 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:AI 同时读 10 个文件是怎么做到的,工具并发执行引擎全拆解
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 76 篇,Claude Code 源码揭秘系列第 8 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let’s explore。无界探索,有术而行。
本系列已更新至第 7 篇,往期精彩:
-
第 1 篇:5 个 Agent 设计模式拆解 — Agent 调度、Repl、工具路由、权限链、Speculation -
第 2 篇:Buddy 宠物系统 — 情感化 UI 交互设计 -
第 3 篇:Skills 系统 — AI 如何学会你的工作流 -
第 4 篇:三级压缩系统 — 上下文管理的工程艺术 -
第 5 篇:Speculation 预判执行 — AI 的分支预测 -
第 6 篇:权限系统与 YOLO Classifier — AI 如何给自己当保安 -
第 7 篇:MCP 协议集成全拆解 — AI 编程工具如何连接整个开发工具链
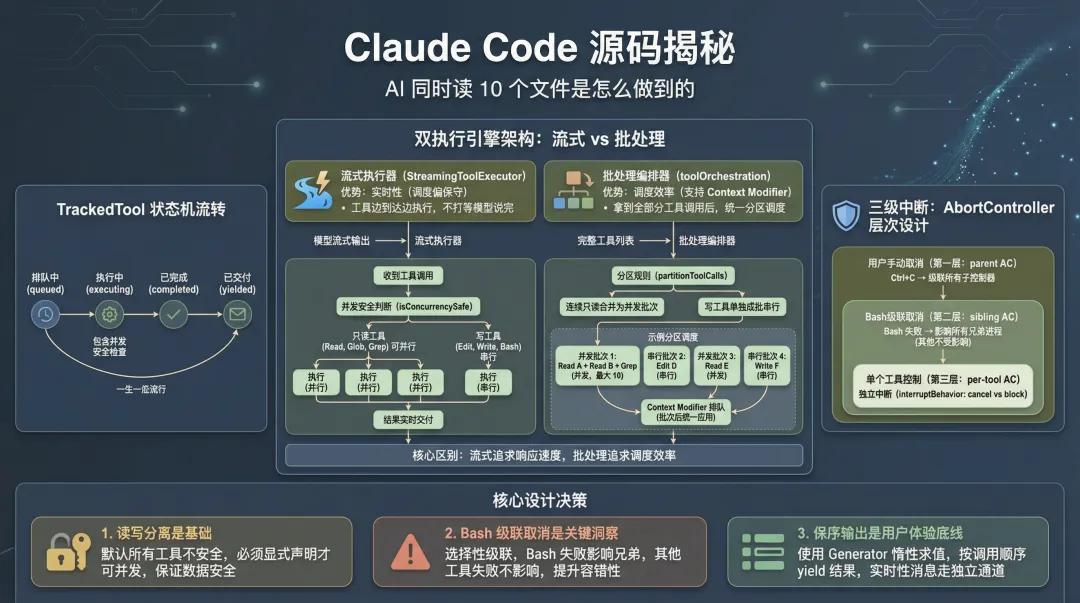
假设你正在用 Claude Code 分析一个老项目。你让它:读一下 src 目录下所有组件的代码,再搜一下哪些地方用了 deprecated API。
如果是串行执行,10 个文件逐个读,再加上几次 Grep 搜索,等它跑完你可能已经泡好了一杯咖啡。但 Claude Code 实际上是把 10 个 Read 请求和 5 个 Grep 请求同时扔出去的——所有只读操作并行执行,几秒内全部返回。
问题来了:两个工具同时写同一个文件怎么办?三个 Bash 命令有先后依赖怎么处理?中途某个命令报错了,其他还在跑的要不要停?
Claude Code 的回答是:读写分离 + 智能调度 + 级联取消。翻了一遍泄露的源码,这套并发控制的设计比我想象的精细得多。
1. 两套执行引擎,各自分工
Claude Code 内部其实有两套工具执行引擎,分别应对不同的使用场景。
一套叫 StreamingToolExecutor——流式执行器。当模型在 streaming 过程中逐个吐出工具调用时,这套引擎能让工具边到达边执行,不用等所有工具调用都输出完毕才开始。想象一下,模型输出了 3 个 Read 工具调用,还没输出第 4 个,前 3 个已经在并行跑了。
另一套叫 toolOrchestration——批处理编排器。它处理的是一批已经确定的工具调用,先把它们分区(只读的归只读,有副作用的归有副作用的),然后按批次执行。批处理编排器还支持 Context Modifier——工具执行前修改上下文的能力,这是流式执行器不具备的。
为什么需要两套?
流式执行器的优势是实时性:工具不用等模型把话说完就能开始干活,用户能更快看到进度。但它有个限制——工具调用是流式到达的,执行器无法预知”后面还有没有工具”,所以调度策略偏保守。
批处理编排器则能看到全貌:一次性拿到所有工具调用,可以做出更激进的分区和调度决策。代价是必须等模型把所有工具调用都输出完。
说白了,一个打的是响应速度,一个打的是调度效率。
2. StreamingToolExecutor:边流边跑
这一节是全文的重点。StreamingToolExecutor 的核心设计思想可以概括为一句话:工具一边流式到达,一边判断能不能执行,能就立刻跑。
状态机:每个工具的四段人生
每个进入执行器的工具都会被包装成一个 TrackedTool 对象,它有四种状态:
type ToolStatus = 'queued' | 'executing' | 'completed' | 'yielded'-
queued:工具已入队,等待执行条件满足 -
executing:正在执行中 -
completed:执行完毕,结果已就绪 -
yielded:结果已经被外部消费
状态流转是单向的:queued → executing → completed → yielded。没有回头路。
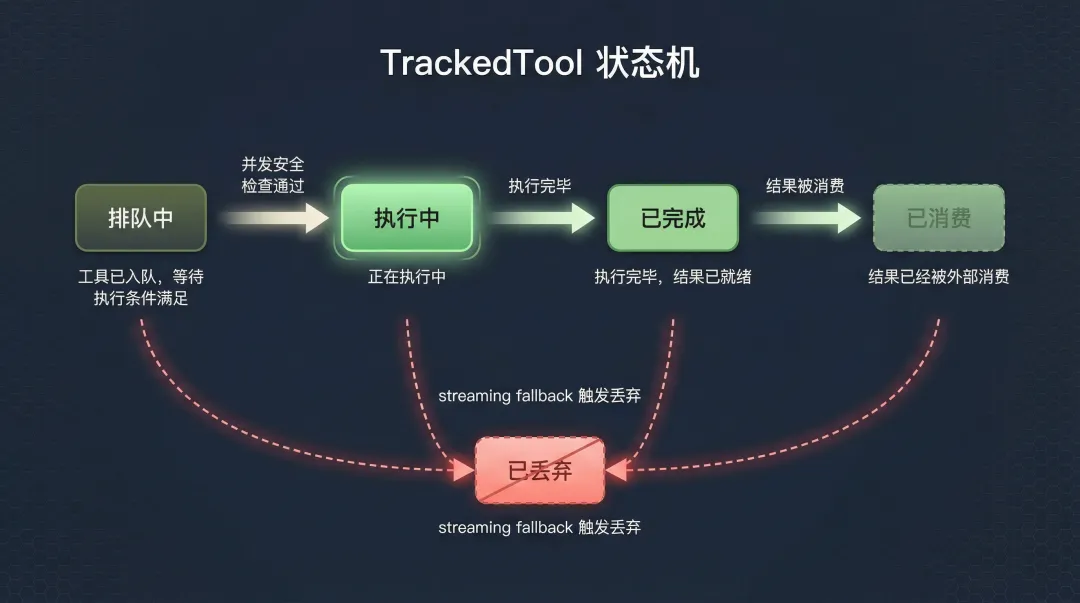
并发安全判断:谁能一起跑?
这是整个并发引擎的决策核心。每添加一个工具,执行器都要回答一个问题:这个工具能不能和当前正在跑的工具同时执行?
判断逻辑在 canExecuteTool 方法里:
private canExecuteTool(isConcurrencySafe: boolean): boolean {const executingTools = this.tools.filter(t => t.status === 'executing')return ( executingTools.length === 0 || (isConcurrencySafe && executingTools.every(t => t.isConcurrencySafe)) )}翻译成人话:要么当前没有工具在执行(随便跑),要么当前所有正在执行的工具都是并发安全的,而且新来的工具也是并发安全的(才能并行)。
只要有一个非并发安全的工具在跑,后面所有工具都得排队。
那”并发安全”又是怎么判断的?每个工具自己定义。看 Tool 接口的默认值:
const TOOL_DEFAULTS = { isEnabled: () =>true, isConcurrencySafe: (_input?: unknown) =>false, // 默认不安全! isReadOnly: (_input?: unknown) =>false, // 默认非只读!}注意这个默认值:所有工具默认都不是并发安全的。这意味着工具必须显式声明自己是安全的,才能参与并行执行。这是一个保守但正确的设计决策——宁可慢一点,也不要因为错误并发导致数据损坏。
在 Claude Code 中,Read、Glob、Grep 这类纯读取工具被标记为并发安全,可以一起跑。而 Edit、Write、Bash 这类有副作用的工具,默认不安全,必须独占执行。
Bash 错误的级联取消
这个设计细节让我觉得挺有意思。
当某个工具执行出错时,执行器并不会一视同仁地取消所有兄弟工具。它做了一个区分:只有 Bash 错误会触发级联取消。
// Only Bash errors cancel siblings. Bash commands often have implicit// dependency chains (e.g. mkdir fails → subsequent commands pointless).// Read/WebFetch/etc are independent — one failure shouldn't nuke the rest.if (tool.block.name === BASH_TOOL_NAME) {this.hasErrored = truethis.erroredToolDescription = this.getToolDescription(tool)this.siblingAbortController.abort('sibling_error')}源码注释说得很直白:Bash 命令之间往往有隐式依赖链。比如先 mkdir 再 cd 再 npm install,如果 mkdir 失败了,后面的命令跑下去也没意义。但 Read、WebFetch 这类工具彼此独立,一个文件读不出来不应该影响其他文件的读取。
这个设计背后是对真实使用模式的洞察。不是所有错误都该级联——只有那些隐含因果关系的操作链才需要。
进度消息:独立的快速通道
TrackedTool 里有个字段叫 pendingProgress,它和最终的执行结果 results 是分开存储的。
为什么要分开?因为进度消息不需要等工具执行完毕就能推送给 UI。一个 Bash 工具可能要跑 30 秒,但在这 30 秒里它会不断输出进度信息。如果进度消息和最终结果混在一起,用户就得等 30 秒才能看到任何输出——这体验太差了。
进度消息走的是独立通道,工具一产生就立刻通过 progressAvailableResolve 通知消费者。
Streaming Fallback:出错就丢掉一切
流式执行有一个固有的风险:模型在输出工具调用的过程中可能改变主意(streaming fallback)。比如输出了 3 个工具调用后,模型决定撤回,换成另一种方案。
这时候 discard() 方法就派上用场了:
discard(): void {this.discarded = true}简单粗暴——标记为已丢弃,所有已执行和正在执行的结果全部作废。getCompletedResults 和 getRemainingResults 在看到 discarded = true 后,直接跳过所有结果。
这个设计保证了 streaming fallback 不会产生幽灵结果:要么全部生效,要么全部丢弃,不存在中间状态。
3. 批处理编排:分区与调度
toolOrchestration 的核心是 partitionToolCalls 函数。它的工作是把一组工具调用分成若干批次,规则很直观:
连续的只读工具合并为一个批次(并发执行),写工具单独成批(串行执行)。
functionpartitionToolCalls(toolUseMessages, toolUseContext): Batch[] {return toolUseMessages.reduce((acc, toolUse) => {const isConcurrencySafe = /* 判断并发安全性 */if (isConcurrencySafe && acc[acc.length - 1]?.isConcurrencySafe) { acc[acc.length - 1]!.blocks.push(toolUse) // 合并到当前只读批次 } else { acc.push({ isConcurrencySafe, blocks: [toolUse] }) // 新批次 }return acc }, [])}举个例子。假设模型依次输出了:Read A、Read B、Grep C、Edit D、Read E、Write F。
分区结果是:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
注意 Read E 和前面的 Read A/B/Grep C 被分到了不同批次——因为中间夹了一个 Edit D,它打断了连续只读的链路。
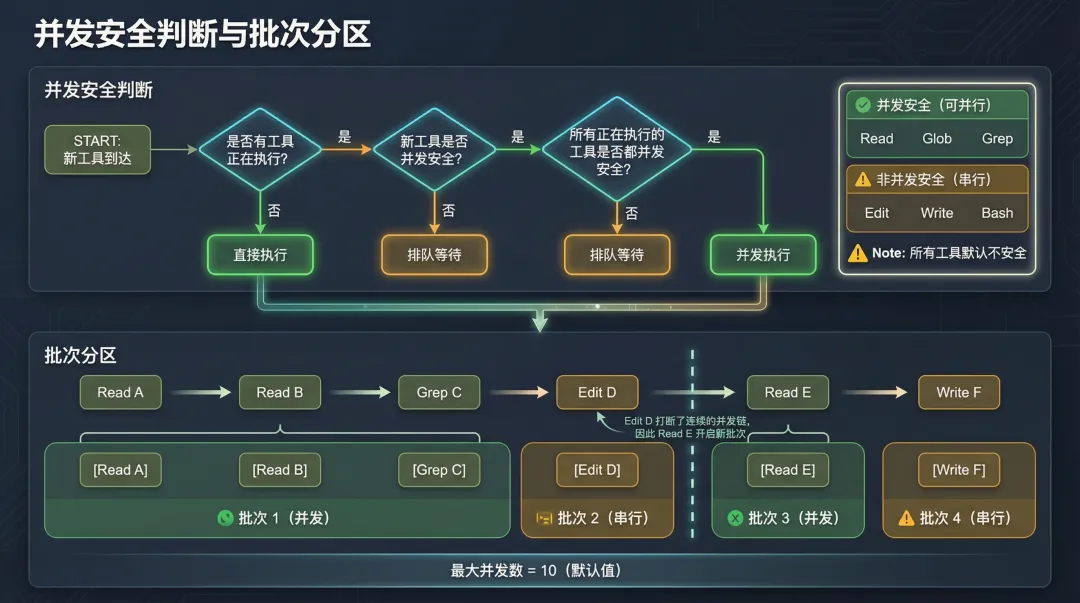
最大并发数
并发执行的上限由 getMaxToolUseConcurrency 控制:
functiongetMaxToolUseConcurrency(): number{returnparseInt( process.env.CLAUDE_CODE_MAX_TOOL_USE_CONCURRENCY || '', 10 ) || 10}默认 10。可以通过环境变量 CLAUDE_CODE_MAX_TOOL_USE_CONCURRENCY 调整。
runToolsConcurrently 使用这个值限制并发数:
asyncfunction* runToolsConcurrently(...) {yield* all( toolUseMessages.map(asyncfunction* (toolUse) { ... }), getMaxToolUseConcurrency(), // 默认 10 )}这里的 all 是一个并发控制原语,类似于 Promise.all 但带有并发上限。10 个 Read 工具同时跑,第 11 个就得等前面某个完成才能开始。
你在项目中用过类似的并发控制方案吗?比如用 p-limit 或者自己写一个信号量?评论区聊聊。
Context Modifier 的排队策略
批处理编排器还有一个流式执行器不具备的能力:Context Modifier 排队。
只读工具可能需要修改执行上下文(比如设置某个环境变量),但这些修改不能立即生效——否则会影响同一批次中其他正在并行执行的工具。解决方案是:只读工具的 context modifier 排队,等整个只读批次执行完毕后,统一应用。这样保证了同一批次内的工具互不干扰。
4. 三级中断:AbortController 的层次设计
中断控制是并发执行中最容易出问题的环节。Claude Code 用了一个三层 AbortController 结构来处理不同级别的中断需求。
parent AbortController (toolUseContext.abortController) └── siblingAbortController (Bash 错误级联) └── per-tool AbortController (每个工具独立)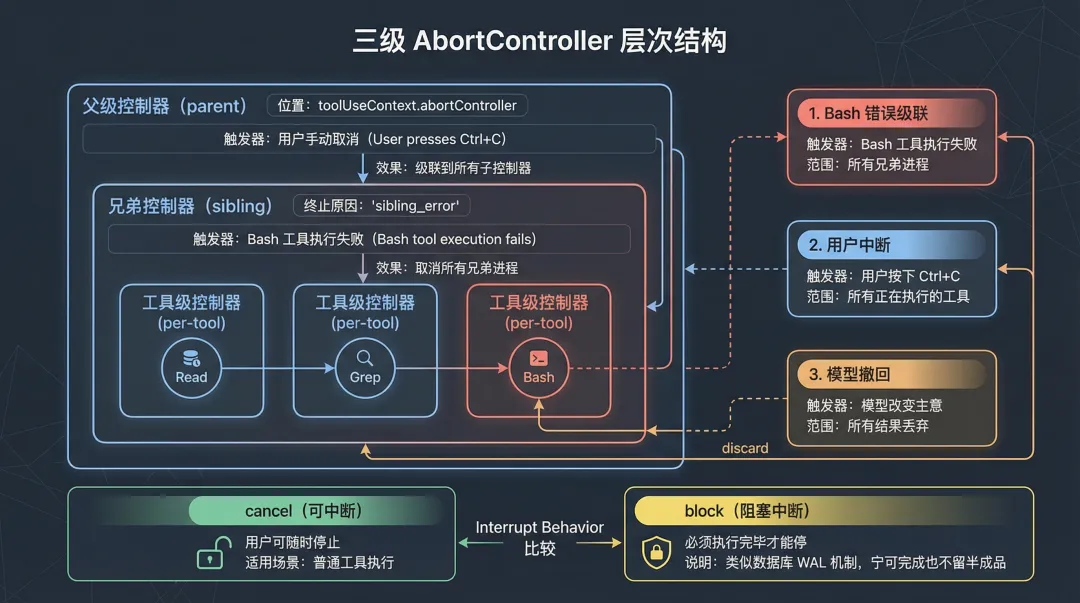
三种中断原因
|
|
|
|
|---|---|---|
sibling_error |
|
|
user_interrupted |
|
|
streaming_fallback |
|
|
sibling_error 只在 Bash 工具失败时触发,前文已经分析过。user_interrupted 是用户主动取消(比如按 Ctrl+C),会从 parent 层级联到所有子控制器。streaming_fallback 则是模型层面的撤回,直接丢弃所有结果。
interruptBehavior:cancel 还是 block
每个工具还可以定义自己的中断行为:
interruptBehavior?(): 'cancel' | 'block'-
cancel:可中断。用户可以随时停止这个工具。 -
block:阻塞中断。即使外部发出中断信号,这个工具也要执行完毕才能停。
什么工具需要 block 行为?通常是那些中断后会导致数据不一致的操作——比如正在写入一个文件,写到一半被中断,文件就坏了。与其留下一个损坏的文件,不如让它写完再停。
这种设计在工程实践中挺常见的。数据库的 WAL(Write-Ahead Log)也是类似的思路:宁可多写一条日志,也不要留下一个半完成的操作。
5. 结果收集:保序与实时性的平衡
并发执行带来的一个经典问题是:工具完成的顺序和调用的顺序不一样,怎么保证结果有序输出?
比如模型先调用了 Read A,再调用 Read B。由于并发执行,Read B 可能比 Read A 先完成。但用户看到的工具结果必须是 Read A 在前、Read B 在后。
非阻塞式收集:getCompletedResults
getCompletedResults 用 Generator 实现了非阻塞式结果收集:
*getCompletedResults(): Generator<MessageUpdate, void> { ... }它按照工具的调用顺序(而不是完成顺序)遍历结果。如果排在前面的工具还没完成,就跳过;如果已完成,就 yield 它的结果。这样保证了输出的有序性,同时不会因为等待某个慢工具而阻塞后续已完成工具的结果输出。
阻塞式等待:getRemainingResults
当所有工具都添加完毕(streaming 结束),执行器会调用 getRemainingResults 来等待剩余结果:
async *getRemainingResults(): AsyncGenerator<MessageUpdate, void> {// Promise.race: 工具完成 vs 进度消息awaitPromise.race([...executingPromises, progressPromise])}这里用 Promise.race 在两个事件之间做选择:要么某个工具完成了,要么有新的进度消息可用。哪个先到就处理哪个。
这种设计保证了 UI 的实时性——即使所有工具都没完成,只要有进度消息,用户就能看到反馈。如果用 Promise.all 替代 Promise.race,就得等所有工具都跑完才能看到任何输出,体验会差很多。
yield 优先级
结果输出遵循一个清晰的优先级:进度消息优先,完整结果按调用顺序 yield。
这意味着用户看到的信息流是这样的:
-
工具 A 开始执行(进度消息) -
工具 B 开始执行(进度消息) -
工具 A 完成,结果输出(完整结果) -
工具 B 完成,结果输出(完整结果)
即使 B 比 A 先完成,A 的完整结果也会排在 B 前面。但进度消息不受这个约束——谁先产生就先输出。
总结
拆完这套并发引擎,我总结了三个核心设计决策:
读写分离是基础。所有工具默认不安全,必须显式声明 isConcurrencySafe 才能参与并发。这个保守策略牺牲了一点性能,但换来了正确性。在实际的 Agent 系统里,正确性比速度重要得多——你可以容忍慢一点,但不能容忍文件被写坏。
Bash 级联取消是关键洞察。不是所有错误都应该级联,但 Bash 命令之间的隐式依赖链确实存在。这个设计说明 Claude Code 团队对真实使用模式做过深入分析,而不是简单地把所有工具一视同仁。
保序输出是用户体验的底线。并发执行带来的结果乱序问题,通过 Generator 的惰性求值特性优雅地解决了。进度消息走独立通道,保证了 UI 的实时反馈。
从这套设计中能看到一个趋势:AI Agent 的工具并发不是简单的 Promise.all,而是一套精细的调度系统。随着 Agent 能力的增强(调用更多工具、处理更复杂的任务),工具并发控制会成为 Agent 框架的核心竞争力。
如果你也在做 Agent 相关的开发,建议关注这几个设计点:并发安全标记的粒度(按工具类型还是按输入内容)、错误级联的范围(全部还是选择性)、结果保序的策略(阻塞还是惰性)。这些决策会直接影响系统的可靠性和用户体验。
关于 AI Agent 的工具并发,你最想了解的是什么?留言告诉我。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
扫码关注,获取更多 AI 工具的实战经验和最佳实践。不错过每一篇干货!
