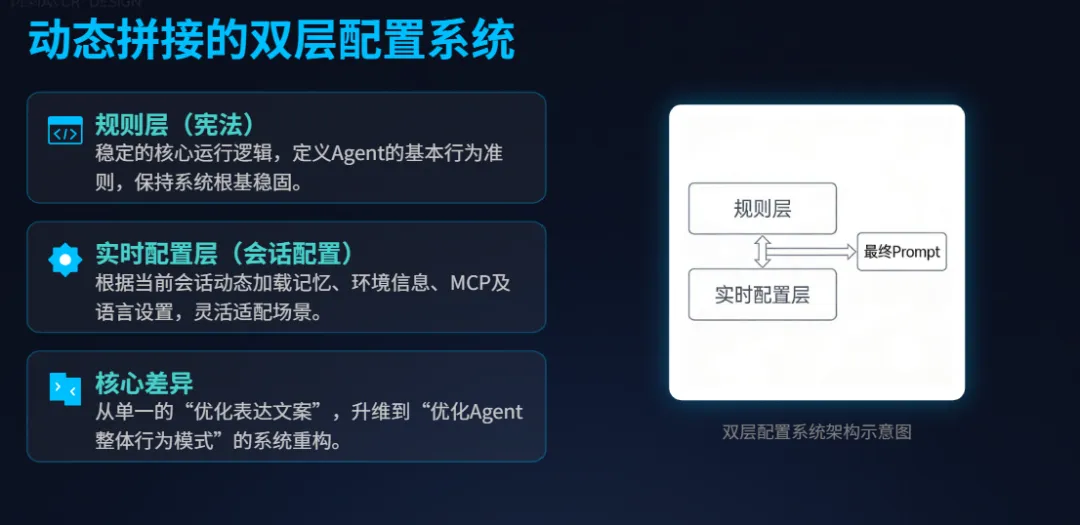
它采用了双层架构:
-
宪法层(Stable Rules): 确定系统的核心运行逻辑和行为边界,这部分是静态且刚性的。 -
环境层(Dynamic Context): 根据当前的上下文,动态加载内存(Memory)、环境信息、MCP 协议、语言设置等。
内行看门道: 别人在调优文字描述,Claude Code 在做运行时编排(Runtime Orchestration)。这种从“写文案”到“写逻辑”的转变,是 Agent 能够稳定处理复杂任务的基础。
2. 职责拆分:软件工程的回归
很多多 Agent 框架更像是“为了分工而分工”,而 Claude Code 的多 Agent 设计则遵循了传统软件工程中“职责分离”的准则。
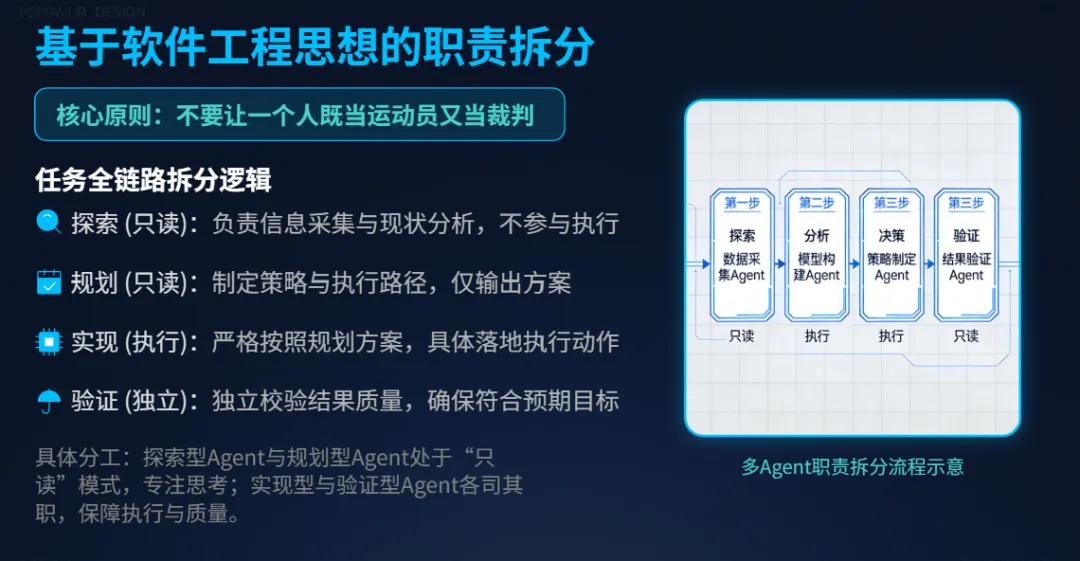
它将任务链拆解为:探索、规划、实现、验证。最硬核的设计在于:负责“探索”和“规划”的 Agent 拥有纯只读权限。它们只负责把现状盘清楚、把路径规划好,绝对不碰代码。
这种设计有效地解决了单一模型既当“运动员”又当“裁判员”的幻觉问题。避免了模型在执行过程中由于赶进度而产生的“差不多就行”的心理归因,确保每一步决策都有据可循。
3. 生成能力只是起点,验收能力才是终点
AI 编程领域一直有个误区:追求“能写出来”。但实际生产中,验证代码的正确性比编写代码代价更高。Claude Code 的高价值点在于它把验证(Verification)做到了极致。

系统内置的 Verification Agent 并不温柔,它的任务是“搞坏系统”。它会强制执行构建流程、跑单元测试、进行类型校验,并覆盖从 CLI 到数据库迁移的所有场景。它甚至会主动推演边界条件,直到确认代码在工业环境下依然稳固。顶级 Agent 的竞争力不在于能写 80 分的代码,而在于它具备严苛的自反馈闭环。
4. 从“工具调用”进化到“工具治理”
简单的 Tool Use 只是“模型发指令,系统跑脚本”,这在 Demo 里没问题,但在生产环境就是灾难。Claude Code 使用工具的核心在于全程治理。
-
执行前: 强制进行输入校验、权限分级和风险评估,防止模型参数误传或越权操作。 -
执行后: 通过 Hook 函数捕获异常,并进行上下文补偿。

它的底层逻辑基于“防御性编程”:默认模型会传错参数,默认环境会返回错误。谁能把异常处理(Error Handling)写进系统骨架,谁的 Agent 才有资格处理真实的业务。
5. 生命周期管理:从实验室到生产线
为什么很多 Agent 只能跑通简单的 Demo?因为它们处理不了长任务。任务中断了怎么接续?后台任务如何回收?上下文数据粘连了怎么清理?
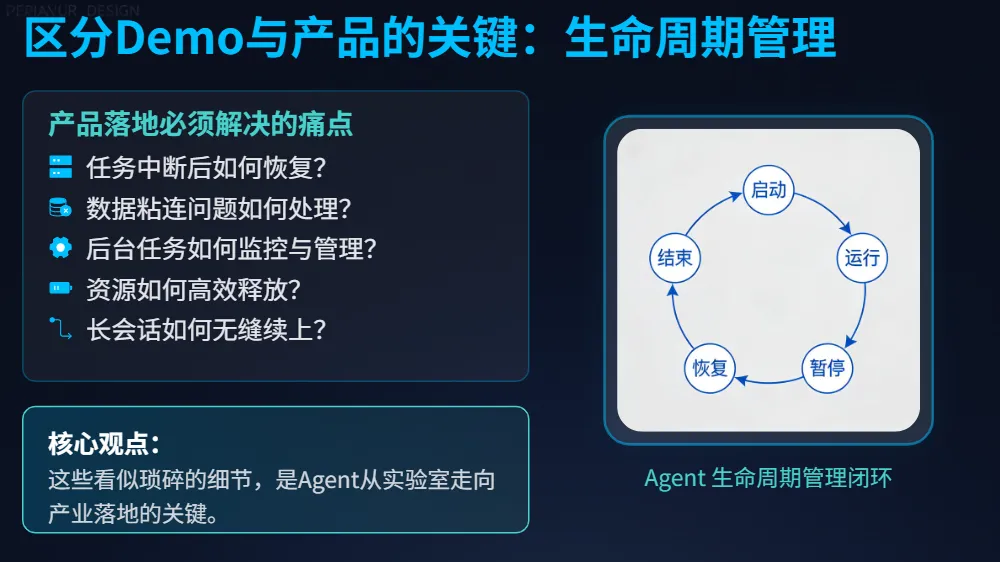
Claude Code 花了大量精力处理这些“琐碎”的细节。它对 Agent 的生命周期进行了显式管理,确保系统在断点续传、资源释放和多轮会话状态保持上具备产品级的稳定性。
总结:Agent 竞速赛已进入“系统工程”时代
Claude Code 源码的流出,给所有开发者提了个醒:AI Agent 的下半场,不再是模型能力的单打独斗,而是系统工程能力的综合比拼。
评价一个 Agent 的工程化程度,不再看它能否写出精妙的诗词,而要看它的规则体系是否稳健、职责分工是否清晰、验证环节是否严苛、工具治理是否完善。
顶级的 AI Agent,本质上是一个组织有序、逻辑自洽的软件系统,而不仅仅是一个“聪明的模型”。夯实这些工程细节,才是 Agent 从实验室走向产业落地的唯一路径。