 夜雨聆风
夜雨聆风





你每天都在用的AI工具,看似在处理文字,其实它只是在处理Token
很多人每天都在用 AI。
写方案,用它。做总结,用它。改文案,用它。写代码,用它。
但如果你问一句:
“Token 到底是什么?”
大多数人其实答不上来。
有人觉得,Token 就是“一个字”。有人以为,Token 就是“一个词”。还有人把它理解成“AI 平台的一种收费单位”。
这些理解都不算完全错。但都没说到最关键的地方。
真正的问题不是 Token 是什么黑话,真正的问题是:为什么它能决定 AI 的成本、速度、上下文上限,甚至影响不同语言的使用体验?
今天这篇文章,就把 Token 一次讲透。

先说结论:
Token,不是字数,不是词数,也不是句子数。它是AI工具处理语言时使用的“内部基本单位”。
看懂这句话,你就会突然理解很多事:
为什么 AI 要按 Token 收费?为什么对话越长越贵?为什么会有 8K、32K、128K 上下文?为什么同样一段内容,换一种语言,成本可能就不一样?
(让我们一点一点的解释这些问题,预计十分钟,出发~)
一、你看到的是文字,模型看到的是 Token
人看一句话,看到的是“意思”。
比如这句:
今天天气真不错。
我们不会真的把它拆成“今 / 天 / 天 / 气 / 真 / 不 / 错”再去理解。我们会自然抓住“今天”“天气”“不错”这些更有意义的整体。
人脑会本能地追求高效。而大模型也是一样。模型并不是直接“读懂”整句话。在真正开始计算之前,它会先把语言拆成一个个更小的单位,再交给系统处理。
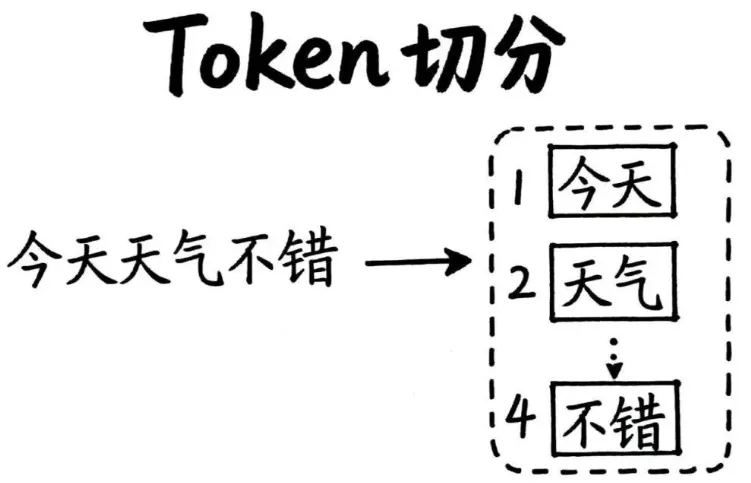
这些单位,就是 Token。
也就是说:用户看到的是文字,模型处理的是 Token 序列。
二、Token 到底是什么?它根本不是你想象中的“字数统计”
很多人第一次听到 Token,会下意识认为:
“是不是一个字等于一个 Token?”
不一定。
因为 Token 可能是:
一个汉字,一个标点,一个完整英文单词,一个高频短语,甚至可能只是半个英文单词。
换句话说,Token 并不是按“我们读起来最自然”的方式切分的,它是按“模型算起来更高效”的方式切分的。
这点非常重要。
所以更准确的说法是:Token,就是语言进入模型之前,被重新打包后的最小处理单元。
三、到底是谁在切 Token?答案是分词器
在大模型真正开始工作之前,通常有一个很关键、但经常被忽略的角色:
分词器(Tokenizer)。
它的作用,可以简单理解成三步:
1)先看海量文本
分词器会从大量语料中学习,观察哪些字、词、片段经常一起出现。
2)再建立一张“词表”
把那些高频、稳定的组合整理成 Token,并给每个 Token 一个编号。
3)最后把语言变成编号
用户输入一句话后,系统先把它切成 Token,再把 Token 转成数字,交给模型去处理。
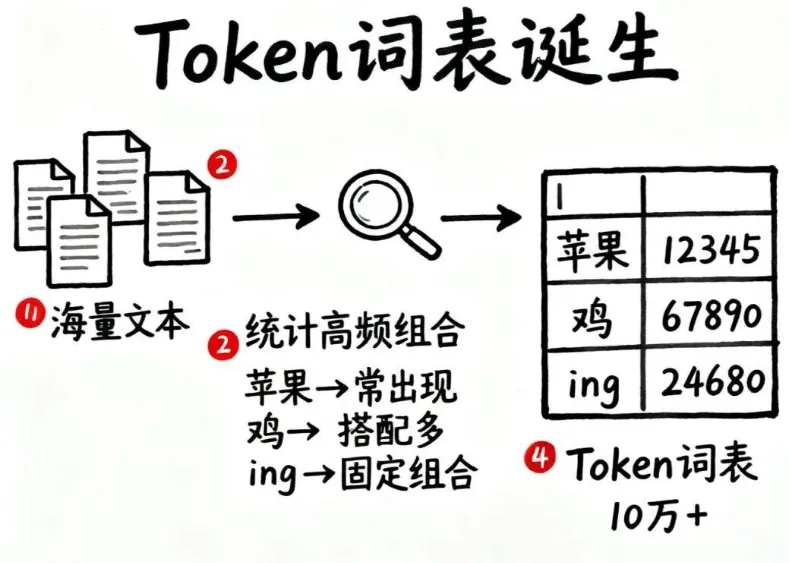
所以,模型真正面对的,根本不是你写下来的那段原文。而是一串被拆分、被编号、被编码后的序列。这也是很多人第一次理解大模型原理时最容易“豁然开朗”的地方:
原来模型处理的不是语言本身,而是语言被编码之后的结构。
四、为什么 Token 的切法并不统一?
这里有个特别容易被误解的点:
Token 没有统一标准。
同样一段内容,在不同模型里,Token 数量可能不一样。原因也很简单:
不同模型,可能用的是不同分词器;不同词表,收录的高频组合不一样;不同训练语料,也会导致它们对语言的“拆法”不同。
这意味着:
你以为只是短短一句话,在不同模型眼里,可能根本不是同一种“长度”。
我们可以用OpenAI提供的Tokenizer 工具(tiktokenizer)来实测一下:
案例1:笑声的Token
●「哈哈」→ 1个Token
●「哈哈哈」→ 1个Token
●「哈哈哈哈」→ 1个Token
●「哈哈哈哈哈」→ 2个Token
说明什么? 大家平时最多笑4声,第5个「哈」超出了训练数据的高频范围。
案例2:词语的Token
在DeepSeek中:
●「鸡蛋」→ 1个Token
●「鸭蛋」→ 2个Token(鸭+蛋)
●「关羽」→ 1个Token
●「张飞」→ 2个Token(张+飞)
●「孙悟空」→ 1个Token
●「沙悟净」→ 3个Token(沙+悟+净)
这说明:训练数据中,“鸡蛋”出现频率远高于”鸭蛋”,”关羽”和”孙悟空”作为高频词被打包,而”沙悟净”关注度相对低。
也就是说,Token 不是天然固定的。它更像是每个模型根据自己的训练方式,自定义出来的一套内部记账规则。
所以以后你看到有人说:“这段内容才几百字,怎么会这么费 Token?”
你就会明白——
因为字数是给人看的,Token 才是给模型算的。
五、为什么所有 AI 都喜欢按 Token 收费?
很多人第一次看到大模型价格表时都会困惑:
为什么不按次收费?为什么不按篇收费?为什么非得按 Token 收费?
答案其实很现实:
因为 Token 数量,最接近模型的真实计算成本。
大模型工作的本质,是根据已有内容,持续预测“下一个 Token”是什么。
这就意味着:
-
你输入越多,模型处理的 Token 越多 -
它输出越多,生成的 Token 也越多 -
输入加输出越长,消耗的计算资源通常就越大
所以,平台按 Token 收费,并不是为了把问题说复杂。而是因为这确实比“按次数”更接近真实成本。一次请求很短,和一次请求几万字,表面上都是“调用一次”,但它们背后的资源消耗,完全不是一个量级。
这就是为什么:
Token 不只是技术单位,它其实还是 AI 世界里的成本单位。
六、为什么对话越聊越久,费用也越涨越快?
很多人都有过这种体验:刚开始和 AI 聊几轮,感觉没什么。聊到后面,突然发现速度变慢了、费用变高了、上下文也快装不下了。
这背后,核心原因还是 Token。
因为大多数对话型模型并不是“只看你刚发的这一句”。它通常还要把前面的对话历史一起带进上下文里,才能保持连贯。于是会发生什么?
你每多聊一轮,上下文里参与计算的 Token 就会继续累积。
也就是说,后面一轮的成本,往往不仅是“这一轮的话”,还包括“前面所有还被带着一起算的内容”。
这就是为什么长对话总会越来越贵。
不是平台故意这样设计,而是模型机制本来如此。
七、为什么会有 8K、32K、128K 上下文?
很多人第一次看到“128K 上下文”时,根本没概念。
其实这句话翻译成人话就是:这个模型一次最多能处理 128K 个 Token。
所谓上下文窗口,本质上就是模型这次能装下多少 Token。
这个窗口里,不只包括你刚输入的问题,还包括系统提示词、历史对话、参考资料,以及模型正在生成的内容。
所以你可以把上下文窗口想象成一个有限容量的行李箱,你往里面塞的东西越多,后面还能装的新内容就越少。
这也解释了为什么有时候你会感觉模型“忘了前面说过的话”,不是它突然失忆了,而是前面的内容可能已经被挤出上下文窗口了。
说到底,所谓上下文长度,看的从来都不是字数,而是 Token 总量。
八、同样一段内容,中文和英文为什么可能消耗不一样?
这点特别值得普通用户注意。
很多人会默认觉得:“差不多长度的内容,成本也应该差不多吧?”
其实未必。
因为不同语言的结构不同,书写方式不同,分词方式也不同。于是同样表达一个意思,最后拆出来的 Token 数量可能会有明显差异。
这意味着什么?意味着你看到的是“差不多长”;模型看到的,可能却是“差很多”。
也正因为这样,Token 机制会直接影响不同语言的真实使用体验:
-
有些语言更省上下文 -
有些语言更费 Token -
有些表达方式更紧凑 -
有些表达方式更分散
九、Token 很重要,但它并不完美
讲到这里,也要提醒一句:
Token 很关键,但它绝对不是完美机制。
它至少有两个天然局限。
第一,Token 不一定公平
不同语言、不同表达方式,可能面对不同的 Token 消耗成本。
第二,Token 不等于理解
分词器再聪明,也只是更高效地把内容拆开。它会打包高频组合,但这不代表它真的理解了这些词背后的含义。
所以,Token 更像是模型理解语言的入口,而不是语言理解本身的终点。
最后一句话,彻底说清 Token
如果一定要用一句最通俗的话来解释 Token,我会这样说:
Token,就是大模型为了处理语言,自定义出来的一种“内部计量单位”。
它决定了模型怎么读,决定了模型一次能装多少内容,决定了模型生成回答要花多少资源,也决定了你为什么会在价格表、上下文和 API 文档里反复看到它。
所以,Token 根本不是什么离普通人很远的技术黑话。
恰恰相反——
它是每一个 AI 用户都应该尽早搞懂的底层常识。
因为从你第一次打开 ChatGPT、Claude、Kimi、豆包,或者任何一个大模型产品开始,你其实就已经在和 Token 打交道了。
只是以前你不知道而已。
你第一次真正意识到 Token 很重要,是在哪个瞬间?
是看到 API 价格表的时候?是发现长对话越来越贵的时候?还是第一次听到“128K 上下文”,却完全不知道那是什么意思的时候?
欢迎留言聊聊:
你最早是在哪一刻,意识到 Token 原来这么关键?
如果你身边也有人总在问:
“AI 为什么这么贵?”“上下文到底是什么?”“Token 不就是字数吗?”
把这篇转给他,应该就够了。