 夜雨聆风
夜雨聆风





MCP 还是 CLI?AI 工具链的两条路
每一轮对话,光是工具描述就烧掉 6 万 token——你真的需要这么用 MCP 吗?
●一、现象:一笔让人肉疼的 token 账单
最近我在使用 Cursor 开发时,一个对话窗口连了十几个 MCP Server。有一天突然好奇:这些工具定义到底吃掉了多少 token?
一查吓一跳。
一个典型的 AI Agent 连接 6 个 MCP Server(GitHub、数据库、Slack、Jira、云基础设施、监控),每个 Server 暴露 20-30 个工具。每个工具的 JSON Schema 定义大约 121 token,而这些 Schema 每轮对话都要注入上下文——不管你用不用。
还没开始干活,6-9 万 token 就已经烧掉了。
这不是我一个人的感受。mcp2cli 项目今年 3 月登上 Hacker News 热榜,声称能把 MCP 的 token 消耗砍掉 99%。按它的基准测试数据:120 个工具跑 25 轮对话,原生 MCP 消耗 362,350 token,优化后只要 5,181 token。
token 账单摆在这了。但在急着优化之前,我想先退一步问:AI Agent 调用外部工具,MCP 是唯一的路吗?
●二、溯源:为什么会有两条路?
带着这个问题,我研究了 OpenCLI 这个项目,发现它代表了一条和 MCP 完全不同的思路。两者的根本差异不在于实现细节,而在于谁来写工具、数据访问权从哪来。
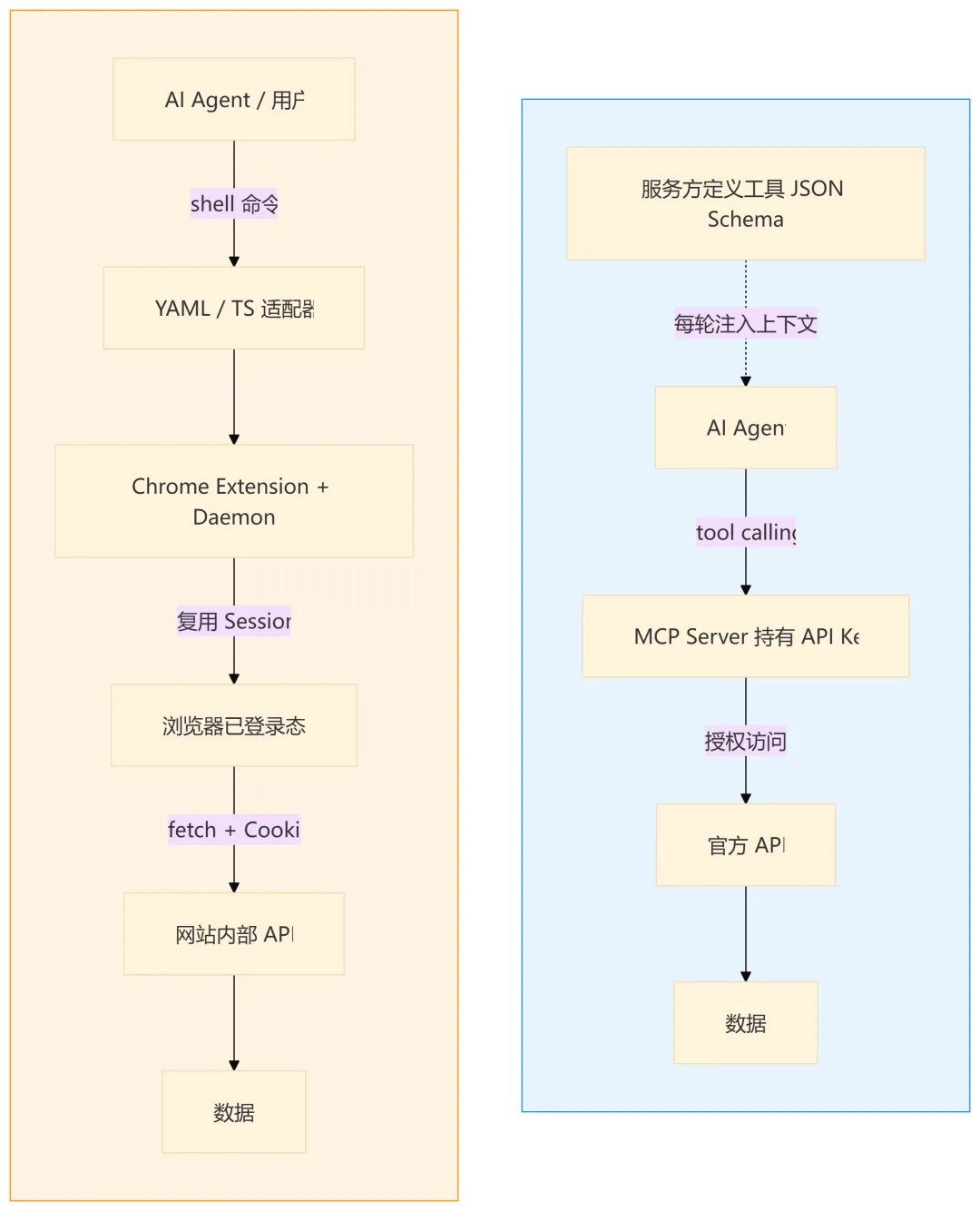
MCP 是”服务方写工具”——GitHub 提供 GitHub MCP Server,MongoDB 提供 MongoDB MCP Server。服务方定义能力,消费者照单使用。
OpenCLI 是”消费者写工具”——通过浏览器逆向发现网站的内部 API,封装成 CLI 命令。一个 20 行 YAML 就是一个完整适配器。消费者自己发现和封装能力。
打个比方:MCP 像餐厅点菜,厨师定义菜单你照着点;OpenCLI 像自己下厨,去市场看有什么食材自己做菜。
但这只是表面区别。深一层看,两者的数据访问权来源完全不同:
- ◆
MCP 是授权模型——服务方给你 API Key,授权你访问 - ◆
OpenCLI 是代理模型——你自己已经登录了,工具帮你自动化操作
知道了”是什么”和”为什么有两条路”,接下来逐个维度对比,看看它们各自的长短板。
●三、对比一:Token 消耗——费在哪?能省吗?
先回到文章开头的痛点:MCP 的 token 到底费在哪?
第一层:Schema 固定注入。 连了 140 个工具?每轮都要把完整定义塞进上下文,数万 token 的固定税,不管你用不用。
第二层:探索性调用的链式放大。 查个数据库要四步——list_databases → list_collections → collection_schema → find。每一步的输入都带着前面所有结果,token 消耗超线性增长。
第三层:必须经过 AI。 你没法绕过 LLM 直接调 MCP 工具,每次调用都是一次 AI 推理。
那 OpenCLI 呢?
|
|
|
|
|---|---|---|
| 每轮固定成本 |
|
|
| 单次调用成本 |
|
|
| 脱离 AI 使用 |
|
零 token
|
指定具体工具后,单次调用成本两者差不多。差距主要在固定成本和能否脱离 AI 使用。
AI Agent 只需调一次 opencli list 拿到命令列表(几千 token),后续直接拼 shell 命令。更关键的是,opencli bilibili hot --limit 10 可以在终端直接跑,完全不经过 LLM,零 token。
不过有一点需要说清楚:如果你在 Skill 或 Prompt 里精确指定了要调用的 MCP 工具,单次调用的 token 消耗其实跟 OpenCLI 差不多。 “MCP 费 token” 的核心是 Schema 注入的固定税和探索链的放大效应,不是单次调用本身。
Token 能省,但省 token 只是技术优化。接下来要问一个更要紧的问题:两种方案的安全模型有什么不同?
●四、对比二:安全——各有取舍,没有银弹
MCP 的认证很直接:你把 API Key 交给 MCP Server,它拿着你的凭据去调 API。
OpenCLI 看起来更安全——复用浏览器登录态,不需要你提供任何凭据。但我仔细看了它的源码,发现事情没那么简单:
OpenCLI 的 Chrome Extension 确实能读取 Cookie,代码里也确实在用。manifest.json 声明了 cookies 权限,Twitter 下载、B 站下载、微信读书等适配器都会通过 chrome.cookies.getAll() 读取 Cookie,传给下载器或拼接请求头。
所以更准确的对比是:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
不存在绝对安全,只有不同的风险模型。 你需要根据自己的场景做取舍。
Token 可以优化,安全可以取舍。但接下来这个维度,是两者之间最本质的差距。
●五、对比三:稳定性——MCP 最大的护城河
前面聊的 token 和安全,都是可以优化的技术问题。但稳定性是架构层面的根本差异,也是 MCP 最大的护城河。
OpenCLI 依赖的是网站内部的、没有任何稳定性承诺的 API。网站随时可以改路径、改返回结构、加签名、加风控,甚至直接下线。
API 改了怎么办?修适配器。没有其他办法。
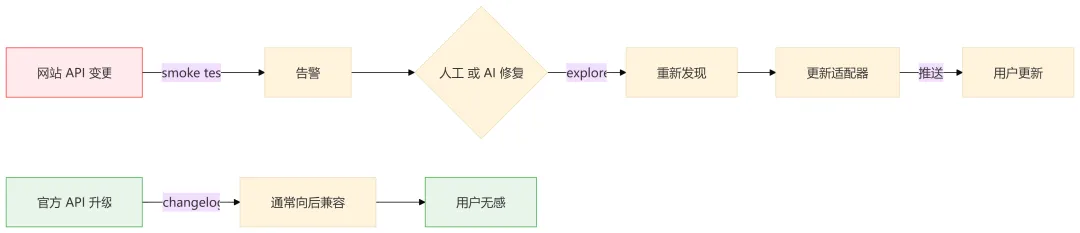
OpenCLI 有 smoke test 巡检、有 explore / record 命令重新发现 API,但这些都是被动防御——你在跟一个不知道你存在的网站玩猫鼠游戏。
MCP 呢?基于官方 API,有版本承诺,有 changelog,有 deprecation notice。API 出了问题是服务方的事。
稳定性来自服务方的承诺,而不是你的维护能力——这是 MCP 当前最大的、不可替代的优势。
说到这里,你可能觉得 MCP 全面碾压 OpenCLI 了。但别急,还有一个关键问题没回答:如果平台压根没有官方 API 呢?
●六、破局:OpenCLI 的价值在 MCP 进不去的地方
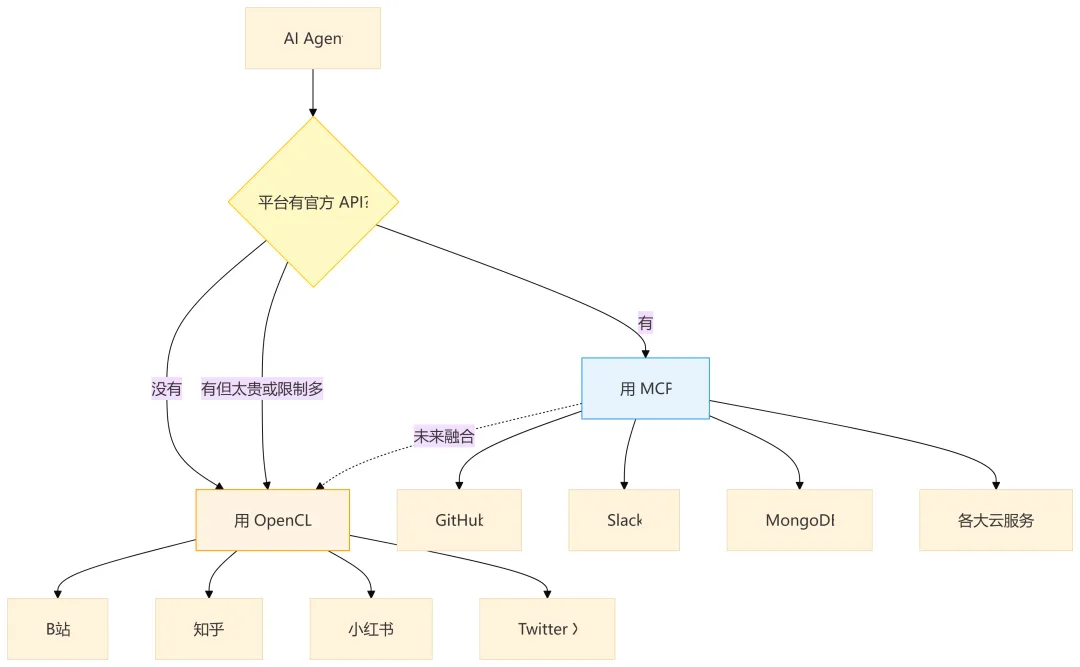
B 站有官方 API 吗?没有。知乎呢?没有。小红书?没有。Twitter 的官方 API 你用得起吗?大概率不行。
MCP 再好,也只能覆盖有官方 API 的平台。 而这些平台没有开放 API,但你作为已登录用户有权访问它们的数据。
OpenCLI 做的就是:把”你能在浏览器里做的操作”变成”你能在命令行里自动化的命令”。
而且它的适配器极其轻量——一个 20 行 YAML 就是一个完整命令。对比 MCP Server 需要一个完整的服务进程,分发成本天差地别。
OpenCLI 找到了自己的战场。但要真正站稳脚跟,它还有一个关键的缺失环节需要补上。
●七、补全:没有 Registry,生态转不起来
OpenCLI 当前最大的实操痛点,不是技术问题,而是分发和更新。
目前内置适配器跟 CLI 本体绑在同一个 npm 包里。B 站改了一个字段,开发者修完要发新版 npm,所有用户得 npm update -g 重装整个 CLI。50+ 站点每周改几个 API,用户要么频繁更新,要么忍受报错。
OpenCLI 需要一个 Registry 平台。 就像 npm 之于 Node 生态——没有中心化的包管理,生态转不起来。
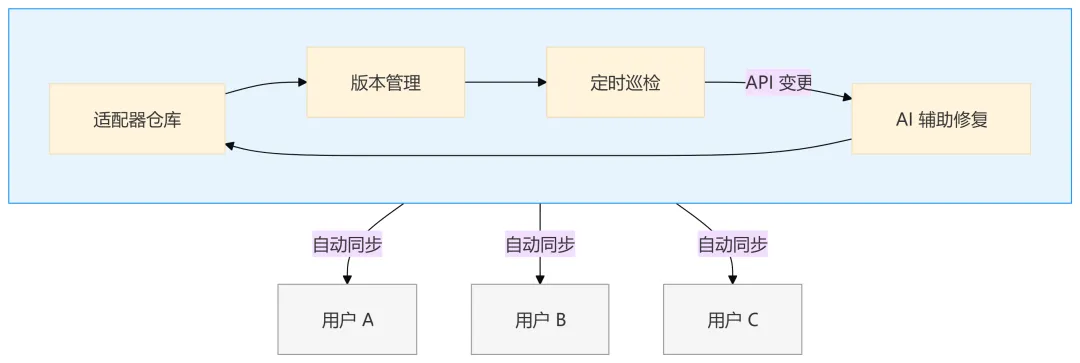
理想的体验是:平台定时巡检 → 发现 API 变更 → AI 辅助修复 → 自动推送给用户。用户什么都不用管,命令永远能用。
有了 Registry,OpenCLI 在更新体验上甚至能做得比 MCP 更好——MCP Server 是分散的重量级进程,而 OpenCLI 的适配器只是配置文件,同步成本极低。
到这里,两条路的优劣已经清楚了。最后给出我的结论。
●八、结论:不是谁替代谁,而是分层使用
回到最初的问题:AI Agent 调用外部工具,选 MCP 还是 CLI?
答案是分层:
|
|
|
|
|---|---|---|
|
|
MCP |
|
|
|
OpenCLI |
|
|
|
OpenCLI |
|
|
|
MCP |
|
MCP 和 OpenCLI 是互补的,不是替代的。 MCP 覆盖有官方 API 的平台,OpenCLI 覆盖 MCP 进不去的地方。
未来可能的融合方向:MCP Server 调用 OpenCLI 的浏览器桥接能力,去访问那些没有官方 API 的平台;或者 OpenCLI 有了 Registry + Skill 指导机制后,成为 MCP 在非开放 API 领域的有力补充。
工具链之争的终局,不是谁赢谁,而是让 AI 在每个场景下都能用到最合适的工具。
以上是我基于 OpenCLI 项目源码分析和 MCP 实际使用经验的个人思考。涉及的 token 数据引用自 mcp2cli 项目的公开基准测试。
你在实际项目中是怎么选择 AI 工具链的?MCP、CLI、还是两者混用? 欢迎在评论区聊聊你的方案和踩过的坑。
关注小唐的技术日志,我会持续分享 AI Agent 工具链、开发者效率、技术选型相关的深度思考。如果这篇文章对你有启发,也欢迎转发给同样在折腾 AI Agent 的朋友。