Claude Code源码泄露:Agent Harness架构全景解析
2026年3月31日晚,AI Coding圈被一则消息引爆:Anthropic官方分发的`@anthropic-ai/claude-code@2.1.88`版本npm包中,意外夹带了一个57MB的`cli.js.map`文件。这个本用于调试、将打包产物映射回原始源码的文件,直接暴露了近1906个Claude Code原生TypeScript/TSX源码文件、超51.2万行代码,规模接近一个中型App的完整代码量。一时间,社区热议从“源码泄露”本身,快速转向了这套代码背后最核心的工程实现——Agent Harness的真实面貌。这并非一次简单的打包失误,而是行业首次完整窥见Anthropic在AI Agent领域的底层架构设计,为所有从事Agent开发的团队提供了一份极具参考价值的真实样本。
很多人将此次事件简单定义为“Claude Code完整源码泄露”,但从技术角度来看,这种说法并不严谨。本次曝光的核心内容的边界的清晰,既不涉及Anthropic的核心壁垒,也未造成用户数据安全风险,更像是一次工程分发环节的疏忽,让原本隐藏在打包产物后的开发态细节,得以完整呈现。
本次通过`cli.js.map`文件公开的内容,核心集中在三个层面,均属于客户端实现范畴,与模型核心和后端服务无关:
-
source map文件本身:包含4756个源文件的完整路径与对应内容,其中1906个为Claude Code自身的TypeScript/TSX源码,剩余2850个为node_modules依赖包,并非“完整闭源系统被扒光”;
-
客户端实现细节:包括CLI界面的构建逻辑、工具调用流程、权限控制机制、任务运行状态管理等,可直接还原开发态的模块结构与代码实现;
-
核心架构相关代码:与Agent Harness相关的主循环、工具池、记忆层、远程权限桥接等核心模块的代码结构,这也是本次事件中最具行业参考价值的部分。
需要明确的是,本次事件不涉及模型权重泄露(Anthropic的核心壁垒的Claude模型本身),不涉及后端服务被攻破,更不存在“可直接利用的后门”。Anthropic的核心竞争力并未受到影响,真正被曝光的,是其在AI Agent产品化过程中,如何将Harness架构落地为可运行的工程实现。
本次泄露的链路十分简单,无需反编译、反混淆等复杂技术手段,普通开发者即可轻松获取相关源码,这也是事件能快速在社区发酵的重要原因。具体链路如下:
-
Anthropic在发布`@anthropic-ai/claude-code@2.1.88`版本时,未在打包环节剔除用于调试的`cli.js.map`文件,导致该文件随npm包一同分发;
-
社区开发者发现这一问题后,通过常规的npm包操作,即可拉取对应版本的包并解包;
-
解包后可直接查看`cli.js.map`文件,该文件本质是一份JSON,包含`sources`(源文件路径)和`sourcesContent`(对应源码内容)两个关键数组,两者索引一一对应,无需额外处理即可读取完整的原始代码。
目前社区流传着一组简单的复现命令,可快速获取并尝试运行相关代码(仅用于技术研究,请勿用于商业或违规用途):
npm pack @anthropic-ai/claude-code@2.1.88 --registry=https://registry.npmjs.org/npm installnpm run buildnode dist/cli.js --help
从工程角度来看,这组命令的核心价值并非“能否成功运行CLI工具”,而是通过`cli.js.map`文件,能快速定位到`src/query.ts`(主循环核心)、`src/tools.ts`(工具系统)、`src/Tool.ts`(工具类定义)、`src/services/autoDream/autoDream.ts`(记忆整理)等关键文件,清晰看到Claude Code的底层实现逻辑。
事件发酵后,AI圈的讨论主要分为三类,其中第三类讨论最能体现本次事件的行业价值,也让焦点从“源码泄露”转向了Agent Harness本身:
-
第一类:聚焦“泄露规模”。社区将还原后的代码打包归档上传至GitHub,短短几小时Star数便突破万,开发者们重点关注`sources`和`sourcesContent`的内容,统计源码文件数量、代码行数,讨论此次暴露的可见性到底有多高;
-
第二类:理性纠偏。不少资深开发者提醒,此次并非“完整源码开源”,Claude Code的CLI逻辑本身就并非绝对闭源(此前为压缩后的可读JS),source map只是将其转化为更易读的TypeScript,Anthropic的核心壁垒始终是Claude模型,而非客户端工具;
-
第三类:聚焦架构未来。开发者们通过代码中的`KAIROS`(持续在线助手)、`COORDINATOR_MODE`(多Agent编排)、`ULTRAPLAN`(远程规划)、`autoDream`(记忆整合)等功能开关,推测Claude Code的未来演进方向,讨论其在多Agent调度、远程工作流、长期记忆等领域的潜在能力。
值得一提的是,Claude Code自身读取这份泄露代码后,明确给出了“这就是我的代码库”的判断——虽然不能作为官方佐证,但也从侧面解释了为何行业注意力会快速转向Harness架构:大家真正关心的,不是“能不能看到代码”,而是“一个成熟的AI Agent产品,其底层运行时到底长成什么样”。
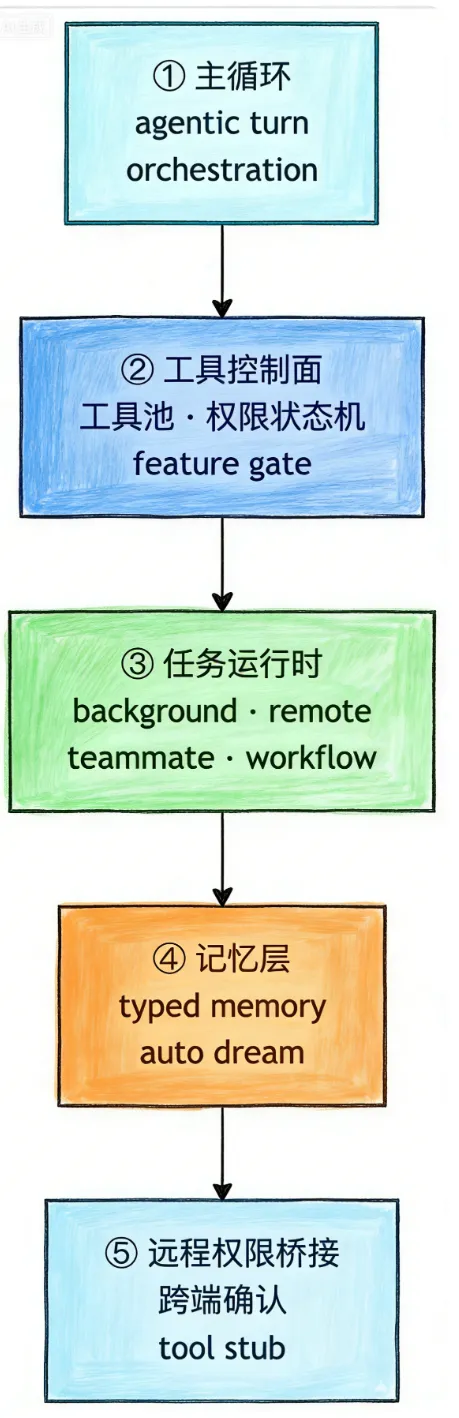
此次泄露的代码中,最具价值的并非某个隐藏功能或彩蛋,而是Claude Code已经形成的一套完整、成熟的Agent Harness架构。与传统“聊天+工具调用”的简单模式不同,这套架构已经进化为一个能独立思考、执行、记忆、跨环境协作的小型运行时系统,共分为五层,层层递进、环环相扣,覆盖了Agent运行的全流程。
从技术栈来看,Claude Code采用React + Ink构建CLI界面,运行于Bun运行时,核心是一个REPL循环,支持自然语言输入和slash命令,底层通过工具系统与LLM API交互,包含约40个工具模块、50个斜杠命令、140个界面组件,其架构设计可作为AI Agent工程化的典型参考。
很多人将Claude Code理解为“更强的终端助手”,但从`src/query.ts`文件的实现来看,其核心主循环并非传统的“用户提问-模型回答”模式,而是一套带状态的Agentic Turn(Agent回合)编排系统,这也是Harness架构的核心基础。
该主循环中集成了多个关键模块,形成了“思考-执行-恢复-迭代”的完整闭环:
-
`runTools`与`StreamingToolExecutor`:负责工具的调用与流式执行,确保工具操作的实时反馈与异常处理;
-
`tokenBudget`:Token预算管控,合理分配上下文与工具调用的Token消耗,避免超出限制;
-
`handleStopHooks`:终止钩子处理,定义Agent回合何时终止、如何优雅退出;
-
`autoCompact`与`reactiveCompact`:自动压缩与响应式压缩,当上下文过长时,自动精简冗余信息,保障运行效率;
-
`toolUseSummary`:工具使用总结,将工具执行结果整理后回写至消息流,为下一轮决策提供依据。
其运行逻辑可概括为:组装上下文→模型生成下一步动作→调用工具执行→结果回写消息流→进行预算管控与内容压缩→判断是否继续回合→直至完成任务并交付。这种设计让Claude Code不再是“被动响应”的工具,而是“主动推进”的执行主体,具备了处理长任务的能力。
如果只看`src/tools.ts`的文件名,很容易将其误解为简单的工具注册表,但结合`src/Tool.ts`一起分析会发现,Claude Code的工具系统已经进化为整个Agent架构的“控制面”,核心解决“工具如何安全、有序地被调用”的问题,包含三个关键设计:
Claude Code的工具池并非将所有工具一股脑暴露给模型,而是采用分层装配的方式,根据不同场景和权限,动态组合工具集,具体分为四类:
-
built-in tools(内置工具):基础核心工具,如文件读取、命令执行等,默认对模型可见;
-
feature-gated tools(功能开关工具):通过`KAIROS`、`AGENTTRIGGERS`、`WORKFLOWSCRIPTS`等功能开关控制,只有开启对应开关,工具才会进入工具池;
-
MCP tools(特定场景工具):针对特定业务场景设计的工具,按需加载;
-
模式专属工具:在REPL模式、coordinator mode(多Agent编排模式)下,会加载对应模式的专属工具组合。
这种设计让Claude Code的工具系统具备了极强的扩展性,可根据产品迭代需求,通过开关控制工具的上线与下线,同时避免模型接触到不必要的工具,降低误调用风险。
Claude Code的权限控制并非“事后拦截”,而是在工具池装配阶段就进行前置过滤,通过`filterToolsByDenyRules`函数,提前剔除不符合权限规则的工具,确保模型从一开始就看不到高风险工具。这种“前置塑形”的设计,从源头降低了工具误调用的风险,也体现了Anthropic对Agent安全的重视。
在`ToolPermissionContext`模块中,权限控制并非简单的“允许”或“拒绝”,而是一套完整的权限状态机,包含多个维度的状态定义:
-
`alwaysAllowRules`(永久允许规则):无需确认即可调用的工具与操作;
-
`alwaysDenyRules`(永久拒绝规则):绝对禁止调用的高风险工具与操作;
-
`alwaysAskRules`(需确认规则):调用前需用户确认的操作;
-
`isBypassPermissionsModeAvailable`(权限绕过模式)、`isAutoModeAvailable`(自动模式):权限模式切换,适配不同使用场景;
-
`prePlanMode`(预规划模式)、`shouldAvoidPermissionPrompts`(避免权限提示):优化用户体验,减少不必要的确认操作。
Anthropic在3月25日的工程博客中曾提到,用户面对大量权限确认框会产生“审批疲劳”,实际中用户会接受93%的权限提示,因此推出了Auto模式,在“完全手动确认”和“完全跳过权限”之间寻找折中。而此次泄露的代码,正是这种权限设计的具体落地,也让我们看到了Agent权限控制的精细化方向。
从`Task.ts`文件和`tasks/`目录的实现来看,Claude Code已经突破了传统CLI“单会话、单任务”的局限,构建了一套完整的任务运行时系统,将执行单元拆分为多种任务类型,适配本地、远程、后台等多种场景,核心设计亮点如下:
Claude Code定义了7种核心任务类型,每种类型对应明确的应用场景,体现了其对Agent执行能力的全面考量:
-
`local_bash`:本地命令行执行,处理本地shell操作;
-
`local_agent`:本地子Agent,负责处理本地细分任务;
-
`remote_agent`:远程Agent,在远程环境中执行任务;
-
`inprocessteammate`:进程内协作Agent(Teammate),与主Agent协同工作;
-
`local_workflow`:本地工作流,串联多个任务形成自动化流程;
-
`monitor_mcp`:持续监控任务,实时跟踪特定场景状态;
-
`dream`:记忆整理任务,后台处理长期记忆的整合与优化。
`LocalMainSessionTask`模块中明确实现了“后台会话”功能,这是典型的任务运行时设计:用户在查询过程中按两次`Ctrl+B`,当前会话会转入后台继续执行,UI则回到新的输入提示,任务完成后会主动通知用户。这种设计将前台交互与后台执行分离,既不影响用户的实时操作,又能保障长任务的持续推进。
更细致的是,后台任务的日志会单独存储在专属路径,不会与主会话日志混淆,即使用户执行`/clear`命令清空主会话,也不会影响后台任务的执行与日志留存,这一细节直接关系到长任务运行的稳定性。
`InProcessTeammateTask`并非简单的“多线程调用”,而是一套成熟的多Agent协同方案,核心设计包括:Teammate运行在同一Node.js进程内,通过AsyncLocalStorage实现状态隔离;具备团队身份标识(team-aware identity);支持预规划模式审批流程;可在空闲(idle)与活跃(active)状态之间切换。
这表明Claude Code对“多Agent”的理解已经超越了“demo级演示”,而是将其作为正式的产品能力,重点解决多Agent之间的身份、生命周期、状态切换、消息注入等核心问题,为复杂任务的协同执行提供了支撑。
在AI Agent的发展中,“记忆”一直是核心痛点——如何高效存储、整理、调用记忆,避免冗余信息占用上下文,同时保障长期记忆的有效性。此次泄露的代码中,`memdir`和`autoDream`两个模块,完整展现了Claude Code的记忆体系设计,将记忆从“聊天附属品”升级为“核心工程组件”。
`src/memdir/memdir.ts`模块的设计,核心是“让记忆更高效、更可控”,包含多个细节设计:
-
容量限制:`MEMORY.md`文件设置了明确的行数上限和字节上限,避免记忆无限膨胀,占用过多资源;
-
超限提示:当记忆容量超出限制时,系统会主动弹出警告,而非悄悄裁剪内容,确保用户知晓记忆状态;
-
主动创建:Harness会主动创建记忆目录,同时明确告知模型“目录已存在”,避免模型浪费回合去执行`mkdir`或目录探测操作,减少无效动作;
-
分类存储:采用typed memory(类型化记忆),将记忆分为用户(user)、反馈(feedback)、项目(project)、参考(reference)四类,同时明确排除可从当前项目状态直接推导的内容,确保记忆的“有用性”。
这种设计的核心逻辑是:记忆不是“第二份代码库索引”,也不是“重复的README”,而是跨会话、无法从当前状态推导、真正有价值的信息,这为Agent处理长周期任务提供了重要支撑。
`src/services/autoDream/autoDream.ts`模块被很多人解读为“AI学会做梦”,但从工程角度来看,其本质是一套克制、高效的后台记忆整理机制,核心作用是将近期积累的会话和记忆进行归拢、整合、裁剪,形成结构化记忆,不阻塞主循环。
autoDream的触发机制十分严谨,需同时满足三个条件,且按“成本最低优先”排序:
-
会话门槛:累计会话数不少于5个,确保有足够的记忆需要整理;
-
锁机制:确保同一时间只有一个进程在执行记忆整理,避免资源冲突。
更关键的是,autoDream并非在主会话中执行,而是通过fork一个子Agent(subagent)在后台运行,既不影响主循环的正常执行,又能确保记忆整理的连续性。这一设计,本质上是在解决所有长周期Agent都会面临的核心问题:如何在不打断主任务、不污染上下文的前提下,沉淀长期记忆,形成可持续的能力。
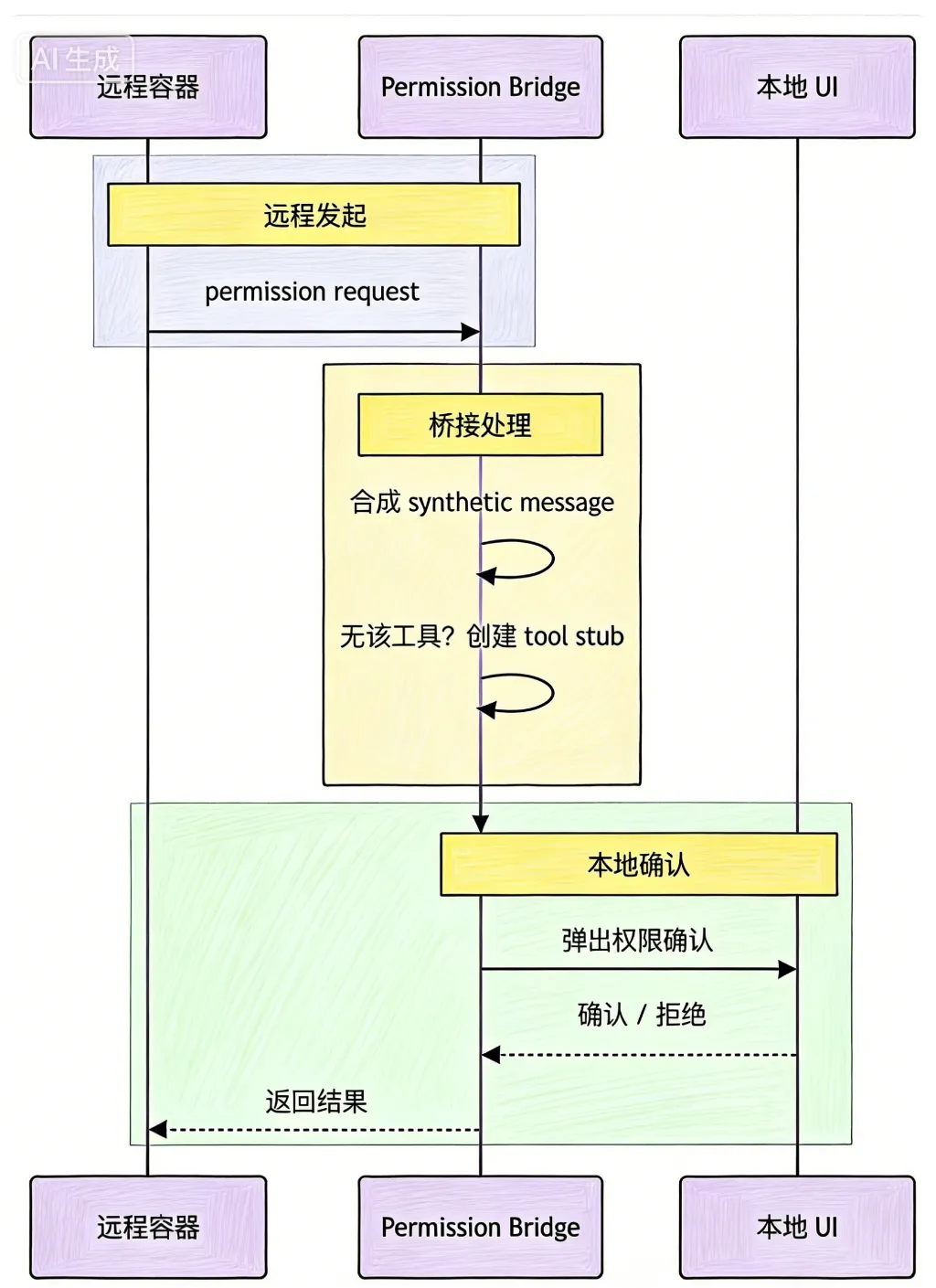
如果说前四层架构解决了“本地Agent如何高效、安全运行”的问题,那么`remotePermissionBridge`(远程权限桥)模块,则解决了“跨环境Agent如何协同”的核心问题,让Claude Code突破了“本地shell+本地文件系统”的边界,具备了跨环境执行任务的能力。
远程权限桥的核心功能看似朴素,但工程意义重大,其核心逻辑的是:将远程环境的权限请求,同步映射到本地UI进行确认,确保跨环境权限管控的一致性,具体实现包括三个关键点:
-
跨环境权限同步:远程容器中的权限请求,无法直接在本地UI展示,系统会合成一个synthetic assistant message(虚拟助手消息),将远程权限请求转化为本地可识别的形式;
-
工具适配:如果远程环境调用的工具,本地未加载,系统会自动创建一个最小化的tool stub(工具桩),承接权限确认流程,确保权限链路不中断;
-
权限一致性:无论任务在本地还是远程执行,权限规则、确认流程保持一致,避免因环境差异导致权限漂移,降低安全风险。
这一设计背后,反映的是Anthropic对Agent实际应用场景的深刻理解——未来的AI Agent不可能只在本地运行,必然需要跨环境、跨设备协同,而权限管控的一致性,正是跨环境协同的核心前提。
除了核心的五层Harness架构,此次泄露的代码中,还有两个容易被关注但又容易被误读的模块——风控机制与辅助功能,它们虽非Harness核心,但能体现Anthropic在产品细节与安全管控上的思考,也为行业提供了参考。
很多用户在使用Claude Code被封号后,会尝试通过换IP、换虚拟信用卡、换浏览器等方式规避风控,但从此次泄露的代码来看,这些手段大概率无效。因为Claude Code的风控逻辑,并非“识别用户来自哪里”,而是“识别用户是谁”,采用了多维度的身份与行为标识,形成了一套完整的风控体系。
其收集的风控数据至少包括六个维度,层层叠加,形成了难以规避的风控屏障:
-
持久设备标识:不依赖Cookie,而是通过更底层的设备ID,跨会话追踪同一物理设备;
-
账户关联:绑定邮箱、账户UUID、组织UUID,形成账户关联网络;
-
环境指纹:收集完整的操作系统信息、硬件配置、软件环境参数、系统时区等,形成设备环境画像;
-
内容指纹:从用户的消息、代码输入中提取字符特征,形成用户行为画像;
-
代码库关联:提取Git仓库远程URL的哈希值,关联用户的代码开发场景;
-
性能特征:实时监控进程的资源占用情况,辅助判断设备与用户行为的合理性。
此外,代码中还暴露了两个用户可自主控制的隐私开关,建议用户根据自身需求检查设置:
-
Location metadata(位置元数据):允许Claude使用粗略的城市/地区位置信息,用于优化产品体验;
-
Help improve Claude(帮助改进Claude):允许Anthropic使用用户的聊天和编码会话,用于模型训练与优化。
此次泄露的代码中,还有两个非核心但极具代表性的辅助模块,分别聚焦“输出控制”与“用户留存”,体现了Anthropic在产品设计上的长远考量:
这是一个Anthropic内部员工专属的安全模式,核心作用是“避免内部信息泄露”。当内部员工在公共或开源仓库操作时,该模式会自动开启,主要做三件事:剥离内部模型代号、隐藏未公开版本号、移除AI痕迹(如“Generated with Claude Code”“Co-Authored-By”等标识)。该模式默认设置为“auto”(自动开启),且无法强制关闭。
从公关角度来看,该模式存在一定争议,但从工程角度来看,它体现了Anthropic对“模型输出治理”的系统级控制,确保内部信息不会通过员工的日常操作意外泄露。
这是一套用于提升用户留存的电子宠物系统,并非Claude Code的核心功能,但设计十分细致:包含18种物种、5种稀有度(普通60%、不常见25%、稀有10%、史诗4%、传奇1%),还有1%的闪光概率,每种宠物包含调试力、耐心、混沌、智慧、嘴炮5项属性。
其生成逻辑具有确定性:通过用户ID + 固定盐值 + Mulberry32伪随机数生成器,确保同一用户永远看到同一只宠物,增强用户的归属感与长期使用意愿。这一设计也说明,Anthropic在AI Agent的产品化过程中,不仅关注技术能力,也重视用户体验与留存。
Claude Code的源码泄露风波,热闹终将过去,但它留给行业的思考与参考,却具有长远价值。此次事件最大的意义,并非“曝光了多少代码”,而是让我们看到了一个成熟AI Agent产品的工程实现全貌,也揭示了下一代AI Agent的发展方向——从“能说”到“会做”,从“简单工具调用”到“完整运行时系统”,工程细节的重要性日益凸显。
很多AI Agent产品在宣传时,会强调“安全可控”“危险提示”,但这些话术终究只是“提醒”,而非真正的安全边界。Claude Code的架构设计告诉我们:真正的安全边界,必须落地为具体的工程实现,主要体现在四个方面:
-
后台/远程任务的强制权限确认,避免无人值守时的误操作;
-
跨环境权限链路的一致性,确保无论在本地还是远程,权限管控不失效。
过去,很多团队做AI Agent,核心精力放在Prompt优化上,但Claude Code的代码表明,当Agent走向成熟,核心经验会从Prompt慢慢外溢到系统层。此次泄露的代码中,最有价值的并非Prompt文本,而是tool pool(工具池)、task runtime(任务运行时)、permission context(权限上下文)、memory pipeline(记忆流水线)、remote bridge(远程桥)这些工程组件——它们才是Agent稳定运行的核心支撑。
同时,Claude Code的架构也为从事Agent开发的团队,提供了四个关键启示:
-
客户端策略不能作为最终安全边界:客户端可以做提示、过滤、约束,但高风险能力的管控,必须依赖后端与系统层的硬限制;
-
长任务与多Agent需配套隔离设计:background session、Teammate、远程Agent等能力虽强,但必须配套清晰的状态模型、独立日志、生命周期管理与回收机制,否则系统会变得难以预测;
-
记忆体系需做工程化设计:不能将记忆视为“附属品”,需设置容量限制、分类存储、后台整理机制,让记忆真正为长任务服务;
-
安全讨论终将回归工程细节:未来评估一个AI Agent的安全性,不会只看demo或模型榜单,更会关注其任务循环、工具池装配、权限状态机、记忆治理、远程桥接等底层工程细节。
结合Claude Code的架构设计与此次泄露事件的教训,针对AI Agent开发团队与开发者,给出5条可落地的实践建议,帮助规避风险、优化架构:
-
npm包发布前,务必剔除source map、调试日志等敏感文件,建立严格的打包审核流程,避免类似的泄露事件;
-
Agent架构设计中,优先构建权限状态机,采用“前置过滤”的权限管控模式,明确高风险工具的调用规则,避免权限漂移;
-
长任务开发中,分离前台交互与后台执行,为后台任务设计独立的日志存储路径,确保任务稳定性与可追溯性;
-
记忆体系设计时,采用类型化存储、容量限制、后台异步整理的方式,减少无效记忆对上下文的占用,提升Agent执行效率;
-
涉及远程执行的Agent,需建立完善的远程权限桥接机制,确保跨环境权限管控的一致性,避免远程操作的安全风险。
Claude Code的源码泄露,与其说是一次“失误”,不如说是一次行业“福利”——它让我们提前看到了成熟AI Agent的工程实现全貌,也让整个行业意识到:AI Agent的竞争,早已从“模型能力”延伸到“工程架构”。
未来的AI Agent,将不再是“只会聊天的工具”,而是“会动手、能思考、可协同、够安全”的运行时系统。它们的价值,不仅在于模型的强大,更在于工程细节的严谨——边界是否清晰、状态是否稳定、约束是否生效、恢复路径是否完善,这些看似琐碎的工程细节,终将决定一个Agent的上限。
Claude Code此次站在了聚光灯下,但它照出来的问题,是所有做Agent的团队都需要面对的:我们到底有没有把Agent的工程边界,从产品文案,真正做成可落地、可验证的系统实现。而这,正是此次风波留给行业最珍贵的思考。
终身学习 专注AI分享
深耕AI领域,探索・实践
欢迎关注,期待同行
 夜雨聆风
夜雨聆风