 夜雨聆风
夜雨聆风





Claude Code Skills 源码拆解:Prompt 如何变成可复用的工作流
这是 Claude Code 源码泄露后,结合源码整理的一手技术分析。不管你是 Claude Code 的深度用户,还是在做 Agent 相关的学习或工作,或许都能从中找到一些启发。本文是系列文章中的一篇,完整系列目录见文末「细说 Claude Code」。
一个你一定遇到过的问题
用 AI 工具用久了,你一定积累了一些”好用的 prompt”。
比如让 Claude 帮你 review PR 时,你每次都要说一串要求——”检查安全漏洞、看看有没有未处理的错误、确认测试覆盖率”。做代码迁移时,你总要先说明”保持原有行为不变、先写测试再改代码、每次只改一个文件”。
这些经验散落在聊天记录的各个角落。下次要用?翻记录复制粘贴。同事要用?微信发过去。换了个项目?重新从头组织一遍。
这不对。如果 prompt 是一种能力,它就应该像代码一样可以封装、命名、复用、版本控制。
Skill 是什么
Skill 的核心想法很简单:把一段 prompt 打包成一个文件,给它一个名字,然后像调函数一样用。
比如你想要一个专门拿来做代码 review 的 skill,让 Claude 每次 review 都按固定标准检查安全、错误处理、测试覆盖和代码可读性。
这时候你会创建一个 SKILL.md 文件:
---name: review-prdescription: Review code changes for quality, security, and best practices---Review the recent code changes. Focus on:1. Security vulnerabilities (injection, auth, data exposure)2. Error handling (are all error cases covered?)3. Test coverage (are the changes tested?)4. Code clarity (is it readable and maintainable?)Provide feedback organized by priority: Critical → Warning → Suggestion.-
• name: review-pr的意思是把这套能力命名成/review-pr -
• description: ...是告诉 Claude:这个 skill 适合用在代码 review 场景 -
• YAML 后面的正文,才是真正的 review 清单
也就是说,这个 skill 并不是“任何时候都能用的通用 prompt”,而是一个专门用于“检查代码变更质量”的小工作流。
上面这个 review-pr 例子其实是 最简版本,只用了 name 和 description 两个字段。根据源码里的 frontmatter 解析逻辑,以及 workspace 里 skill-creator 这类示例 skill 的写法,YAML 这一段还可以继续扩充。可以先把常见字段理解成下面这张表:
|
|
|
|
|---|---|---|
name |
|
review-pr、deep-research |
description |
|
|
version |
|
|
arguments |
|
|
argument-hint |
|
|
allowed-tools |
|
|
when_to_use |
|
description 一起帮助模型判断 |
user-invocable |
/skill-name 调它 |
false 时,更偏后台自动能力;后面“技巧 3”会讲它和 disable-model-invocation 的组合 |
disable-model-invocation |
|
true 时,通常表示高风险或你不想让它自动触发;后面“技巧 3”会展开 |
context |
|
context: fork;后面“两种执行模式”会详细解释 |
agent |
|
Explore、Plan、general-purpose;后面 deep-research 例子会展开 |
paths |
|
|
hooks |
|
|
effort |
|
|
model |
|
|
shell |
|
|
所以可以把 YAML frontmatter 理解成:前两三个字段是在定义“它是什么 skill”,后面这些扩充字段是在定义“它怎么触发、怎么运行、运行时受什么限制”。
然后在 Claude Code 里直接 /review-pr 就行了。Claude 会按照你定义的步骤来执行 review。
你可以把它放在 ~/.claude/skills/review-pr/SKILL.md(所有项目可用),也可以放在项目的 .claude/skills/review-pr/SKILL.md(提交到 git,团队共享)。
不只是”保存 prompt”——还解决上下文爆炸问题
Skill 的设计初衷当然是复用 prompt。其实它还解决了另一个更深层的问题:上下文爆炸。
想象一下这个场景:你的团队定义了 15 个规范——PR review 清单、代码迁移步骤、提交规范、部署流程、安全审查要求……如果这些全部塞进 CLAUDE.md 里,会怎样?
CLAUDE.md 是每次对话都加载的。15 个规范加起来可能有几千行,直接吃掉你上下文窗口的一大块。更糟的是,当对话中充斥着大量”背景规范”,模型对每条规范的注意力都会降低——你写了”必须先写测试”,但它被淹没在几千行其他指令里,模型出来就忘了。
Skill 的解法是渐进式披露(progressive disclosure):
-
• 平时:只把 skill 的名字和一句话描述(最多 250 字符)放在上下文里,告诉模型”你有这些能力可以用” -
• 按需:只有当模型判断需要用某个 skill 时,才把完整的 prompt 内容展开加载 -
• 用完:skill 执行结束后,这段展开的内容就不再占位了
就像一个工具箱——你不会把所有工具都摊在桌子上,而是看目录,需要哪个再拿出来用。
从源码 prompt.ts 的 formatCommandsWithinBudget() 可以看到具体实现:每个 skill 在技能列表里的说明先最多保留 250 字符;所有 skill 的这些说明加起来,最多占上下文窗口的 1%(默认大约200k token上下文的话,是 8000 字符)。如果总量还太大,就继续压缩部分 skill 的说明;再不够,部分 skill 就只显示名字。这样你定义很多 skill,也不会把上下文撑爆。
两种执行模式
源码 SkillTool.ts 显示 Skill 有两种执行路径。你可以把它理解成一个很直观的区别:
-
• 内联模式:像“Claude 留在当前聊天里,现场照着这份说明做事” -
• Fork 模式:像“Claude 另外派出一个子 Agent 单独去干活,干完回来汇报结果”
两者的核心差别,不是 skill 内容写法完全不同,而是:这段 skill prompt 最终是塞进当前对话继续执行,还是交给一个独立子 Agent 去执行。
如果你只记一个判断标准,可以先记这个:
-
• 这件事强依赖当前对话上下文,就优先用内联 -
• 这件事会读很多文件、跑很多步骤、产生很多中间过程,就优先用 fork
内联模式(默认)
Skill 的 prompt 内容直接展开到当前对话里,Claude 在主上下文中按指令执行。
可以把它想成:你正在和 Claude 对话,突然递给它一张“小抄”,让它接下来按这张小抄做事。 Claude 没有离开当前会话,也没有换一个执行者,只是把这份 skill 当成当前任务的额外操作说明。
所以内联模式下,Claude 手上同时有三类信息:
-
1. 你们前面已经聊过的上下文 -
2. 当前用户这一轮的请求 -
3. 这个 skill 展开的完整 prompt
这也是为什么内联模式特别适合“结合上下文继续往下做”的任务。比如:
-
• 你们刚讨论完一个发布方案,现在要 /deploy staging -
• 你刚贴了一段代码,接着要 /review-pr -
• 你们已经明确了需求边界,现在让 Claude 按某个 skill 生成实现方案
好处:Claude 能看到完整的对话历史。你可以说”按照我们刚才讨论的方案,用 /deploy 部署”,Claude 知道”刚才讨论的方案”是什么。
坏处:如果 skill 的执行过程产生大量输出(比如读了很多文件),这些内容会留在主上下文里。
这点很关键。因为内联模式不是“开了个临时空间”,而是直接在主对话里展开执行。所以 Claude 为了完成 skill 去读的文件摘要、分析过程、临时结论,都会挤占主上下文窗口。
换句话说,内联模式的优点是“记得住前文”,代价是“执行痕迹也会留在前文里”。
所以内联模式最适合:任务不算太重,而且确实需要紧贴当前对话来做判断。
Fork 模式(context: fork)
context: fork 的意思是:不要在当前对话里直接展开这个 skill,而是把它交给一个独立子 Agent 去执行,最后只把结果带回主对话。
源码里有一句话,几乎可以直接拿来当判断标准:
Only set context: fork for self-contained skills that don't need mid-process user input.
翻成大白话就是:只有当这个 skill 本身就是一个自包含任务,不需要中途再问用户,也不强依赖当前对话里的隐含前提时,才适合开 fork。
所以 fork 的核心特点可以直接记成两点:
-
• 优点:中间过程不会把主上下文塞满,适合重任务 -
• 代价:子 Agent 不天然继承主对话历史,所以任务必须写得明确
实操上可以这样判断:
-
• 适合 fork:搜索文档、跑测试、扫大量代码、生成一份独立调研结果 -
• 不适合 fork:长期参考规则、需要结合刚才对话判断的任务、需要中途和用户来回确认的任务
另一个常见坑,官方原文也说得很直接:
context: forkonly makes sense for skills with explicit instructions. If your skill contains guidelines like “use these API conventions” without a task, the subagent receives the guidelines but no actionable prompt, and returns without meaningful output.
比如你有一个 skill,不是让 Claude 顺手回答几句,而是要它认真去代码库里做一次深度调研。这个 skill 更像是在说:”别在主对话里边聊边做了,开个专门的只读子 Agent 去查清楚,再回来汇报。”
---name: deep-researchdescription: Research a topic thoroughly in the codebasecontext: fork # 在独立子 Agent 中执行agent: Explore # 用 Explore Agent 的只读工具集---Research $ARGUMENTS thoroughly:1. Find relevant files using Glob and Grep2. Read and analyze the code3. Summarize findings with specific file references这里可以把这个 skill 文件先拆成两层来看:上面的 YAML 负责配置“怎么运行”,下面的正文负责定义“运行时做什么”。
-
• YAML 部分是元数据:比如 context: fork表示交给子 Agent 执行,agent: Explore表示这个子 Agent 用偏只读、偏调研的能力集 -
• 正文部分才是真正注入给模型的任务指令:这里的 Research $ARGUMENTS thoroughly和后面的 1、2、3 步,定义了子 Agent 具体要完成什么
说白了,就是给 Claude 一个明确的研究任务,让它在独立子 Agent 里查清楚,再把结果带回主对话。
Skill 的调度方式
一次只能执行一个 skill
源码注释写得清楚:
Only one skill/command should run at a time, since the tool expands the command into a full prompt that Claude must process before continuing.
为什么?因为 skill 展开后是一大段 prompt(可能几百行),模型需要先”消化”完这段指令再继续。如果同时展开两个 skill 的 prompt,模型会搞混哪段指令属于哪个 skill。
这条限制的实际含义不是”一次请求只能做一件事”,而是:同一时刻只展开一个 skill。
那你想”先 review 再 deploy”怎么办?让模型自己串行调——你说”帮我 review 代码然后部署”,Claude 会先调 /review-pr,收到结果后再调 /deploy。
多 Skill 场景:一次请求怎么用到多个 Skill?
前面说了”一次只能执行一个 skill”。那用户说”帮我 review 代码然后部署到 staging”怎么办?
答案:模型自己串行调用多个 SkillTool。
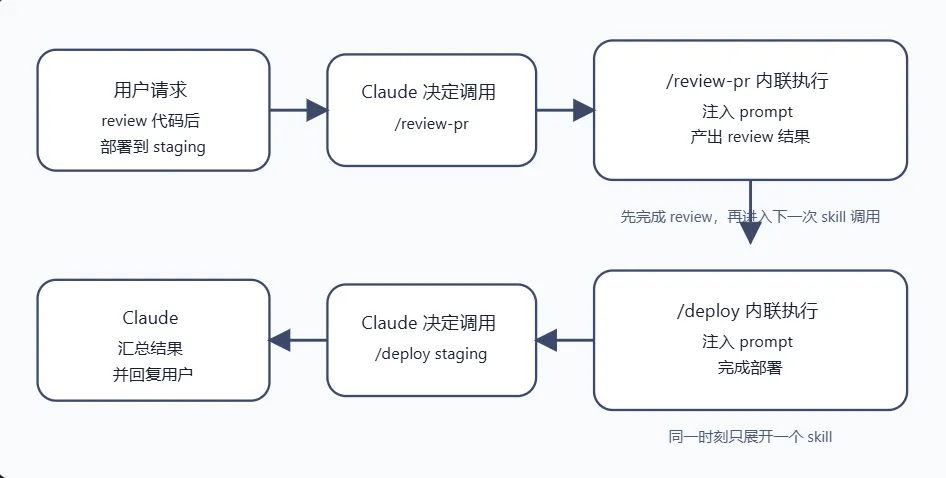
如果你经常需要”先 A 再 B”,有三种做法:
-
1. 组合 Skill:创建一个新 skill,在 SKILL.md 里描述完整流程 -
2. 让模型编排:直接用自然语言说”先 review 再 deploy” -
3. /batch:大任务自动分解,每个子任务在独立 worktree 并行执行
运行配置和边界
description 被截断可能导致 skill 不被使用
你定义了一个 skill,但 Claude 从来不调它,很多时候不是 skill 写错了,而是 Claude 根本没看到完整说明。
所有 skill 的 description 总预算只有上下文窗口的 1%。如果你有 30 个 skill,每个 description 平均只能分到 260 字符,其中 250 字符是上限,超出的只保留名字。如果你的 skill description 第 251 字符起才写了关键触发词,模型就看不到了。
所以 description 的职责不是”写漂亮简介”,而是尽快让模型知道什么时候该调用这个 skill。
写法上也有一个很实用的经验:把 description 当触发器,不要当简介。 最好在前 120-180 个字符里就交代清楚“Use when…”场景和触发词,别把真正有用的关键词放到后面。
解决方案:把最重要的使用场景放在 description 的前 250 字符。或者设置 SLASH_COMMAND_TOOL_CHAR_BUDGET 环境变量调高预算。
Skill 可以有自己的 Hook
再比如,你有一个 deploy 类 skill,平时最大的问题不是”Claude 不会部署”,而是”它在部署过程中可能直接跑 Bash 命令,缺一道安全检查”。这种场景下,hook 的作用就很清楚了:给这个 skill 临时加一层护栏。
---name: secure-deploydescription: Deploy with security checkshooks: PreToolUse: - matcher: "Bash" hooks: - type: command command: "./scripts/security-check.sh"---重点不是“怎么部署”,而是“怎么给某个 skill 临时挂一个安全护栏”。只要进入这个 deploy skill,它后面凡是想调用 Bash,都先过一遍安全检查脚本。
这里也值得拆开解释一下:
-
• hooks不是 skill 正文的一部分,而是 frontmatter 里的运行配置 -
• PreToolUse的意思是:在调用工具之前先拦一下 -
• matcher: "Bash"表示只匹配 Bash 这个工具 -
• command: "./scripts/security-check.sh"表示每次这个 skill 想跑 Bash 时,先执行你的安全检查脚本
这些 hook 只在 skill 激活期间生效,skill 完成后自动清理。你可以给 deploy skill 加一个安全检查 hook,不影响其他工作流。
如果你想继续看更完整的 hook 机制、事件类型和实战例子,可以看我之前写的这篇:Claude Code Hooks 拆解:控制你的 AI Agent 行为。
动态注入 shell 输出
还有一种常见需求:你不是想让 Claude 空口总结一个 PR,而是希望它先拿到真实的 PR diff、评论、改动文件,再基于这些信息给出总结。这个时候就适合用动态注入。
---name: pr-summarydescription: Summarize a pull request---## PR 上下文- PR diff: !`gh pr diff`- PR 评论: !`gh pr view --comments`## 你的任务基于以上信息总结这个 PR...这里做的事情很直接:先取实时数据,再让 Claude 基于这些数据工作。不是让 Claude 自己去想办法拿 PR 信息,而是系统先把 diff 和评论拉下来,再交给 Claude 做总结。
!command“ 就是一种“运行前取数”语法:系统会先执行这条 shell 命令,把输出结果填进 prompt,然后 Claude 再基于这些真实数据工作。它不是让 Claude 先看到命令,再自己决定要不要执行。
所以这里的执行顺序其实是:
-
1. 系统先执行 gh pr diff -
2. 再执行 gh pr view --comments -
3. 把输出塞进 prompt -
4. Claude 基于已经准备好的 PR 数据做总结
这很适合把 Git、CI、工单系统里的实时信息先取回来,再交给 Claude 分析。
写法上也别只堆命令,最好顺手说明每份数据是拿来干什么的。否则 Claude 虽然拿到了 diff、评论、文件列表,也不一定会按你想要的方式使用它们。
从 Skill 到 Plugin
再往上走一层,就会到 plugin。
可以先这么理解:skill 是一个具体能力,plugin 是把一组 skills、agents、hooks 甚至 MCP 配置一起打包分发的容器。 官方文档也明确把两者区分开了:单项目里自己写几个 .claude/skills/,属于 standalone configuration;当你想把整套能力跨项目复用、做版本发布、放进 marketplace 给团队或社区安装时,就更适合做成 plugin。
superpowers 就是个很典型的例子。它想解决的问题也很明确:很多人用 Claude Code 时,会直接上手写代码,跳过澄清需求、拆计划、验证结果、代码审查这些步骤。superpowers 做的,就是把这些更稳的工作方式提前封装好,让 Claude 做事时更像一个有流程意识的工程师。
比如它里面不是只有一个 /review 之类的小命令,而是会提供一整套彼此配合的 skills:需求澄清和 brainstorming、写计划、按计划执行、TDD、系统化调试、代码审查、完成前验证、并行 agent 协作、git worktree 工作流等。官方 marketplace 对它的描述也是一个 core plugin,提供 20+ battle-tested skills,再配上一组相关命令、skills 搜索能力,以及会话启动时的上下文注入。
所以 superpowers 不是“教 Claude 做一个动作”,而是“给 Claude 装上一套成体系的开发 workflow”。也正因为它包含的是很多互相配合的能力,所以更适合以 plugin 的形式分发,而不是只写成一个独立 skill。
所以这里有个层级关系最好分清:
-
• skill:一个具体能力,比如 review、deploy、deep-research -
• plugin:一组相关能力的分发包,里面可以同时放很多 skills,以及配套的 agents、hooks、MCP servers
这也是为什么你会看到很多像 superpowers 这样的工具:当一套 workflow 不再只是“一个命令”,而是“很多互相配合的技能集合”时,用 plugin 来打包会比散落在 .claude/skills/ 里更容易共享、升级和维护。
好用的 Skill 写法技巧
前面讲的是机制。下面这些更像是把 skill 写得更容易触发、更容易遵循、更不浪费上下文的实战经验。
技巧 1:把要求改写成 checklist,通常比散文更容易遵循
如果一个 skill 的目标是”按固定标准检查”或者”按固定流程执行”,用 checklist 往往比写成长段说明更稳。
比如你要做一个 review 类 skill,目标是让 Claude 检查代码变更,而不是自由发挥地评论几句。先看一个不太理想的写法:
Review this change carefully. Pay attention to security, error handling,test coverage, and whether naming is clear.再看更好的写法:
Review this change using the following checklist:1. Security: Is there any injection risk, auth bypass, or data leak?2. Error handling: Are failures surfaced and handled consistently?3. Tests: Are happy path and edge cases both covered?4. Maintainability: Are names, structure, and abstractions still clear?Output format:- Critical- Warning- Suggestion这个例子其实就是在定义一个“审查型 skill”:目标不是生成代码,而是按照固定维度检查代码变更,并且把输出整理成固定栏目。
为什么这类写法更有效?
-
• 模型更容易把任务拆成几个稳定检查点,而不是自由发挥 -
• 你也更容易看出它漏检了哪一项 -
• 这类结构天然适合 review、发布前检查、PR 总结、代码迁移等工作流
严格说,源码没有写死”checklist 会更好”这条规则;但从官方文档反复用 numbered steps、固定模板、示例输出的写法,再结合内建 skill 的工作方式,可以看出 Claude 更擅长执行结构化约束,而不是猜你的隐含标准。
技巧 2:把 SKILL.md 写成路由器,把细节放到 supporting files
这是 skill 最值得学的设计模式之一:主文件只写任务入口和导航,细节放到旁边的参考文件里。
官方文档明确建议 SKILL.md 控制在 500 行以内,大块参考资料放 supporting files。这样做不是为了好看,而是为了配合前面讲过的渐进式披露。
常见结构大概是这样:
my-skill/├── SKILL.md├── references/│ ├── api.md│ ├── examples.md│ └── edge-cases.md└── scripts/ └── validate.sh如果你的 skill 涉及很多规则、示例和边界情况,不要把它们全堆进一个文件。更好的思路是:SKILL.md 只负责总控和分流。
也就是说,SKILL.md 不要试图塞下所有知识,而是写成:
-
• 这个 skill 是干什么的 -
• 先做哪几步 -
• 遇到什么情况去读哪个 supporting file -
• 需要确定性处理时去跑哪个脚本
比如一个“生成 assertion”的 skill,可以这样写:
When generating assertions:1. First read references/assertion_rules.md for the scoring rules.2. If the task is about factual claims, also read references/intent_factual.md.3. If examples are needed, consult references/examples.md.4. Before finalizing, run ${CLAUDE_SKILL_DIR}/scripts/validate.sh.这个例子展示的是“总控 + 分资料”的写法:主 skill 只负责告诉 Claude 当前在做 assertion 生成,具体规则去哪个 reference 文件读,最后再跑哪个脚本校验。
这就是你说的”渐进式披露引用其他文章”对应到 skill 里的最佳实践。不是把其他文章全文贴进 SKILL.md,而是告诉 Claude 什么时候该去读哪份材料。
再往前走一步,SKILL.md 最好不只是说“有问题小心处理”,而是明确写成“遇到什么情况,就去读哪个文件”。前者只是抽象提醒,后者才是真正能执行的路由规则。
技巧 3:把“给 Claude 用”和“给用户手动用”分开设计
官方文档其实给了一个很实用的二分法:
-
• 参考型 skill:让 Claude 在相关场景自动加载 -
• 任务型 skill:只允许用户显式调用
对应字段就是:
disable-model-invocation: trueuser-invocable: false常见组合:
-
• 参考知识库:user-invocable: false适合”旧系统背景知识”、”API 约定”、”领域术语解释” -
• 高风险动作:disable-model-invocation: true适合 deploy、commit、发消息、改数据库这类有副作用的流程
这个区分很重要,因为它直接影响一个 skill 是被当成”背景能力”,还是被当成”显式命令”。
技巧 4:用 paths 缩小自动触发范围
这是很容易被忽略,但实际非常有用的字段。
比如你做的是一个 React 组件迁移 skill,它就没必要在后端 Python 文件、SQL 目录、基础设施脚本里刷存在感。如果一个 skill 只跟某类文件有关,不要让它对整个仓库都可见。
---name: react-migrationdescription: Migrate legacy React components to hooks and modern patternspaths: - src/components/**/*.tsx - src/pages/**/*.tsx---这类写法的意思很简单:只在特定文件范围内更容易想到这个 skill。它不是整个仓库通用的迁移规则,而是专门服务于 React 组件目录。
这样做的好处是:
-
• Claude 只有在处理这些路径时才更可能自动想到它 -
• 能减少无关 skill 的竞争,降低误触发 -
• 在 monorepo 或多技术栈项目里尤其有效
源码 frontmatter 解析里确实支持 paths,官方文档也说明它用于限制 skill 自动激活的文件范围。对大型代码库来说,这比一味堆更多 description 更有用。
技巧 5:把确定性步骤外包给脚本,不要全靠 prompt
如果某个步骤本来就是确定性的,最好别只写一句”请检查一下”,而是让 skill 直接调用脚本。
适合外包给脚本的东西:
-
• JSON / YAML 校验 -
• 固定格式转换 -
• 报表生成 -
• benchmark 聚合 -
• 静态分析结果收集
文档专门演示了这种模式:skill 目录里可以带 scripts/,正文里通过 {CLAUDE_SKILL_DIR} 和 ${CLAUDE_SESSION_ID} 在执行前会被替换。
比如一个 benchmark 汇总类 skill,最后聚合结果这一步就应该交给脚本:
Before finalizing the report, run:```bashpython ${CLAUDE_SKILL_DIR}/scripts/aggregate.py results/${CLAUDE_SESSION_ID}```这个例子想说明的是:最后这一步不是让 Claude 靠语言能力“总结一下 benchmark”,而是直接调用 skill 自带脚本去聚合结果。Claude 在这里负责决定何时运行,脚本负责把结果算准。
这种写法的好处是:让模型负责编排,让程序负责确定性。
技巧 6:给复杂 skill 明确输出模板,不要只说“总结一下”
skill 越复杂,越应该给固定输出骨架。否则模型很可能步骤做对了,但落地结果不稳定。
比如你要做一个风险分析或 review 汇总 skill,最后就不该只让它“总结一下”,而要明确规定输出结构:
## Output format# Summary## What changed## Risks## Missing tests## Recommended next actions这就是典型的“结果型 skill”。重点不在过程,而在于把输出结构卡死,让 Claude 不管分析过程多复杂,最后都落到统一格式里。
这种模板的价值不只是让结果好看,更重要的是:
-
• 方便用户复核 -
• 方便后续脚本处理 -
• 方便做 skill 评测和对比
这一点在你 workspace 里的 skill-creator skill 里就很明显,它大量使用固定目录结构、固定 JSON schema、固定评测输出格式。
技巧 7:复杂分析型 skill 可以埋 ultrathink,但别滥用
这一点如果只看文档,很容易以为“在 skill 里写上 ultrathink 就行”;但结合源码看,最好把两条机制分开理解。
第一条是 ultrathink 关键词触发。源码 thinking.ts 里会检查输入文本里有没有出现 ultrathink,命中后会额外附加一个 ultrathink_effort 提示,把这一轮 reasoning effort 提升到 high。
第二条是 frontmatter 的 effort 字段。源码 loadSkillsDir.ts 会解析 skill 的 effort,SkillTool.ts 再把它真正传到当前执行上下文或 fork 出去的子 Agent 里。也就是说,如果你想让某个 skill 稳定用更高思考强度,显式写 effort 往往比只埋一个 ultrathink 更直接。
所以更准确的理解应该是:ultrathink 更像“这一轮输入里的高强度触发词”,而 effort 更像“这个 skill 的正式运行配置”。
比如下面这两种写法,语义其实不一样。
例子 1:把 ultrathink 当成正文里的触发词
Analyze this migration plan carefully. Ultrathink about architectural risks,rollback strategy, and compatibility constraints before proposing changes.这个写法更像是在说:这一次任务请认真多想一层。它适合偶发的高复杂度分析,比如某次架构评审、一次迁移方案评估。
例子 2:直接把高 effort 配进 skill
---name: architecture-reviewdescription: Review architecture changes and identify design riskseffort: high---Review the proposed architecture change.Focus on tradeoffs, failure modes, scaling limits, and rollback options.这个写法表达的是:这个 skill 默认就是高强度思考模式。只要触发它,就稳定按高 effort 跑,更适合长期存在的复杂分析型 skill。
如果你只是偶尔想让某一轮“想深一点”,正文里出现 ultrathink 就够了;如果你想把“高强度思考”变成这个 skill 的稳定默认行为,那就更适合直接写 effort。
这适合:
-
• 架构评审 -
• 深度调研 -
• 复杂迁移方案 -
• 多方案权衡
但不适合:
-
• 简单格式化 -
• 机械生成 -
• 高频小任务
原因也很直接:thinking 更深通常更贵、更慢。它适合留给少数真正需要推理空间的 skill,而不是变成默认前缀。
小节
-
1. Skill 说到底就是“带名字、带触发条件、带运行配置的 prompt”。 SKILL.md里上面的 YAML 定义它是什么、什么时候触发、怎么运行,下面的正文才是 Claude 真正执行的任务指令。 -
2. Skill 不只是复用 prompt,更是在解决上下文管理问题。 平时只让 Claude 看到 skill 名字和 description,真正需要时才展开完整内容,这就是渐进式披露。 -
3. 把 skill 写好,关键不在“文案优美”,而在“结构清楚、触发准确、执行稳定”。 description 要前置触发词,正文最好写成 checklist 或明确步骤,复杂规则放 supporting files,确定性环节交给脚本。 -
4. 运行方式决定了 skill 的使用边界。 内联模式适合结合当前对话继续判断; context: fork适合自包含、重执行、低交互的独立任务;hook、allowed-tools、effort、shell 这些字段则进一步决定它运行时的护栏和能力。 -
5. 动态注入让 skill 从“静态说明书”变成“先取数据再分析”的工作流。 !command“ 不是让 Claude 临时决定跑命令,而是系统先执行命令,把结果填进 prompt,再交给 Claude 处理。 -
6. 当能力不再是单个 skill,而是一整套 workflow 时,就会上升到 plugin。 像 superpowers这种工具,说到底就是把很多相互配合的 skills、agents、hooks 打包分发,让 Claude 获得一整套更稳定的工作方式。
附:内建的 bundled skill
|
|
|
|
|---|---|---|
| batch | /batch <指令> |
|
| claude-api | /claude-api |
|
| debug | /debug |
|
| loop | /loop 5m 检查部署状态 |
|
| simplify | /simplify |
|
/batch 最值得关注。你说”把所有 React 组件从 class 迁移到 hooks”,它会自己分析代码库、找出所有需要改的组件、分成独立任务、每个任务在独立 git worktree 里并行执行、跑测试确认、最后各自开 PR。一人干了一个团队的活。
附:源码位置速查
|
|
|
|---|---|
src/tools/SkillTool/SkillTool.ts |
|
src/tools/SkillTool/prompt.ts |
formatCommandsWithinBudget()
|
src/skills/loadSkillsDir.ts |
.claude/skills/ 目录发现和加载 skill 文件 |
src/skills/bundled/ |
|
src/commands.ts |
getSkillToolCommands()
|
src/constants/prompts.ts |
|
src/services/skillSearch/ |
|
#ClaudeCode #ClaudeCode教程 #ClaudeCodeSkills #AI编程 #AIAgent #PromptEngineering #工作流自动化 #插件系统