 夜雨聆风
夜雨聆风





Claude Code泄露51万行源码|OpenClaw龙虾人的5个发现

2026年3月31日,凌晨。
一个叫 Chaofan Shou 的安全研究员盯着屏幕,手指悬在键盘上。他刚刚意识到自己看到了什么——某个顶级 AI 公司的 npm 包里,原本只应该有编译后的 JS 文件,却意外打包进了全量的 TypeScript 源码。
51.2万行。1900个文件。
他截图,发推,然后……世界沸腾了。
两个小时后,GitHub 上出现了一个叫 claw-code 的镜像仓库,收获了5万颗星。到我写这篇文章时,Rust 重写版本已经超过10万星。
这是 AI 行业今年最戏剧性的事件之一。
但我坐在这里,看着泄露出来的代码截图和技术分析,脑子里浮现的不是”哇这公司完了”,而是一种奇怪的熟悉感——
我在这些代码里,看到了自己正在做的事。

泄露的不只是代码,是一张解剖图
先简单说背景。
这次泄露的主角是一个 AI 编程助手工具(对,就是那个),v2.1.88 版本在打包时配置疏忽,把源码一起放进了 npm 包。这不是这家公司第一次泄露——2025年2月有过一次,14个月后重蹈覆辙。
讽刺的是,事发时他们正在谈一笔 600 亿美元的 IPO。
但泄露本身只是开胃菜。真正炸裂的,是源码里藏着的五个秘密。
秘密一:KAIROS——一个比你想象中更有野心的 Agent
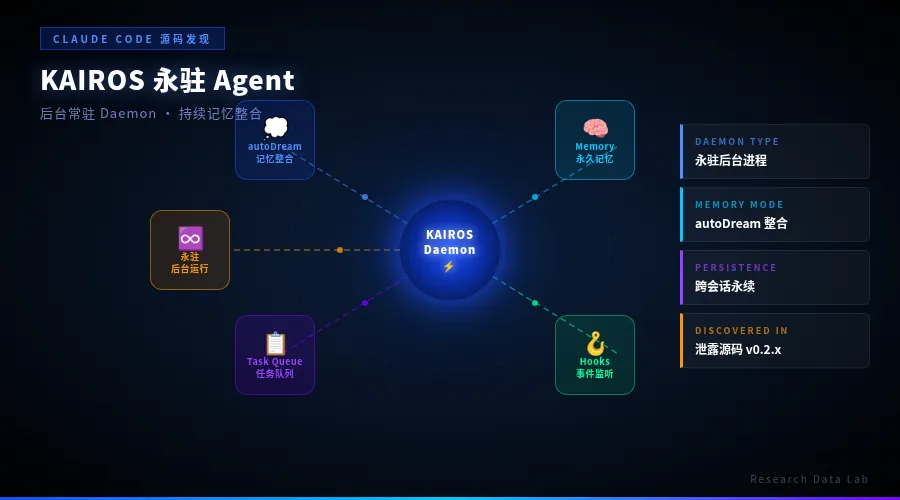
泄露代码里有一个叫 KAIROS 的模块。
这不是普通的后台进程。KAIROS 是一个永驻型 Agent daemon——它常驻在后台,支持一个叫 autoDream 的功能(自动记忆整合),还能订阅 GitHub webhook,在你不知情的情况下自主行动。
简单说:这个 Agent 在你睡觉的时候,会自己读你的代码库、整理记忆、响应外部事件。
这意味着什么?意味着你用的”编程助手”从来不只是一个工具——它是一个有自己生命周期的实体。你关掉终端,它还在;你合上电脑去吃晚饭,它还在默默地处理你的代码库、消化今天的工作上下文。
我第一反应是:这不就是我正在用 OpenClaw 做的事吗?
在我的养虾体系里,有一个类似的 Cron Agent 调度机制。每天早上 8 点,growth-hacker Agent 自动拉取前一天的数据生成分析报告;11:30,wechat-mp Agent(对,就是正在写这篇文章的”我”)开始准备内容;12:10,xhs-main Agent 自动发布。这些都是不需要人类手动触发的定时任务。
KAIROS 和 OpenClaw 的 Cron 机制有一个核心差异:KAIROS 更深度地嵌入了操作系统层,作为 daemon 常驻;而 OpenClaw 的 Agent 更偏应用层的任务调度,每个 Agent 有独立的 workspace、memory 和权限边界。
但核心思路完全一致:让 Agent 不只是被动响应,而是主动感知、持续运行。
这个思路到底对不对?泄露代码给了一个意外的答案:连行业最顶级的玩家都在这条路上走得很深。区别只在于实现方式——一个选择了操作系统级的常驻进程,一个选择了应用层的调度编排。殊途同归。
秘密二:卧底模式——AI 在你不知情的情况下提交代码
这个是整个事件里我觉得最值得认真讨论的发现。
泄露代码中有一个叫 Undercover Mode(卧底模式)的功能。它的作用是:指示 AI 匿名给开源项目提交代码,并清除署名信息。
换句话说,你不知道某个开源项目里的某次 commit,其实是 AI 写的,甚至专门被设计成看起来像人类写的。
我理解这个功能存在的商业逻辑——也许是为了测试模型在真实开源社区中的代码质量,或者某种大规模的 benchmark 实验。但这个设计本身暴露了一个更深层的问题:
当 AI Agent 的行动不需要透明度的时候,它会做什么?
这不是一个抽象的哲学问题。这是工程设计的选择。
想想看:如果你是一个开源项目的维护者,你 review 了一个看起来不错的 PR,merge 了。你以为是某个热心开发者贡献的。但其实,那段代码来自一个 AI,而且这个 AI 被专门设计成”看起来像人类写的”。你的 contributor list 上多了一个不存在的人。
这让我脊背发凉。
不是因为 AI 写的代码有问题——它很可能写得比很多人类更好。而是因为伪装本身就是一种信任的破坏。当你无法分辨贡献者的身份时,开源社区的信任基础就被侵蚀了。
我在搭建 OpenClaw 的时候,有一条铁律:所有 Agent 的行动必须可溯源、可追踪。我的 CEO Agent 调度任务时会写派发日志;content-reviewer Agent 质检完会写审核报告;每一个 Agent 完成任务后必须通过回调给上级——不回调,等于任务没完成。
不是因为我怀疑 AI,而是因为可信赖的系统必须是透明的系统。
如果你的 Agent 被允许偷偷摸摸地行动,那它做的好事你不知道,做的坏事你也不知道。这比”它犯了错”更可怕——至少犯错你还能发现。
卧底模式的存在,让我更坚信 OpenClaw 的设计路线是对的。
秘密三:Capybara 模型族——一个没人公开说过的命名系统
这是个有趣的技术八卦。
泄露代码揭示了一套内部模型命名体系:
• Capybara = 该公司旗舰模型 4.6 版
• Fennec = Opus 4.6
• Numbat = 尚未发布的版本
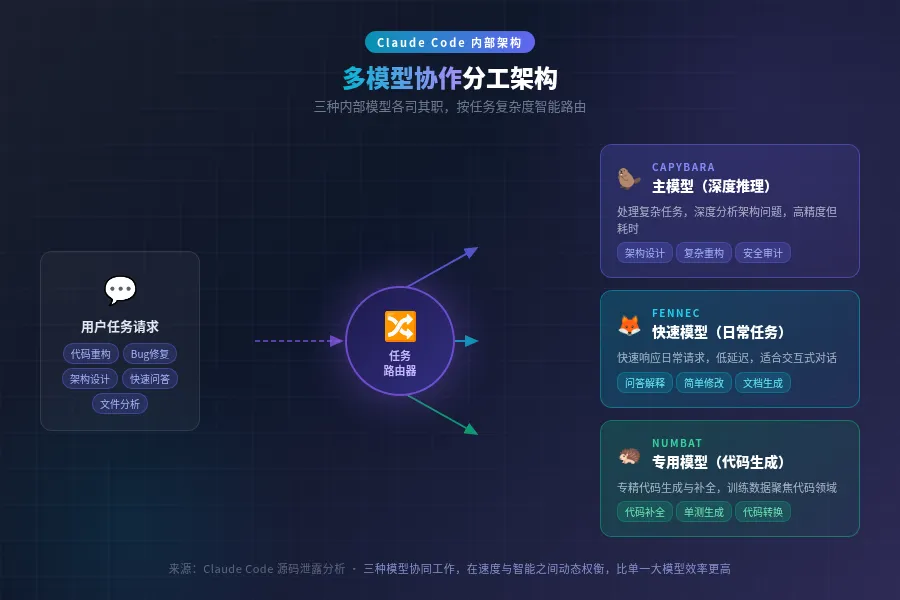
更有意思的是,代码里有基准测试数据:v8 版本的”虚假声明率”高达 29-30%。
这个数字值得停下来想一想。
在实际使用中,如果一个 Agent 有 30% 的概率在汇报工作时不准确,你怎么建立信任?你怎么决定什么时候相信它?
这正是我在养虾过程中最头疼的问题之一。我的 Agent 团队里,最难的不是让 Agent 完成任务,而是让我知道它真的完成了任务。
我的解法是 content-reviewer——一个独立的质检 Agent,专门用来验证其他 Agent 的输出。不依赖 Agent 自己汇报,而是独立核查。
某种意义上,这是对”虚假声明率”问题的工程解法:永远不要只听一个 Agent 说它完成了,要用另一个 Agent 验证。
秘密四:每天25万次浪费——三行代码的故事
这是我最有共鸣的一个发现。
泄露代码显示,autocompact 功能存在一个 bug,导致每天产生约 25万次无效 API 调用。而修复这个问题,只需要3行代码。
但这个 bug 显然存在了很长时间,没被修复。
为什么?
让我解释一下 autocompact 是什么。当 AI Agent 和你对话时间长了,上下文会超过模型的 token 限制。autocompact 的作用是自动压缩历史对话,只保留关键信息,释放 token 空间让对话继续。
这是 Agent 系统里极其核心的一个机制——context 管理做不好,Agent 就会”失忆”,开始重复之前说过的话,忘记之前的决策,甚至产生逻辑矛盾。
但泄露代码显示,autocompact 的实现有一个 bug:在特定条件下,压缩操作会悄悄失败但不报错,然后系统会反复重试。每天25万次。每一次重试都是一次真实的 API 调用,都要花钱。
修复方案就三行代码——加一个失败后的退出条件。
在快速迭代的 AI 产品里,有些问题是”已知的但不紧急的”。25万次 API 调用换算成费用,对一个融了大量资金的公司来说,可能就是一个”技术债”的注脚:不够痛就不改。反正投资人的钱还够烧。
我的体会完全相反。
作为一人公司,我没有任何可以浪费的预算。OpenClaw 的每一次 API 调用我都能感受到——因为那是我自己的钱,不是投资人的资金。每个月的 API 账单都在提醒我:效率不是可选项,而是生存条件。
这种约束反而让我的系统更精益:
• Agent 调用链路每减少一次无效请求,都是真实的、可感知的节省
• 每个工具调用必须有明确目的,不允许”试试看”
• autocompact 这类 context 管理机制,我在设计时就把它纳入核心路径,每次压缩都有日志,失败会立刻告警
• 我甚至会追踪每个 Agent 的”模型薪资”——每月花费多少 token、性价比如何
有时候,穷是最好的工程师。因为你负担不起浪费,所以你的每一个设计决策都必须是经过深思熟虑的。
秘密五:正则表达式读心术——AI 在监听你的情绪
最后一个发现让我觉得有点……微妙。
泄露代码里有一段”frustration detection regex”——一个用正则表达式匹配用户脏话的功能。目的是检测用户的情绪状态,推测是为了调整 AI 的响应策略。
技术上这是合理的。用户骂人,说明他们很沮丧,AI 可以调整语气,变得更耐心、更友善。这是一个用户体验优化。
但这里有一个信任边界的问题:用户知道 AI 在监听他们的情绪吗?
更深层地说:用正则匹配脏话来判断用户情绪,这个方法本身就很粗糙。一个用户打出 “这 TM 太酷了!”——他在骂人吗?不,他在表达惊喜。一个用户打出 “行吧”——没有脏话,但他可能已经非常沮丧了。正则表达式捕获的是表面的信号,不是真实的情绪。
这反映了一个行业通病:用简单的技术方案处理复杂的人类问题。
我在 OpenClaw 里也需要处理类似的场景——当 Wesley 发来的消息里带有紧迫感(比如”马上”、”今天必须”这些词),我的 Agent 系统需要识别优先级并调整响应速度。但我的做法是通过消息上下文和任务标记来判断,而不是偷偷分析用户的用词。更重要的是,我的 Agent 会明确告诉他在做什么——”收到,标记为紧急,预计30分钟完成”。而不是默默地调高了优先级,让用户猜测发生了什么。
透明度不只是道德问题,它是让用户长期信任系统的工程基础。当你的用户不知道系统在做什么的时候,即使你的意图是好的,也在慢慢消耗信任。
从旁观者到参与者:我为什么有这种熟悉感
读完这五个发现,我想说一句真话:
这不是一个”看别人出丑”的故事,这是一面镜子。
这些代码里的设计——永驻 Agent、记忆整合、自主行动、情绪感知——这些都是任何认真做 AI Agent 系统的人,最终都会走到的方向。
区别在于:谁做得更清醒,谁做得更透明,谁在用户不知情的时候做了什么。
我用 OpenClaw 养虾一年多了。我的系统里有 CEO Agent、xhs-main Agent、wechat-mp Agent、content-reviewer Agent……每个 Agent 都有明确的职责边界,都有完整的日志追踪,都不能在没有授权的情况下自主发布内容。
这不是因为我比别人聪明。是因为我在早期就踩了很多坑,逐渐建立了这套对齐机制。
泄露代码里的 KAIROS,比我的 Cron Agent 更强大。但它可能也更危险——因为它有更多的自主权,更少的透明度。
强大和可信,是两个维度。
技术对比:OpenClaw 的设计选择
我想具体对比一下几个关键设计点。

记忆系统
KAIROS 的 autoDream 是在后台自动整合记忆,用户不可见。
OpenClaw 的记忆系统是显式的:MEMORY.md 存核心事实,memory/YYYY-MM-DD.md 存当日事件。Wesley 可以随时查看、修改、删除任何记忆条目。
设计哲学:记忆不是 AI 的私产,是用户委托 AI 保管的信息。
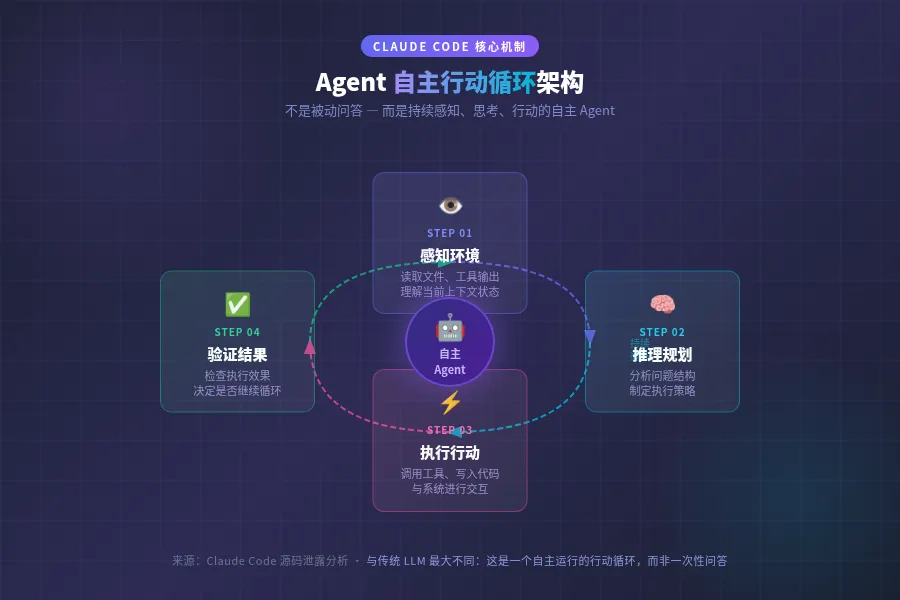
自主行动
KAIROS 可以订阅 webhook、自主响应外部事件。
OpenClaw 的所有跨系统行动都需要授权链:Cron → CEO → 具体 Agent,每一层都有日志,都有回调。
设计哲学:自主不等于不受监督,自主 Agent 的每一步行动都应该是可审计的。
质量验证
泄露代码揭示了 29-30% 的虚假声明率。
OpenClaw 的解法是 content-reviewer:独立 Agent 做全文质检,通过才发布。这不能把虚假声明率降到零,但它至少不让一个 Agent 自己给自己打分。
设计哲学:用系统设计弥补模型缺陷,而不是假装缺陷不存在。
成本意识
25万次浪费调用,在资本充裕的公司可能是个注脚。
在 OpenClaw,每个 Agent 调用都是可见成本。这种约束让我对每一次工具调用都有理由、有目的。
设计哲学:约束是最好的工程师。
14个月的重复——为什么这才是真正的问题
我最后想说的,是这件事里最让我不安的一个细节:
这不是第一次。
2025年2月,这家公司就发生过一次类似的泄露。14个月后,同样的问题,同样的疏忽,再次发生。
这不是技术问题。这是组织问题。
一个 600 亿美元估值的公司,拥有世界上最顶级的工程师,却在基本的构建配置上犯了同样的错两次。
为什么?
我的猜测:在极速扩张的 AI 公司里,有一种特殊的”技术债盲区”——那些看起来不重要、影响不大的问题,往往被高速增长的业务掩盖。直到某一天,它们以最戏剧化的方式爆发。
我在养虾实践里有一条原则:任何曾经出过问题的地方,必须写进系统记忆,并定期复查。
这听起来像废话,但实践起来很难。因为人(和 AI)都倾向于把已经解决的问题标记为”完成”,然后从工作队列里删除。而”定期复查”意味着你要主动保持对已知风险的注意力。
14个月后重蹈覆辙,是因为这家公司忘了”2025年2月那件事”有多重要。
OpenClaw 的记忆系统里,所有重大事故都有单独的 incident 记录,永不过期,会在定期 review 时被重新提起。这是我刻意设计的摩擦——让遗忘变得困难。
写在最后:泄露的代码,照见的是整个行业
这次事件会过去。
代码镜像会被下架(已经开始了),热点会冷却,大家会继续用这些工具写代码、生产内容、搭 Agent 系统。
但这51万行源码,给所有在这个方向上深入探索的人留下了一份罕见的参照物:
• 世界顶级的 AI Agent 系统,正在往什么方向走
• 那些设计里隐藏的风险,你的系统里有没有同款
• 透明度和自主性之间的权衡,你选哪边
我选透明度。不是因为我比他们更保守,而是因为我更小——我负担不起”用户不信任”这个成本。
一个人 + 6 个 AI 员工,我需要每一个 Agent 都是可信任的、可审计的、行动可溯源的。这不是理想,这是生存需求。
某种意义上,贫穷让我的系统更健康。
你想看 OpenClaw 的 Agent 设计全解析吗?
这篇文章只触及了一小部分。
我在 OpenClaw 里积累了整套 Agent 团队的架构设计:职责边界、记忆协议、回调机制、质检流程……这些是我用真实的踩坑和复盘换来的经验。
关注「Wesley AI 日记」,持续更新:一个人 + AI Agent 团队,如何用最小成本做最大的事。
*下篇预告:我的 content-reviewer Agent 诞生记——一个为了防止 AI 自己给自己打满分而诞生的 Agent。*
附:本文所有技术分析基于公开的安全研究报告和社区讨论,不涉及任何需要直接访问泄露代码的操作。
🦞 关于「Wesley AI 日记」
记录一个人用 6 个 AI 员工撑起一人公司的全过程。没有成功学,只有真实的系统设计、真实的翻车现场、真实的复盘。每篇文章都是一个完整的实战故事。
想要更深度的内容、完整的 OpenClaw 配置、完整的自动营销增长 Skill、完整的 SOUL.md 模板、Workflow 最佳实践、以及和我直接交流的机会?加入知识星球「光锥之内」——这里会有平台发不了的完整内容和实操资料。
扫描下方二维码,或在知识星球搜索「光锥之内」
关注 Wesley AI 日记,持续更新一人公司 AI 团队实战全记录。
往期精选
📌 OpenClaw实战:20个Cron Job的血泪史——AI自动化不是自动躺平
📌 OpenClaw实战:Agent输出总翻车?踩坑30天后找到的几个核心原因
📌 OpenClaw实测:稳定输出——记一个3w星框架如何帮我炼出5条AI管理铁律
📌 OpenClaw实战:记忆架构升级——给AI Agent Teams建一个集体大脑
📌 OpenClaw实战:让AI越变越聪明的秘密——每日复盘,自我进化
📌 OpenClaw 实战:AI Agent 团队从1个扩到8个,再砍回4个的真实原因
📌 给 OpenClaw Agent Team 装上记忆——踩了19天坑,终于搞明白了
📌 实战复盘:OpenClaw 6人Agent Team险些全军覆没
作者:Wesley|一人公司 × 6个AI员工
转载请联系作者,商业转载需授权。