【白话】深度解析Claude Code源码记忆模块:影子Agent+KAIROS机制
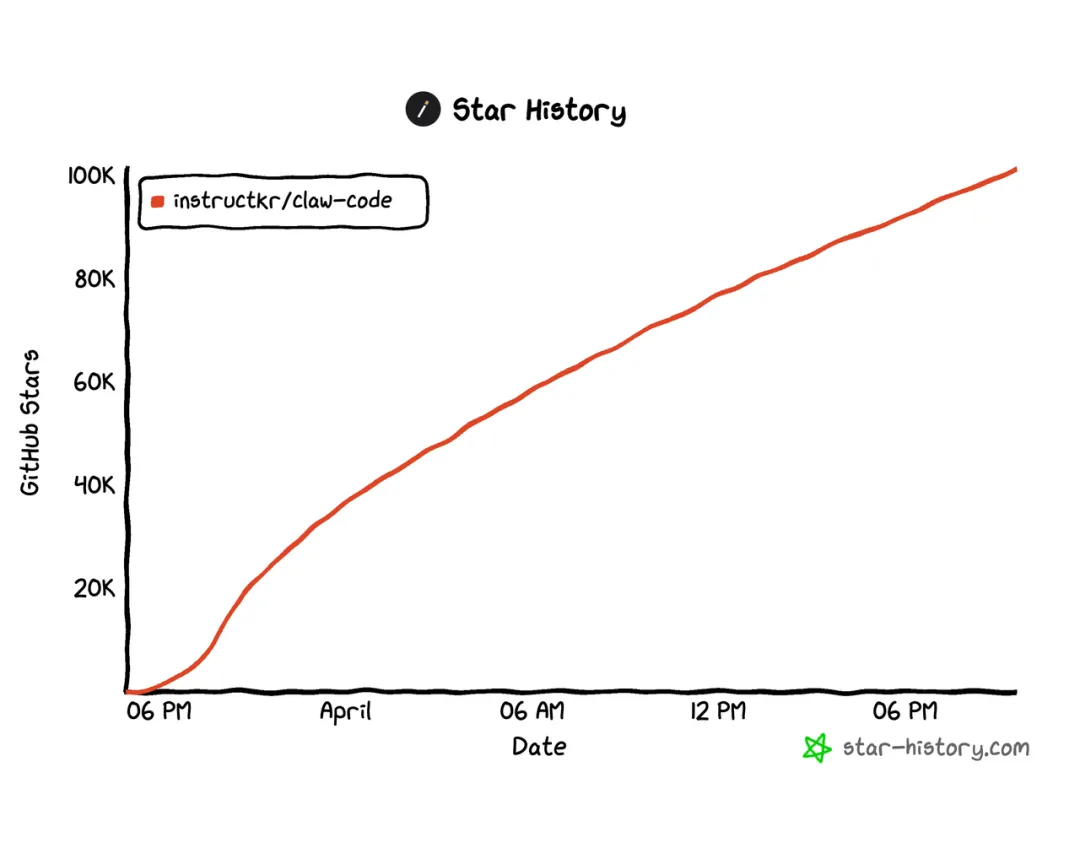
这两天 Claude Code 被 “被迫开源” 的消息热度很高,两天时间star已经升至101k,对做 AI Agent 的人而言,这无疑是一份送上门的标准答案。 出于好奇,我把整套源码完整梳理了一遍,内容体量极大,单篇很难讲透。 今天先聚焦大家普遍关注的记忆模块,它依靠三个核心技术决策,既规避了记忆爆炸问题,也避免了因遗忘导致系统失效。内容有点儿多,可以先收藏~ 先稍微赘述一下memory记忆模块干的事情:简单说主要是解决每次开新session都要重新解释项目背景的烦躁感; 可以让我们不用每次都对着AI反反复复的说我们的一些通用诉求,比如 “我是后端工程师,用TypeScript,主要做React Native移动端——好了Claude,我们继续上次的工作。” 因此我们需要agent具有记忆,这才是Claude Code真正花大力气解决的问题。 大模型没有状态。每次`send`都是白纸一张。Claude Code的解法是:把记忆写成磁盘上的Markdown文件,每次对话开始时读进来,塞进System Prompt 。
主Agent一边回答一边写记忆,和后台提取记忆,会不会重复劳动?
团队共享记忆时,如何防止有人把API Key也传上去?
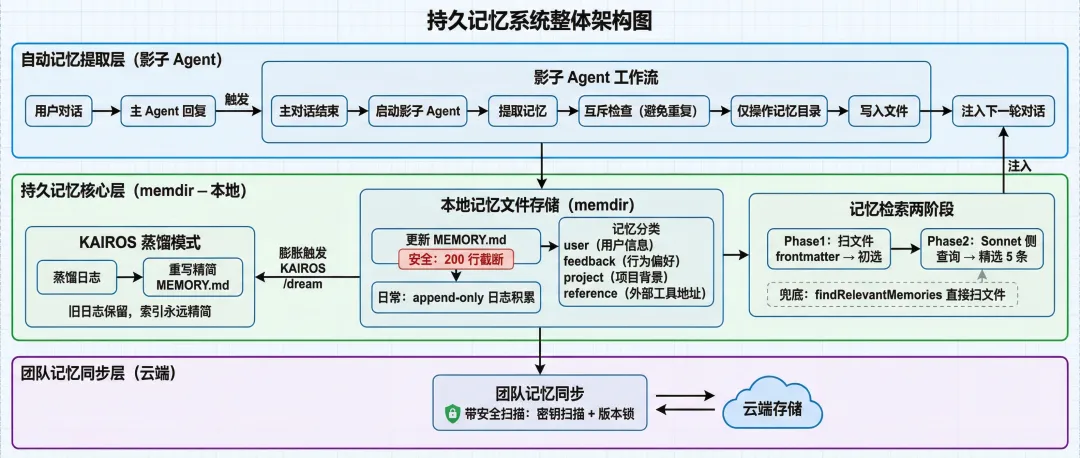
记忆系统采用三层架构设计,核心实现“文件存储、自动提取、云端同步”的全流程记忆管理,具体分层及细节如下:
一、持久记忆核心层(memdir/,基于本地文件系统)
作为整个记忆系统的“数据底座”,负责本地记忆的存储、解析、检索与基础管理,所有记忆最终以文件形式沉淀于此;
二、自动记忆提取层(services/extractMemories/,后台影子Agent)
作为记忆的“自动采集器”,由后台影子Agent(智能代理)负责,无需手动操作,自动从相关场景中提取可复用记忆;
三、团队记忆同步层(services/teamMemorySync/,云端同步)
作为团队记忆的“协同桥梁”,负责本地团队记忆与云端的同步,保障多成员、多设备间的记忆一致性; 三层职责分离: 存储的是文件, 写入的是影子Agent, 同步 的是团队云端。这三个层次互相配合,又各自独立演化 。
记忆系统三层结构 ├── memdir/ # 持久记忆核心层(本地文件系统) │ ├── paths.ts # 路径解析与安全校验 │ ├── memdir.ts # Prompt 构建与截断保护 │ ├── memoryTypes.ts # 四种记忆分类 + 内置 Prompt 文本 │ ├── memoryScan.ts # 记忆文件扫描(frontmatter(记忆文件前面有一小段"目录卡") 读取) │ ├── findRelevantMemories.ts # 相关记忆检索(模型侧查询) │ ├── memoryAge.ts # 记忆时效性管理 │ ├── teamMemPaths.ts # 团队记忆路径管理 │ └── teamMemPrompts.ts # 团队/个人合并 Prompt 构建 │ ├── services /extractMemories/ # 自动记忆提取层(后台影子 Agent) │ ├── extractMemories.ts # 提取引擎 │ └── prompts.ts # 提取 Agent 的专用 Prompt │ └── services /teamMemorySync/ # 团队记忆同步层(云端同步) ├── index.ts # 同步核心(pull/push/ETag 管理) ├── watcher.ts # 文件变更监听器(fs.watch) ├── secretScanner.ts # 上传前秘钥扫描 └── teamMemSecretGuard.ts # 秘钥防泄漏守卫
Claude Code强制将记忆分为四种类型,每种有明确的边界和写入规范: 记忆口诀:”我是谁(user)/怎么做(feedback)/在干嘛(project)/去哪找(reference)”
代码和git历史里看不出来的 项目背景:谁在做什么、为什么、截止日期
外部系统的 地址和用途 :Linear项目、Slack频道、内部看板
用户说”pipeline的bug在Linear INGEST项目跟踪”
这个分类法,它解决了一个实际问题: 让Claude知道什么值得写进记忆,什么读代码就能知道 。 Prompt里明确告知Claude:代码模式、架构、Git历史、commit message,这些都不值得记 ,因为工具本身就带着这些信息。 只有代码里看不出来的才值得写下来。 user 和 feedback 这两个记忆相对好理解,我们对 project 和 reference 做进一步的解释: 存的是当前项目的来龙去脉和现状,不是代码怎么写的技术细节。 存的是去哪里查,而不是信息本身。外部系统(Linear、Grafana、Slack、内部Wiki)里的内容会不断变化,Claude没法把它们的实时状态存进记忆,能存的是这类信息在那个系统的哪个位置 。 下次遇到相关问题,Claude知道往哪里找,而不是凭记忆直接给出可能过时的答案。
MEMORY.md 截断保护 —`truncateEntrypointContent()`
这里简单提一下大家已经说过比较多的 MEMORY.md 200行限制,工作逻辑如下:
文件超 200 行 → Claude 只显示前 200 行并弹出警告
理想情况:Claude 主动精简、合并、删除过时内容
export const MAX_ENTRYPOINT_LINES = 200 // 最多 200 行 export const MAX_ENTRYPOINT_BYTES = 25 _000 // 最多 25000 字节
> WARNING: MEMORY.md is 247 lines ( limit : 200). Only part of it was loaded. Keep index entries to one line under ~200 chars; move detail into topic files.
当然被截断后的MEMORY.md还是会有额外的兜底机制,保证记忆被截断后不至于完全失忆,以下是兜底逻辑: 即使 MEMORY.md 超过 200 行后面的条目被截掉, findRelevantMemories() 仍然能找到对应的具体记忆文件。它直接扫描文件系统,不依赖 MEMORY.md 索引。会直接扫描文件,绕过 MEMORY 的 200 行限制,仍能找到相关记忆。 代码里没有任何自动删除旧记忆的逻辑 。管理 MEMORY.md 的责任完全压在 Claude 的判断力上,靠 Prompt 指令约束行为。 设计哲学 :Anthropic 赌 Claude 足够聪明,看到”索引已截断”警告后会主动整理,而不是无限堆砌,用 LLM 智能替代硬性算法,灵活但无法保证一致性。
通俗理解: 想象有一个后台记忆秘书,它在你每次和Claude聊完天后,悄悄阅读对话记录,帮你把重要信息整理成笔记。这个秘书完全后台运行,不耽误你继续聊天。
每一个完整的查询循环结束时(即主模型产出最终回复、且本轮没有剩余工具调用时), 一个影子Agent在后台悄然启动 ,专门负责从这轮对话中提取可能值得记住的内容。 Claude Code的做法是: 主Agent和影子Agent共享同一份System Prompt和对话历史 (称为”完美Fork”),影子Agent在后台以相同的模型配置运行,完全不干扰主Agent的响应。
互斥机制:防止主Agent和影子Agent重复劳动
如果主Agent已经在对话中主动写过记忆文件,影子Agent会检测到这一点(通过扫描`tool_use`块里的文件路径),然后主动放弃本轮提取 。 两个Agent永远不会写同一轮对话的记忆,互斥,不重复,不遗漏。 如果用户连续快速发消息,影子Agent可能还在处理第一轮,此时第二轮对话已经结束。Claude Code的做法是: 把最新上下文暂存起来 ,等当前提取完成后,立即触发一次补充提取,确保中间轮次不被跳过。 这是个安全设计:影子Agent的工具权限被严格限制。 这个权限矩阵确保影子Agent即使被Prompt注入攻击,也无法把记忆目录之外的东西写进去。 把所有记忆都塞进对话不现实。Claude Code用了两阶段检索:
Phase 1 :scanMemoryFiles() → 读取每个记忆文件的前 30 行以解析frontmatter(name/description/ type ) → 自动排除MEMORY.md(它已通过System Prompt注入,不参与检索) → 按修改时间倒序,最多返回 200 个文件 Phase 2 :sideQuery(Sonnet) → 用Sonnet判断哪些记忆和当前问题真正相关 → 保守策略:只选 "明显有用" 的,最多 5 个 → 相关记忆 → Attachment Message注入主对话
通俗理解: 记忆文件前面有一小段”目录卡”(frontmatter),写着这是哪种记忆、什么时候记的。检索时先快速扫目录卡,过滤掉无关的;再用Sonnet做第二轮判断,确保只拉取真正有用的进来。
这个设计省了大量Token。先用模型做初筛,确保只有真正相关的记忆才进入主模型的上下文窗口。
通俗理解: 普通模式像每次聊完天就写笔记,时间久了笔记本越来越厚。KAIROS模式换了个策略,平时只写日记(append-only日志),定期找时间做一次精华提炼,把日记整理成 精简版笔记本 。日记本越来越厚没关系,反正查资料时先去翻精华版,需要细节再去日记里找。
普通模式下,影子Agent负责将每轮对话中值得保留的内容提取并写入独立的记忆文件,再在`MEMORY.md`里更新索引,长期使用后`MEMORY.md`越来越长,超过 200行或25,000字节 (两个限制,任一触发即截断)后,Claude只能看到前半部分,后面的内容对主模型不可见 。 Claude Code没有用自动删除策略。它的解法是:KAIROS模式 。
KAIROS模式(长会话/助手模式专用): 平时:对话内容 → 追加写入日志文件 logs/YYYY/MM/YYYY-MM-DD.md( append - only ,永不修改) MEMORY.md由单独的蒸馏步骤维护,不在平时直接编辑 autoDream自动触发条件:距上次整理 ≥ 24 小时 AND 积累了 ≥ 5 个session /dream技能手动触发:蒸馏所有日志 → 重写MEMORY.md → MEMORY.md永远是精华版
日志是append-only的,不做修改,只做积累。蒸馏时把日志里的重要信息提炼出来,重写MEMORY.md。 索引文件永远保持精简,细节在日志里,需要时通过`findRelevantMemories`检索。 这里的设计哲学同样是用LLM的智能代替硬性算法 。不是写个定时任务自动删旧记忆,而是让Claude自己判断什么值得保留,然后用一套蒸馏流程重建索引。 在团队场景下,记忆文件会同步到云端(GitHub repo关联)。这里有一个巨大风险,有人不小心把API Key写进记忆文件,然后同步到团队云端 。
第一层:上传前扫描。 同步前自动检测密钥、私钥等敏感内容,只提示违规,不泄露明文。
第二层:版本锁防冲突。 类似在线文档机制,多人同时修改时,避免内容被覆盖,提交失败会自动重试。
不过话说回来,不知道Claude Code这次被迫开源,有没有走这套逻辑~ Claude Code记忆系统的核心设计哲学是相信模型足够聪明 。 但用LLM智能替代硬性算法也有代价,那就是灵活但无法保证一致性 。 Anthropic赌的是Claude的判断力足够好,对于Memory的更删改主要依赖模型能力来进行。 Claude Code的记忆系统,真正值得借鉴的不是某个具体实现,而是一个系统设计的思路:把存储、执行、检索三层解耦;用影子Agent分离关注点;用append-only日志+蒸馏解决膨胀问题;用权限矩阵控制安全风险。 AI Agent的记忆问题,本质上是一个 工程问题, 而不是一个模型问题 。需要一个好的记忆架构,让模型每次都能想起来需要的东西。
 夜雨聆风
夜雨聆风