 夜雨聆风
夜雨聆风





Claude Code 源码泄露事件:系统化学习指南
📅 事件日期:2026年3月31日 | 来源:多平台技术分析汇总 | 整理:小旺
一、事件全景
核心事实:Anthropic 在发布 Claude Code v2.1.88 到 npm 时,因多重配置错误,导致 512,000 行 TypeScript 源码泄露至公开互联网。
泄露规模一览
|
指标 |
数值 |
|---|---|
|
泄露代码行数 |
512,000+ 行 |
|
TypeScript 文件数 |
1,906 个 |
|
Source Map 大小 |
59.8 MB |
|
GitHub 峰值 Star |
2小时内破 50,000 |
|
GitHub Fork 数 |
41,500+ |
|
原始推文浏览量 |
1,600 万 |
|
Hidden Feature Flags |
44 个 |
|
Claude Code 年化收入 (ARR) |
$25 亿美元 |
|
Anthropic 总 ARR |
$190 亿美元 |
二、技术根因:三层失误叠加
2.1 第一层:.npmignore 配置遗漏
npm 包发布时,build 工具链会生成 source map(.map 文件)用于调试。正确做法是在 .npmignore 中排除 *.map 文件。
Claude Code 的问题:
# 正确配置应该包含:*.mapdist/*.map# 实际情况:# .npmignore 里压根没写 .map 相关的排除规则就这样,一行配置的缺失,导致整个 source map 被打包进了 npm 包。
2.2 第二层:R2 存储桶公开可访问
Source map 文件(59.8 MB)本身并不直接包含源码,而是指向一个 Cloudflare R2 存储桶中的
src.zip文件。泄露路径:
npm install @anthropic-ai/claude-code→ 下载包内包含 main.js.map (59.8 MB)→ .map 文件包含指向 src.zip 的 URL→ src.zip 托管在 Anthropic 自己的 R2 存储桶→ 该存储桶完全公开,无需任何认证→ 任何人可直接下载并解压 51.2 万行 TypeScript 源码2.3 第三层:Bun 运行时的已知 Bug
Anthropic 在 2025 年底收购了 Bun JavaScript 运行时,Claude Code 构建于 Bun 之上。然而:
-
Bun Issue #28001(2026年3月11日提交):source map 会在生产构建中被 served,尽管文档说不会
-
这个 Bug 在泄露发生时已公开 20 天,但未被标记为关键级别
-
Anthropic 自己收购的工具链,间接导致了自家产品的源码泄露
讽刺拉满
:Claude Code 有一个专门的 “Undercover Mode”,用于防止 AI 在 git commit 中泄露内部代号。然而人类工程师的配置失误,让整个源码大白于天下。
三、事件时间线
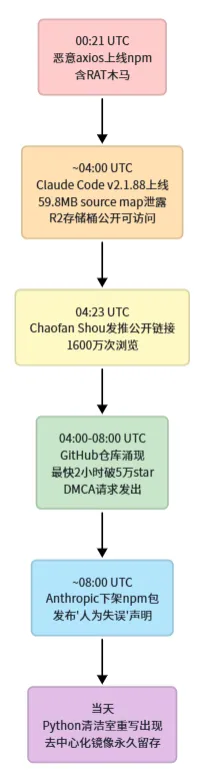
四、架构精华(最值得学习)
核心洞察:AI 编程工具的真正护城河不是底层模型,而是工具架构、记忆系统和权限模型的设计水平。模型可以被复制,但一套生产级的 agent 架构需要数年工程积累。
4.1 Tool System(约40个工具,~29,000行)
Claude Code 采用插件式架构,每个能力都是一个独立的、权限 gated 的工具:
|
工具名称 |
功能 |
关键特性 |
|---|---|---|
|
BashTool |
Shell 命令执行 |
内置安全 guardrails |
|
FileReadTool / FileWriteTool / FileEditTool |
文件读写编辑 |
各自独立权限模型 |
|
WebFetchTool |
实时网络访问 |
按需 fetch |
|
LSPTool |
语言服务器协议集成 |
IDE 级别的代码理解 |
|
GlobTool / GrepTool |
代码库搜索 |
结构化检索 |
|
MultiEditTool |
原子性多文件编辑 |
事务性保证 |
|
TodoReadTool / TodoWriteTool |
任务跟踪 |
与外部工具集成 |
每个工具都有独立的权限模型、验证逻辑和输出格式化。基础工具定义部分就有 29,000 行代码。
4.2 Query Engine(~46,000行)
被称为”整个系统的大脑”:
-
所有 LLM API 调用和响应流
-
Token 缓存和上下文管理
-
多智能体编排
-
重试逻辑
4.3 三层记忆架构(应对 Context Entropy)
这是泄露中被研究最深入的部分。Anthropic 解决的是”Context Entropy”问题——长会话中 AI 容易产生幻觉。
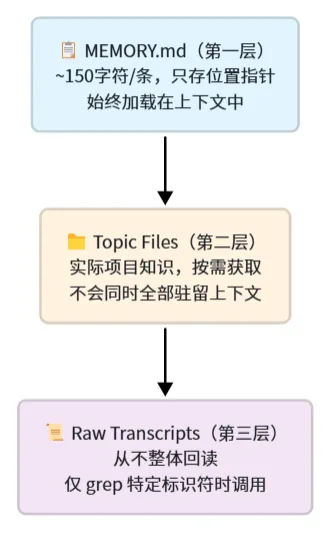
关键设计原则——”Strict Write Discipline”(严格写入纪律):
-
Agent 只有在确认文件写入成功后才能更新自己的记忆索引
-
这样就防止了 Agent 在失败尝试中污染上下文
-
Agent 将自己的记忆视为”提示”而非”事实”,在行动前会对照实际代码库验证
设计启示:构建一个”怀疑一切”的记忆系统,而不是”存储一切”的系统。
4.4 多智能体协调架构
Claude Code 从设计之初就是为多智能体协调而构建的:
-
Coordinator Mode:一个 Claude 派生并管理多个并行工作的 Worker Claude
-
协调者负责任务分发、结果聚合和冲突处理
-
核心循环、工具系统、记忆和权限模型、编排层都假设多个 agent 会一起运行并共享状态
五、隐藏功能(未发布)
5.1 KAIROS:常驻自主 Agent
在源码中被提及 150+ 次。核心理念:
-
Always-On 后台守护进程模式
-
闲置时执行 autoDream 记忆整合
-
合并分散的观察结果、去除逻辑矛盾
-
将模糊洞察转化为经验证的事实
5.2 ULTRAPLAN:30分钟远程规划
-
将复杂规划任务卸载到云端容器运行时(CCR)
-
使用 Opus 模型,给予最多 30 分钟思考时间
-
用户可在手机或浏览器批准结果
-
特殊 sentinel 值
__ULTRAPLAN_TELEPORT_LOCAL__将结果传回本地终端
5.3 BUDDY:Tamagotchi 风格桌面宠物 🐣
最受欢迎的非技术发现:
-
终端输入框旁的泡沫宠物
-
18个物种(Duck、Dragon、Axolotl、Capybara、ghost 等)
-
稀有度等级:Common → Uncommon → Rare → Epic → Legendary
-
1% 闪光概率(独立于稀有度)
-
5项属性:DEBUGGING / PATIENCE / CHAOS / WISDOM / SNARK
计划发布时间窗口:2026年4月1日-7日。
5.4 Undercover Mode:隐藏 AI 身份
-
系统提示词要求”你正在 undercover 行动”
-
commit 信息禁止包含任何 Anthropic 内部信息
-
模型名称(如 “Tengu”、”Capybara”)在外部仓库中被强制屏蔽
5.5 Anti-Distillation(反蒸馏)
两层机制防止竞争对手通过记录 API 流量训练自己的模型:
第一层:ANTI_DISTILLATION_CC 标志在 API 请求中注入 fake_tools 字段,”毒化”竞争对手的训练数据。
第二层:服务器端对工具调用之间的推理过程进行缓冲和摘要返回,并加密签名。
六、内部指标与教训
6.1 Capybara 模型(下一代 Claude)
泄露确认了几个未来模型的内部代号:
-
Capybara:Claude 4.6 变体代号
-
Fennec:对应 Opus 4.6
-
Numbat:仍在测试中
内部文件显示 Capybara v8 的虚假声明率仍为 29-30%,相比 v4 的 16.7% 实际上是倒退。
6.2 每日 25 万次浪费的 API 调用
最坦诚的内部自白(来自 autoCompact.ts):
"BQ 2026-03-10: 1,279 个会话出现 50+ 次连续失败,
每天浪费约 25 万次全球 API 调用。"
修复方法:3行代码——设置 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3。
有时候好的工程就是知道什么时候该放弃。
七、安全警示
如果在 2026年3月31日 00:21-03:29 UTC 之间通过 npm 更新过 Claude Code,请立即检查 lockfile 中是否包含恶意 axios 版本。
检查命令:
grep -r "1.14.1\|0.30.4\|plain-crypto-js" package-lock.json
grep -r "1.14.1\|0.30.4\|plain-crypto-js" yarn.lock
grep -r "1.14.1\|0.30.4\|plain-crypto-js" bun.lockb
如果发现匹配: 将机器视为完全沦陷 → 立即轮换所有凭证 → 干净重装系统
安全安装方式(Anthropic 推荐):
curl -fsSL https://claude.ai/install.sh | bash
八、构建 AI 系统的 16 条经验
架构层面
-
工具 = 模块化安全积木 — 默认权限模型极度严格,所有工具
checkPermissions默认为 “ask” -
为多智能体协调而设计 — 从第一天就把协调层建在核心循环里,不是后期添加
-
四层记忆结构 — 同时管理活跃工作流和跨 agent 共享上下文
-
透明性构建信任 — 用户能清楚看到 agent 在做什么、为什么做
安全层面
-
预防失败也是体验的一部分 — 内置 2,500+ 行 bash 验证逻辑
-
严格权限分层 — 每个工具独立 gating,不是全局一刀切
-
Anti-distillation 要做,但知道它不是银弹 — 真正的护城河是法律而非技术
记忆层面
-
“怀疑一切”的记忆 — Agent 被要求把自身记忆当作”提示”而非”事实”
-
严格写入纪律 — 记忆只能基于确认成功的操作更新
-
分层按需加载 — 不是全部加载,是 LOCATIONS(索引)常驻,知识按需获取
性能层面
-
知道何时放弃 — 3次连续失败后停止重试
-
为”长时间运行”而设计 — 解决 Context Entropy 是核心工程挑战
-
压缩胜过截断 — 面对上下文增长时的策略是压缩而非简单丢弃
UX 层面
-
让失败有尊严 — 错误信息应该帮助用户理解出了什么问题
-
个性增加黏性 — BUDDY 宠物的设计说明产品个性是留存的重要手段
多智能体层面
-
协调者模式 — 一个 agent 管理多个 worker,任务分发→结果聚合→冲突处理是标准模式
九、系统化学习路径
推荐阅读顺序
|
顺序 |
文章 |
来源 |
重点 |
|---|---|---|---|
|
1 |
The Great Claude Code Leak of 2026 |
dev.to |
事件全貌 + 根因分析 |
|
2 |
VentureBeat 报道 |
VentureBeat |
架构分析 + 安全警示 |
|
3 |
Everyone Analyzed Features. Nobody Analyzed Architecture |
Medium |
架构护城河分析 |
|
4 |
16 Lessons on Building Production-Ready AI |
Analytics Vidhya |
实战经验总结 |
|
5 |
HuggingFace 架构模式分析 |
HuggingFace |
工程级架构视角 |
|
6 |
The Claude Code Leak (PDF) |
SSRN |
学术级深度分析 |
学习重点指引
-
AI 应用开发者:重点看第四、五部分(Tool System + 三层记忆架构)
-
AI 产品经理:重点看第五部分(隐藏功能)和第八部分(经验教训)
-
AI 安全研究员:重点看第三部分(根因)和第七部分(安全警示)
-
想构建自己的 Agent:四层记忆结构、多智能体协调模式、严格权限模型最值得借鉴
十、事件反思
这个事件给我们的终极教训不是 Anthropic 有多不小心,而是它有多认真对待 AI 工程。一套 51.2 万行的 TypeScript 代码,全部围绕”让 AI 能可靠地编程”这一件事。护城河不在于模型本身,而在于这些年积累的工程细节。
最讽刺的对比:Anthropic 有一整个子系统(Undercover Mode)专门防止 AI 泄露内部代号。然后人类工程师把整个源码泄露了。AI 安全工程和人类发布工程之间的差距发人心醒。
整理:小旺 | 2026-04-06主要参考来源:dev.to、VentureBeat、Analytics Vidhya、HuggingFace、SSRN