 夜雨聆风
夜雨聆风





Claude Code 源码泄露:12 种缓存优化机制全解析
3 月底,Claude Code 的 npm 包意外附带了完整的 TypeScript 源码 map 文件。安全研究员 Chaofan Shou 发现并公开后,开发者社区掀起了一场”代码审计热”。
大多数人关注的是安全风险。但开发者 barazany 看到了另一个故事——Claude Code 如何通过极其精细的缓存优化,从 Anthropic 的 5 小时配额限制中榨取每一分价值。
他从源码中发现了 12 种独立的缓存优化机制。每一种都针对一个具体的缓存泄漏点。
这篇文章,我们把最关键的几个拆开来看。
一个被忽视的事实:缓存命中率 = 配额
大部分开发者理解配额的方式是”我有多少 token 可以用”。
但 Anthropic 的计费不是线性的:
-
• 缓存命中:正常价的 10% -
• 正常输入:1x -
• 缓存未命中:正常价的 125%
同样的配额,缓存命中率高的用户能做 10 倍以上的工作。缓存命中率低的人,同样的配额可能只够用 1 小时。
所以当 Claude Code 核心开发者 Boris 说”改进即将到来”时,很多人困惑——配额是服务器端的限制,客户端能做什么?
答案:他没有改配额,他在改缓存命中率。
缓存命中率每提升 1%,等于配额增加 1%。这就是 Claude Code 12 种缓存机制存在的意义。
机制一:一行字符串解决 2^N 爆炸
每次你跟 Claude 说话,Claude Code 都要组装一条完整的 prompt 发给 API。这条 prompt 包含系统提示、工具定义、对话历史、代码上下文等等。
服务器会缓存这条 prompt。下次发相同的 prompt 前缀时,直接复用缓存,不用重新处理。
但有个问题:系统提示中有大量运行时条件——哪些工具启用了、是否处于交互模式、加载了哪些技能……每多一个条件,缓存变体就翻一倍。
5 个布尔值 = 32 种变体。10 个 = 1024 种。数百万用户,大多数变体永远不会命中第二次。
Claude Code 的解决方案极其简单——在源码中插入了一个字面字符串:
__SYSTEM_PROMPT_DYNAMIC_BOUNDARY__这行之前的内容:所有 Claude Code 用户完全相同。编码规范、安全规则、语调指导。标记为 scope: 'global',全球共享一个缓存条目。
这行之后的内容:运行时动态部分。工具状态、用户配置。每次重新处理。
源码注释写得很直接:
“Each conditional here is a runtime bit that would otherwise multiply the Blake2b prefix hash variants (2^N).”
一句话,把指数级的缓存碎片变成了常量。
机制二:不改消息的”手术刀”
长对话中,旧的工具调用结果会堆积在缓存里。它们占着空间,你还在为它们付费。
最直觉的做法是删掉它们——编辑消息、删除内容。
但问题来了:只要消息序列中任何一个字节发生变化,服务器就认为这是一条全新的消息。从修改点开始,所有缓存全部失效,按 1.25x 惩罚价重新处理。
压缩省下的 token,远不够付缓存失效的罚款。
Claude Code 的解法叫 cache_edits。它不走正常编辑路径,而是一个侧通道:
不修改消息内容 → 附加一条带外指令给 API → “服务器,请删除 tool_use_id 为 X 的缓存 KV 条目” → 消息字节完全不变 → 缓存键不变 → 缓存保持有效。
同样的对话,更少的膨胀,缓存不失效。
这是整个设计中我最欣赏的一个决策——宁可增加 API 的复杂度,也要保护缓存完整性。
机制三:三层递进式压缩
不是所有膨胀都能用侧通道解决。对话太长时,Claude Code 用三层递进策略处理:
第一层:轻量清理(每次 API 调用前)
不调用模型,直接删除旧的工具结果,只保留最近 5 个。其余替换为 [Old tool result content cleared]。
快速、零成本、每次请求自动执行。
第二层:API 级别处理
服务器端策略,处理 thinking 块和基于 token 阈值的工具结果清理。
第三层:完整 LLM 总结(最后手段)
当前两层不够时,调用模型对整个对话做结构化总结,包含 9 个部分:意图、技术概念、涉及的文件、错误和修复、所有用户消息、待处理任务、当前工作状态……
模型在生成总结前会先做思维链推理(scratchpad),推理过程在提交前被剥离。
架构原则:总结是昂贵且有损的,只在其他方法都失败后才触发。
机制四:DANGEROUS 标记和 728 行诊断系统
如果缓存命中率突然下降,你怎么知道是哪里出了问题?
Claude Code 内置了一个 728 行的实时监控系统。当 cache_read_input_tokens 下降超过 5% 且 2000 token 时,它会:
-
• 写一个 .diff文件到磁盘 -
• 精确归因:是哪个工具 schema 变了?哪个 beta header 改了?TTL 过期了? -
• 记录到遥测系统
更狠的是,源码中有一个函数叫 DANGEROUS_uncachedSystemPromptSection()。
任何工程师想往系统提示的动态部分加内容,都必须调用这个函数,并传入书面理由。注释写的是:”请解释为什么这部分必须是动态的。”
这相当于在代码层面强制执行一个规则:如果你要破坏缓存,你必须说出来为什么。
机制五:willow——75 分钟的倒计时
Claude Code 内部有一个叫 “willow” 的功能。当两个条件同时满足时触发:
-
1. 空闲时间 ≥ 75 分钟 -
2. 对话 token 数 ≥ 100K
触发后,用户会看到两种之一:
-
• 一个阻拦对话框(A/B 测试变体 A) -
• 一行提示:”new task? /clear to save 1.2M tokens”(变体 B)
为什么是 75 分钟?因为 Anthropic 的缓存 TTL 约 1 小时。75 分钟意味着缓存一定已经过期。
如果你继续这个 100K+ token 的旧对话,整个上下文会从头重新处理,按 1.25x 计费。可能一次就烧掉上百万 token。
willow 不是在帮你省 token——它是在你还没意识到成本之前,让成本变得可见。
机制六:总结调用复用主对话缓存
这是一个很容易被忽略的细节。
当 Claude Code 需要对对话做总结时(触发第三层压缩),最直觉的做法是发一个独立的 API 调用:
-
• 系统提示:”You are a summarization assistant…” -
• 不同的系统提示 = 不同的缓存键 -
• 整个对话从头重新 token 化
有人测试过这种替代方案:98% 的缓存失效率。全球每天因此重复处理数百亿 token。
Claude Code 的做法是:复用主对话的完全相同配置。
-
• 相同的系统提示 -
• 相同的工具定义 -
• 相同的模型 -
• 相同的消息前缀
把总结指令作为新的用户消息追加在末尾。服务器看到相同的缓存键——命中。
一个设计决策,避免了 98% 的缓存浪费。
一句话重写省了 20K token
barazany 在分析中发现了一个精彩的案例。
Claude Code 旧版代码中,有一段逻辑会根据 token 预算是否激活来切换系统提示:
// 旧版:有预算时显示,无预算时隐藏
if (hasTokenBudget) {
prompt += "\n当前预算: " + budget;
}每次预算开关翻转,系统提示就变了。缓存键变了。整个系统提示的缓存全部失效——约 20K token 重新计费。
新版代码重写成了一句话:
"When the user specifies a token target (e.g., '+500k', 'spend 2M tokens'),
your output token count will be shown each turn. Keep working until you
approach the target..."关键改变:不再在系统提示中插入具体的预算数字。数字改在运行时注入到其他位置。系统提示变成了静态文本,永远不会因为预算变化而失效。
一句话重写,消除了一个 20K token 的缓存泄漏点。
12 种机制全景
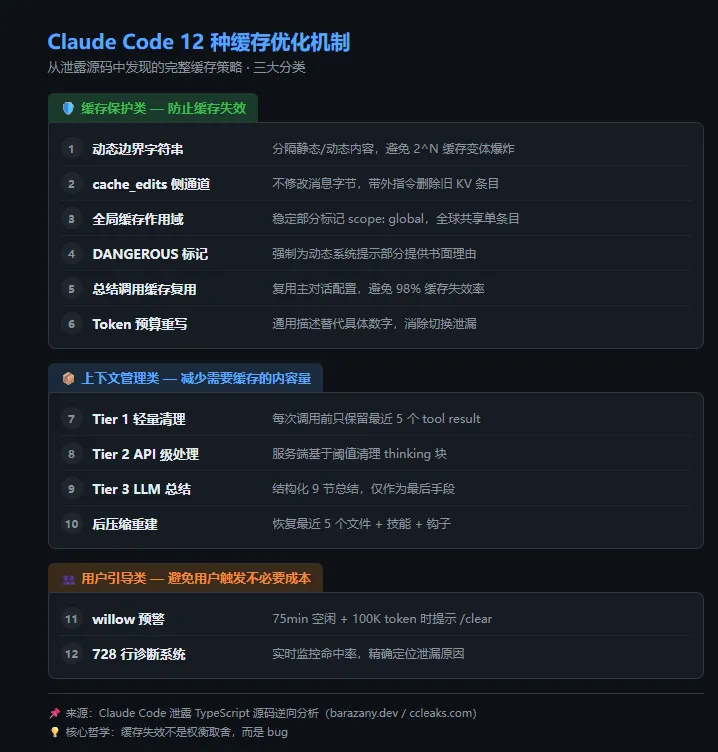
从源码中识别出的所有缓存优化策略:
缓存保护类(防止缓存失效):
-
1. 动态边界字符串:分隔静态/动态内容,避免 2^N 变体 -
2. cache_edits 侧通道:不修改消息字节,带外删除 KV 条目 -
3. 全局缓存作用域:稳定部分标记为 scope: 'global',全球共享 -
4. DANGEROUS 标记:强制为动态部分提供书面理由 -
5. 总结调用缓存复用:复用主对话配置,避免 98% 失效率 -
6. Token 预算提示重写:通用描述替代具体数字,消除切换泄漏
上下文管理类(减少需要缓存的内容量):
7. Tier 1 轻量清理:每次调用前只保留最近 5 个 tool result
8. Tier 2 API 级处理:服务端基于阈值清理
9. Tier 3 LLM 总结:结构化 9 节总结,最后手段
10. 后压缩重建:恢复最近 5 个文件 + 技能 + 钩子
用户引导类(避免用户触发不必要的成本):
11. willow 预警:75min 空闲 + 100K token 时提示 /clear
12. 728 行诊断系统:实时监控缓存命中率,精确定位泄漏原因
工程哲学
读完这些代码,最强烈的感受是:Claude Code 团队不把缓存失效视为权衡取舍,而是视为 bug。
从 728 行的诊断系统,到 DANGEROUS_uncached 的强制注释,从边界字符串到侧通道删除——每一个设计决策都指向同一个目标:
让缓存命中率尽可能接近 100%。
因为在这个计费模型下,缓存命中率不是优化目标,而是产品的生命线。命中率每掉 1 个百分点,用户的配额就少 1 个百分点。
这对所有构建 AI 应用的开发者都是一个启示:API token 的价格不是线性的。你是否理解并优化了缓存策略,可能决定了你的成本是 X 还是 12X。
本文基于开发者 barazany 对泄露源码的分析文章,以及 ccleaks.com 的代码审计数据。所有信息均来自公开的源码分析,不涉及任何私有或未公开的内容。