 夜雨聆风
夜雨聆风





Word2vec 词向量原理图解:King – Man + Woman = Queen
👇连享会 · 推文导航 | www.lianxh.cn
连享会:2026五一论文班 · 线上时间:4月15日(先导课),5月2-4日(正式课)嘉宾:郭士祺 (上海交通大学)、戚树森 (厦门大学)、李学恒 (中山大学)咨询:王老师 18903405450(微信)

先导课:Claude Code / Opencode 快速上手
-
• 第一部分:安装与配置(25分钟) -
• Claude Code 与 Opencode 的定位与区别 -
• 两条安装路径:Claude Code(需特殊网络)vs Opencode(国内推荐,自带免费模型) -
• 完整工具链:AI 本体 + VS Code + Git + Miniconda + Pandoc -
• 现场演示:从零启动、界面介绍、常见问题排查 -
• 配套教程:《Opencode 套件安装指南》 -
• 第二部分:Skill 生态(35分钟) -
• 什么是 Skill:从重复 prompt 到可复用工作规则 -
• Skill 的三类分类:文档资产型、流程自动化型、MCP 增强型 -
• 发现、安装与触发机制(渐进式披露) -
• 演示 1:文件格式自由切换(PDF ↔ Markdown ↔ Word) -
• 演示 2: web-research深度网络调研,自动生成带引用的研究报告 -
• 演示 3: marp-slides-creator将调研报告一键转为演示文稿 -
• 串联效果:调研报告 → Markdown Slides → PDF

作者:巩倩 (北京外国语大学)邮箱:gongqian1999yt@163.com[1]
Note: 本文主要内容译自 Jay Alammar 的 The Illustrated Word2vec(Link[2]),并结合经管领域的应用场景做了补充和调整,特此感谢原作者!
-
• Title:Word2vec 词向量原理图解:King – Man + Woman = Queen -
• Keywords:Word2vec, 词嵌入, 词向量, Skip-gram, 负采样, 文本分析, 词嵌入, 语义分析, 机器学习, 自然语言处理
温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:

1. 引言:为什么需要词向量?
在机器学习中,嵌入 (embedding) 是自然语言处理 (NLP) 中的核心概念之一。如果你曾经使用过语音助手、机器翻译,甚至是带有下一词预测功能的智能手机输入法,那么你就已经在受益于这一理念。在过去的几十年中,神经模型在使用嵌入方面取得了长足的发展(最近的进展包括上下文词嵌入,并由此产生了 BERT[3] 和 GPT 等前沿模型)。
近年来,词嵌入方法在经济学和管理学研究中也得到了广泛应用。例如,研究者利用词向量分析企业年报的语义特征、度量政策不确定性、衡量文化距离等。理解词向量的基本原理,有助于经管类研究者更好地运用这些文本分析工具。
Word2vec 是一种高效创建词嵌入的方法。本文将介绍嵌入的概念,以及使用 Word2vec 生成嵌入的机制。我们从一个直观的例子开始,感受「用向量来表示事物」这一思想。
2. 从向量到嵌入:一个直觉性的例子
在 0 到 100 的范围内,你有多内向或多外向(0 代表最内向,100 代表最外向)?这类问题来自 MBTI 或大五人格等性格测试。这些测试会问你一系列问题,然后根据若干维度对你进行打分,内向/外向就是其中之一。

假设某人的内向/外向得分为 38/100,我们可以将其标在数轴上:
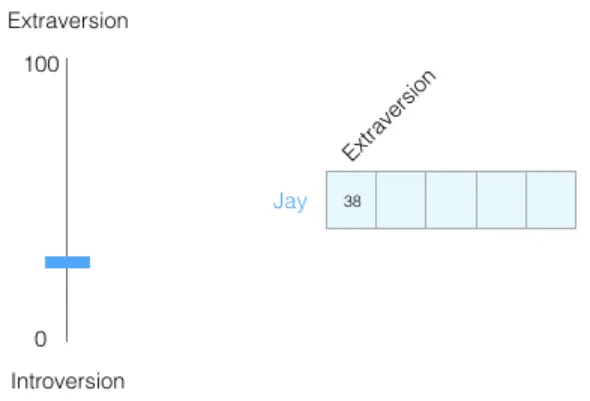
将范围标准化为 -1 到 1:

仅凭一个维度的信息,我们对一个人的了解是非常有限的。人是复杂的,因此我们增加一个维度——另一个特质的得分:
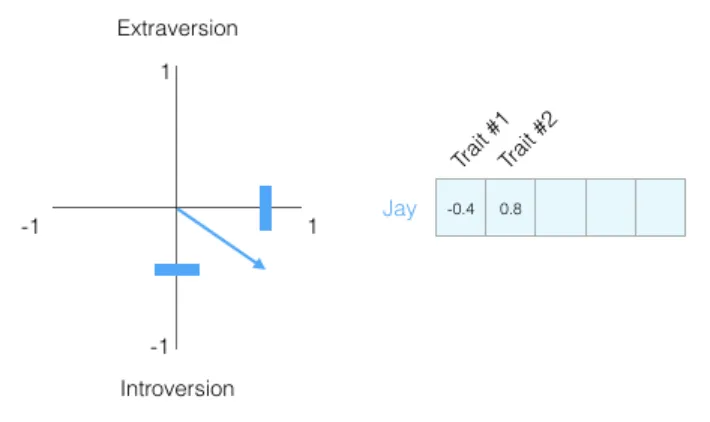
现在,这个二维向量可以部分刻画一个人的性格特征。当我们需要比较不同人的相似度时,这种表示法就派上了用场。例如,下图中哪个人与「我」的性格更相似?
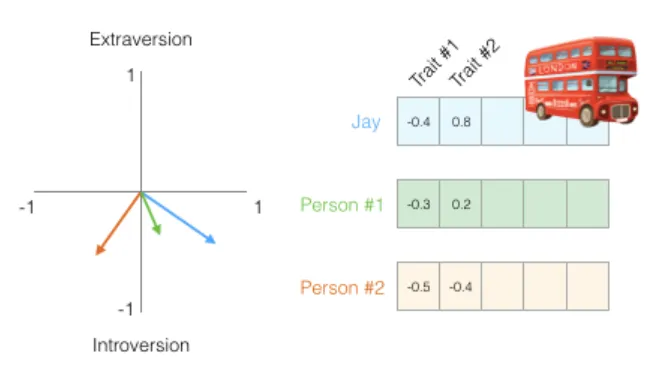
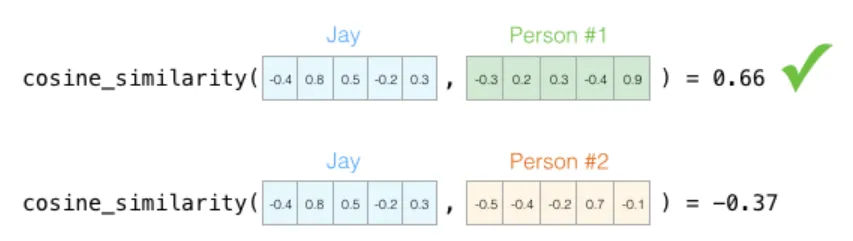
在处理向量时,计算相似度的常用方法是余弦相似度 (cosine similarity)。方向越一致的两个向量,余弦相似度越高。根据下图,第一个人与「我」更相似:

然而,两个维度仍不足以充分刻画人与人之间的差异。数十年的心理学研究已总结出五种主要特质(以及大量子特质),因此我们可以使用全部五个维度:

五维空间无法在平面上直接绘制箭头进行可视化,这是机器学习中常见的挑战——我们经常需要在高维空间中思考问题。好在余弦相似度在任意维度下都适用:
从这个例子中,我们可以提炼出两个核心思想:
-
1. 向量表示:我们可以用数字向量来表示人和事物,机器可以直接处理这些数值。 -
2. 相似度计算:我们可以方便地计算向量之间的相似度,从而度量事物之间的关系。

3. 词嵌入
3.1 词嵌入长什么样?
有了上述认识,我们可以进一步了解词向量(也称词嵌入,word embedding)。下面是 “king” 一词的词向量示例(基于 Wikipedia 训练的 GloVe[4] 向量,50 维):
[ 0.50451, 0.68607, -0.59517, -0.02280, 0.60046, -0.13498, -0.08813, 0.47377, -0.61798, -0.31012, -0.07667, 1.49300, -0.03419, -0.98173, 0.68229, 0.81722, -0.51874, -0.31503, -0.55809, 0.66421, 0.19610, -0.13495, -0.11476, -0.30344, 0.41177, -2.22300, -1.07560, -1.07830, -0.34354, 0.33505, 1.99270, -0.04234, -0.64319, 0.71125, 0.49159, 0.16754, 0.34344, -0.25663, -0.85230, 0.16610, 0.40102, 1.16850, -1.01370, -0.21585, -0.15155, 0.78321, -0.91241, -1.61060, -0.64426, -0.51042 ]每个数字代表 “king” 在某个语义维度上的特征值。虽然单独看这些数值难以直接解读,但它们共同构成了该词在语义空间中的位置,是后续语义分析和词向量运算的基础。
为了更直观地理解,我们可以用颜色编码来可视化这些数值(红色表示接近 2,白色表示接近 0,蓝色表示接近 -2):

将 “king” 与其他词的向量进行对比:

可以看到,”man” 和 “woman” 之间的相似程度远高于 “king” 和 “woman”,这说明向量表示法确实捕捉到了词语的语义信息。
下面是更多词语的向量可视化(可以纵向浏览,寻找颜色模式相似的列):
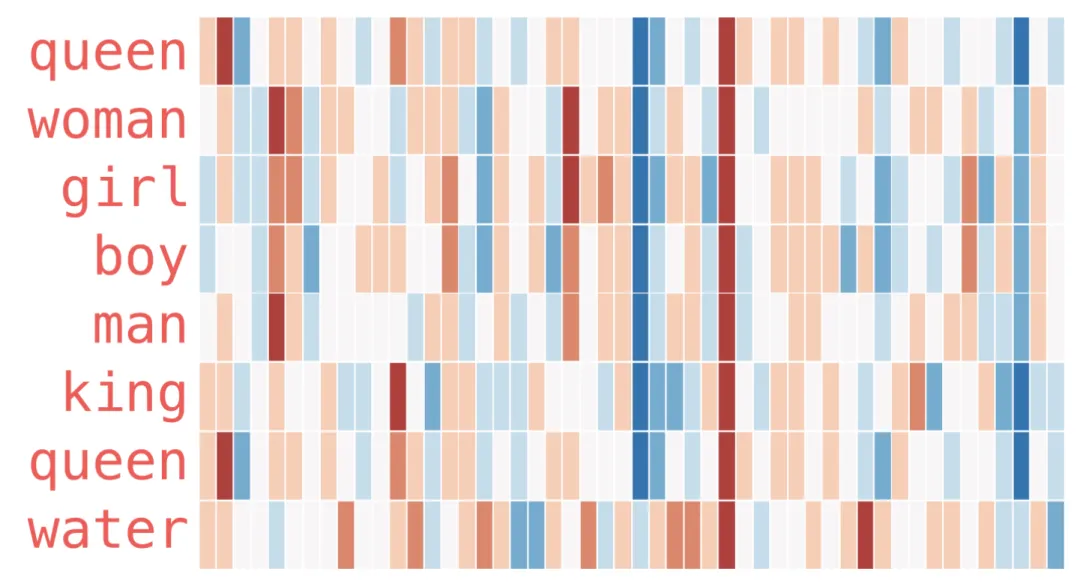
几个值得关注的现象:
-
• 所有词在某一列上都呈现红色,说明它们在该维度上具有相似特征(我们并不知道每个维度具体对应什么语义)。 -
• “woman” 和 “girl” 在很多维度上相似,”man” 和 “boy” 亦然。 -
• “boy” 和 “girl” 之间也有共性,但与 “woman” 或 “man” 不同——这或许编码了某种「年轻」的语义。 -
• 除最后一个词外,其余都是表示人的词。”water” 作为物体,其向量模式与表示人的词明显不同。 -
• “king” 和 “queen” 彼此相似,但又与其他类别有区别——这或许编码了「王权」的语义。
3.2 词嵌入的语义运算
词嵌入一个引人注目的特性是可以进行代数运算。最经典的例子是:
“king” – “man” + “woman” ≈ “queen”
直观的解释是:从 “king” 的向量中减去 “man” 的语义成分(去除与「普通男性」相关的特征),保留与「王权」相关的部分,再加上 “woman” 的语义成分,最终得到的向量最接近 “queen”。
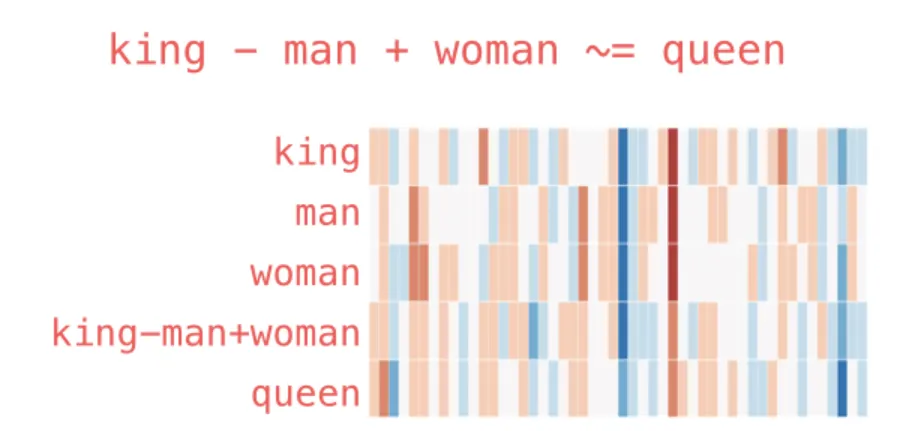
需要指出的是,由 “king” – “man” + “woman” 计算得到的向量并不完全等同于 “queen” 的向量,但在约 400,000 个词的词汇表中,”queen” 是与该结果向量最接近的词。
4. 语言模型与词嵌入的关系
4.1 下一词预测任务
智能手机输入法中的下一词预测功能是语言模型的一个典型应用。
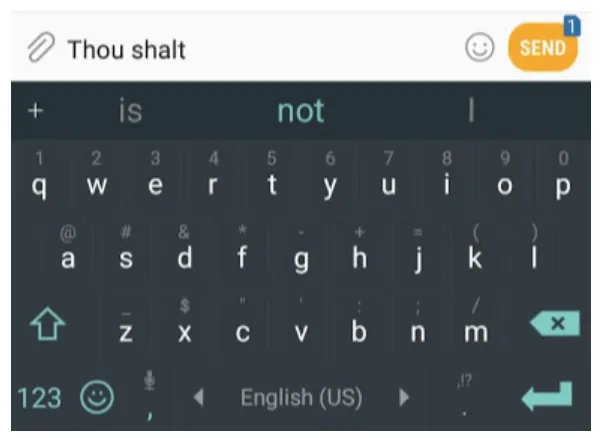
语言模型可以接收一个词序列(例如两个词),并预测紧随其后的词。例如,给定 “thou shalt”,模型会返回一组候选词及其概率,”not” 的概率最高:

模型的工作过程可以抽象为如下的黑盒子:

实际上,模型并不只输出一个词,而是输出词汇表中所有词的概率分布(词汇量可能从数千到上百万不等),然后应用程序从中选取概率最高的若干词呈现给用户。

经过训练后,早期的神经语言模型(Bengio, 2003)通常分三个步骤计算预测结果:
-
1. 查询词嵌入 -
2. 计算概率 -
3. 映射到输出词
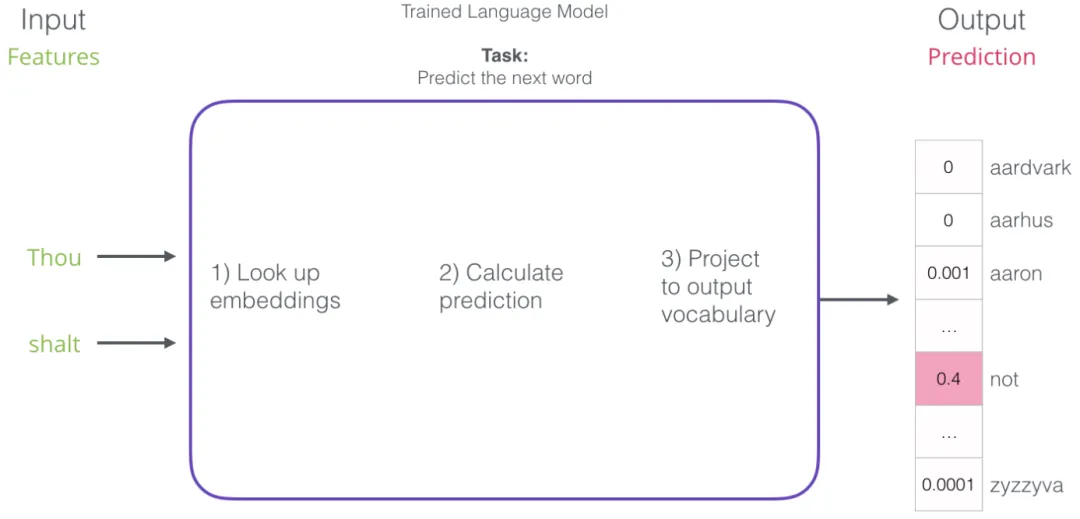
其中第一步与本文讨论的「嵌入」最为相关。训练过程的一个重要产物就是嵌入矩阵 (Embedding Matrix),它包含了词汇表中每个词的嵌入向量。在预测时,只需查找输入词的嵌入,并据此计算预测结果:
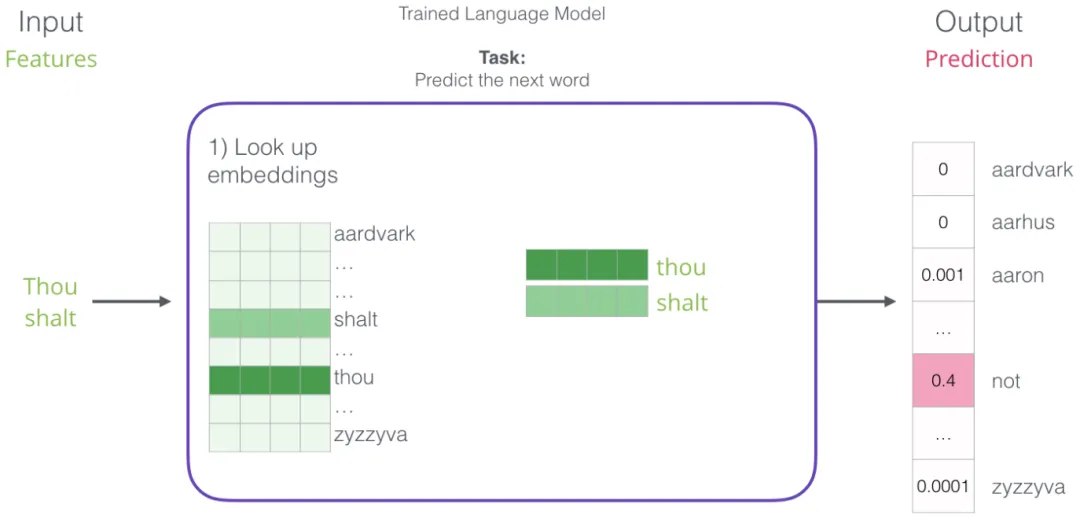
下面我们来看训练过程,了解这个嵌入矩阵是如何构建的。
4.2 滑动窗口与训练样本的生成
与许多机器学习模型不同,语言模型具有一个显著优势:可以直接利用大规模无标注文本进行训练。书籍、文章、维基百科等海量文本数据都可以作为训练语料,无需人工标注。
词嵌入的核心思想是:一个词的含义由它的上下文决定。具体而言:
-
1. 获取大量文本数据(例如维基百科的全部文章); -
2. 设定一个固定大小的窗口(例如 3 个词),在全部文本上滑动; -
3. 滑动窗口在每个位置生成一个训练样本。
以下面这个句子为例:
“Thou shalt not make a machine in the likeness of a human mind” — Dune
窗口从句首开始,取前三个词:

前两个词作为特征(输入),第三个词作为标签(输出):

窗口滑动到下一个位置,生成第二个样本:

依此类推,我们得到一个训练数据集,其中记录了哪些词倾向于出现在哪些词对之后:

4.3 「瞻前顾后」——上下文的重要性
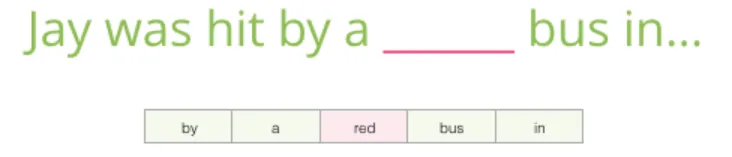
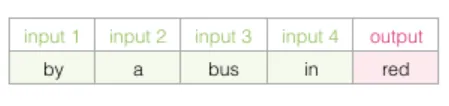
请看下面的填空任务:

上下文是空白处之前的五个词(假设前文已经提到 “bus”),大多数人会猜测空白处是 “bus”。但如果我们再给出空白处之后的一个词呢?

答案完全改变了——现在 “red” 最有可能填入空白处。这说明,目标词前后的词都具有重要的信息价值。同时考虑左右两个方向的上下文,能够学到更好的词嵌入。
5. Word2vec 的两种架构
5.1 CBOW:由上下文预测目标词
基于上述思路,我们不仅考虑目标词前面的词,还同时考虑后面的词:
这样生成的训练数据集如下所示:
这种架构称为连续词袋模型 (Continuous Bag of Words, CBOW),由 Mikolov et al. (2013[5]) 提出。
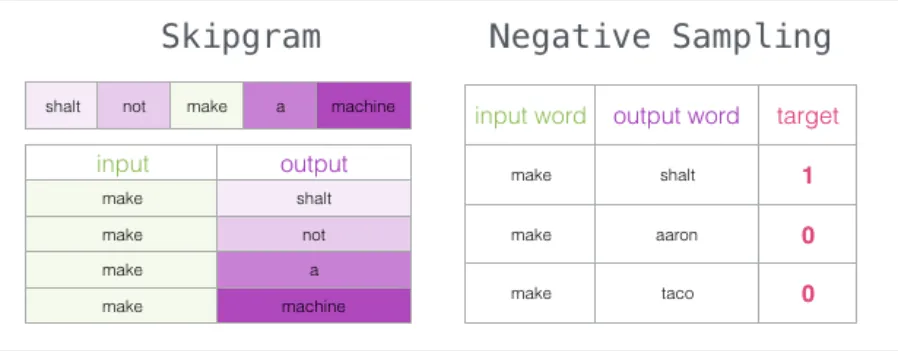
5.2 Skip-gram:由目标词预测上下文
另一种架构的思路恰好相反:不是根据上下文预测目标词,而是根据目标词预测其上下文。下图展示了滑动窗口的工作方式(绿框为输入词,粉框为可能的输出):
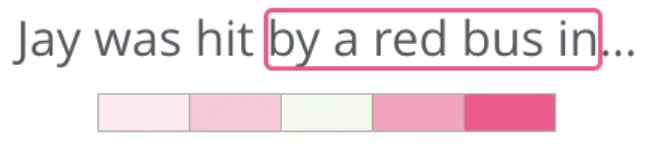
粉色方框的颜色深浅不同,因为每个窗口位置实际上会生成多个训练样本:
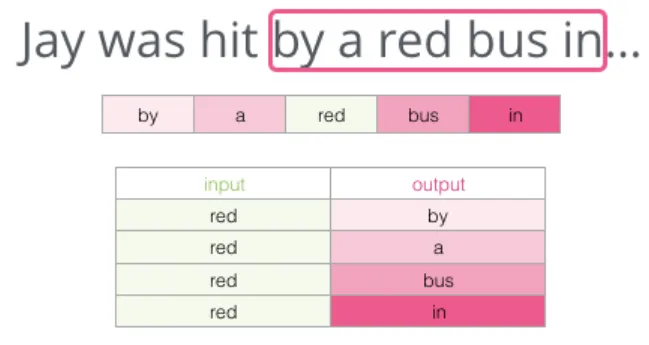
这种方法称为 Skip-gram 架构。滑动窗口的内容可以这样展示:

由此生成的四个训练样本为:
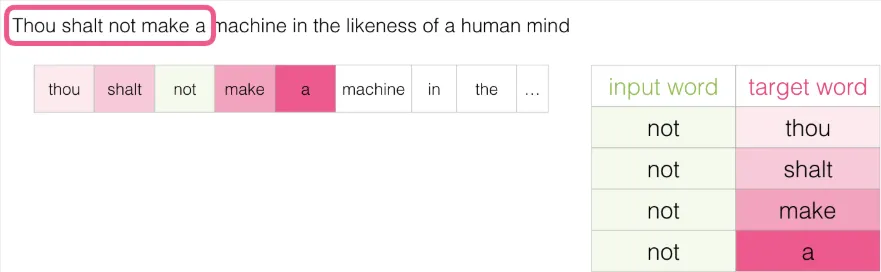
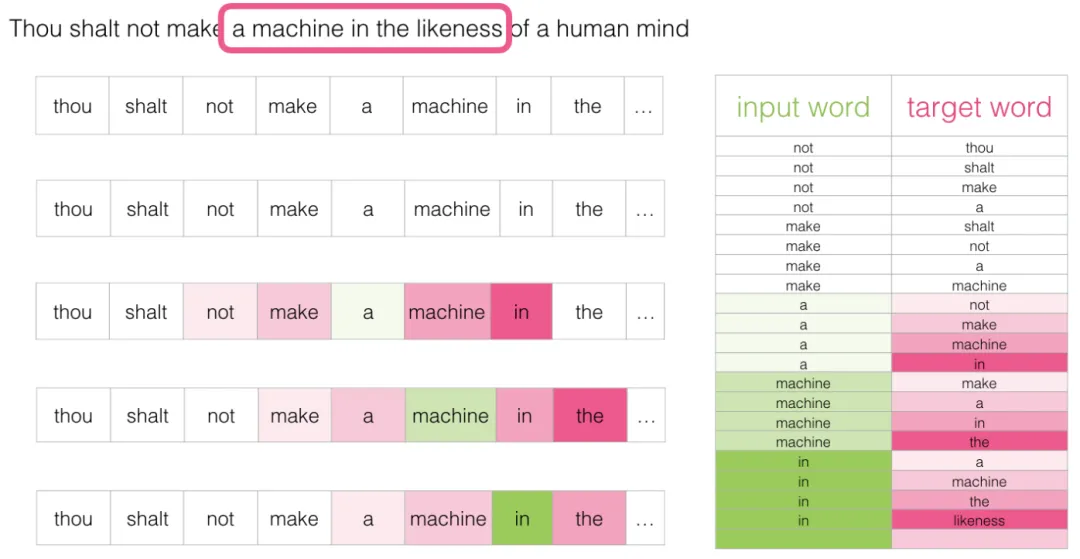
窗口继续滑动到下一个位置:
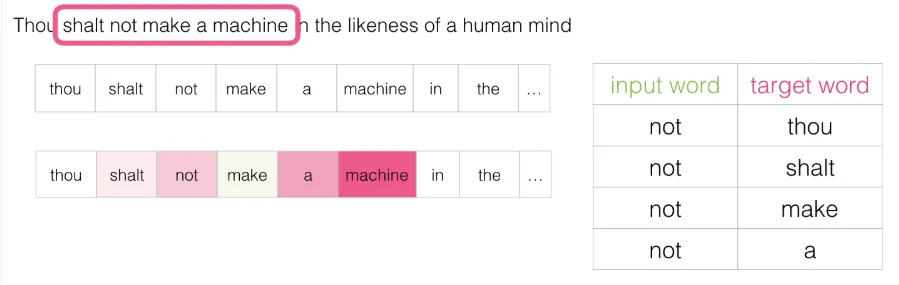
产生接下来的四个样本:
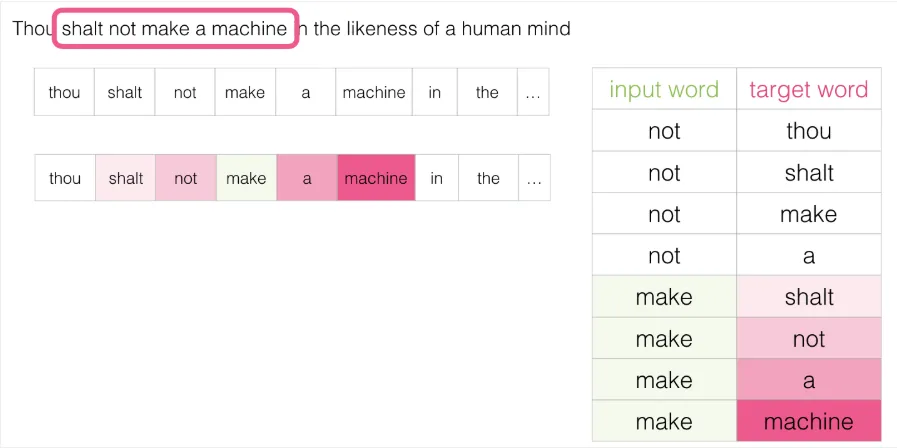
经过多次滑动后,我们得到一批训练样本:
Skip-gram 的训练过程概览
有了 Skip-gram 训练数据集,我们来看如何训练一个预测邻近词的神经语言模型。

从数据集的第一个样本开始,将特征词输入尚未训练的模型,要求它预测一个邻近词:
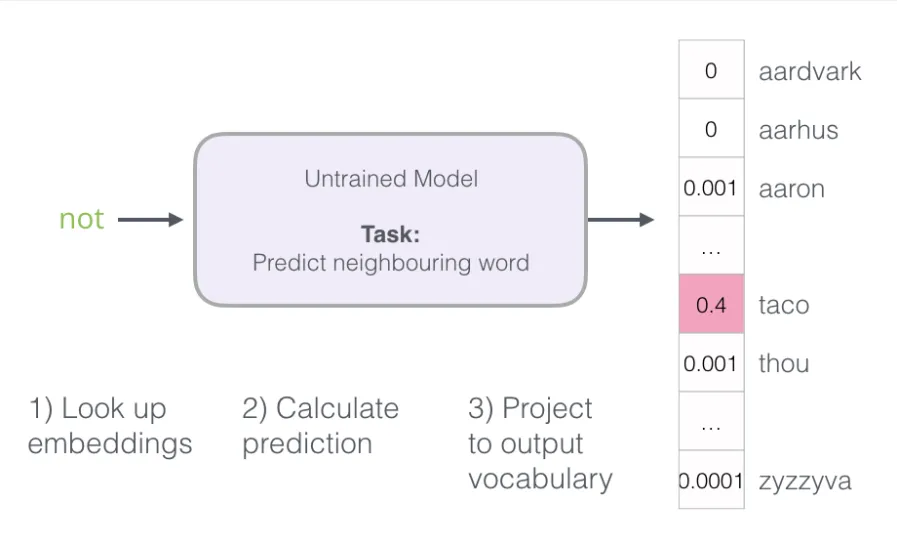
模型完成三个步骤后输出一个预测向量(为词汇表中每个词分配一个概率)。由于模型尚未经过训练,此时的预测必然不准确。我们知道正确答案是什么——即训练数据中对应的标签词(下图左侧为目标向量,目标词概率为 1,其余为 0;右侧为模型的预测输出):
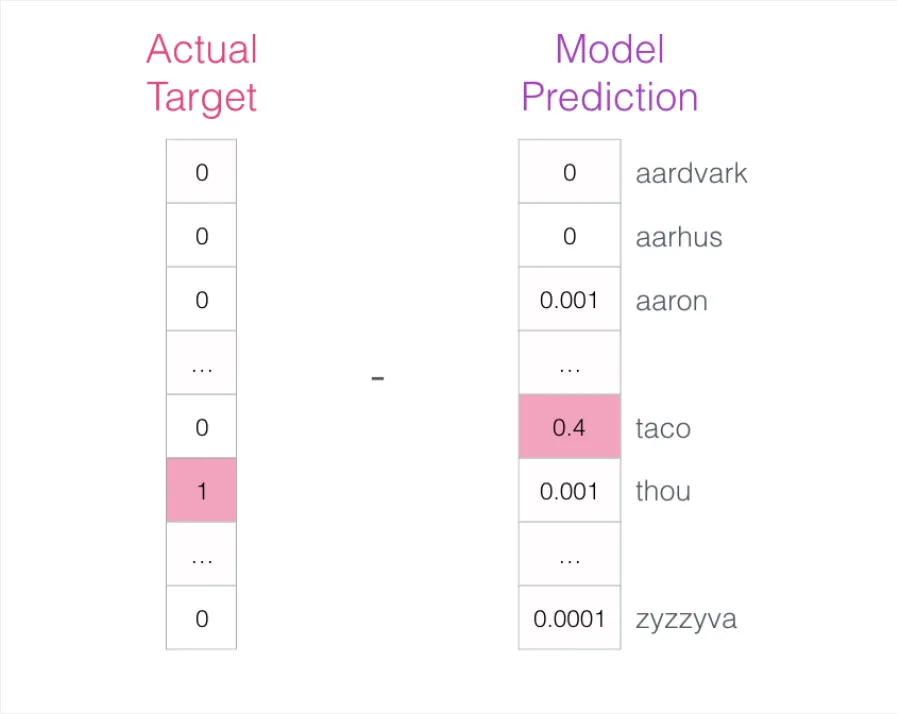
将两个向量相减,得到误差向量:
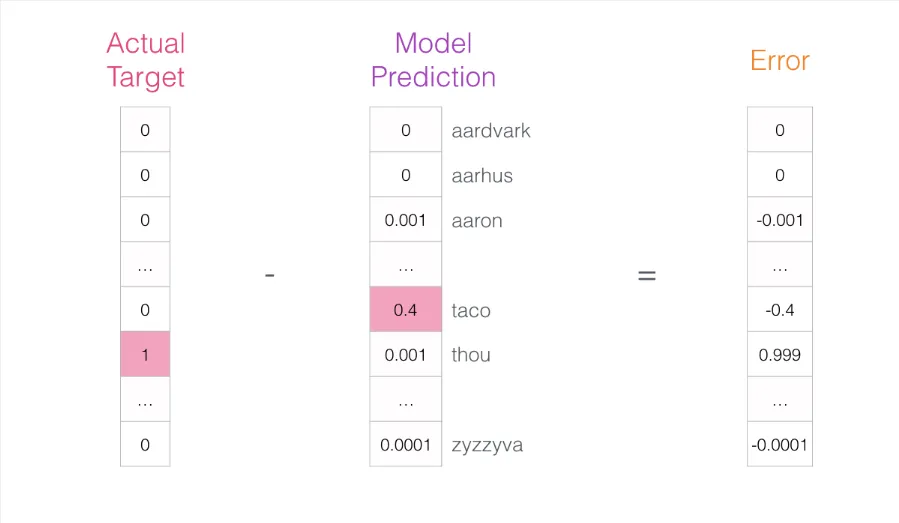
利用这个误差向量来更新模型参数,使其在下一次遇到相同输入时能做出更准确的预测:
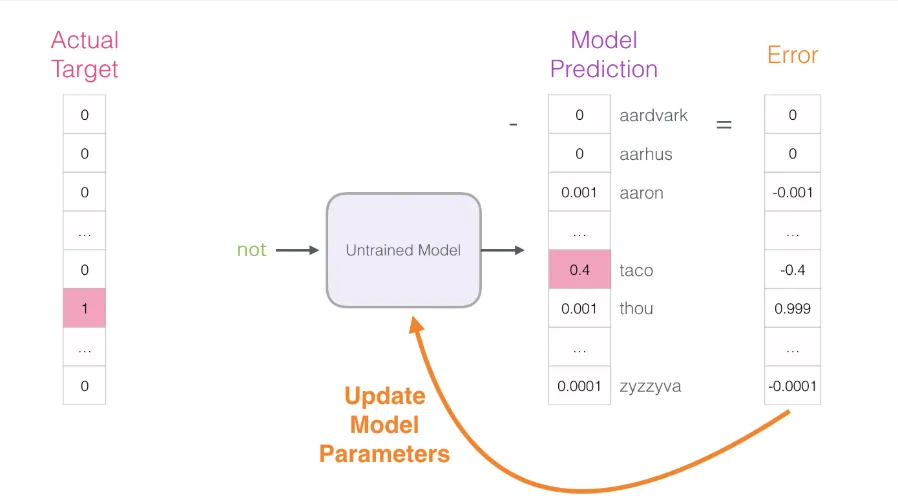
第一个训练步骤到此结束。接下来,我们对数据集中的样本逐一重复上述过程,循环多个轮次后,便可从训练好的模型中提取嵌入矩阵。
以上过程有助于理解词嵌入的训练逻辑,但实际的 Word2vec 训练还引入了几个关键的优化技术——其中最重要的是负采样。
6. 负采样:让训练更高效
6.1 为什么需要负采样?
回顾神经语言模型计算预测结果的三个步骤:
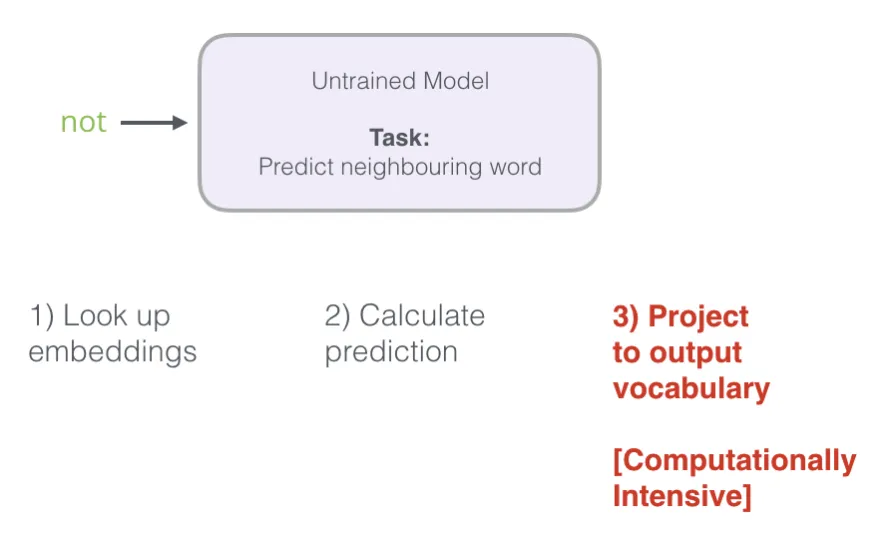
从计算角度来看,第三步的成本非常高——它需要对整个词汇表计算 softmax 概率,而这一操作需要对每个训练样本都执行一次(训练样本通常多达数千万个)。
为了提高效率,我们将任务分为两步:
-
1. 生成高质量的词嵌入(这是本文关注的重点); -
2. 使用这些词嵌入来训练下游语言模型。
针对第 1 步,我们可以对任务进行简化。原始任务是:给定输入词,预测邻近词(一个多分类问题):
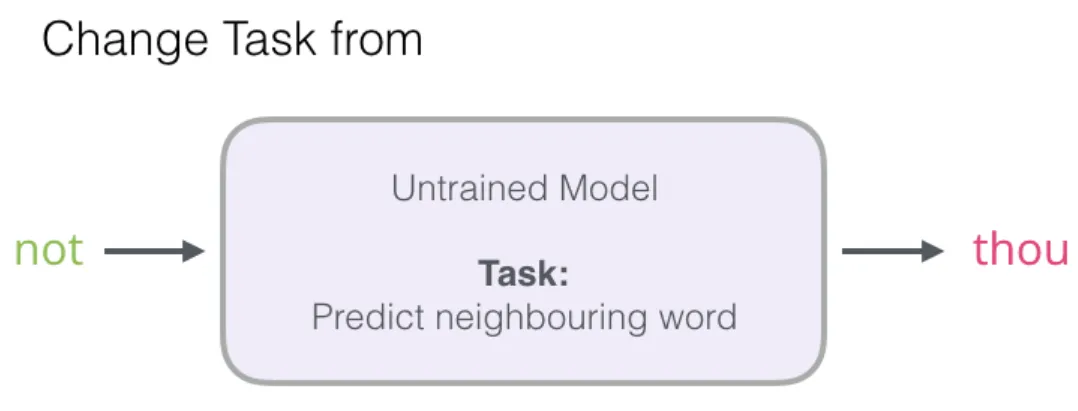
简化后的任务变为:给定一对词,判断它们是否为邻近词(一个二分类问题,输出 0 或 1):

这一转换将模型从神经网络简化为逻辑回归模型,计算速度大幅提升。
相应地,训练数据的结构也发生了变化——新增一列标签,值为 0 或 1。由于所有来自滑动窗口的词对都是实际共现的邻近词,它们的标签均为 1:
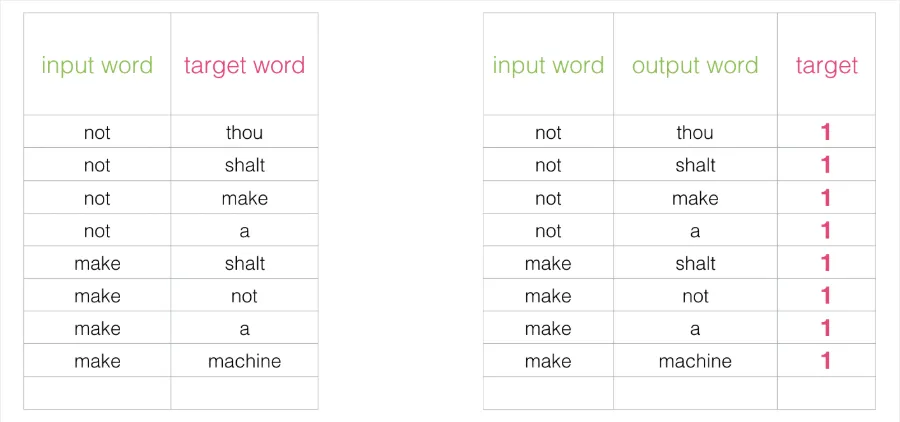
但如果所有样本的标签都是 1,模型可能学会对所有输入都输出 1——虽然训练准确率为 100%,但无法学到有意义的词嵌入:

为了解决这个问题,我们需要在数据集中引入负样本 (negative samples)——即不相邻的词对,模型需要为这些样本返回 0。负样本的构造方法是:从词汇表中随机抽取词作为「伪上下文词」:

这一思想源自噪声对比估计 (Noise Contrastive Estimation, NCE) 方法 (Gutmann & Hyvärinen, 2010[6])。其核心在于将真实信号(邻近词的正样本)与噪声(随机选取的非邻近词)进行对比,从而在计算效率和统计效率之间取得平衡。
6.2 基于负采样的 Skip-gram (SGNS) 训练过程
将 Skip-gram 与负采样结合,就得到了 Word2vec 中最常用的训练方法——SGNS (Skip-gram with Negative Sampling)。
对于一个正样本 和 个负样本 ,SGNS 的目标函数为:
其中 是 sigmoid 函数, 和 分别是目标词和上下文词的嵌入向量。目标函数的含义很直观:让真实共现的词对得分尽量高,让随机配对的词对得分尽量低。
训练的具体步骤如下:
在训练开始前,我们先确定词汇量大小(记为 vocab_size,假设为 10,000)及其包含的词。然后创建两个矩阵:
-
• 嵌入矩阵 (Embedding Matrix):存储每个词作为「输入词」时的向量; -
• 上下文矩阵 (Context Matrix):存储每个词作为「上下文词」时的向量。
两个矩阵的维度均为 vocab_size × embedding_size(embedding_size 常取 300,本文前面的示例取 50)。

训练开始时,两个矩阵用随机值初始化。在每个训练步骤中,取一个正样本及其对应的负样本。以下面这组为例:
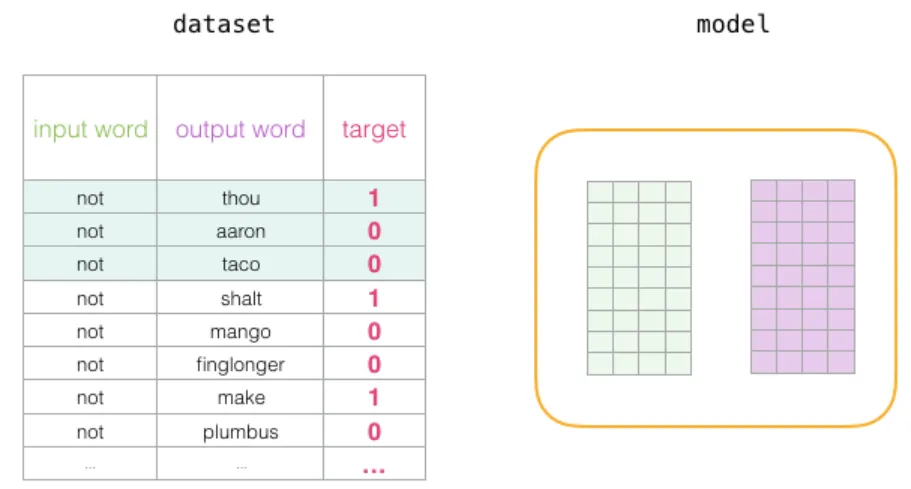
这里有四个词:输入词 “not”,正样本上下文词 “thou”(实际邻近词),以及负样本 “aaron” 和 “taco”(随机选取的非邻近词)。对于输入词,从嵌入矩阵中查找其向量;对于上下文词,从上下文矩阵中查找:
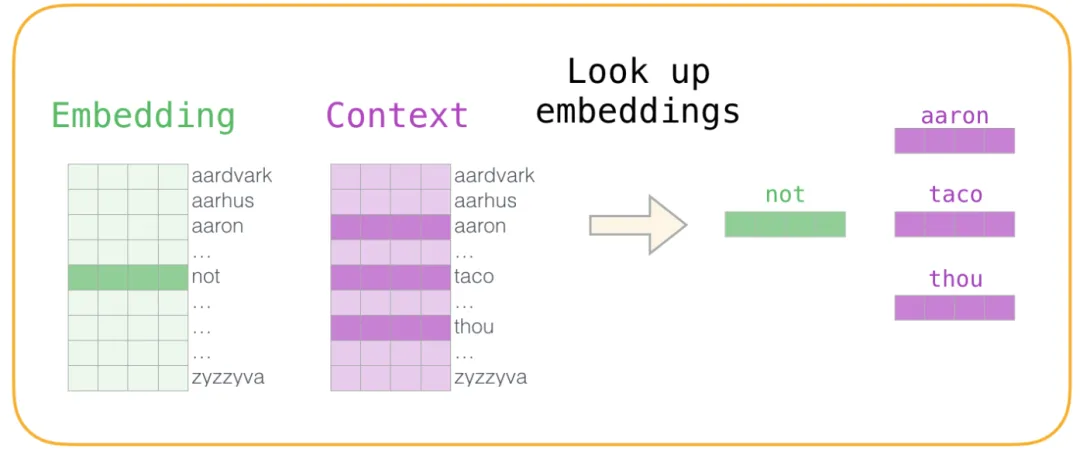
然后,计算输入词嵌入与每个上下文词嵌入的点积,得到一个相似度分数:
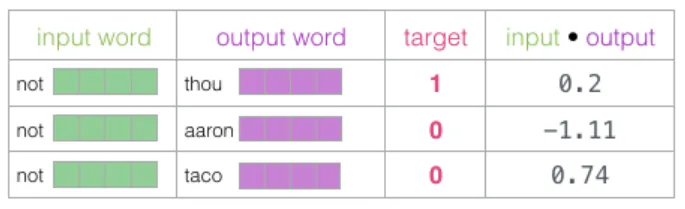
接下来,用 sigmoid 函数将分数转换为 0 到 1 之间的概率值:
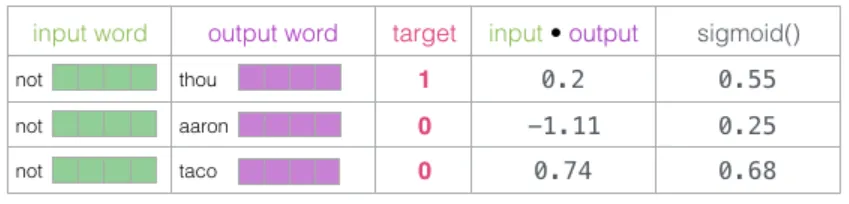
可以看到,未经训练的模型中,”taco” 的得分最高,”aaron” 最低——这显然是不合理的。我们用目标标签减去 sigmoid 输出,得到误差:

利用这个误差向量,通过反向传播更新 “not”、”thou”、”aaron” 和 “taco” 的嵌入向量,使得下一次计算时,结果更接近目标值:

一个训练步骤到此结束。随后,取下一组正样本和负样本,重复上述过程:
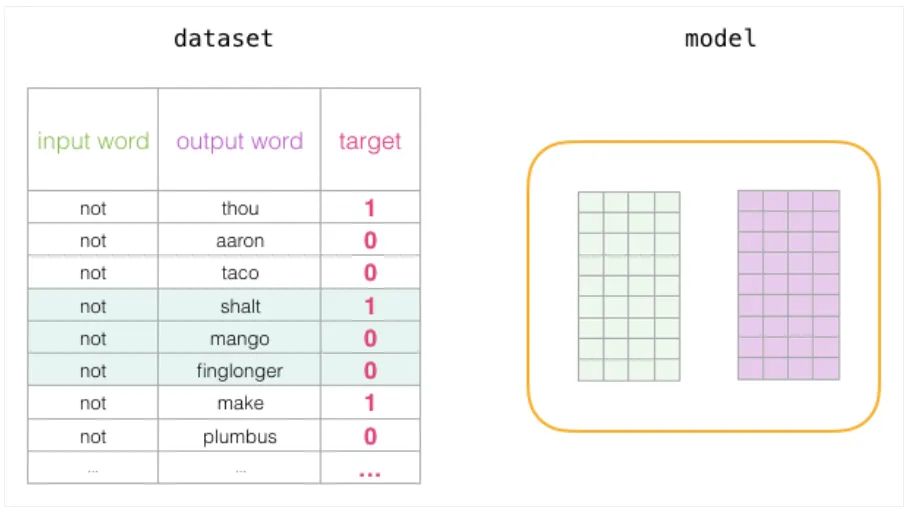
当我们遍历整个数据集多个轮次后,嵌入向量的质量会持续改善。训练结束后,丢弃上下文矩阵,保留嵌入矩阵作为最终的预训练词向量,用于下游任务。
7. 关键超参数的选择
Word2vec 训练中有两个关键超参数:窗口大小和负样本数量。
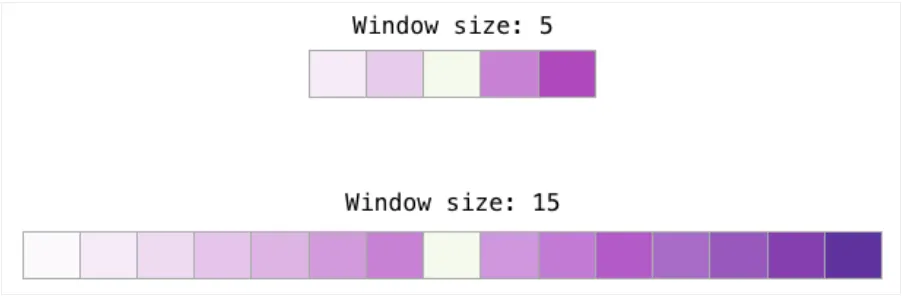
窗口大小直接影响词嵌入捕捉的语义关系类型:
-
• 较小的窗口 (2-15):嵌入倾向于反映词的可替换性。两个高相似度的词往往可以在相同位置互换。需要注意的是,反义词(如 “good” 和 “bad”)在小窗口下也可能具有高相似度,因为它们常出现在相似的局部上下文中。 -
• 较大的窗口 (15-50 甚至更大):嵌入更多地反映词的主题相关性,而非局部的语法可替换性。
Gensim 库的默认窗口大小为 5(输入词前后各取 5 个词)。
负样本数量方面,原始论文建议 5-20 个为宜;当数据集足够大时,2-5 个即可。Gensim 的默认值为 5。
8. 词向量在经管研究中的应用与扩展
8.1 经管领域的典型应用场景
词向量技术为经管领域的文本分析提供了有力的工具,以下是几类典型应用:
(1) 文本语义相似度度量
利用词向量计算文档之间的语义距离,可用于:
-
• 衡量企业年报之间的信息相似性,度量企业间战略趋同程度; -
• 比较不同地区政策文本之间的异同; -
• 进行学术文献的主题聚类与演化分析。
(2) 情感分析与语调度量
在金融文本分析中,研究者常利用词向量来扩展情感词典。给定一组已知的正面/负面种子词,通过余弦相似度自动发现语义相近的词汇,从而构建领域专用的情感词典。
(3) 概念度量与文化分析
词向量的代数运算特性可以被用来度量抽象概念:
-
• Kozlowski et al. (2019) 利用词向量度量文化维度中的性别、阶层等社会偏见; -
• Li et al. (2021) 利用词嵌入衡量企业文化的多个维度。
(4) 命名实体与关系抽取
在构建企业关联网络、识别供应链关系等任务中,词向量可以作为底层特征,辅助命名实体识别 (NER) 和关系抽取。
8.2 从 Word2vec 到上下文嵌入:方法演进
Word2vec 为每个词学习一个固定的向量表示,不区分同一个词在不同语境下的含义(即无法处理一词多义问题)。后续方法逐步克服了这一局限:
|
|
|
|
|---|---|---|
| GloVe
|
|
|
| FastText
|
|
|
| ELMo
|
|
|
| BERT
|
|
|
| GPT 系列
|
|
|
对于经管类研究者而言:
-
• 如果任务相对简单(如构建词典、计算文档相似度),Word2vec 或 GloVe 通常就能满足需求,且计算资源要求低; -
• 如果需要处理多义词或更精细的语义分析(如细粒度情感分类),可考虑 BERT 等上下文嵌入模型。
8.3 常用工具与资源
Python 包:
|
|
|
|
|---|---|---|
gensim |
|
|
spaCy |
|
|
transformers |
|
|
sentence-transformers |
|
|
whatlies |
|
|
预训练词向量资源:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
快速上手示例 (Gensim):
from gensim.models import Word2Vec# 准备语料:分好词的句子列表sentences = [["经济", "增长", "放缓"], ["货币", "政策", "宽松"], ["经济", "政策", "不确定性"]]# 训练 Skip-gram 模型model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=1) # sg=1 表示 Skip-gram# 查看词向量vector = model.wv["经济"]# 计算最相似的词similar_words = model.wv.most_similar("经济", topn=5)print(similar_words)8.4 延伸阅读
-
• Gentzkow, M., Kelly, B., & Taddy, M. (2019). Text as data. Journal of Economic Literature, 57(3), 535–574. Link[15], PDF[16], Google[17] —— 经济学领域文本分析的综述性文章。 -
• Kozlowski, A. C., Taddy, M., & Evans, J. A. (2019). The geometry of culture: Analyzing the meanings of class through word embeddings. American Sociological Review, 84(5), 905–949. Link[18], PDF[19], Google[20] —— 利用词向量度量文化概念的经典案例。 -
• Li, K., Mai, F., Shen, R., & Yan, X. (2021). Measuring corporate culture using machine learning. The Review of Financial Studies, 34(7), 3265–3315. Link[21], PDF[22], Google[23] —— 利用词嵌入度量企业文化。 -
• Ash, E., & Hansen, S. (2023). Text algorithms in economics. Annual Review of Economics, 15, 659–688. Link[24], PDF[25], Google[26] —— 经济学中文本算法的近期综述。
9. 小结
本文以图解方式介绍了 Word2vec 的核心原理。主要内容包括:
-
• 向量表示:用数值向量表示词语的语义特征,通过余弦相似度度量词与词之间的关系; -
• 训练思路:通过大规模文本中的上下文共现关系来学习词向量; -
• 两种架构:CBOW(由上下文预测目标词)和 Skip-gram(由目标词预测上下文); -
• 负采样:将多分类任务转化为二分类任务,大幅提升训练效率; -
• 应用扩展:词向量在经管研究中的典型应用场景及常用工具。
对于经管领域的研究者而言,Word2vec 提供了一种将非结构化文本转化为可计算语义表示的实用方法。理解其基本原理,有助于在实证研究中更合理地选择和使用文本分析工具。
10. 参考资料
-
• Ash, E., & Hansen, S. (2023). Text algorithms in economics. Annual Review of Economics, 15, 659–688. Link[24], PDF[25], Google[26] -
• Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. Journal of Machine Learning Research, 3, 1137–1155. Link[27], PDF[28], Google[29] -
• Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5, 135–146. Link[30], PDF[31], Google[32] -
• Carlson, R., Bauer, J., & Manning, C. D. (2025). A new pair of GloVes (Version 1). arXiv. Link[33], PDF[34], Google[35] -
• Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT (pp. 4171–4186). Link[36], PDF[37], Google[38] -
• Gentzkow, M., Kelly, B., & Taddy, M. (2019). Text as data. Journal of Economic Literature, 57(3), 535–574. Link[15], PDF[16], Google[17] -
• Gutmann, M. U., & Hyvärinen, A. (2010). Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (pp. 297–304). Link[39], PDF[6], Google[40] -
• Kozlowski, A. C., Taddy, M., & Evans, J. A. (2019). The geometry of culture: Analyzing the meanings of class through word embeddings. American Sociological Review, 84(5), 905–949. Link[18], PDF[19], Google[20] -
• Li, K., Mai, F., Shen, R., & Yan, X. (2021). Measuring corporate culture using machine learning. The Review of Financial Studies, 34(7), 3265–3315. Link[21], PDF[22], Google[23] -
• Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint, arXiv:1301.3781. Link[41], PDF[5], Google[42] -
• Pennington, J., Socher, R., & Manning, C. D. (2014). GloVe: Global vectors for word representation. In Proceedings of EMNLP (pp. 1532–1543). Link[43], PDF[44], Google[45] -
• Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. In Proceedings of NAACL-HLT (pp. 2227–2237). Link[46], PDF[47], Google[48]
相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh 词向量 文本分析 LLM, nocat md2安装最新版lianxh命令:ssc install lianxh, replace
-
• 丁闪闪, 2026, 从零开始玩转金融LLM:12个数据集+8个模型+完整代码实战[49]. -
• 丁闪闪 曾咏新 厦门大, 2026, 大语言模型如何重塑金融研究?一份全景式综述(上)[50]. -
• 修博文, 2024, 爬取政府工作报告文本-Python[51]. -
• 刘聪聪, 2020, Stata文本分析之-tex2col-命令-文字变表格[52]. -
• 初虹, 2022, Stata:fillmissing-缺失值填充-数值和文字的前后填充![53]. -
• 吴欣洋, 2025, AI自动生成研究假设,靠谱吗?流程与挑战[54]. -
• 吴茜, 2025, 我们需要因果 AI:Judea Pearl 聊 AI 的未来[55]. -
• 孙晓艺, 2024, 文本分析:正则表达式之位置匹配[56]. -
• 宗景辉, 2026, GenAI 正在如何改变金融研究?一份系统性综述 (上)[57]. -
• 宗景辉, 2026, GenAI 正在如何改变金融研究?一份系统性综述(下)[58]. -
• 宗景辉, 2026, GenAI 正在如何改变金融研究?一份系统性综述(中)[59]. -
• 张弛, 2025, 大语言模型到底是个啥?通俗易懂教程[60]. -
• 张琪琳, 2025, CClaRA-扒了四万篇论文:如何论证因果关系?[61]. -
• 李梦玉, 2025, 深度学习在经济学中的各类应用[62]. -
• 杜思昱, 2021, textfind:文本分析之词频分析-TF-IDF[63]. -
• 杜新月, 2025, 研究假设!研究假设!AI 来帮我[64]. -
• 梁海, 2020, Python:爬取东方财富股吧评论进行情感分析[65]. -
• 梁淑珍, 2022, Python:文本分析必备—搜狗词库[66]. -
• 游万海, 2020, Stata: 正则表达式和文本分析[67]. -
• 王卓, 2022, Python文本分析:将词转换为向量-Word2Vec[68]. -
• 王烨文, 2025, LLM Agent:大语言模型的智能体图解[69]. -
• 经菠, 2021, ldagibbs-基于LDA的文档分类模型-latent-Dirichlet-allocation-T305[70]. -
• 赵文琦, 2025, LLM系列:ChatGPT提示词精选与实操指南[71]. -
• 赵汗青, 2021, Stata文本分析:lsemantica-潜在语义分析的文本相似性判别[72]. -
• 连享会, 2020, ssc install lianxh:在 Stata 中快速搜索连享会推文[73]. -
• 连享会, 2021, 下载:金融领域中文情绪词典[74].
-
• 连享会, 2020, 在 Visual Studio (vsCode) 中使用正则表达式[76].
-
• 连享会, 2020, 正则表达式语言 – 快速参考[78]. -
• 连小白, 2025, GPU 还是 CPU?文本分析、LLM 微调、多模态各自怎么选[79]. -
• 陈云菲, 2025, PDF神器MinerU:结构重构、图表提取、LaTeX公式识别全搞定![80]. -
• 陈云菲, 2025, 新书推荐:《图解大模型》轻松上手 LLM![81]. -
• 颜国强, 2026, 从 15 分钟到 5 小时:2025 年大模型能力跃迁全景图[82].
连享会:2026五一论文班 · 线上时间:5月2-4日嘉宾:郭士祺 (上海交通大学)、戚树森 (厦门大学)、李学恒 (中山大学)咨询:王老师 18903405450(微信)

New! Stata 搜索神器:
lianxh和songblGIF 动图介绍搜: 推文、数据分享、期刊论文、重现代码 ……👉 安装:. ssc install lianxh. ssc install songbl👉 使用:. lianxh DID 倍分法. songbl all
🍏 关于我们
-
•连享会 ( www.lianxh.cn,推文列表) 由中山大学连玉君老师团队创办,定期分享实证分析经验。 -
• 直通车: 👉【百度一下:连享会】即可直达连享会主页。亦可进一步添加 「知乎」,「b 站」,「面板数据」,「公开课」 等关键词细化搜索。

引用链接
[1] gongqian1999yt@163.com: mailto:gongqian1999yt@163.com[2] Link: https://jalammar.github.io/illustrated-word2vec/[3] BERT: https://jalammar.github.io/illustrated-bert/[4] GloVe: https://nlp.stanford.edu/projects/glove/[5] 2013: https://arxiv.org/pdf/1301.3781.pdf[6] Gutmann & Hyvärinen, 2010: http://proceedings.mlr.press/v9/gutmann10a/gutmann10a.pdf[7] GitHub: https://github.com/piskvorky/gensim[8] GitHub: https://github.com/explosion/spaCy[9] GitHub: https://github.com/huggingface/transformers[10] GitHub: https://github.com/UKPLab/sentence-transformers[11] GitHub: https://github.com/koaning/whatlies[12] Link: https://code.google.com/archive/p/word2vec/[13] Link: https://fasttext.cc/docs/en/crawl-vectors.html[14] Link: https://ai.tencent.com/ailab/nlp/en/embedding.html[15] Link: https://doi.org/10.1257/jel.20181020[16] PDF: https://web.stanford.edu/~gentzkow/research/text-as-data.pdf[17] Google: https://scholar.google.com/scholar?q=Text+as+data+Gentzkow+Kelly+Taddy[18] Link: https://doi.org/10.1177/0003122419877135[19] PDF: https://arxiv.org/pdf/1803.09288[20] Google: https://scholar.google.com/scholar?q=The+geometry+of+culture+Analyzing+the+meanings+of+class+through+word+embeddings[21] Link: https://doi.org/10.1093/rfs/hhaa079[22] PDF: https://www.fengmai.net/download/manuscripts/LiMaiShenYan2021_Measuring%20Corporate%20Culture%20Using%20Machine%20Learning-RFS.pdf[23] Google: https://scholar.google.com/scholar?q=Measuring+corporate+culture+using+machine+learning[24] Link: https://doi.org/10.1146/annurev-economics-082222-074352[25] PDF: https://elliottash.com/wp-content/uploads/2023/04/Ash-Hansen-Text-Algorithms-Economics.pdf[26] Google: https://scholar.google.com/scholar?q=Text+algorithms+in+economics+Ash+Hansen[27] Link: https://doi.org/10.1162/153244303322533223[28] PDF: https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf[29] Google: https://scholar.google.com/scholar?q=A+neural+probabilistic+language+model+Bengio+Ducharme+Vincent+Jauvin[30] Link: https://doi.org/10.1162/tacl_a_00051[31] PDF: https://aclanthology.org/Q17-1010.pdf[32] Google: https://scholar.google.com/scholar?q=Enriching+word+vectors+with+subword+information[33] Link: https://doi.org/10.48550/arXiv.2507.18103[34] PDF: https://arxiv.org/pdf/2507.18103[35] Google: https://scholar.google.com/scholar?q=A+new+pair+of+GloVes+Carlson+Bauer+Manning[36] Link: https://doi.org/10.18653/v1/N19-1423[37] PDF: https://aclanthology.org/N19-1423.pdf[38] Google: https://scholar.google.com/scholar?q=BERT+Pre-training+of+deep+bidirectional+transformers+for+language+understanding[39] Link: https://proceedings.mlr.press/v9/gutmann10a.html[40] Google: https://scholar.google.com/scholar?q=Noise-contrastive+estimation+A+new+estimation+principle+for+unnormalized+statistical+models[41] Link: https://doi.org/10.48550/arXiv.1301.3781[42] Google: https://scholar.google.com/scholar?q=Efficient+estimation+of+word+representations+in+vector+space[43] Link: https://doi.org/10.3115/v1/D14-1162[44] PDF: https://nlp.stanford.edu/pubs/glove.pdf[45] Google: https://scholar.google.com/scholar?q=GloVe+Global+vectors+for+word+representation[46] Link: https://doi.org/10.18653/v1/N18-1202[47] PDF: https://aclanthology.org/N18-1202.pdf[48] Google: https://scholar.google.com/scholar?q=Deep+contextualized+word+representations[49] 从零开始玩转金融LLM:12个数据集+8个模型+完整代码实战: https://www.lianxh.cn/details/1754.html[50] 大语言模型如何重塑金融研究?一份全景式综述(上): https://www.lianxh.cn/details/1751.html[51] 爬取政府工作报告文本-Python: https://www.lianxh.cn/details/1354.html[52] Stata文本分析之-tex2col-命令-文字变表格: https://www.lianxh.cn/details/328.html[53] Stata:fillmissing-缺失值填充-数值和文字的前后填充!: https://www.lianxh.cn/details/1050.html[54] AI自动生成研究假设,靠谱吗?流程与挑战: https://www.lianxh.cn/details/1588.html[55] 我们需要因果 AI:Judea Pearl 聊 AI 的未来: https://www.lianxh.cn/details/1655.html[56] 文本分析:正则表达式之位置匹配: https://www.lianxh.cn/details/1350.html[57] GenAI 正在如何改变金融研究?一份系统性综述 (上): https://www.lianxh.cn/details/1760.html[58] GenAI 正在如何改变金融研究?一份系统性综述(下): https://www.lianxh.cn/details/1762.html[59] GenAI 正在如何改变金融研究?一份系统性综述(中): https://www.lianxh.cn/details/1761.html[60] 大语言模型到底是个啥?通俗易懂教程: https://www.lianxh.cn/details/1600.html[61] CClaRA-扒了四万篇论文:如何论证因果关系?: https://www.lianxh.cn/details/1589.html[62] 深度学习在经济学中的各类应用: https://www.lianxh.cn/details/1718.html[63] textfind:文本分析之词频分析-TF-IDF: https://www.lianxh.cn/details/548.html[64] 研究假设!研究假设!AI 来帮我: https://www.lianxh.cn/details/1715.html[65] Python:爬取东方财富股吧评论进行情感分析: https://www.lianxh.cn/details/440.html[66] Python:文本分析必备—搜狗词库: https://www.lianxh.cn/details/1078.html[67] Stata: 正则表达式和文本分析: https://www.lianxh.cn/details/35.html[68] Python文本分析:将词转换为向量-Word2Vec: https://www.lianxh.cn/details/1134.html[69] LLM Agent:大语言模型的智能体图解: https://www.lianxh.cn/details/1650.html[70] ldagibbs-基于LDA的文档分类模型-latent-Dirichlet-allocation-T305: https://www.lianxh.cn/details/593.html[71] LLM系列:ChatGPT提示词精选与实操指南: https://www.lianxh.cn/details/1615.html[72] Stata文本分析:lsemantica-潜在语义分析的文本相似性判别: https://www.lianxh.cn/details/640.html[73] ssc install lianxh:在 Stata 中快速搜索连享会推文: https://www.lianxh.cn/details/233.html[74] 下载:金融领域中文情绪词典: https://www.lianxh.cn/details/673.html[75] 公开课:王菲菲-文本分析在经济金融领域的应用: https://www.lianxh.cn/details/1230.html[76] 在 Visual Studio (vsCode) 中使用正则表达式: https://www.lianxh.cn/details/10.html[77] 文本分析:从文本到论文: https://www.lianxh.cn/details/1259.html[78] 正则表达式语言 – 快速参考: https://www.lianxh.cn/details/81.html[79] GPU 还是 CPU?文本分析、LLM 微调、多模态各自怎么选: https://www.lianxh.cn/details/1716.html[80] PDF神器MinerU:结构重构、图表提取、LaTeX公式识别全搞定!: https://www.lianxh.cn/details/1618.html[81] 新书推荐:《图解大模型》轻松上手 LLM!: https://www.lianxh.cn/details/1603.html[82] 从 15 分钟到 5 小时:2025 年大模型能力跃迁全景图: https://www.lianxh.cn/details/1750.html