 夜雨聆风
夜雨聆风





Claude Code 源码意外泄露:真正被看光的,不是模型,而是 AI 编程产品的“工程底牌”
Claude Code 源码意外泄露:真正被看光的,不是模型,而是 AI 编程产品的“工程底牌”
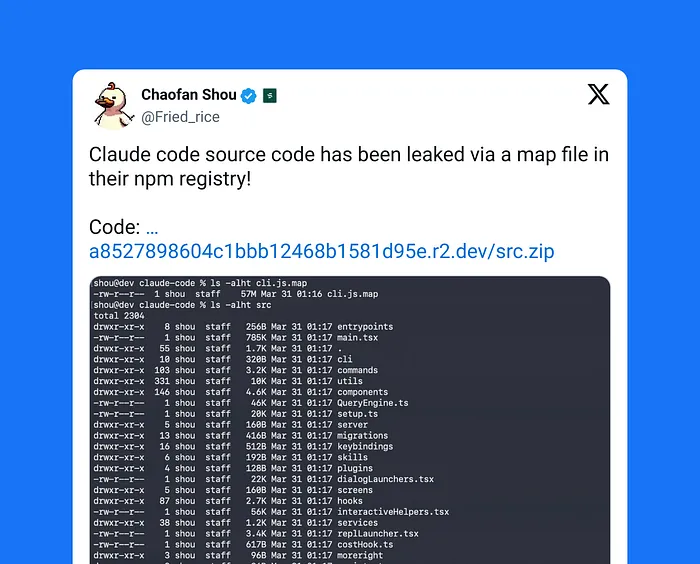
大家这两天应该都刷到了一个消息:
Anthropic 的 Claude Code,源码泄了。
但先别急着把它理解成“模型被偷了”“核心算法没了”这种夸张说法。 根据多家媒体与 Anthropic 对外说法,这次事件更准确的描述是:**Claude Code 某次发布时,把内部源码相关内容错误打进了公开包里,属于发布流程中的人为失误,不是外部黑客入侵。**Anthropic 也明确表示,这次没有泄露敏感客户数据、凭证,Claude 的模型权重也没有暴露。
真正让开发者圈炸锅的点在于:
泄露的不是“模型本体”,而是围绕模型构建出来的一整套 AI 编程代理工程能力。
而这一层,恰恰是当下 AI Coding 产品最值钱、也最难补齐的部分。
一、先把背景讲清楚:Claude Code 到底是什么?
Claude Code 不是单纯一个聊天框,也不是普通补全插件。 Anthropic 在 2025 年 2 月 24 日正式推出 Claude Code,把它定位成一个可在终端里执行复杂工程任务的 agentic coding CLI 工具。也就是说,它不是只会“回答代码问题”,而是能在代码仓库上下文中理解、编辑、执行、规划,逐步帮你推进开发任务。
所以,Claude Code 的价值,从来不只是模型回答得聪不聪明,而是:
它如何管理上下文,如何调用工具,如何做任务规划,如何保证改代码这件事尽量可控。
这也是为什么这次泄露会让整个行业高度关注。
二、这次是怎么泄的?
公开信息显示,问题出现在 npm 上发布的 @anthropic-ai/claude-code2.1.88 版本。 媒体报道称,这个版本里意外带出了一个体积接近 59.8MB 的 JavaScript source map 文件,也就是常说的 .map 文件。source map 本来是用来调试和映射源码的,但一旦被错误带到公开发布包里,就可能把原始 TypeScript 代码结构暴露出来。随后,开发者迅速发现并传播了相关内容。
这也是这次事件最让人唏嘘的地方:
不是被攻破,而是自己“打包打漏了”。
从安全行业角度看,这类事故往往比“高难度黑客攻击”更常见,也更真实。因为很多时候,真正危险的不是系统不够强,而是发布链路里某个看起来不起眼的细节没拦住。
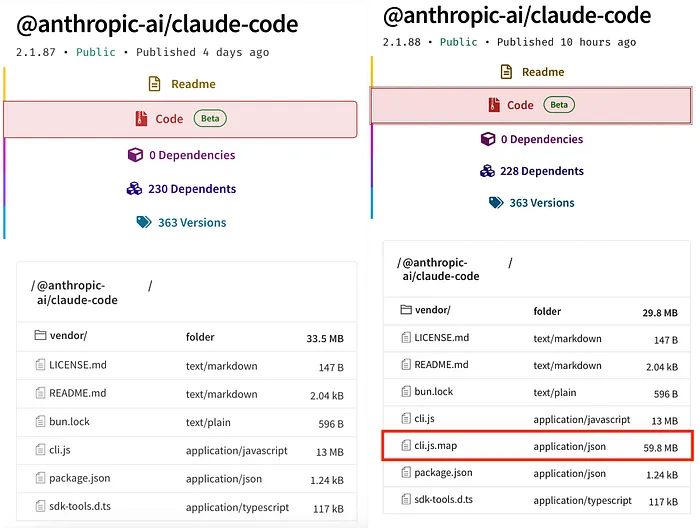
三、泄露的到底是什么?哪些又没有泄露?
这一点特别重要。
从目前公开报道看,外界看到的是 Claude Code 的大量内部实现细节,规模大约在 50 多万行代码、近 2000 个文件 的量级;但 没有证据表明 Claude 模型权重本身被泄露,也没有用户数据、API 密钥之类的敏感信息外泄。
换句话说,这次被公开的是:
-
Claude Code 作为 AI 编程代理的工程组织方式 -
它的任务编排思路 -
一部分记忆与上下文管理逻辑 -
工具调用和错误恢复相关实现 -
部分尚未正式公开的功能线索
而不是大家口中的“Claude 大模型源码”。模型没被拆开,但产品护城河的一部分被看见了。
四、为什么业内会这么震动?
因为今天做 AI Coding,难的早就不只是“接一个模型 API”。
真正决定体验上限的,往往是下面这些问题:
你怎么做任务拆解? 你怎么决定什么时候该读文件、什么时候该改文件? 你怎么避免代理“自信地做错事”? 你怎么让多轮长任务不把上下文拖垮? 你怎么控制工具权限、失败重试和中断恢复?
这些问题,才是 AI 编程产品从“能演示”走向“能长期用”的关键。 而这次泄露,让外界第一次更近距离地看到:一线 AI Coding 产品到底是怎么把这些环节串起来的。
这也是为什么不少媒体都把它定义成:
对用户风险不算最高,但对产品和竞争层面影响很大。
五、外界从这次泄露里看到了什么?
媒体与开发者分析普遍提到几个方向。
第一,是 Claude Code 的“记忆/上下文”机制。 有报道提到,其内部并不是简单“把所有历史一股脑塞进上下文”,而是存在更有层次的索引与按需读取思路,尽量减少长会话中的混乱与幻觉。还有一个很有代表性的工程细节:只有在文件成功写入后,代理才更新相关记忆索引。这类“先落盘,再记忆”的策略,本质上是在降低代理自我欺骗和错误累积的风险。 第二,是 未发布功能线索。 The Verge、Guardian 等媒体都提到,外界从泄露内容中发现了一些尚未公开的项目痕迹,比如类似虚拟宠物的 Buddy,以及疑似“常驻后台代理”方向的 KAIROS。这不一定代表功能即将上线,但至少说明 Claude Code 的演进方向,已经不只是“命令行问答助手”这么简单。
第三,是 行业对 AI 代理工程价值的重新认识。 这次事件再次证明:模型能力当然重要,但把模型变成可用产品的那层“harness / orchestration / workflow”同样稀缺。很多竞品之间真正拉开差距的,不只是模型谁更强,而是谁把工程层做得更稳、更敢交给用户。
六、这件事对普通开发者意味着什么?
我觉得,至少有 3 个很现实的启发。
1)别再把 AI 产品理解成“套个模型壳子”
很多人以为,做 AI 产品就是:
接 API 加聊天框 做个历史记录 完事
但真正进入生产环境后,你会发现最费时间的根本不是模型接入,而是流程编排、权限控制、异常处理、上下文治理、工具调用设计这些工程问题。
这也是为什么有些产品 Demo 看着都差不多,真正用起来体验却能差一大截。
2)发布链路,永远是工程安全里的高危地带
这次事件不是传统意义上的攻防对抗,却照样造成了巨大的信息外泄。 对开发团队来说,这提醒非常直接:
-
调试产物不要默认进入发布包 -
对构建结果做自动审计 -
对 sourcemap、环境变量、内部路径做额外扫描 -
发布流程尽量减少人工步骤 -
让 CI/CD 去替代“我记得已经检查过了”
很多事故,最后都不是输在“不会防”,而是输在“觉得不会出事”。
3)未来 AI 编程工具的竞争,会越来越像“工程体系竞争”
过去大家喜欢比模型分数、比 benchmark。 但这次之后,更多开发者会意识到:真正决定产品壁垒的,是完整的代理系统设计。
谁的任务规划更稳, 谁的上下文更干净, 谁的工具调用更可靠, 谁的失败恢复更像一个靠谱的工程搭子, 谁就更容易赢。
七、为什么说这次事件值得所有做产品的人看看?
因为它非常像一个时代切片。
以前大家觉得 AI 产品拼的是模型。 现在你会越来越清楚地看到:
模型是引擎,工程层才是整辆车。
引擎再强,传动不行、刹车不行、方向盘不行,用户一样不敢开。 Claude Code 这次意外把“车架结构”露出来,反而让行业第一次更直观地看到了:一款先进 AI 编程工具,背后到底堆了多少产品工程细节。
结语
所以,Claude Code 这次“泄露门”,我更愿意把它理解成:
一次不光彩的事故,但也是一次罕见的行业样本外流。
它没有把 Claude 模型本体暴露给全世界, 却让所有人看到了——
一个成熟 AI Coding Agent,究竟是怎么被工程化出来的。
而这件事最值得国内开发者、独立开发者、做 AI 应用的人思考的点是:
未来最值钱的,不只是模型能力, 更是你如何把模型变成一个真正能交付结果的系统。

扫码关注我们!