 夜雨聆风
夜雨聆风





源码泄露 24 小时后:为什么 Anthropic 的估值没跌,反倒让“API 搬运工”们火了?

https://www.apevon.ai
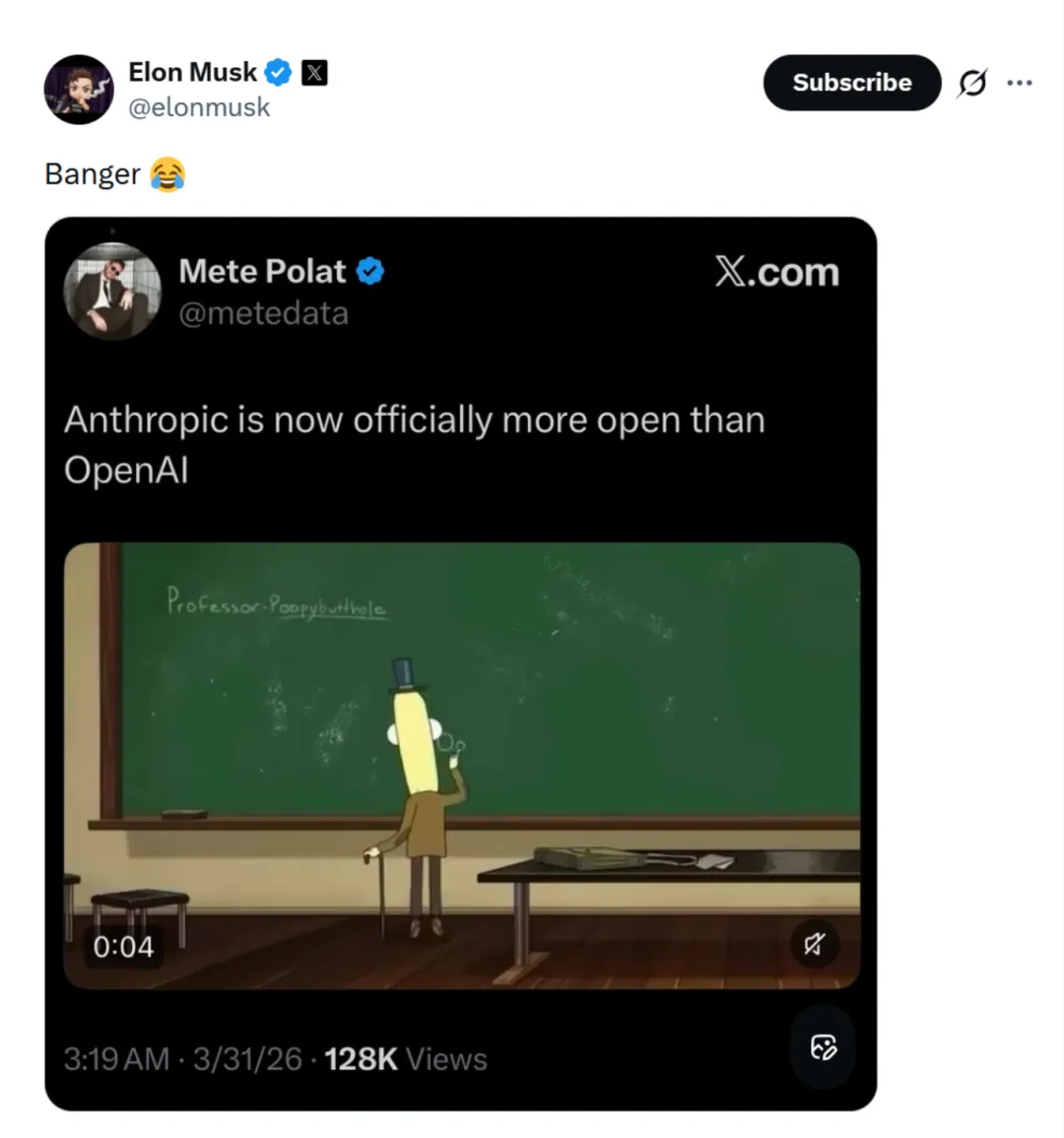
这几天,AI 圈的人大概都在熬夜吃同一个瓜:
Anthropic 员工因为一次低级的操作失误
把自家内测工具 Claude Code 的核心源码推到了公共仓库
短短几小时,51 万行代码被全网疯狂克隆
各种技术群里像过年一样,大家逐行拆解顶级 AI 的“大脑构造”
甚至扒出了里面用来吐槽的注释彩蛋
但如果你跳出技术圈的狂欢
看一眼商业层面的反应,会发现一个极其反常的现象:
资本市场异常冷静,没有任何投资人觉得 Anthropic 会因为这次泄露而跌落神坛
为什么底裤都漏了,大厂却丝毫不慌?
今天和大家聊聊源码背后的真实商业逻辑
代码是开源的,但算力和配额是“垄断”的
很多人觉得,既然拿到了源码,我是不是也能自己搓一个 Claude 出来?
现实很骨感
当你真的扒开这 2000 个泄露文件,你会发现它里面其实没有魔法
全是非常扎实的“工程化调度”和极其复杂的长文本 Prompt链条
这意味着什么?意味着极其恐怖的 Token 消耗量
顶级 Agent 为了不犯错,会在后台进行大量的自我校验、逻辑回溯和循环反思
你想复刻这种聪明,就得拥有能扛住海量并发调用(TPM/RPM)的基础设施
大厂的护城河,从来不是那几行被泄露的 TypeScript 代码
而是跑在几万张 H100 显卡上的算力,以及普通开发者根本拿不到的极高 API 并发上限
你学会了顶级大厨的菜谱,但高端食材你一个也买不起
企业级核心焦虑:从“AI不够聪明”到“AI突然罢工”
这次事件给B端企业敲响了另一记警钟。
既然强如 Anthropic 的工程师也会“手滑”漏掉配置文件
那谁能保证他们的服务器不会突然宕机?
谁能保证他们不会为了修补安全漏洞
明天就突然强行停用旧版本的 API 接口?
如果你公司的核心业务(比如智能客服、自动化营销)只绑定了这一家大厂的接口
这种单点依赖带来的系统性风险,是任何一个成熟的企业都无法承受的
业务跑起来之后,最怕的不是AI偶尔说错话
而是 API 突然调不通
行业风向转变:从“单一依赖”转向“多重冗余”
这也解释了为什么在这次风波中,很多企业开始重新评估底层的调用架构
大家不再盲目追求某一个单一的“最强模型”
而是开始转向更务实的API聚合调度策略
作为在行业里做模型接口聚合的从业者
这两天明显感觉到,企业对以下三点需求越来越重视:
-
不再把鸡蛋放在一个篮子里。底层架构必须能用一套接口同时兼容多个大模型。当某一家大厂因为事故或调整出现延迟时,系统能自动热切换到备用节点,确保业务流不断。
-
既然高级逻辑非常费 Token,那就必须通过渠道把单价打下来。相比于直接用官方零散的额度,通过聚合通道的大宗采购协议(通常能压低 20%-40% 成本)来平衡开销。
-
官方连源码都能漏,企业自然不敢把核心数据全存在他们那儿。采用不缓存、不存储数据的中转层,配合国内对公结算的财务合规,成了很多企业的一致选择。
写在最后:
AI 行业的变化比翻书还快
今天泄露源码,明天可能又出个新模型
但对于真正要把 AI 当作生产力工具的企业来说
万变不离其宗的铁律只有三条:单价要低、接口要稳、数据要安全

https://www.apevon.ai

看到这里,说明你对“AI”这条赛道多少有点上头了
欢迎随时找我们交流
我们会不定期抽选优质评论,送出小惊喜(最新大模型账号资源哦)🎁