 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:三级压缩系统,让 AI 用有限的上下文窗口做无限长的任务!
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 72 篇,Claude Code 源码揭秘系列第 4 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let’s explore。无界探索,有术而行。
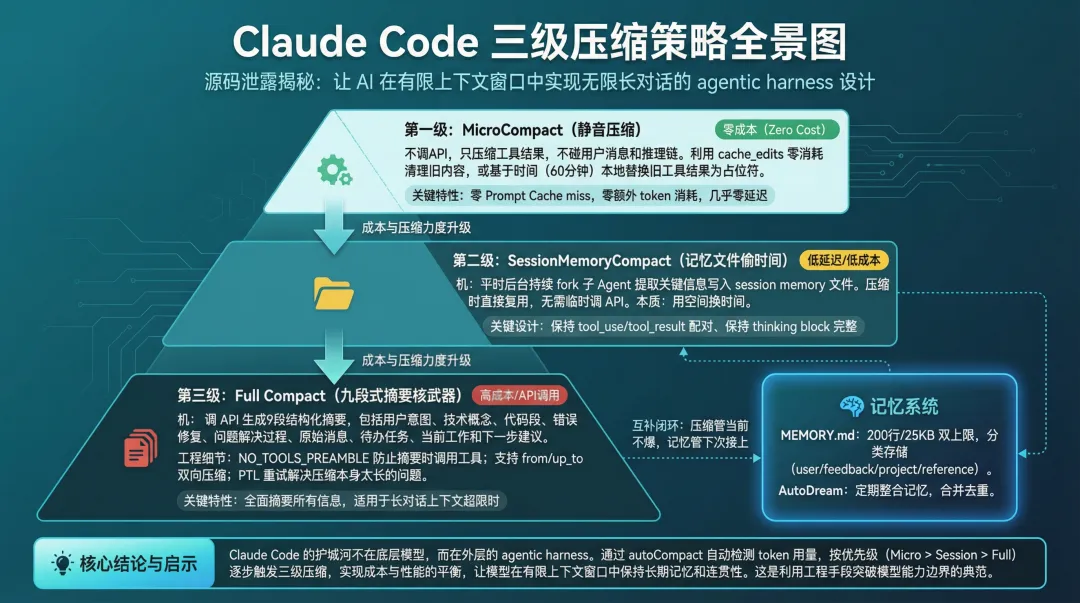
图 1:Claude Code 三级渐进式压缩策略全景图
Fortune 3 月 31 日的独家报道,把 Anthropic 推上了风口浪尖:Claude Code 全部约 51.2 万行 TypeScript 源代码因为一个 NPM 打包失误,意外泄露到了公网。1900 个文件,40 多个工具模块,包括尚未发布的新模型代号:全部裸奔。
但说实话,比起新模型代号,真正让我盯着屏幕反复看的,是那 8 个以 compact 命名的源码文件。
Fortune 的报道里有一句话说到点子上了:Claude Code 的核心能力不是来自底层模型,而是来自包裹在模型外层的 agentic harness。翻译成人话就是:模型谁都能用,但怎么让模型在长达几小时的对话中不”失忆”、不”跑偏”,这才是 Anthropic 真正的护城河。
这个问题每个做 AI Agent 的开发者都绕不开:对话一长,上下文窗口就撑爆了。
1. 长对话为什么是 AI Agent 的命门
先说一个残酷的现实:不管你的模型有多强,上下文窗口总是有限的。
传统做法无非两条路。简单截断:把旧消息直接扔掉,好处是简单粗暴,坏处是关键信息可能跟着一块丢了。滑动窗口:保留最近 N 条消息,比截断好一点,但早期的约束条件、用户的原始意图,照样找不回来。
两条路的问题本质上是一样的:丢掉的不仅仅是信息,还有上下文之间的因果关联。
Claude Code 给出了一个不一样的答案:三级渐进式压缩策略。
思路很清楚:不要等到上下文爆了才处理,而是从轻到重、逐级升级。能不动缓存就不动缓存,能不调 API 就不调 API,实在不行了再上”核武器”。每一级都比上一级成本更高、效果更强,但都尽力保持 Prompt Cache 的命中率。

图 2:Cached MicroCompact vs Time-Based MicroCompact 对比
2. 第一级:MicroCompact:不动声色的”静音压缩”
MicroCompact 是整个压缩体系里设计最精巧的部分。它有两个子策略,一个针对缓存还热着的情况,一个针对缓存已经凉了的情况。
Cached MicroCompact:在服务端悄悄删东西
这个策略的核心是利用 Anthropic 的 cache_edits API。
传统的压缩方式是什么?拿到完整的 prompt,删掉一些旧消息,然后重新发送。这一发不要紧,之前命中的 Prompt Cache 全部失效:因为你改变了缓存前缀的内容,服务端必须重新处理整个 prompt。
cache_edits 的创新在于:直接在服务端缓存的 prompt 前缀中删除旧的工具调用结果,不需要重新发送完整 prompt。
看源码里的实现逻辑:
// 注册工具 ID → 排队 cache_edits 块 → API 层自动应用// 源码路径:src/services/compact/apiMicrocompact.ts (153 行)// 核心思路:告诉服务端"把缓存里第 X 个工具结果删掉"// 而不是"重新发一个没有第 X 个工具结果的完整 prompt"结果是什么?零 Prompt Cache miss,零额外 token 消耗。你删了旧的工具输出,但缓存的主体结构没变,下一轮对话照常命中缓存。
这不是什么复杂的算法创新,而是对 API 能力的极致利用。说实话,看到这个设计的时候,第一反应是”为什么我没想到”。
Time-Based MicroCompact:60 分钟的时间窗口
这个策略更简单直接。
触发条件只有一个:(当前时间 - 最后一条助手消息的时间) > 60 分钟。
为什么是 60 分钟?因为 Anthropic 的 Prompt Cache TTL(生存时间)大约是 5 分钟到 1 小时。超过 60 分钟没活动,服务端缓存大概率已经过期了。既然缓存都凉了,就没必要再小心翼翼地维护缓存结构:直接在本地消息列表里把旧的工具调用结果替换成一句 [Old tool result content cleared]。
// 源码路径:src/services/compact/timeBasedMCConfig.ts (43 行)// 配置:60 分钟阈值,保留最近 N 个可压缩工具结果但不是所有东西都会被清理。源码里明确定义了一个可压缩工具清单:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
为什么这么分?因为工具调用的结果(比如读取了一个文件的内容)在后续对话中大概率不再需要精确值,但 Agent 的推理链和用户的原始意图必须完整保留。这是信息优先级的判断。
MicroCompact 的设计哲学可以概括为八个字:能省就省,该留就留。
3. 第二级:SessionMemoryCompact:用记忆文件”偷时间”
MicroCompact 能处理一部分问题,但当对话真的变得很长:比如你在做一个跨十几文件的重构任务,光删工具结果就不够了。
SessionMemoryCompact 的思路是:不要等到需要压缩的瞬间才开始压缩,而是平时就在后台持续准备。
源码中 sessionMemory.ts(495 行)和 extractMemories.ts(615 行)负责在每轮对话后,fork 一个子 Agent 从对话中提取关键信息,写入一个 session memory 文件。
等到上下文真的需要压缩时,直接用这个现成的记忆文件作为摘要:不需要临时调 API 生成摘要,不需要用户等待,几乎零延迟。
// 源码路径:src/services/compact/sessionMemoryCompact.ts (630 行)// 核心逻辑:// 1. 计算保留消息窗口(最少 10K token,5 条文本消息)// 2. 用后台维护的 session memory 文件替代被裁剪的旧消息// 3. 切割点保持 tool_use/tool_result 配对// 4. 保持 thinking block 完整性有几个细节值得注意:
切割点必须保持 tool_use 和 tool_result 的配对关系。如果你只保留了工具调用但删掉了结果,或者反过来,模型的推理链就断了。这看起来是小事,但在实际开发中,这种”配对完整性”往往是 Agent 行为稳定性的关键。
Thinking block 必须保持完整。Claude 的思考过程是一个完整的逻辑单元,从中间切断会导致下一轮对话的推理质量断崖式下降。
这本质上是一种用空间换时间的策略:平时后台持续提取记忆(消耗额外 API 调用),压缩时直接复用(省掉等待时间)。如果你的 Agent 场景对响应延迟敏感,这个设计非常值得借鉴。
4. 第三级:Full Compact:九段式摘要的”核武器”
前两级都做不到时,Full Compact 登场。它会调用 API 生成一份结构化摘要,替代被压缩掉的旧消息。

图 3:Full Compact 九段式结构化摘要格式
为什么是 9 段而不是自由文本?
prompt.ts(374 行)定义了一个 9 段式的摘要格式。每一段回答一个核心问题:”要继续工作,你必须知道什么”:
-
Primary Request and Intent:用户到底想干什么(不是字面意思,是真实意图) -
Key Technical Concepts:对话中涉及的核心技术概念 -
Files and Code Sections:涉及哪些文件,关键代码是什么(这是信息量最大的一节) -
Errors and Fixes:遇到过什么错误,怎么修的 -
Problem Solving:解决问题的思路和过程 -
All User Messages:用户所有原始消息(为什么要保留?因为用户的每一次修正、补充、否定都是约束条件) -
Pending Tasks:还有什么没做完 -
Current Work:当前正在做什么,精确到代码片段 -
Optional Next Step:下一步应该做什么,必须包含原文引用
为什么不用自由文本摘要?因为自由文本的不可控性太高:模型可能把重要的代码细节省略,也可能把用户的否定性约束记反了。结构化的 9 段格式本质上是一份”任务交接文档“,确保压缩后的信息足以让模型无缝续接。
NO_TOOLS_PREAMBLE:一段降低失败率的 prompt
这里有个很有意思的工程细节。
Full Compact 调 API 时设置了 maxTurns: 1:只允许模型做一次回复,不允许调用工具。但 Sonnet 4.6+ 的自适应思考模型有时候会在摘要任务中”自作主张”调用工具。maxTurns: 1 意味着一次工具调用失败就等于零输出、完全失败。
源码里的数据:4.6 模型在摘要任务中的工具调用失败率 2.79%,4.5 模型只有 0.01%。
解法是在 prompt 的最前面加一段强硬声明:
// 源码路径:src/services/compact/prompt.ts// NO_TOOLS_PREAMBLE 开头的声明:// "CRITICAL: Respond with TEXT ONLY. Do NOT use any tools."// 这不是 prompt engineering 的花活,而是对模型行为模式的工程化应对说实话,这不是什么优雅的方案,但它是务实的。在工程世界里,能解决问题的方案就是好方案。
两种压缩方向:保前头还是保尾巴
源码里 Full Compact 支持两种部分压缩方向:
-
'from'模式:保留前半段对话,压缩后半段。好处是缓存前缀不变,Prompt Cache 照常命中 -
'up_to'模式:压缩前半段,保留后半段。缓存会失效,但保留了最新的上下文
源码中有一个 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 标记,用来分隔系统 prompt 的静态段和动态段。'from' 模式之所以能保持缓存命中,就是因为它只动动态段的内容,静态段的缓存前缀纹丝不动。
这个设计太聪明了。 它意味着选择压缩方向不仅仅是信息保留的决策,还是成本控制的决策。
PTL 重试:用来解决”太长”的方法本身也”太长”
这是压缩系统里最有递归味道的部分。
当 Full Compact 需要压缩对话时,它要把旧消息发给 API 生成摘要。但如果旧消息本身已经超出了上下文窗口呢?用来解决”太长”的方法,自己也”太长”了。
源码的解法是 groupMessagesByApiRound():把消息按 API 轮次分组,然后从最旧的组开始逐个截断,最多重试 3 次:
// 源码路径:src/services/compact/grouping.ts (63 行)// 按轮次分组 → 截断最旧的组 → 重试压缩请求// 最多 3 次重试每截断一个组,发送给 API 的内容就少一些,直到能塞进上下文窗口为止。
压缩后的文件恢复
压缩不可避免地丢掉了具体的文件内容。但后续对话可能还需要这些文件的信息。
源码的自动化策略:压缩完成后,自动重读最近 5 个访问过的文件。预算是 5 万 token,每个文件 5K 上限。还有一个去重逻辑:如果某个文件的内容已经存在于保留的消息中(比如最近刚好读过),就不重复读取。
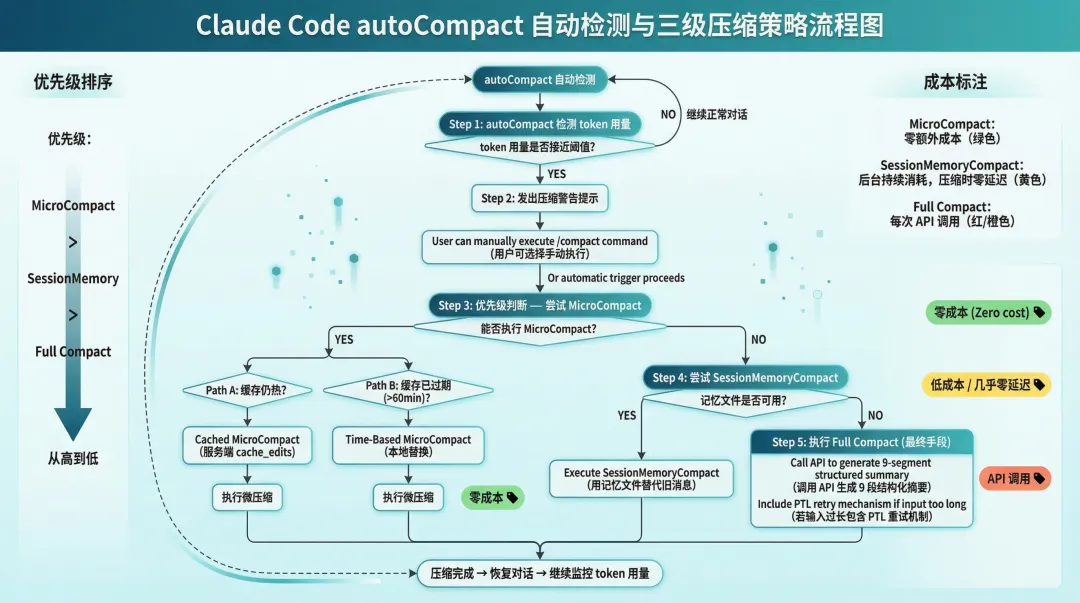
图 4:autoCompact 自动触发与三级策略选择流程
你在项目中用过类似的多级缓存或渐进式降级方案吗?欢迎在评论区聊聊。
5. 自动触发与成本感知
三级策略不会让用户手动选择。autoCompact.ts(351 行)负责在 token 用量达到阈值时自动触发压缩,选择优先级是:
MicroCompact > SessionMemoryCompact > Full Compact
为什么是这个顺序?因为成本。
MicroCompact(尤其是 Cached 模式)几乎零额外成本:不调 API,不消耗 token。SessionMemoryCompact 需要后台持续运行但不需要压缩时临时调 API。Full Compact 每次都需要额外的 API 调用来生成摘要。
而且源码里还设计了一个压缩警告提示:在即将触发压缩前通知用户,让用户有机会手动执行 /compact,选择自己想要的压缩时机。这是一个很好的用户体验设计:自动化不等于剥夺控制权。
6. 记忆系统:压缩的长期伴侣
三级压缩解决了”对话中”的上下文管理,但跨会话呢?你关掉终端,第二天再打开,之前的东西全没了。
这就是记忆系统要做的事。
MEMORY.md:200 行 / 25KB 的双保险
memdir.ts(507 行)管理着 MEMORY.md 文件,这是 Claude Code 的长期记忆索引。双重上限:200 行或 25KB,哪个先到就触发截断。
记忆分为四类:
|
|
|
|
|---|---|---|
user |
|
|
feedback |
|
|
project |
|
|
reference |
|
|
更有意思的是什么不该记住。源码中明确排除了:代码模式、架构设计、Git 历史。原因很实在:这些东西可以从代码本身推导出来,存了反而会让记忆文件膨胀,挤占真正需要持久化的信息。
AutoDream:记忆的”消化”过程
autoDream.ts(324 行)实现了一个叫”梦境”的记忆整合机制。不是简单地把新记忆追加到文件末尾,而是定期把零散的记忆条目重新整理、合并、去重。
触发条件有三道门:
-
时间门:距上次整合超过 24 小时 -
会话门:积累超过 5 次会话 -
文件锁:防止多个进程同时整合
Compact 和 Memory 的互补闭环
把压缩和记忆放在一起看,它们是一个互补关系:
压缩不可避免地丢掉细节(比如某次具体的文件读取结果),但记忆系统保存了要点(比如”用户要求用 TypeScript strict mode”)。压缩管”当前对话怎么不爆”,记忆管”下一次对话怎么接上”。
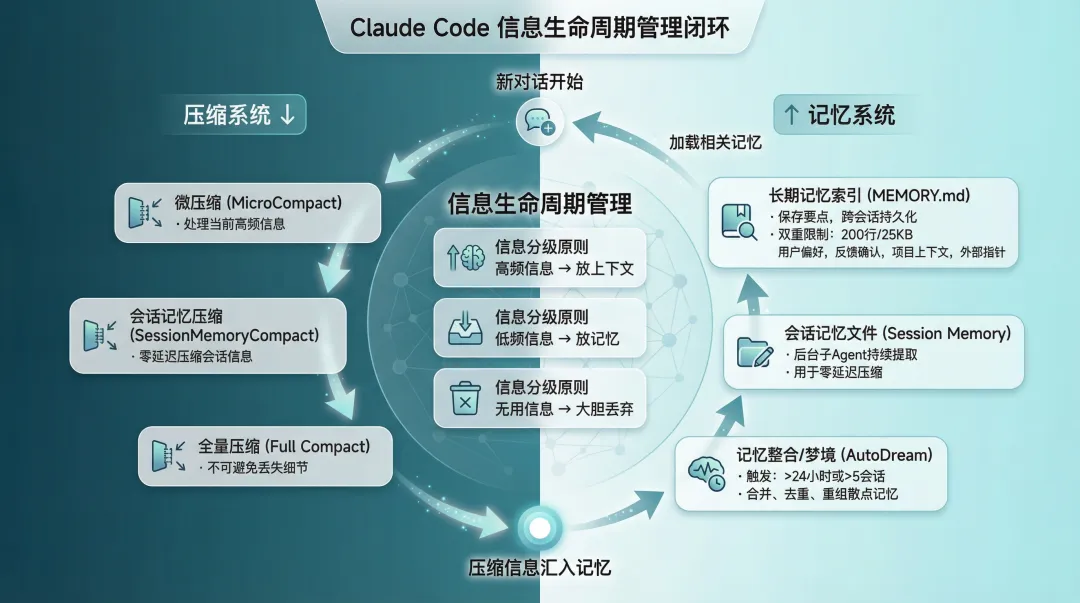
图 5:Compact 压缩系统与 Memory 记忆系统的互补闭环
这不是两个独立的系统拼在一起,而是一套完整的信息生命周期管理:高频信息放上下文、低频信息放记忆、无用的信息大胆丢弃。
总结
读完这 8 个 compact 相关的源码文件,印象深刻的不是某个单独的技术点,而是整体的设计思路:
-
渐进式降级:从零成本的缓存编辑开始,逐级升级到 API 调用,每一步都是”能省则省” -
缓存友好:压缩方向的选择不仅考虑信息保留,还考虑 Prompt Cache 命中率,把压缩和缓存当共生关系来设计 -
结构化摘要:9 段式格式比自由文本靠谱得多,本质是一份”任务交接文档” -
信息分级:工具结果可以丢、用户意图必须留、思考过程不能断:”什么不保存”比”保存什么”更重要
对做 AI Agent 开发的人来说,这套源码提供了一个可参考的上下文管理框架。核心教训是:不要等到上下文爆了才处理,要建立自动触发机制;不要只想着怎么压缩,要想着怎么让压缩和缓存协同工作。
上下文管理正在成为 AI Agent 框架的核心竞争力。Claude Code 的三级压缩系统,大概是目前能看到的最完整的一份工程答卷。
如果你的同事也在做 Agent 开发,转发给他看看:这套压缩系统的设计思路,比 51.2 万行源码本身更值得琢磨。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
扫码关注,获取更多 AI 工具的实战经验和最佳实践。不错过每一篇干货!
