 夜雨聆风
夜雨聆风





ClaudeCode源码解读:深入Memory设计
上一篇聊了 Claude Code 的上下文工程——System Prompt 的”正确海拔”、CLAUDE.md 的层级加载、对话历史的精简策略。这一篇往更有意思的方向走:它是如何在多次会话之间持续学习、记住你这个人的?
引言:AI 编程助手的”失忆症”
用过多款 AI 编程助手的人大概都有同一个体验:每次打开新对话,它就像失忆了一样,什么都不认识你了。你上次花了十分钟解释的”我们项目不用 mock 测试”,这次还得再说一遍。
这是 LLM 的架构特性决定的——模型没有跨会话的持久状态。早期的做法是让用户手动维护一个”规则文件”(比如 Claude Code 的 CLAUDE.md),每次会话时加载进来。这固然有效,但有个本质缺陷:它要求人记得写。
真实情况是,大量有价值的上下文信息是在对话过程中自然流露的:一次纠正(”别用 sed,用 awk”),一个偏好(”PR 描述要短,不要列所有改动”),一个背景(”下周五之前这个模块要冻结代码”)。没有人会在对话结束后专门去更新 CLAUDE.md。
Claude Code 的 Memory 系统就是为了解决这个问题:让 AI 自己学习、自己记录、自己在下次会话时回忆起来。
一、两层持久化:CLAUDE.md 与 Auto Memory 的分工
理解 Claude Code 的 Memory 设计,首先要厘清它不是一个单一系统,而是两层机制的组合。
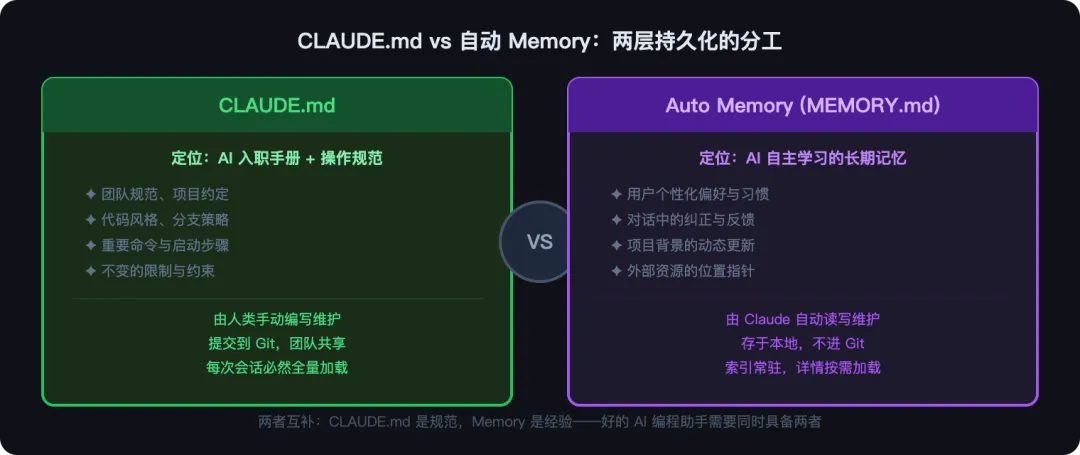
CLAUDE.md 是”AI 入职手册”。它由人类手动编写,提交到 Git,对整个团队生效。内容是相对稳定的项目规范:代码风格、分支策略、重要的约束和禁令。每次会话都必然全量加载。
Auto Memory(MEMORY.md + 话题文件)是”AI 的学习日记”。它由 Claude 自己维护,存于本地,不进 Git。内容是动态积累的个性化经验:用户偏好、对话中的纠错、项目背景的变化。索引常驻上下文,详细内容按需拉取。
两者的分工很清晰:CLAUDE.md 是规范,Memory 是经验。一个优秀的人类工程师需要同时具备公司规范手册和多年工作经验,Claude Code 也用同样的双层结构来模拟这一点。
二、存储设计:文件系统作为数据库
Claude Code 的 Memory 使用纯文件系统存储,没有任何数据库,没有向量索引,没有嵌入(embedding)。这是个刻意的设计选择,值得深入看。
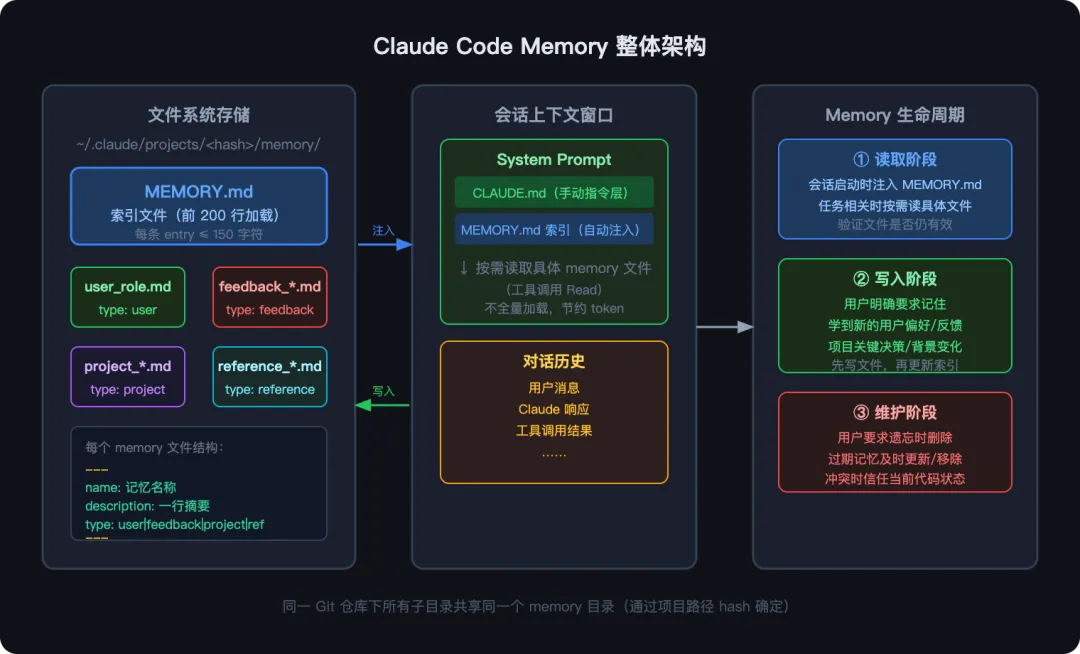
存储位置与路径计算
所有 memory 文件存放在:
~/.claude/projects/<sanitized-git-root>/memory/路径计算的关键在两处:一是规范化 Git 根目录,二是对路径做安全处理。来看源码(src/memdir/paths.ts):
// 获取规范 Git 根(所有 worktree 共享同一 memory 目录)function getAutoMemBase(): string { return findCanonicalGitRoot(getProjectRoot()) ?? getProjectRoot()}// 构造完整的 memory 目录路径export const getAutoMemPath = memoize( (): string => { const override = getAutoMemPathOverride() ?? getAutoMemPathSetting() if (override) { return override } const projectsDir = join(getMemoryBaseDir(), 'projects') return ( join(projectsDir, sanitizePath(getAutoMemBase()), AUTO_MEM_DIRNAME) + sep ).normalize('NFC') }, () => getProjectRoot(),)
路径中的 sanitizePath 并非随机哈希,而是将路径里的所有非字母数字字符替换为连字符,超出文件系统长度限制时才在末尾追加哈希(src/utils/sessionStoragePortable.ts):
export function sanitizePath(name: string): string { const sanitized = name.replace(/[^a-zA-Z0-9]/g, '-') if (sanitized.length <= MAX_SANITIZED_LENGTH) { return sanitized } // 路径过长时截断并追加哈希保证唯一性 const hash = typeof Bun !== 'undefined' ? Bun.hash(name).toString(36) : simpleHash(name) return `${sanitized.slice(0, MAX_SANITIZED_LENGTH)}-${hash}`}
因此,/Users/alice/my-project 对应的 memory 目录会是:
~/.claude/projects/-Users-alice-my-project/memory/同一 Git 仓库下的所有子目录和 worktree 共享同一个 memory 目录——这是用 findCanonicalGitRoot 实现的,所以你在 backend/ 子目录里教给 Claude 的知识,它在 frontend/ 里也能用到。
两级结构:索引 + 话题文件
Memory 系统采用了一个极其简洁的”索引 + 详情“模式:
MEMORY.md 是唯一的索引文件。每条记录一行,不超过 150 字符,格式统一:
- [记忆名称](文件名.md) — 一句话描述这条记忆的核心内容话题文件(如 user_role.md、feedback_testing.md)存放具体内容。每个文件有标准的 frontmatter 头:
---name: 记忆名称description: 一行摘要(决定未来会话中是否判断相关)type: user | feedback | project | reference---正文内容……
name 和 description 字段的设计非常关键:它们的功能是让 Claude 在加载了索引但还没读详情时,就能判断”这条记忆和当前任务相关吗”。这是一个典型的两阶段检索设计:先看摘要决定是否相关,再读全文获取细节。
三、容量上限与截断逻辑
这是源码里最值得细看的一处实现细节。MEMORY.md 有两个并行的上限(src/memdir/memdir.ts):
export const ENTRYPOINT_NAME = 'MEMORY.md'export const MAX_ENTRYPOINT_LINES = 200// ~125 chars/line at 200 lines. At p97 today; catches long-line indexes that// slip past the line cap (p100 observed: 197KB under 200 lines).export const MAX_ENTRYPOINT_BYTES = 25_000
注释里的 “p97″、”p100 observed: 197KB” 是生产观测数据——他们发现有人写了不到 200 行、但每行超级长导致总大小达到 197KB 的索引,所以加了字节上限作为兜底。
截断函数 truncateEntrypointContent 的逻辑也很精巧:
export function truncateEntrypointContent(raw: string): EntrypointTruncation { const trimmed = raw.trim() const contentLines = trimmed.split('\n') const lineCount = contentLines.length const byteCount = trimmed.length const wasLineTruncated = lineCount > MAX_ENTRYPOINT_LINES // 先检查原始字节数——长行是字节上限要处理的问题, // 行截断后的大小会低估警告的必要性。 const wasByteTruncated = byteCount > MAX_ENTRYPOINT_BYTES // ... 先按行截断,再按字节截断(在最近的换行处切断,不切半行) let truncated = wasLineTruncated ? contentLines.slice(0, MAX_ENTRYPOINT_LINES).join('\n') : trimmed if (truncated.length > MAX_ENTRYPOINT_BYTES) { const cutAt = truncated.lastIndexOf('\n', MAX_ENTRYPOINT_BYTES) truncated = truncated.slice(0, cutAt > 0 ? cutAt : MAX_ENTRYPOINT_BYTES) } // 截断后追加警告,说明是哪个上限触发的 return { content: truncated + `\n\n> WARNING: ${ENTRYPOINT_NAME} is ${reason}. Only part of it was loaded...`, // ... }}
两个上限各自独立检测,字节截断时从末尾往前找最近的换行符,确保不切断半行。触发哪个上限,追加不同的警告文字告诉 Claude——这说明设计者认真考虑了”让 AI 知道自己的信息被截断了”这件事。
开关的优先级链
Memory 可以被多种方式关闭,优先级链如下(src/memdir/paths.ts):
export function isAutoMemoryEnabled(): boolean { // 1. 环境变量(最高优先级) const envVal = process.env.CLAUDE_CODE_DISABLE_AUTO_MEMORY if (isEnvTruthy(envVal)) return false if (isEnvDefinedFalsy(envVal)) return true // 2. --bare 模式(精简模式,关闭 memory) if (isEnvTruthy(process.env.CLAUDE_CODE_SIMPLE)) return false // 3. 远程模式但没有配置持久化存储目录 if (isEnvTruthy(process.env.CLAUDE_CODE_REMOTE) && !process.env.CLAUDE_CODE_REMOTE_MEMORY_DIR) return false // 4. settings.json 中的配置(项目级可选退出) const settings = getInitialSettings() if (settings.autoMemoryEnabled !== undefined) return settings.autoMemoryEnabled // 5. 默认:开启 return true}
值得注意的安全细节:autoMemoryDirectory(自定义 memory 路径)只能通过 policySettings、localSettings、userSettings 设置,刻意排除了 projectSettings(即提交到仓库的 .claude/settings.json)。原因直接写在注释里:恶意仓库可能设置 autoMemoryDirectory: "~/.ssh" 来获取对敏感目录的写权限。
四、四种 Memory 类型:覆盖不同维度的经验

Memory 系统将经验分成四个语义维度(src/memdir/memoryTypes.ts):
export const MEMORY_TYPES = [ 'user', 'feedback', 'project', 'reference',] as const
user — 关于这个人是谁
存储用户的角色、专业背景和偏好。核心问题是:”我应该以什么方式跟这个人协作?”
---name: 用户背景description: 用户是 Go 老手,React 新手type: user---用户有十年 Go 开发经验,但这是他第一次接触这个项目的 React 前端。解释前端代码时,应使用 Go 的类比(组件 ≈ 结构体,Hook ≈ 中间件)。
触发时机:用户介绍自己的背景,或透露出明显的经验层次差异。用途是调整解释深度和术语选择。值得注意:user 记忆只存有助于协作的正向信息,不记录对用户的负面评价——避免 AI 在记忆里给用户贴负面标签。
feedback — 关于怎么干活
这是使用频率最高、也最重要的类型。存储被纠正的做法和被确认的非常规选择。
设计要求 feedback 记忆必须包含三个部分:
规则本身(做什么/不做什么)**Why:** 背后的原因(为什么这条规则成立)**How to apply:** 触发时机(什么情况下这条规则生效)Why 字段是精髓所在。纯粹的规则列表会导致死板执行,有了原因,遇到边界情况时才能灵活判断。比如:
不要在这些测试里 mock 数据库**Why:** 上季度 mock 测试全过、但 prod migration 失败的事故,根因是 mock 与 prod 行为不一致**How to apply:** 所有集成测试,包括新增功能的测试另一个关键设计:不只记录纠错,也记录被认可的非常规做法。如果用户没有对某个特殊选择提出异议,说明这个方向是被接受的——这条经验同样值得记录,否则 AI 只有”避免犯错”的记忆,没有”什么方向是对的”的经验。
project — 关于这个项目的动态状态
存储正在进行的工作、关键决策和业务约束。这类记忆有个重要特性:衰减快。
设计上要求相对时间必须转换为绝对时间(”下周五” → “2026-04-10″)。三个月后你回来问 AI,”下周五”已经毫无意义,而绝对日期能让 AI 判断这条记忆是否已经过期。
reference — 关于去哪里找信息
存储外部资源的位置:Jira/Linear 项目、Grafana 仪表盘、Slack 频道、关键文档 URL。本质是指针,记录的是”去哪里找”,而不是把内容复制进来。
五、什么不该存:设计的约束边界
Memory 系统有一份明确的”禁止列表”,这是设计中同等重要的部分:
|
|
|
|---|---|
|
|
|
|
|
git log
git blame 是权威来源 |
|
|
|
|
|
|
|
|
|
核心逻辑是:只有那些”代码或 git 里找不到、但跨会话有价值”的信息,才值得占用 memory 空间。
六、索引模式的工程权衡
200 行 / 25KB 的索引上限,是这个设计里最值得品味的决策。
为什么不全量加载所有 memory?
Context window 是有限的注意力预算,无差别地注入所有 memory 不仅消耗 token,还会稀释模型对真正相关内容的注意力。一个积累了几十条记忆的长期项目,如果每次对话都把全部历史 memory 塞进去,可能反而比没有 memory 效果更差。
为什么不用向量检索?
向量数据库(RAG)方案可以做语义相似度检索,在大量记忆中精确找到相关条目。但它也带来了额外的复杂度:需要 embedding 模型、向量存储、相似度计算。
Claude Code 的选择是:用 LLM 本身来做”检索”。具体实现在 src/memdir/findRelevantMemories.ts:
const SELECT_MEMORIES_SYSTEM_PROMPT = `You are selecting memories that will be useful to Claude Code as it processes a user's query. You will be given the user's query and a list of available memory files with their filenames and descriptions.Return a list of filenames for the memories that will clearly be useful to Claude Code as it processes the user's query (up to 5). Only include memories that you are certain will be helpful based on their name and description.- If you are unsure if a memory will be useful in processing the user's query, then do not include it in your list. Be selective and discerning.- If a list of recently-used tools is provided, do not select memories that are usage reference or API documentation for those tools (Claude Code is already exercising them). DO still select memories containing warnings, gotchas, or known issues about those tools — active use is exactly when those matter.`export async function findRelevantMemories( query: string, memoryDir: string, signal: AbortSignal, recentTools: readonly string[] = [], alreadySurfaced: ReadonlySet<string> = new Set(),): Promise<RelevantMemory[]> { const memories = (await scanMemoryFiles(memoryDir, signal)).filter( m => !alreadySurfaced.has(m.filePath), ) if (memories.length === 0) return [] // 用 Sonnet 从所有 memory header 中选出最相关的(最多 5 条) const selectedFilenames = await selectRelevantMemories( query, memories, signal, recentTools, ) // ...}
一个有意思的细节:如果 Claude 最近刚用过某个工具(比如 MCP 的某个工具),那个工具的参考文档类记忆就不会被选中——因为”Claude 已经在用它了,这时候把文档推进去是噪声”,但如果记忆里包含那个工具的警告和已知问题,则依然会被选中。
七、后台提取 Agent:记忆是怎么写入的
Memory 的写入有两条路径。主路径:Claude 在对话中自己判断并调用 Write 工具写文件。后台路径:每次对话结束时,系统会启动一个后台提取 Agent(src/services/extractMemories/extractMemories.ts):
/** * 在每次完整的 query loop 结束时运行(模型产出最终响应且无工具调用时)。 * 使用 forked agent 模式——复刻主对话,共享 prompt cache。 */两条路径互不干扰的机制是 hasMemoryWritesSince:
function hasMemoryWritesSince( messages: Message[], sinceUuid: string | undefined,): boolean { // 扫描主 agent 的消息,看是否已经写过 memory 目录里的文件 for (const message of messages) { // ... for (const block of content) { const filePath = getWrittenFilePath(block) if (filePath !== undefined && isAutoMemPath(filePath)) { return true // 主 agent 已写,后台跳过 } } } return false}后台提取 Agent 有严格的权限限制:只能用 Read/Grep/Glob 读取文件,Bash 只允许只读命令(ls、cat、find 等),Write/Edit 只能操作 memory 目录内的文件,其他任何写操作一律拒绝。
八、记忆新鲜度:内建的时间衰减机制
这是原文章没有覆盖、但非常有意思的一个机制。每条 memory 文件都有 mtime(修改时间),系统会实时计算记忆的”年龄”并附上警告(src/memdir/memoryAge.ts):
/** * 人类可读的年龄字符串。 * 模型在日期运算上表现差——"47 days ago" 比一个原始 ISO 时间戳 * 更容易触发模型的过期推理。 */export function memoryAge(mtimeMs: number): string { const d = memoryAgeDays(mtimeMs) if (d === 0) return 'today' if (d === 1) return 'yesterday' return `${d} days ago`}/** * 超过 1 天的记忆追加过期警告。今天/昨天的记忆不加——加了是噪声。 * * 设计动机:用户反馈陈旧的代码状态记忆(file:line 引用到已改动的代码) * 被当作事实断言——引用格式反而让过期的说法听起来更权威。 */export function memoryFreshnessText(mtimeMs: number): string { const d = memoryAgeDays(mtimeMs) if (d <= 1) return '' return ( `This memory is ${d} days old. ` + `Memories are point-in-time observations, not live state — ` + `claims about code behavior or file:line citations may be outdated. ` + `Verify against current code before asserting as fact.` )}
注释里的”用户反馈”说明了这个设计的直接来源:生产环境里有人因为 Claude 引用了过期的 file:line 信息而受到误导,带引用格式的陈旧说法比不带引用的更有欺骗性——所以加了这个强制警告。
九、DIR_EXISTS_GUIDANCE:一个微小但有趣的优化
buildMemoryLines 函数在生成系统提示时,会注入这样一段文字:
export const DIR_EXISTS_GUIDANCE = 'This directory already exists — write to it directly with the Write tool (do not run mkdir or check for its existence).'这么一句话,背后的设计理由是:Claude 在写文件前有时会先 ls 检查目录是否存在,然后再 mkdir -p,浪费一到两轮工具调用。系统在每次会话启动时通过 ensureMemoryDirExists 保证目录已经存在,然后在 Prompt 里直接告诉 Claude “目录已存在,直接写”,省掉了冗余的探索步骤。
十、Memory 注入系统提示的全链路
把所有环节串起来看,memory 进入系统提示的完整路径如下(src/constants/prompts.ts):
systemPromptSection('memory', () => loadMemoryPrompt()),loadMemoryPrompt() 内部的分发逻辑:
-
检查是否启用了 KAIROS 模式(长会话的日志模式,见下文) -
检查是否启用了 TEAMMEM(团队共享 memory) -
普通模式:调用 buildMemoryLines,读取MEMORY.md,截断到双上限,注入系统提示
整个过程是同步读文件(因为 System Prompt 的构建是同步的),并通过 systemPromptSection 的缓存机制保证每次会话只构建一次。
附:KAIROS 模式——长会话的日志变体
源码里还有一个目前通过 feature flag 灰度的实验性变体,叫 KAIROS 模式,专为”长期存活的助手会话”设计。
普通 Memory 的问题在于,长会话中频繁更新 MEMORY.md 会造成写冲突和频繁重组。KAIROS 模式改变了写入范式:
function buildAssistantDailyLogPrompt(): string { // ... const logPathPattern = join(memoryDir, 'logs', 'YYYY', 'MM', 'YYYY-MM-DD.md') return [ // ... "This session is long-lived. As you work, record anything worth remembering by **appending** to today's daily log file:", `\`${logPathPattern}\``, "Write each entry as a short timestamped bullet. Create the file (and parent directories) on first write if it does not exist. Do not rewrite or reorganize the log — it is append-only.", "A separate nightly process distills these logs into `MEMORY.md` and topic files.", // ... ].join('\n')}
变化很明显:Claude 不再直接维护 MEMORY.md,而是只追加写入每日日志文件(logs/2026/04/2026-04-01.md),由一个独立的夜间蒸馏进程(/dream)定期将日志汇总成 MEMORY.md 和话题文件。
追加写入天然不冲突,日期滚动时自动开新文件,完全回避了长会话中的写竞争问题。
结语
Claude Code 的 Memory 系统没有用任何”高级”技术:没有向量数据库,没有嵌入模型,没有复杂的检索算法。它的核心是几个朴素的设计决策的组合:
- 文件系统 + Markdown
,完全透明可编辑 - 索引 + 详情的两阶段结构
,平衡常驻 token 与信息完整性 - 双上限截断
(行 + 字节),来自真实生产数据的观测 - 四种语义类型
,覆盖”人、方法、项目、资源”四个维度 - 后台提取 Agent +
hasMemoryWritesSince去重
,两路写入互不干扰 - 时间新鲜度警告
,防止陈旧记忆被当作事实 - LLM 充当检索引擎
,Sonnet 从 header 列表中选出最相关的条目
每一处看似简单的实现背后,都有具体的生产问题驱动:截断上限来自 “197KB 索引” 的实际观测,时间警告来自用户反馈的 “陈旧 file:line 误导” 问题,DIR_EXISTS_GUIDANCE 来自节省冗余工具调用的工程考量。
这套设计的价值不在于技术复杂度,而在于对 LLM 工作方式的深刻理解:什么信息应该常驻,什么信息按需拉取,什么信息根本不需要存。Context window 是有限的注意力预算,每一条 memory 都在竞争这个预算——系统的工程取舍,本质上都是在回答这个问题。
对于正在构建自己的 AI Agent 的人来说,Claude Code Memory 提供了一个可以直接参考的生产级实现:不过度工程化,不引入不必要的复杂度,但每个决策背后都有清晰的理由。
本文是「ClaudeCode源码解读」系列第 3 篇。前序文章:整体架构设计、Context-Enginerring设计。