 夜雨聆风
夜雨聆风





Claude Code 50 万行源码泄露后,我越来越确信:AI 编程真正值钱的,不是模型,而是编排系统
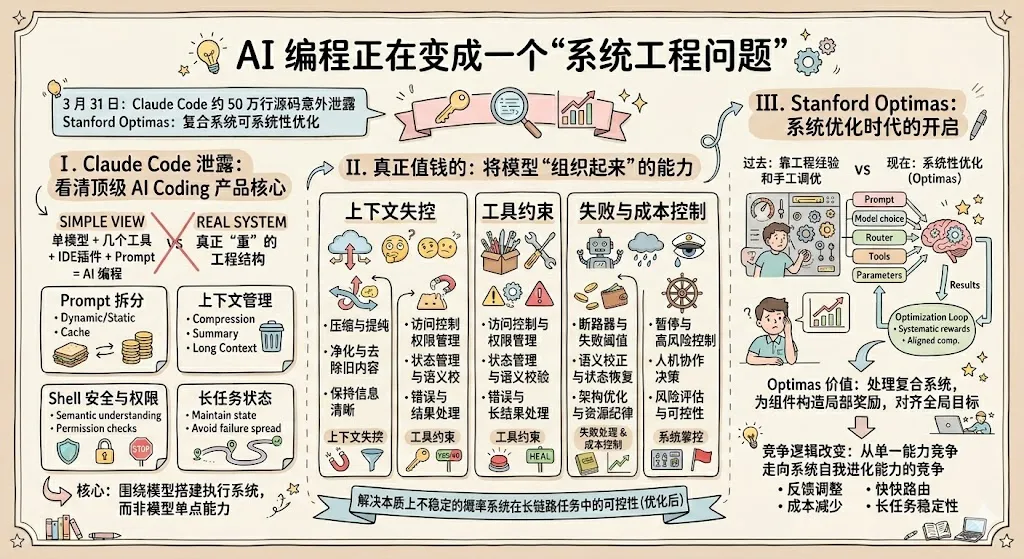
3 月 31 日,Claude Code 约 50 万行源码意外泄露。
这件事之所以能在 AI 圈瞬间炸开,不只是因为 Anthropic 出了事故,也不只是因为大家第一次有机会围观一个顶级 AI Coding 产品的内部实现。真正让人兴奋的,是它把一个过去只能靠猜的问题,突然摊到了台面上:一个年化收入已经超过 25 亿美元的 AI 编程产品,到底是怎么被做出来的?
几乎同一时间,Stanford 的 Optimas 又把另一只靴子落了下来。它证明了一件更重要的事:像 AI Coding 这种由模型、Prompt、工具、路由、参数和工作流共同组成的复合系统,不只是可以被人工设计,还可以被系统性优化。
把这两个事件放在一起看,我的感觉很强烈:AI 编程行业正在换赛道。
过去大家比的是谁的模型更强。
现在真正拉开差距的,越来越是另一种能力:
-
谁更会组织模型
-
谁更会管理上下文
-
谁更会处理失败
-
谁更会约束工具
-
谁更会控制成本
-
谁能让整套系统持续变好
换句话说,AI 编程开始从“拼模型”,走向“拼编排系统”。
而这次 Claude Code 泄露,第一次让全行业看到了这种变化已经发生到什么程度。
一、Claude Code 泄露后,行业第一次看清:顶级 AI Coding 产品的核心,根本不只是写代码
很多人一开始理解 AI 编程工具,脑子里其实是一个很简单的结构:
一个强模型。
几个工具。
一个 IDE 插件。
再加一些 Prompt。
看起来差不多就够了。
但只要你认真看一眼这次泄露后外界总结出来的那些细节,就会发现,真实系统完全不是这么回事。
大家真正看到的,不是某个神奇提示词,不是某个别人抄不走的单点技巧,而是一整套非常“重”的工程结构:
-
Prompt 怎么拆成静态区和动态区,尽量吃满缓存,降低成本
-
长上下文怎么压缩、怎么总结、怎么避免反复失败后无限重试
-
工具结果什么时候进上下文,什么时候落盘,再按需读取
-
Shell 怎么做安全校验,怎么处理权限,怎么理解不同命令的退出语义
-
系统如何在长任务里维持状态,不让一次错误扩散成整段任务失控
这些东西单独拿出来看,都不性感。
但真正做过产品的人会立刻知道,这些恰恰才是最贵的部分。
因为模型“会写代码”,只能证明它可能做出结果。
可一个产品能不能稳定完成复杂任务,能不能在企业环境里被信任,能不能在成本、风险和体验之间取得平衡,靠的从来都不是模型单点能力,而是模型外面那套把能力收束起来的系统。
如果要把这些能力统一看成一件事,其实可以这样理解:
编排系统,本质上在做三件事:
-
决定信息如何进入、停留、以及退出上下文
-
决定模型在什么条件下可以采取什么行动
-
决定系统如何根据结果不断调整自身行为
这也是我觉得这次泄露最值得重视的地方。
它让大家第一次不靠想象,而是靠真实代码,看到一件事:一个成熟的 AI Coding 产品,本质上不是一个会写代码的模型,而是一套围绕模型搭起来的执行系统。
二、真正值钱的,不是“模型更聪明”,而是“模型终于被组织起来了”
很多行业在早期都会有一个共同幻觉:只要核心技术足够强,产品问题自然会被带过去。
AI 编程过去两年也有点像这样。
大家首先追逐的是模型能力:更长上下文、更强推理、更好的代码生成、更少幻觉。
这些当然重要,但它们解决的主要是“脑子够不够好”。
而 Claude Code 这次真正暴露出来的,是另一个层面的问题:脑子够好了之后,系统到底怎么把它组织成一个能稳定交付结果的产品。
这里面至少有五个非常现实、也非常贵的问题。
1.上下文不是越长越好,而是越长越容易失控
很多外行对 AI Coding 的直觉是:上下文越长,系统越强。
但只要任务真的做深了,你很快就会发现问题根本不是“装不装得下”,而是“系统还能不能保持清醒”。
任务一长,信息就会开始变形:
-
早期目标被后续细节覆盖
-
已经失败过的尝试被误当成有效事实
-
工具输出太长,把真正重要的信号淹掉
-
局部上下文越来越多,全局意图越来越模糊
所以成熟系统做的,不是无限塞历史,而是不断做三件事:
-
压缩
-
提纯
-
把不该一直放在上下文里的内容移出去
这看起来像“小事”,但其实直接决定了一个 Agent 到底能不能跑长任务。
2.工具不是接上就行,而是必须被管住
很多人第一次做 Agent,最兴奋的部分就是接工具。
能读文件、能改代码、能跑测试、能调终端,好像一下子就进入“自动编程时代”了。
但工具一旦接入真实世界,问题就不再是“能不能用”,而是:
-
谁能调用
-
在什么状态下调用
-
调错了怎么办
-
结果太长怎么办
-
失败是正常失败,还是危险失败
-
某个命令的
exit code到底代表错误,还是只是“没搜到结果”
也就是说,工具不是能力展示台,而是风险和复杂度的入口。
你以为你给了模型一把螺丝刀,实际上你给它的是一个施工现场。
3.失败处理,才是产品成熟度最真实的地方
一个 Demo 最容易骗人的地方是:它只展示成功路径。
可真实系统一旦跑起来,失败根本不是例外,而是常态。
-
搜索没搜到
-
修改没通过测试
-
命令权限不够
-
压缩上下文失败
-
某一步输出太长
-
路由到了不合适的模型
这时候最能拉开差距的,不是“谁更少失败”,而是“谁失败后还不崩”。
Claude Code 泄露后,很多人最大的感受之一就是:它内部花了大量力气在处理那些你平时根本不会发朋友圈的东西。
比如断路器、失败阈值、权限门禁、语义校正、状态恢复。
这些都不是宣传页上的卖点。
但这些恰恰才决定了产品是不是能一直活着。
4.成本控制不是商业问题,而是系统设计问题
很多人谈 AI 成本,还是用一个过于粗糙的视角:模型贵,调用多,所以成本高。
但真正做产品的人会知道,成本很大程度上是系统问题。
如果你的 Prompt 每轮都在变,缓存命中率就上不去。
如果你的工具结果总是直接灌回上下文,token 很快就爆。
如果你的失败重试没有断路器,系统会无限烧钱。
如果你的路由策略混乱,你会把高成本模型浪费在不该浪费的地方。
所以顶级 AI Coding 产品真正擅长的,往往不是“少调用模型”,而是:把调用组织得足够有纪律。
成本优化不是财务动作,而是架构动作。
5.真正的产品,不只是让模型行动,而是让系统始终握着方向盘
模型当然可以做很多判断。
但一个成熟产品最关键的地方,是它不会把所有判断都交给模型。
什么时候继续。
什么时候暂停。
什么时候必须让人接管。
什么时候高风险动作不能再靠模型自己决定。
这部分往往不出现在外界对“大模型能力”的讨论里,但它实际上决定了系统是不是还可控。
你会发现,产品做到后面,真正重要的不是“模型能不能做”,而是:系统敢不敢让它继续做。
这五个问题看起来分散,但本质上在解决同一件事:如何让一个本质上不稳定的概率系统,在长链路任务中保持可控。
你会发现,一旦从这个角度看,这些问题就不再是零散的工程细节,而是同一个系统问题的不同侧面。
三、Stanford 论文真正重要的地方,不是又提了一个新方法,而是它把“系统优化”抬到了台前
如果说前面的问题还可以靠工程经验和人工调优去解决,那么一个更现实的问题是:当系统复杂到一定程度,人类其实已经调不动它了。
如果说 Claude Code 泄露让大家看到了顶级产品今天长什么样,Stanford 的 Optimas 真正推进的一步是:这整套东西,不只是可以被工程师手工调,还可以被系统性优化。
这句话看起来不算惊人,但其实很关键。
因为 AI Coding 产品本质上不是一个单模型问题,而是一个典型的复合系统问题。
它里面同时有很多层东西在互相影响:
-
Prompt 怎么写
-
不同任务走哪个模型
-
路由怎么分
-
工具怎么配
-
参数怎么设
-
哪些局部优化会真的提升全局结果
过去这些事,大部分靠人一点点调。
问题是,复合系统最麻烦的地方就在这里:
你调好了一个局部,经常会把另一个局部弄坏。
你以为某个 Prompt 变好了,结果全局成本上去了。
你以为某个路由更聪明了,结果整体稳定性下降了。
你以为某一步提速了,结果任务完成率掉了。
Optimas 的价值就在于,它在认真处理这个问题。
它不是只盯一个全局分数蛮力搜索,而是给系统里的不同组件构造和全局目标对齐的局部奖励,让每个组件可以各自优化,但又不至于把整体方向带偏。
这背后真正值得注意的,不只是平均 11.92% 的提升数字,而是一个更大的信号:AI 行业开始把“系统怎么优化系统”当成正式问题了。
这件事一旦成立,整个竞争逻辑都会变。
过去大家卷的是:
-
谁先接更多工具
-
谁先接入 IDE
-
谁上下文更长
-
谁模型更会写代码
接下来大家更可能卷的是:
-
谁的系统更会根据反馈自我调整
-
谁的路由更快进化
-
谁的成本曲线降得更快
-
谁的长任务稳定性提升得更快
-
谁能把新的模型和新的工具更快吸进系统并重新组织起来
也就是说,下一阶段的差距,不一定首先来自“谁的模型更强”,而更可能来自:谁更早拥有一个能持续优化自己的编排系统。
四、这两个事件放在一起,真正改写的是 AI 编程的护城河
如果只看表面,这两个事件一个是事故,一个是论文。
但放在一起,它们其实在共同改写一个行业共识:AI 编程产品真正的护城河,正在从模型护城河,转向系统护城河。
这个变化非常重要。
因为模型越来越像一种公共能力。当然,不同模型之间仍然有强弱差距。但在产品层面,越来越多团队都能接到不错的模型。
模型本身仍然重要,却越来越不像唯一壁垒。
真正拉开差距的,开始变成别的东西:
-
你如何管理上下文污染
-
你如何组织工具调用
-
你如何定义失败恢复
-
你如何控制权限边界
-
你如何做模型路由
-
你如何在成本、速度、成功率之间找到平衡
-
你如何把每次运行沉淀成下一轮优化的信号
这些能力的共同点是:
它们很少被写进宣传文案。
它们不如模型榜单耀眼。
它们很难被一句口号讲清楚。
但它们决定了产品最后到底是个 Demo,还是个业务。
这也是为什么我越来越觉得,接下来 AI Coding 最值得研究的问题,已经不是“哪个模型更聪明”,而是:哪个团队更会把模型组织成系统。
再往下一步,则是:哪个团队更会让这个系统自己持续变好。
五、对普通团队来说,这两个热点真正提醒的,是三件很现实的事
如果你不是 Anthropic,也不是 Stanford,这两个事件对你还有什么价值?
我觉得至少有三个判断值得尽快更新。
第一,不要再把 AI Coding 理解成“套一个强模型”
模型当然重要。
但只要任务真的复杂,系统迟早会暴露出更难的问题:
-
上下文怎么控
-
工具怎么管
-
失败怎么接
-
权限怎么收
-
成本怎么压
-
路由怎么调
如果这些问题没有答案,模型再强,也只会把失控放大得更快。
第二,别把那些“不性感的工程”当成后补项
很多团队喜欢先把能力做出来,再回头补安全、补记忆、补状态、补验证、补权限。
现实通常恰恰相反。
这些看起来最不性感的地方,往往最先决定产品有没有下限。
你以为后面再补的,常常才是系统最贵的部分。
第三,尽早把产品做成“可被优化的系统”
今天很多团队做 Agent,还是按“功能堆叠”的方式在做。
接一个模型,再加一个工具,再补一个工作流,再补一个规则。
这种方法短期当然能跑起来。
但一旦你想继续提升成功率、降低成本、缩短任务时长、提高长任务稳定性,你就会发现自己没有抓手。
所以真正重要的不是“先把功能叠满”,而是早点把系统做成一个可观测、可调优、可反馈闭环的对象。
因为未来真正拉开差距的,很可能不是谁的功能更多,而是谁的系统学得更快。
最后
Claude Code 50 万行源码泄露,让全行业第一次看到了顶级 AI Coding 产品内部最重的部分,原来不是“生成”,而是“管理生成”。
Stanford 的 Optimas 又进一步说明,这种管理不只靠经验,不只靠人工微调,它本身也正在成为 AI 的优化对象。
这两个事件放在一起,给了我一个越来越清楚的判断:
AI 编程真正值钱的,不再只是模型会不会写代码,而是整套系统会不会管理代码、管理上下文、管理工具、管理失败、管理成本,并且让自己持续变强。
过去很多人以为,AI Coding 拼的是谁更像一个厉害的程序员。
现在越来越像在拼:谁更像一个成熟的软件系统。
如果再往上抽象一层,这个变化其实可以这样理解:AI 产品正在从“能力竞争”,走向“系统工程竞争”。
如果一定要给这套东西起个名字,很多人会把它叫做工作流、Agent 架构、执行引擎,或者别的什么。名字不重要。真正重要的是,你已经很难再把它理解成“一个模型加几个工具”。
模型决定系统的上限。编排系统决定产品的下限。而能不能持续优化这套编排系统,决定的是这家公司最后能不能把 AI 能力滚成真正的复利。