 夜雨聆风
夜雨聆风





Claude Code 源码泄露的第二天,我的 AI 却悄悄利用这套源码进化了
Claude Code 源码泄露的第二天,我的 AI 却悄悄利用这套源码进化了
前几天,Claude Code 的源码泄露了。
不是黑客入侵,是 Anthropic 自己的失误——他们发布的 npm 包 @anthropic-ai/claude-code 附带了 source map,有人用这个 source map 把压缩代码完整还原出了 TypeScript 源码。4756 个文件,1884 个 .ts 源文件,全部公开挂在 GitHub 上。
全网沸腾了两天。大家在扒功能、截图、评论 Anthropic 是不是故意的。
我在做另一件事。
一次反向工程
我把 repo 链接扔给小T,没有说”帮我总结功能”。
我问的是:这里面,有没有你能学的东西?拿它和你自己的系统对比,找出差距,给我一份升级清单。
它扫完了整个 repo 结构,定位了核心模块,10 分钟后给我交回来一份清单。
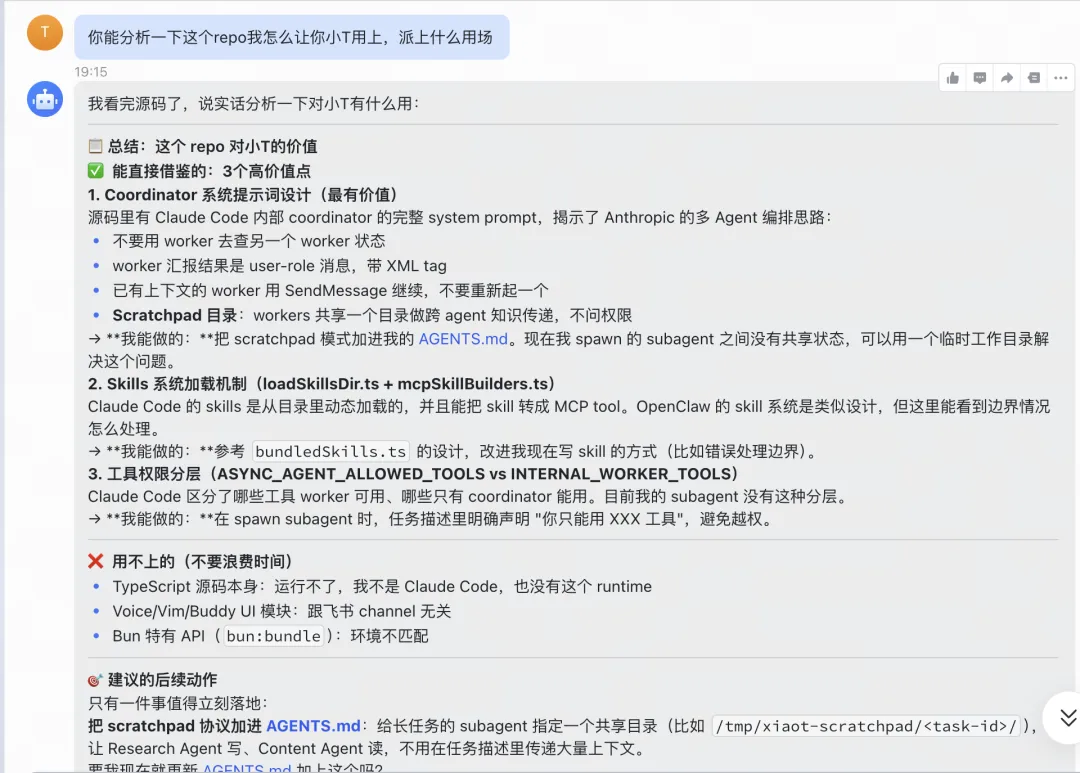
不是”Claude Code 有这些功能”的总结。是”我在哪里有同类问题,他们怎么解的”。
一个 AI,读懂了另一个 AI 的工程师是怎么想的。
升级清单:分门别类做了这些
多 Agent 协作
| 功能 | 来源 | 技术实现 | 解决的问题 |
|---|---|---|---|
| Scratchpad 协议 | coordinator 架构 | 串行任务强制建共享目录 /tmp/xiaot-scratchpad/<task-id>/;Research Agent 写 findings.md(含用户原话 verbatim 段防止目标漂移),Code Agent 写 plan.md + progress.md,Content Agent 写 draft.md | 多 agent 交接时,上游探索的文件上下文、关键决策在 session 切换后完全蒸发;下游 agent 只能靠任务描述重建上下文,精度差 |
| Continue vs Spawn Fresh | AgentTool 决策逻辑 | 按 context overlap 决策:上游已探索的文件后续实现需要 → Continue;验证刚写的代码/全新方向 → Spawn Fresh(verifier 必须用新眼睛,不能带实现假设);错误方向失败 → 必须 Spawn Fresh | 每次都新开或者每次都续,靠直觉,重复踩坑 |
| Prompt 质量规则 | coordinator 源码注释 | 禁止”based on your findings fix the bug”类模糊指令;coordinator 必须先综合 research 结果,再写含具体文件路径、行号、错误信息、完成定义的指令;任务目的必须说明 | Agent 拿到模糊指令后自行推断,目标悄悄偏移,coordinator 以为在做 A,agent 在做 B |
| 分段 Research 规则 | coordinator 架构 | 预计 >8 分钟的调研拆分为多段,每段写 findings-N.md,下段先读前序再执行 | runTimeoutSeconds 上限约 10 分钟,深度调研直接超时 |
任务管理
| 功能 | 来源 | 技术实现 | 解决的问题 |
|---|---|---|---|
| 一次只有一个”进行中” | TodoWriteTool | 状态严格单一:完成立刻标记,阻塞改为”阻塞”并注明原因,测试失败不得标完成 | 多步骤同时挂”进行中”,看板状态虚报,真实进度不可追踪 |
| 双向 Code Review | Advisor 机制 | 实质动手前先 review plan(read/explore ≠ 实质工作,write/commit 才是);宣布完成前先持久化成果再验证;执行证据与计划冲突时不能无声切换,必须记录冲突并通知 | 跑完了发现方向错了;自测通过但 review 的检查点没覆盖到 |
| 验证步骤自检 | TodoWriteTool 收尾规范 | 3步以上复杂任务完成后,主动检查是否有验证步骤,没有则追加,不依赖用户提醒 | 完成即交付,没有验证;靠用户发现问题 |
记忆系统
| 功能 | 来源 | 技术实现 | 解决的问题 |
|---|---|---|---|
| Dream Pass(4-phase) | autoDream 机制 | Orient → Gather → Consolidate(修正漂移事实,相对时间强制转绝对时间,删除被推翻的旧条目)→ Prune(清理过期指针,保持 MEMORY.md ≤35行) | 旧记忆静静躺在文件里作为”事实”被读入;”昨天 Tarry 说”一周后变幽灵;堆叠不是记忆,是噪声 |
| 防重复读 | contextAnalysis 优化 | Subagent task 描述里明确 scratchpad 路径,先读再执行;Code Agent 把已读文件写进 progress.md,continue 时不重读;findings.md 只写摘要,不复制完整文件内容 | 多轮对话中反复读同一文件,token 浪费是主要开销来源 |
进度播报
| 功能 | 来源 | 技术实现 | 解决的问题 |
|---|---|---|---|
| AgentSummary 格式 | AgentSummary + toolUseSummaryGenerator | 进行中:现在进行时 + 具体操作对象 3-5词(正在读取 findings.md);完成:过去时 ≤30字(修复 ETL 空指针);禁止”处理中”、”调查问题”等模糊词 | 进度描述形如”处理中”,看不出在干什么;完成描述看不出做了什么 |

每个人的小龙虾都不一样
这件事让我想清楚一个问题:OpenClaw 配置的上限,不是工具,是你对自己需求的理解深度。
我的小T的记忆系统,是根据我的工作方式慢慢调出来的。我需要跨 session 记住项目决策,我需要分层记忆而不是一个大文件,我需要定期清理而不是无限堆积——这些需求,别人的配置不一定有,也不需要有。
Claude Code 的设计逻辑是一套很好的参照系,但它是 Anthropic 工程师为他们的场景踩坑踩出来的。
借鉴逻辑,不是复制功能。
这次升级 15 处,不是因为 Claude Code 有这 15 个功能,而是我的小T在这 15 个地方有类似的问题,且他们的解法有参考价值。
不同的人,不同的工作流,同样用 OpenClaw,最后跑出来的系统会完全不一样。这才是可编程 AI 基础设施真正有意思的地方。
AI 吃同类,是一种更精准的学习方式
人教 AI,靠的是自然语言。自然语言是有损的——意图准确,但边界模糊。
AI 读源码,是读工程师的决策逻辑。每一行约束背后都有具体的踩坑记录。TodoWriteTool 写”一次只有一个进行中的任务”,不是规格要求,是血泪教训。这种信息密度,自然语言传不了。
所以这次我没有”教”小T任何东西。
我只是把学习材料放在了它面前,问了正确的问题。
进化的方向,由人来选。进化的执行,由 AI 来做。
全网在追热点的时候,热点本身不稀缺。稀缺的是,你拿热点做了什么。
旧记忆会腐烂
autoDream 机制里有一句话,让我想了很久:
“Memory is not about storage. It’s about staying accurate.”
我们本能地以为记忆越多越好。但 AI 的记忆是有机体,不是硬盘。
三个月前写下的规则,今天可能已经被推翻,但还在文件里作为”事实”被每次 session 读入。”昨天 Tarry 说…”——写下那天准确,一周后是幽灵。
清理旧记忆,和写入新记忆同样重要。现在小T每隔几天会做一次 Dream pass,旧条目不是档案,是负债。
这个道理不只适用于 AI。
Tarry Wang | 2026-04-02
诺贝松AI成长社区
个人观点,仅供参考