 夜雨聆风
夜雨聆风





Gemma 4 是 Agent APP 的 Iphone 时刻
2007 年,乔布斯从兜里掏出 iPhone,台下的人还以为是个大号 iPod。结果呢?整个移动互联网炸了。
2026 年 4 月 2 日,Google 发布了 Gemma 4 系列模型,其中两个小家伙——E2B 和 E4B——专门为手机设计,原生支持视觉、语音和函数调用(Function Calling)。
如果没听出这意味着什么,笔者翻译一下:
一个不到 4B 参数的大模型,塞进你的手机,不联网,不调 API,能看图、能听声、能调用 App 功能。
这不是”AI 助手”升级了,这是 Agent APP 的 iPhone 时刻。
为什么这么说?
之前有个很火的语音输入软件叫 Typeless,年订阅价144 美金 1000 多人民币。许多人趋之若鹜,语音转文字确实好用。但你仔细想想,Typeless 的语音识别大概率走的是 OpenAI 或 Deepgram 的云端 API。每次你对着手机说话,语音数据先飞到美国的某个数据中心,识别完再飞回来。
一来隐私裸奔——你的声音数据飘在别人的服务器上。二来成本不低——Typeless 每月 12 美元的定价背后,是实打实的 API 调用费。
有了 Gemma 4 的 E2B 和 E4B,这类 Agent APP 的大模型调用成本变成了一个非常好看的数字:0元。
Google 还特意把 Gemma 4 的许可协议从过去限制重重的 Gemma License 换成了 Apache 2.0——完全免费商用,不要求开源衍生品,不限制商业用途。
理论上每个有好奇心的人,都能低成本手搓一个 Agent APP。
以前这句话是画饼。现在不是了。
01
PART
E2B、E4B 模型的特点
为边缘计算而生的 Omni 小钢炮
这两个模型最显著的突破是:在 4B 以下的极小体量内,原生支持多模态输入(文字 + 视觉 + 语音)和函数调用。
为什么这三项能力如此关键?
因为人在手机上跟 App 互动,从来不只是打字。
你可能懒得打字,直接发语音;可能拍张照片问”这是什么花”;可能截个图让 AI 帮你总结。文字、图片、语音——这三种输入是手机场景的标配。一个手机端的本地模型如果只能处理文字,那跟一个高级搜索框有什么区别?
E2B(Effective 2B,实际参数约 2.3B)和 E4B(Effective 4B,实际参数约 4.5B)原生支持三种输入类型,配合 128K 的上下文窗口和 140+ 种语言支持。
可以把 E2B 和 E4B 理解为手机端的 Omni 模型。
Omni 是”全模态”的意思——全模态输入与输出(Omni-modal)。
提到 Omni,小米刚发布的 MiMo-V2-Omni 也很猛,号称要做 Agent APP 的基座模型,支持图像、视频、音频联合推理,甚至能连续理解超过 10 小时的音频。但 MiMo-V2-Omni 的参数量级决定了它很难塞进手机本地跑。
开源社区里还有 Qwen3-Omni,能力也不差,但同样——完全不可能放入手机。
Gemma 4 的 E2B 和 E4B 是目前唯一能在手机端本地跑、同时原生支持视觉 + 语音 + 函数调用的开源模型。
Google 为了这两个小模型,专门拉上了 Pixel 团队、高通和联发科一起协作优化。跑在手机、树莓派、Jetson Nano 上,号称近零延迟。
这就像当年 iPhone 不是第一个触屏手机,但它是第一个把触屏体验做到”能用且好用”的手机。E2B 和 E4B 不是第一个小模型,但它们是第一个把多模态 + 函数调用做到”手机端能跑且实用”的模型。
02
PART
E2B、E4B 多模态能力实测
用于手机整活完全没问题
光说参数没意思,得上手搓。
笔者有个随时收集信息的习惯——可能是朋友分享的一篇文章链接,可能是自己灵光乍现想到的产品方向,可能是想记下的一个开源项目名称,甚至是听到的一期播客。
以前的做法是打开备忘录记一笔,然后就忘了。现在的做法是在 IM 里直接发给自己的 Agent,让它帮忙分析一下,自动录入 Obsidian,有空再研究。
于是笔者手搓了一个本地 Agent,接入 E2B 模型试试水。
首先,我在手搓的 agent 里设置好本地调用的 E2B 模型:
文字对话——还行: 然后在 im 里哈个啰,E2B 结合 Prompt 回复得还行:
文章摘要——能用。
朋友分享了一篇文章,转发给 Agent 让它提炼要点。说实话,总结质量和 MiniMax 2.7 比还是差了一点点——关键信息都抓到了,但措辞不够精炼,偶尔会冒出一些”正确的废话”。
不过话说回来,这是一个 2B 参数的模型在手机上跑出来的结果。现在每个月花百多块专门用于处理文字的 API,干的也就是这活儿。

图片识别——基本准确。
接着发张图给他,正常识别,图片表达的主题意思,描述基本准确:

语音识别——翻车了。
发了条语音消息过去,Σ(°ロ°),出 bug 了。Agent 完全不响应。
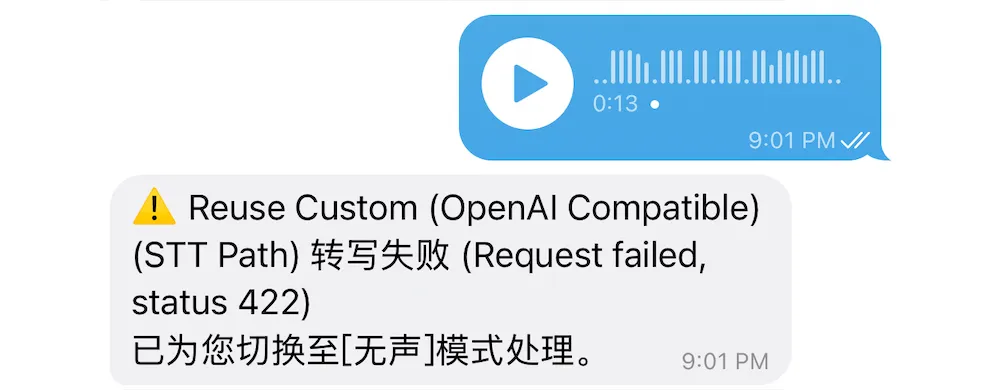
笔者当时以为是自己手搓的 Agent 接入逻辑有问题,debug 了整整两个小时。改了消息格式、重启了三遍服务,甚至怀疑是不是 Prompt 写得有毛病。
结果排查下来——是部署本地模型的基座 oMLX 还不支持语音输入。
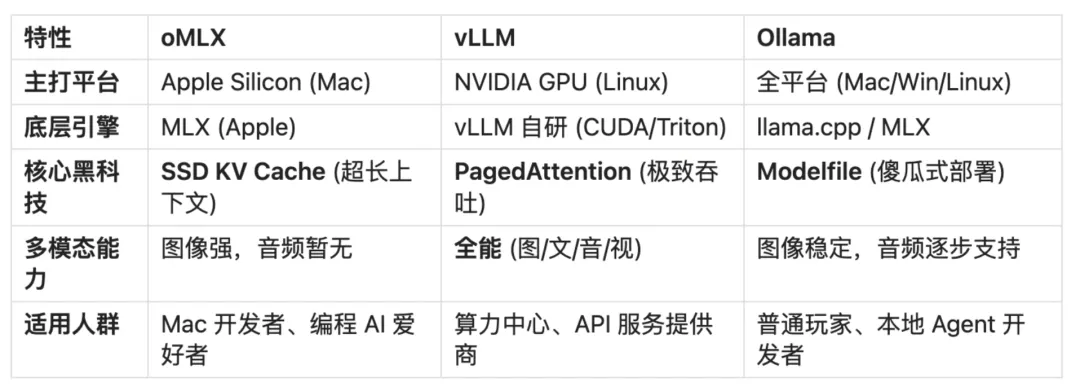
oMLX 是一个为 Apple Silicon 优化的本地推理服务器,文本和图像模型跑得飞起,但音频输入接口还没跟上。E2B 本身是支持语音的,但中间这层”翻译官”掉链子了。
两个小时的 debug 时间,买个教训:模型能力是一回事,部署基座的支持度是另一回事。 看来支持大模型本地部署的基座们,也需要赶紧跟上。
最终文字和图片识别的内容,自动生成了 Markdown 文档,存入笔者常年开机的本地 Obsidian。流程跑通了大半,等 oMLX 补上音频支持,就是完整的闭环。

03
PART
如果安卓自带 E2B
每个 APP 都值得重做一遍
安卓系统植入多模态端侧模型,已经不是”会不会”的问题,而是”什么时候”的问题。
Google 和 Pixel 团队、高通、联发科一起优化 E2B 和 E4B,摆明了就是在为”系统级集成”铺路。今天是 Pixel 手机预装,明天就是整个安卓生态标配。
一旦安卓系统原生集成了多模态端侧模型,事情就有趣了。
翻译 APP 可能第一个遭殃。
翻译 APP 过去最大的卖点是什么?实时翻译、同声传译。但如果系统自带的端侧模型就能做到呢?而且是本地跑,不联网,零延迟,不花钱。
那翻译 APP 存在的意义是什么?
更进一步——如果社交软件内置了实时翻译,你跟一个日本人聊天,你说中文他说日语,双方各自看到母语,那传统翻译 APP 是不是就没了?
其实现在已经有大量跨国社交 APP 在做类似的事了。只不过它们依赖云端 API,成本高、延迟大。端侧模型一旦解决了成本和延迟问题,跨语言社交会成为常态而非特例。
翻译 APP 消失不消失不好说,但翻译作为一个独立品类的 APP,商业壁垒已经塌了。
Function Calling 才是真正的杀手锏。
多人关注 E2B 的多模态能力——能看图、能听声——但忽略了一个更有用的特性:原生函数调用(Function Calling)。
能看、能听,只是”感知”。能调用函数,才是”行动”。
感知 + 行动 = Agent。
举个每个人都可能遇到的例子。
你买了一台高级路由器。拆开包装,打开管理后台,迎面砸来一堆名词:静态路由、VLAN、DHCP 地址池、NAT 映射、QoS 带宽策略……
你只是想让家里 Wi-Fi 快一点,结果感觉自己在考网络工程师资格证。
搜教程?每篇教程对应的路由器型号都不一样,按钮位置对不上,固件版本也不同。问客服?排队半小时,对面让你”重启试试”。
现在想象一下:你打开手机,对准路由器背面的铭牌拍一张照。
铭牌上印着管理地址 192.168.1.1、默认用户名 admin、默认密码 admin@2026、型号 AX6000 Pro。
接下来三件事自动发生:
视觉识别——E2B 通过摄像头识别铭牌上的文字信息,提取登录地址、账号密码、设备型号
函数调用登录——模型调用本地网络函数,通过 HTTP 请求登录路由器管理后台
函数调用配置——根据你家的网络环境(几个人用、有没有 NAS、打不打游戏),自动调用路由器的配置 API,完成 VLAN 划分、QoS 策略设置、Wi-Fi 信道优化
你全程只做了一件事:拍了张照。
过去这活儿,轻则折腾一下午翻论坛帖子,重则花钱请人上门。而且路由器这东西,配错了网就断了,断了之后你连搜教程的网都没有——经典的”需要联网才能修网”死循环。
有了端侧模型 + 函数调用,手机变成了一个拍一下就搞定的网络工程师。模型跑在本地,通过局域网直接跟路由器通信,压根不需要互联网。
这只是一个生活场景。把思路打开——智能家居设备的初始配置、打印机的驱动安装、新买的 NAS 的初始化设置……所有”说明书又长又看不懂、客服又排不上队”的硬件配置场景,都能被这套”视觉 + 函数调用”的组合拳一拍搞定。
Function Calling 让端侧模型从”能聊天的玩具”变成了”能干活的工具”。
游戏会更惊艳。
这是笔者最期待的部分。
手机摄像头、麦克风都可以作为实时输入加入游戏模态。想象一下——你对着手机摄像头做了个手势,游戏角色跟着做出同样的动作。你对着麦克风喊了句”开门”,游戏里的门真的开了。
固定的游戏套路变成可变套路。NPC 的对话不再是预设的几百句脚本,而是由本地模型即时生成,根据你之前的游戏行为和对话历史产生个性化回应。
每个玩家的游戏体验都是独一无二的。
而且这一切都在本地计算,不依赖网络,不需要付费,不存在隐私泄露。
安卓和 iOS 系统集成端侧多模态模型之后,最终会消灭掉哪些 APP?
笔者觉得,与其问”消灭谁”,不如问”谁能进化”。
能接入系统级端侧模型能力的 APP,会变得更强;不能接入的,会变成信息孤岛。就像当年不支持触屏操作的 APP 被 iPhone 淘汰一样——不是功能不好,是交互方式过时了。
回到标题:为什么说 Gemma 4 是 Agent APP 的 iPhone 时刻?
iPhone 之前,智能手机也有,触屏也有,APP 也有。但 iPhone 把硬件、操作系统、开发者生态三件事同时做对了,才引爆了移动互联网。
Gemma 4 做的是类似的事:
模型够小——2B/4B 参数,手机跑得动
能力够全——文字、图像、语音、函数调用,Agent 该有的全有
协议够开——Apache 2.0,谁都能用,谁都能改,谁都能卖
大模型调用成本归零、隐私完全本地化、多模态能力原生支持——这三件事凑在一起,Vibe Coding 手搓手机 Agent APP 的时代,真的来了。
以前你想做一个语音笔记 APP,得接 Whisper API、接 GPT API、搞服务器、算成本、处理隐私合规。现在?下载一个 E2B 模型,本地跑起来,搞定。
每个有好奇心的人,都可以成为 Agent APP 的开发者。
这件事的影响有多大?可能得等三五年才看得清楚。就像 2007 年没人想到 iPhone 会催生出 Uber、Instagram 和整个移动支付生态。
但有一点可以确定:当大模型从云端落入每个人的口袋,应用层的想象力就不再被 API 价格和网络延迟所束缚。
等着大家做出 Agent 时代的“抖音”和“微信”,还有“王者荣耀”。
觉知思想,感受科技
松先生笔谈
10年,我觉得做产品就是做用户体验。15年,我觉得做产品就是懂人性的贪嗔痴。25年,我觉得做产品,不熟悉文史哲,不反思人之所以为人,根本做不好产品。
额……居然拉到了底,感谢你的耐心。
有共鸣求个赞,有异议请吐槽。
没看够的话,顺手点个关注吧 ^_^