 夜雨聆风
夜雨聆风





Claude Code 51 万行源码,是我见过最好的 AI Agent 架构教材
3 月 31 日,Anthropic 犯了一个工程师最怕的错误 —— 把不该发的东西发出去了。
一个缺失的 .npmignore 配置,让 Claude Code v2.1.88 的完整源码随 npm 包一起发布。51.2 万行 TypeScript,1900 多个文件,59.8 MB 的 source map,全部公开可读。
社区的反应堪称疯狂。几小时内代码被镜像、反编译,Python 和 Rust 的 clean-room 重写项目 2 小时斩获 5 万 GitHub stars,可能是 GitHub 历史上增长最快的仓库。
但大多数文章都在聊”泄漏了什么八卦” —— Undercover 模式、电子宠物彩蛋、44 个隐藏 feature flag。
很少有人系统地回答一个更有价值的问题:如果你自己要做一个 AI Agent,能从这 51 万行代码里学到什么?
这就是这篇文章要做的事。
先看全貌。Claude Code 的技术栈是 TypeScript + Bun 运行时 + React/Ink 终端 UI —— 没错,用 React 写 CLI,不走寻常路。但真正值得关注的不是技术选型,而是它的核心架构:一个极其简单的 Agentic Loop。
while (response.has_tool_calls) { result = execute(tool_call) messages.append(result) response = call_model(messages)}单线程,一个扁平的消息列表,没有多角色竞争,没有复杂的状态机。Anthropic 明确选择了这种”笨”架构,理由只有两个字:可调试。
51 万行代码的核心,不是模型。是围绕这个简单循环构建的四个子系统:工具管理、权限控制、上下文治理、记忆整合。
这四个子系统,恰好是每个做 AI Agent 的人都要解决的问题。
01 | 工具系统:怎么给 Agent 装上 40 把瑞士军刀
大多数人给 Agent 加工具的方式是”写一个函数,注册进去”。5 个工具是没问题,但涨到 40 个,麻烦就来了 —— 权限怎么分级?并发怎么控制?某个工具返回了 10MB 文本怎么办?
Claude Code 管理着 40 多个工具 —— 从 Bash、Read、Write、Edit 到 Glob、Grep,再到 AgentTool(生成子代理)和 MCP 服务器注入的运行时工具。它的解法是一套工具合约模式。

每个工具必须实现同一份合约:输入 Schema(Zod 验证)、权限检查逻辑、执行函数、终端 UI 渲染器。不是建议,是强制。工具间零共享可变状态,完全隔离。
更精妙的是两个行为标签:isReadOnly(是否只读)和 isConcurrencySafe(是否并发安全)。BashTool 能改系统状态,FileReadTool 只读 —— 它们在同一个注册表里,但运行时的权限和调度策略完全不同。这些标签让调度器不需要”认识”每个工具,只看标签就能做出正确的并发决策。
一个 buildTool 工厂函数提供保守的安全默认值。新工具”出厂即安全” —— 你需要显式声明它能做危险操作,而不是默认放行。
还有一个容易忽视的设计:结果溢出保护。每个工具有 maxResultSizeChars 属性。超限的结果不会硬塞进上下文 —— 而是存到临时文件,模型只收到预览和文件路径。这一个小设计,就避免了上下文被单次工具调用”撑爆”的问题。
最后,Claude Code 的子代理也是工具。AgentTool 和 BashTool 待在同一个注册表里,走同一套合约。想让你的 Agent 调度另一个 Agent?不需要搞什么编排框架 —— 把子代理包装成工具接口就行了。
02 | 权限模型:AI 能自己决定什么,不能决定什么
你的 AI Agent 能执行 Shell 命令、编辑文件、发起网络请求。问题来了 —— 哪些操作可以自动执行,哪些必须问用户?
判断错了,代价很高:全都问,用户烦死,体验约等于手动操作;全都放,某天 Agent 删了你的 .bashrc,你才知道后怕。
Claude Code 的权限系统是整个代码库中最复杂的部分。它的核心设计是一条 Deny-First 权限管道 —— 每次工具调用都要流经七道门,deny 永远优先于 allow。

第一层是五种权限模式,覆盖从”每步都问”到”全部放行”的完整光谱:
-
default:所有操作需确认 -
acceptEdits:文件编辑自动通过,Shell 命令需确认 -
plan:只读,审批后才执行 -
bypassPermissions:自动放行一切 -
auto:AI 自主判断,最小审批
第二层是七步规则管道:工具级拒绝 → 工具级询问 → 工具自身 checkPermissions() → 安全免疫路径检查 → bypass 模式评估 → 内容特定规则匹配 → 兜底询问。
这里有一个非常精妙的设计:安全免疫路径。即使你开了 --dangerously-skip-permissions(最高权限),修改 .bashrc、.zshrc、.git/、.gitconfig 仍然会触发强制提示。
为什么?因为这些文件是”延时炸弹” —— 改了 .bashrc 不会立即出事,而是下次开 Shell 时悄悄执行。用户授权的那一刻,和危害发生的那一刻之间隔了一段时间,人的记忆早就淡了。Claude Code 的设计者显然被这种场景坑过。
但最让我印象深刻的,是 Auto 模式下的两阶段 LLM 分类器。
当 Auto 模式需要判断一个工具调用是否安全时,它不是查规则表 —— 而是发起一次独立的 Claude API 调用,让另一个模型来判断。
Stage 1(快速判断):温度 0,最多 64 tokens,倾向保守拒绝。大多数明显安全的操作在这里直接放行。
Stage 2(深度思考):仅在 Stage 1 拒绝时触发,允许 4096 tokens 的链式推理,用来减少误报。
关键的安全设计:两个阶段都只看用户输入和工具调用,不看助手的文本输出。为什么?如果分类器能看到主模型的”解释”,一个被入侵的主模型可以写出极具说服力的理由来欺骗分类器。剥离助手文本,直接切断了这条攻击路径。
连续 3 次被拒绝或单次会话总计 20 次拒绝后,系统自动回退到交互式提示 —— 这是最后一道保险。
03 | 上下文管理:不是塞更多,而是丢什么
AI Agent 干活越久,上下文越大。直觉上,信息越多模型应该越聪明。
但事实相反。 Anthropic 的官方文档直接写了:随着 token 数量增长,模型的准确率和召回率会下降。他们把这个现象叫 context rot。
所以上下文管理的核心问题不是”怎么塞更多”,而是**”该丢什么”**。

Claude Code 用了一套渐进式三级压缩策略,按成本从低到高排列:
MicroCompact(零成本):基于时间清理旧的工具调用结果。不调用任何 API,纯本地操作。你 10 轮前的 git status 输出?大概率已经过时了,直接清掉。
AutoCompact(中等成本):当上下文使用率达到 92% 时自动触发。调用 LLM 生成一份不超过 20,000 token 的结构化摘要,同时保留 13,000 token 的缓冲区给后续操作。如果摘要连续失败 3 次,触发熔断 —— 不会无限重试浪费预算。
Full Compact(高成本):完整对话压缩,加上选择性文件重注入,每个文件上限 5,000 tokens。这是最后手段。
另一个值得学的设计:静态内容缓存分离。跨轮次不变的内容 —— 系统提示、工具定义、CLAUDE.md 项目说明 —— 被归为静态内容,自动走 prompt cache。动态内容(对话历史、工具结果)单独管理。这个分离让缓存命中率大幅提升,直接省钱。
还有一个小但关键的细节:每个工具的 maxResultSizeChars。超大结果存临时文件、返回预览和路径。这不仅是工具系统的设计,也是上下文保护的重要防线 —— 一个意外返回了整个日志文件的 Bash 调用,不会把上下文窗口一发带走。
04 | 记忆系统:让 AI 在你睡觉时整理笔记
你的 Agent 在第 20 轮对话时忘了第 1 轮说什么,这不是 bug —— 是上下文窗口的物理限制。大多数人的解法是 RAG:把历史扔进向量数据库,用的时候搜出来。
Claude Code 的做法完全不同。它用了一套三层记忆架构,设计思路更像人类的工作记忆 + 长期记忆,而不是数据库检索。
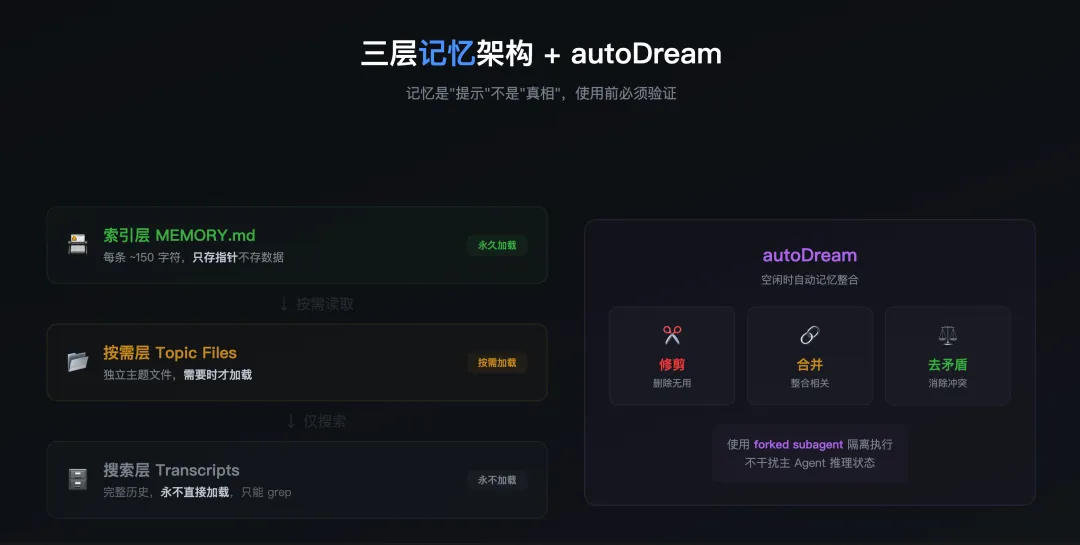
第一层:索引层(MEMORY.md)。这个文件永久加载在上下文中,但它不存任何实际数据 —— 只存指针。每条记录约 150 个字符,格式是”标题 + 文件路径 + 一句话描述”。它的作用是让模型知道”什么信息存在、去哪里找”。
第二层:按需层(Topic Files)。实际知识分散在独立的主题文件中。模型需要某个领域的记忆时,根据索引去读对应文件。不需要的不加载 —— 记忆的成本和上下文占用直接挂钩,按需获取是关键。
第三层:搜索层(Transcripts)。完整的历史对话记录。但它永远不会被直接加载到上下文中 —— 只能通过 grep 搜索特定关键词。这保证了即使历史记录有几十万行,也不会侵占宝贵的上下文空间。
这套架构还有一个”写入纪律”:Agent 必须在文件写入成功后才能更新索引。如果写入失败,索引不变。这防止了模型用失败的尝试污染自己的记忆。更重要的是,整个系统把记忆视为”提示”而非”事实” —— 使用任何记忆前,Agent 被要求先验证它是否仍然准确。
然后是目前藏在 feature flag 后面、尚未正式发布的 autoDream。
autoDream 是一个在会话空闲时自动运行的后台进程。它做三件事:修剪不再有用的记忆、合并相关的条目、消除逻辑矛盾。名字不是随便取的 —— 这是在刻意模拟人类睡眠时大脑整理记忆的过程。
架构上的关键决策:autoDream 使用 forked subagent 执行,运行在隔离环境中。这意味着记忆整理过程不可能干扰主 Agent 的推理状态 —— 就像你在睡觉时大脑在整理记忆,但不会影响你的梦境。
想象一下:你周五关了电脑,周一回来,你的 AI Agent 已经把过去一周的零散笔记整理成了结构化知识。这就是 KAIROS(autoDream 所属的更大系统)的愿景 —— 把 Agent 从”你调用才动”的工具,变成持续运行的助手。
05 | 5 个你今天就能用的设计模式
前面拆了四个子系统,信息量不小。这一章做一件事:提炼成你马上能用的模式清单。

模式 1:工具合约
问题:你的 Agent 工具越来越多,每个工具的权限、并发、错误处理逻辑各写各的。
做法:定义统一的工具接口 —— 输入 Schema、权限级别、行为标签(只读?并发安全?)、结果大小上限。用工厂函数提供安全默认值,新工具”出厂即安全”。
模式 2:Deny-First 权限
问题:你需要一套权限策略,但不知道是先列白名单还是黑名单。
做法:先列绝对禁止的操作(deny list),再列确定安全的操作(allow list),其余全部默认询问用户。特别注意”延时危险”操作 —— 改配置文件、环境变量这类不会立即出事、但下次生效时才暴雷的操作。
模式 3:渐进式压缩
问题:长对话后 Agent 开始”犯迷糊”,Context rot 明显。
做法:按成本分三级。先清理过时的工具结果(零 API 调用),再在 90%+ 使用率时触发 LLM 摘要(中等成本),最后才做完整压缩(高成本)。给压缩加熔断机制 —— 失败三次就停,不要无限重试烧钱。
模式 4:索引-按需记忆
问题:你的 Agent 需要记住跨会话的信息,但全量加载记忆太贵。
做法:维护一个轻量索引文件(< 200 行),永久放在上下文里。实际内容存在独立文件中,按需读取。给记忆加”写入纪律” —— 只有确认成功的操作才写入记忆,记忆是提示不是真相,使用前先验证。
模式 5:子代理即工具
问题:你想让 Agent 能调度其他 Agent,但不想搞复杂的编排框架。
做法:把子代理包装成和普通工具一样的接口,注册进同一个工具表。主 Agent 调用子代理就像调用 Bash 一样自然 —— 不需要特殊的编排层、消息总线或调度器。保持架构扁平。
51 万行源码里最值得学的,不是某个具体的函数实现。
而是一个认知:生产级 AI 的难题不在模型,在 Harness。
模型会越来越强。但工具怎么管理、权限怎么控制、上下文怎么治理、记忆怎么整合 —— 这些工程问题不会因为模型变强就消失。它们只会越来越重要。
有时候,那个看起来最”笨”的 while 循环,恰恰是最聪明的架构决策。
