 夜雨聆风
夜雨聆风





Claude Code 长记忆插件 claude-mem 教程:为什么你越用 AI,越需要它
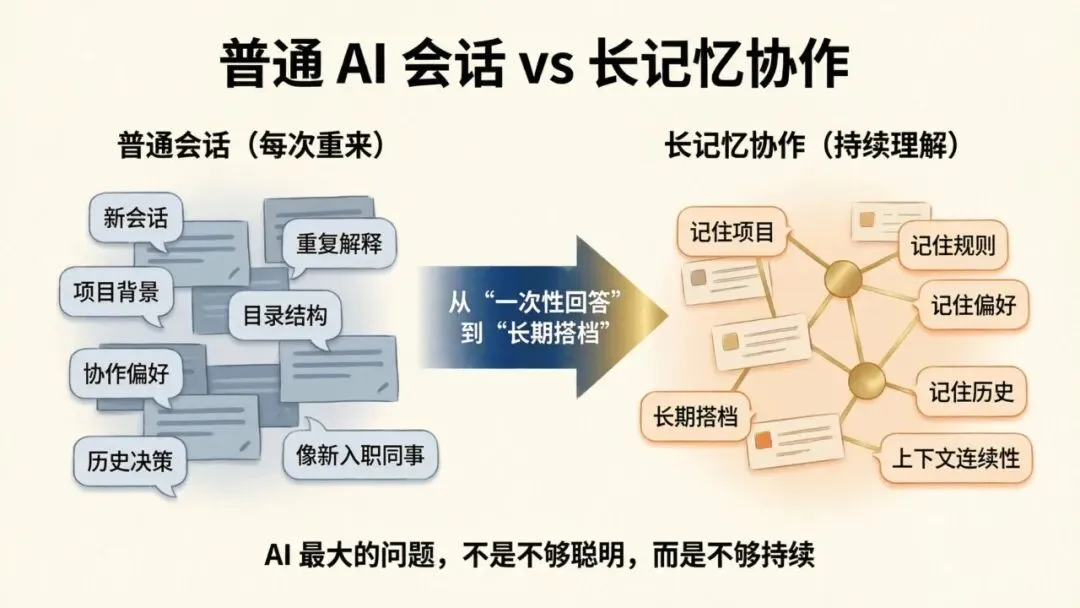
如果你已经是 Claude Code 的重度用户,你大概率有过这种烦躁时刻:
昨天你刚花半小时,把项目背景、目录结构、协作偏好、代码禁忌,一条条讲给 Claude。
今天新开一个会话,它又像一个“很聪明、但刚入职”的新人,重新问你:
-
• 这个项目是做什么的? -
• 你希望我怎么改代码? -
• 之前为什么不用那个方案? -
• 你到底喜欢什么风格?
那一瞬间你会特别清楚地意识到一件事:
AI 最大的问题,不是它不够聪明,而是它不够“持续”。
它这一轮很强,下一轮却可能像失忆。
而 claude-mem,本质上就是来解决这件事的。
它不是一个“帮你多记几条聊天记录”的小插件。它真正厉害的地方是:
它在给 Claude Code 补一层长期记忆。
让它不只是“这次会答”,而是慢慢变成一个:
-
• 记得你项目背景的搭档 -
• 记得你协作习惯的搭档 -
• 记得你历史决策的搭档 -
• 甚至能围绕一个主题,持续越用越懂你的搭档
这篇文章,我不打算写成那种“功能清单 + 参数解释”的说明书。
我会直接用最实战的方式,帮你搞清楚 5 件事:
-
1. claude-mem到底是什么 -
2. 为什么它对 Claude Code 用户越来越重要 -
3. 它最值得用的能力到底是哪几个 -
4. 怎么判断你已经真的装好并能用了 -
5. 新手怎么最快跑通第一套工作流
如果你只想先看一句结论,那就是:
如果你只是偶尔用一下 Claude Code,它不是刚需。但如果你已经开始把 Claude 当长期搭档,那它几乎早晚会变成刚需。
一、先说人话:claude-mem 到底是什么?
一句话版本:
claude-mem 是给 Claude Code 增加“长记忆”和“知识沉淀”能力的插件。
你可以把它理解成:
Claude 原本已经很聪明,但它更擅长“当前这场对话”。而 claude-mem 做的,是把你们之前合作过程中真正有价值的东西,沉淀成一个可以长期复用的记忆层。
注意,这里关键不是“聊天记录存档”。
真正有价值的是这些东西:
-
• 你们之前做过什么决策 -
• 你纠正过 Claude 哪些协作习惯 -
• 某个项目里有哪些重要背景 -
• 某个 bug 是怎么定位出来的 -
• 某条产品线、某类文章、某套工作流,过去积累了什么经验
这些信息如果只是散落在聊天窗口里,几天后就跟没有差不多。
但如果它们能被结构化沉淀、检索、串联、复用,那意义就完全变了。
你会发现,claude-mem 真正补上的不是“记忆功能”,而是:
让你和 Claude 的每一次合作,不再只服务于当下,而开始服务于未来。
这就很关键了。
因为很多人以为自己在“训练 AI”,实际上只是一次次临时喂上下文。
而 claude-mem 的价值在于:
你今天花的时间,不会明天白费。
二、为什么它会越来越重要?因为 Claude Code 用户正在掉进同一个坑
如果你只是偶尔让 Claude Code 帮你写个函数、解释个报错,说实话,claude-mem 不一定让你第一天就感觉“哇,神器”。
但如果你已经进入下面这种使用阶段,你一定会越来越痛:
-
• 让 Claude 长期参与一个项目 -
• 让它持续帮你写代码、改配置、读文档、排查问题 -
• 让它逐渐学习你的协作偏好 -
• 让它同时参与代码、内容、知识管理这些长期任务
一旦进入这个阶段,你遇到的痛点会非常集中。
1. 同样的话,你要说很多遍
这是最典型的。
比如你一次次重复这些内容:
-
• 这个仓库主要做什么 -
• 哪些目录不要乱改 -
• 你不喜欢“顺手优化一堆无关代码” -
• 你写作时更像公众号,不像论文 -
• 你希望它先读文件再动手
你第一次说,还觉得正常。你说到第十次,就会开始怀疑人生。
2. 你明明教过它,但它不稳定记得
这是最让人火大的地方。
你明明已经纠正过它:
-
• 请用简体中文 -
• 不要过度重构 -
• 回答简洁一点 -
• 做事先查现有代码,不要凭空脑补
结果新会话一开,它又像回到出厂设置。
这不是 Claude 不聪明。而是你们之间的长期协作知识,没有被真正接住。
3. 项目越复杂,历史决策越容易丢
这是开发者最容易低估的一点。
真正难的,从来不是“写一段代码”,而是你得知道:
-
• 为什么上次不用那个方案 -
• 为什么那次重构做到一半停了 -
• 某个 bug 之前是不是已经踩过 -
• 哪些限制是业务原因,不是技术原因 -
• 某个协作规则是因为之前吃过亏,不是拍脑袋定的
这些东西,一旦丢了,Claude 每次都会看起来“能力在线,但理解半截”。
4. 你越重度使用 AI,越会发现:真正稀缺的是上下文连续性
很多人一开始比模型。比谁更强、谁更快、谁更会写。
但当你真的把 AI 用进日常工作后,你会发现一个更底层的问题:
不是谁会答,而是谁能承接历史。
这就是 claude-mem 重要的原因。
它解决的不是“回答质量再高 5%”这种锦上添花,而是:
让 Claude 从一个“每次重新认识你的人”,慢慢变成“越来越懂你的人”。
三、别急着神化它:claude-mem 最适合哪些人?
我不想把这篇文章写成“所有人都必须装”的样子。
因为不是。
最适合的人,其实就三类
第一类:高频使用 Claude Code 的开发者
如果你几乎每天都在用 Claude 看代码、改代码、查问题、做项目协作,那它很适合你。
第二类:把 Claude 当长期搭档的人
你不只是临时问问题,而是希望 Claude 越来越理解你的项目、流程、偏好、目标。
这时“长记忆”不是加分项,是底层能力。
第三类:同时做代码、内容、知识沉淀的人
比如独立开发者、技术作者、AI 工作流重度用户,会非常明显感受到它的价值。
因为你会反复在这些事情之间切换:
-
• 项目背景 -
• 个人偏好 -
• 内容风格 -
• 历史决策 -
• 主题知识积累
这些如果全靠你手动重复,太累了。
不一定刚需的人,也有
第一类:低频用户
一周用几次,每次都完全是新任务,那收益会小很多。
第二类:只做短平快问答的人
比如只问一条命令、一个报错、一个语法,那普通会话通常够了。
所以我更愿意把 claude-mem 定义成:
不是人人必须装,而是你一旦进入长期协作阶段,迟早会需要的那层基础设施。
四、它到底强在哪?别看名字,真正值钱的是这几类能力
很多人一看到“长记忆”,脑子里第一反应是:“哦,就是 AI 帮我记住以前聊过什么。”
如果你只这么理解,就低估它了。
claude-mem 真正值钱的,是它把“过去发生过的事”变成了“以后还用得上的知识”。
下面是最值得你理解的三类能力。
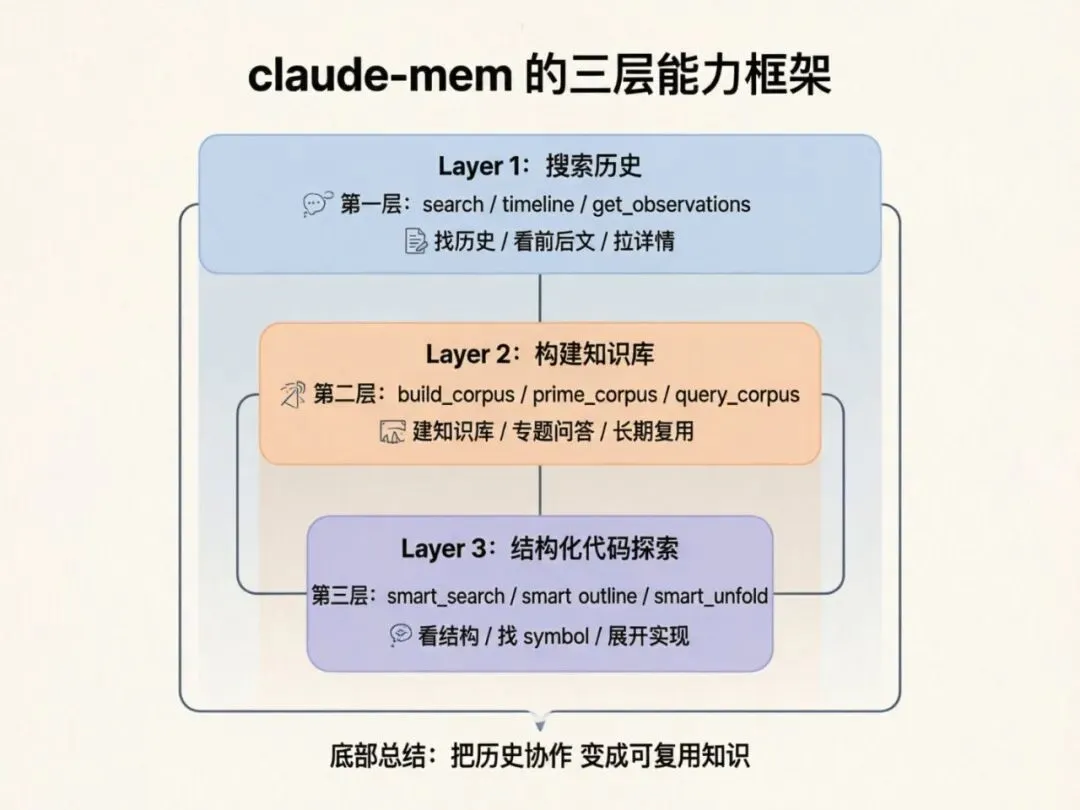
1. 搜历史:search / timeline / get_observations
这组能力看起来普通,其实是最好用、也最容易马上见效的一组。
你可以把它理解成一套三段式动作:
第一步:search
先查索引,找到和某个主题相关的 observation。
比如你可以让 Claude 找:
-
• 这个项目之前跟发布相关的记录 -
• 某个模块历史上讨论过哪些方案 -
• 之前关于某类 bug 的观察记录
第二步:timeline
围绕一条 observation,往前后看上下文。
这个特别关键。
因为真正有价值的信息,往往不是那一条记录本身,而是它前后串起来的过程:
-
• 之前发生了什么 -
• 这条记录为什么会出现 -
• 后来又引发了什么决定
这就不再是“看一条笔记”,而是“看一个过程”。
第三步:get_observations
把你真正需要的 observation 详情拉出来。
这一整套非常像一个会查资料的老手:
不是一上来把所有细节铺满屏幕,而是先搜、再定位、再深挖。
这件事的意义很简单:它让 Claude 不只是会答,还会查你们自己的历史。
这一点,一旦你习惯了,就会很难回去。
2. 建知识库:build_corpus / prime_corpus / query_corpus
这部分是很多人第一次用时最容易低估、但越用越觉得厉害的能力。
因为它已经不只是“记忆检索”了。
它是在把零散的 observation,进一步升级成一个可以持续问答的专题知识库。
什么意思?
比如你最近连续在做下面这些事:
-
• 某个项目的重构 -
• 某个产品功能线的推进 -
• 某类 bug 的长期排查 -
• 某个内容主题的持续积累
这些记录原本是散的。但你可以把它们筛出来,构建成一个 corpus。
然后:
-
1. build_corpus:建库 -
2. prime_corpus:载入这个知识库 -
3. query_corpus:围绕这个专题持续提问
这时候 Claude 的感觉就不一样了。
它不是“从一堆记忆里随便翻一翻”,而是开始像真的带着一个专题脑袋在回答你。
这尤其适合那种会持续 1 周、2 周、1 个月的工作。
说白了:
你不是在让 Claude 记住一点东西,而是在给它建一块长期作战的阵地。
3. 结构化看代码:smart_search / smart_outline / smart_unfold
这部分对开发者尤其友好。
因为很多时候,你根本不是想全文搜索。你只是想快速知道:
-
• 这个函数在哪 -
• 这个类怎么组织的 -
• 这个文件的大致结构是什么 -
• 某个 symbol 的完整实现长什么样
这时 claude-mem 提供的不是简单 grep,而是更结构化的能力。
smart_search
搜索函数、类、symbol、文件名。
smart_outline
先看文件骨架,不急着看全文。
smart_unfold
只展开你关心的那一个 symbol。
如果你在大项目里工作过,就知道这有多重要。
很多人最浪费上下文和时间的地方,就是:
一上来就把超长文件整段塞给 Claude。
这样做不是不行,但很笨。
更好的方式是:
-
1. 先 outline 看结构 -
2. 再 search 找目标 -
3. 再 unfold 看关键实现
这会让 Claude 看代码更像一个经验工程师,而不是一个“什么都先吞进去再说”的模型。
五、怎么安装 claude-mem?别把注意力放错地方
讲安装,我想先提醒一句:
很多人太执着“我是不是装了某个包”,却忽略了最重要的问题——能力到底通没通。
从实际形态看,claude-mem 更像是接到 Claude Code 里的一个能力层,常见会通过技能系统、MCP server 或类似方式暴露给 Claude 使用。
所以你真正该确认的,不是“文件在不在”,而是这几件事:
-
1. Claude Code 能不能看到相关工具 -
2. 工具能不能成功调用 -
3. observation 能不能被搜索和回溯 -
4. corpus 能不能建起来并被查询
如果这些通了,才算真的装好了。
一个最简单的判断方式
如果你在 Claude Code 的工具/技能体系里,已经能看到类似这些名字:
-
• claude-mem:mem-search -
• claude-mem:make-plan -
• claude-mem:smart-explore -
• claude-mem:knowledge-agent
或者更底层一点的:
-
• search -
• timeline -
• get_observations -
• build_corpus -
• query_corpus -
• smart_search -
• smart_outline -
• smart_unfold
那说明它大概率已经接入了。
安装这件事最容易犯的错,就是只看“配没配”,不看“能不能跑”。
而 claude-mem 这种工具,最重要的是:
跑通一条完整链路,比看一百行安装说明都有用。
六、装完以后,怎么判断它不是“假装可用”?
这是最现实的问题。
很多插件的问题不是装不上,而是:“看起来在,但我不知道到底有没有生效。”
你可以用下面这套最实用的验证方法。
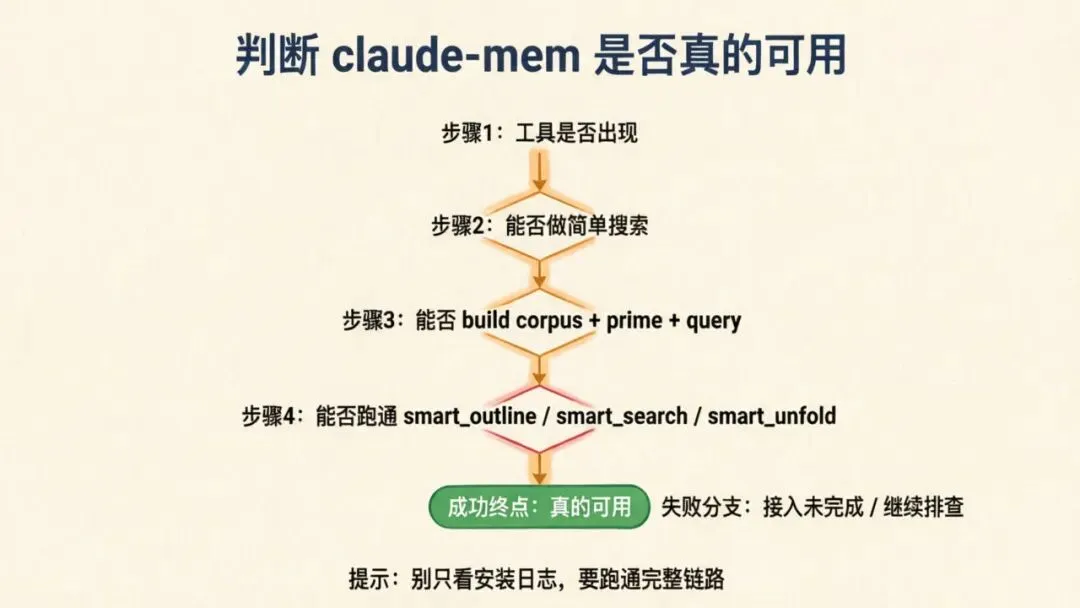
第一步:先看工具有没有出现
如果相关工具都没出现,那后面不用看了。
第二步:立刻做一次简单搜索
这是最容易验证的一步。
直接拿你当前项目试:
-
• “把这个项目之前和发布相关的 observation 找出来。” -
• “把和某个模块有关的历史记录找出来。” -
• “拉取几条相关 observation 的详情。”
如果有正常结果,说明这层记忆已经不是摆设。
第三步:试着建一个小 corpus
别一上来建很大的。
先围绕一个清晰主题建,比如:
-
• 某个功能线 -
• 某个项目阶段 -
• 某个 bug 系列
如果 build 成功、prime 成功、query 能稳定回答,说明它已经从“能搜”进入“能用”。
第四步:用一次结构化代码探索
对一个你熟悉的文件,跑一遍:
-
• smart_outline -
• smart_search -
• smart_unfold
如果这条链路顺,说明它在开发工作流里也能真正落地。
请注意,验证插件最好的方式不是问“有没有装好”,而是:
你有没有真的让它完成一件事情。
七、新手别贪:先用这 3 个能力,最容易立刻感受到价值
如果你第一次上手 claude-mem,我强烈建议你别一上来就研究所有功能。
先把下面三件事用起来,收益最大。
第一件:先学会“搜历史”
这是门槛最低、回报最快的。
你以后做任何复杂任务前,都先问一句:
-
• “之前我们讨论过这个吗?” -
• “这个项目过去有哪些相关记录?” -
• “把和这个功能相关的历史决策找出来。”
这个动作非常简单,但威力很大。
因为它会让 Claude 从“现在回答你”变成“带着历史回答你”。
第二件:围绕一个长期主题建 corpus
如果你最近正在持续做一个方向,不管是项目、功能线还是内容专题,都很适合建 corpus。
原因很简单:
你最不该重复解释的,恰恰是那些未来还会反复用到的东西。
第三件:看代码时别再盲读全文
以后别动不动就“把整个文件读一遍”。
更好的顺序是:
-
1. smart_outline看结构 -
2. smart_search找目标 -
3. smart_unfold展开关键实现
这个习惯一旦养成,代码理解效率会明显上一个台阶。
八、一个开发者最值得直接照抄的实战工作流
如果你问我:“第一次认真用 claude-mem,最值得抄的流程是什么?”
我会给你这个版本。
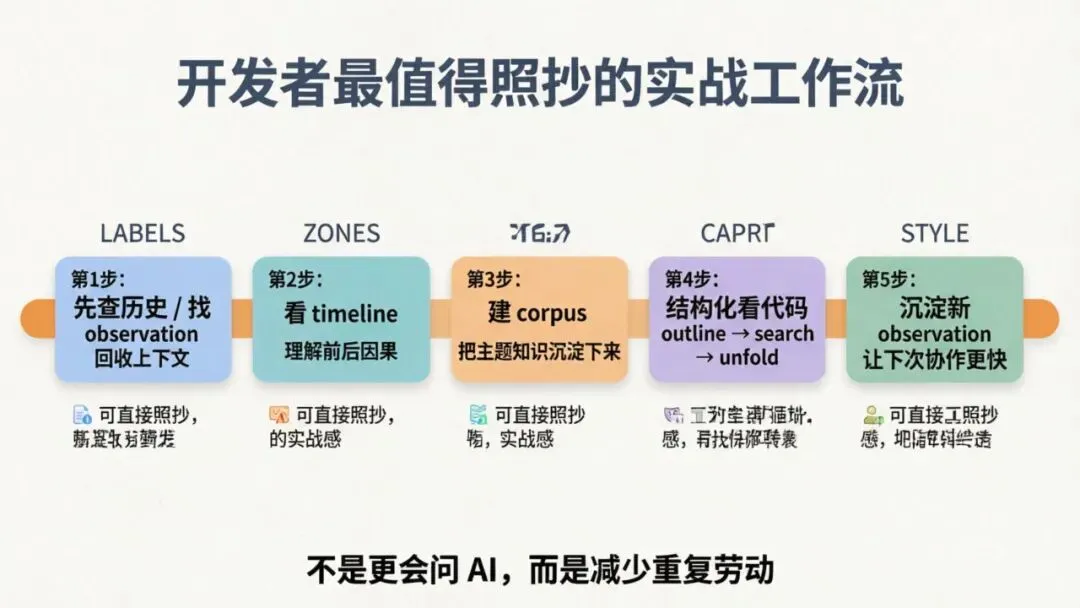
场景:你正在长期维护一个项目
第一步:别急着做,先查历史
先让 Claude 找:
-
• 这个项目之前和认证、发布、测试相关的 observation -
• 某个模块历史上有哪些决策 -
• 某些做法为什么以前被否掉
这一层非常重要。
因为很多时候,真正浪费时间的不是“不会做”,而是“从零重新进入状态”。
第二步:沿着 timeline 看关键节点
如果某条 observation 提到了一个关键判断,比如“为什么不采用某种方案”,不要停在那一条上。
继续让 Claude 沿着 timeline 看前后文。
因为一条记录只有放回历史过程里,才有真正价值。
第三步:把相关记录整理成 corpus
如果你发现某个主题已经形成了连续知识,比如“认证系统重构”或“发布流程优化”,那就别让它继续散着。
直接建一个 corpus。
这样下次你再围绕这个主题工作时,就不是从零开始。
第四步:进入具体编码前,用结构化方式看代码
不是先读全文,而是:
-
• 先看 outline -
• 再 search -
• 再 unfold
这一步会让 Claude 理解代码的方式明显更稳。
第五步:把这次的新发现继续沉淀进去
这一点很多人会漏掉。
如果你只是使用过去的记忆,却不持续沉淀新的 observation,那记忆层很快就会停留在旧版本。
真正高效的方式是:
每次协作都留下可复用资产。
这就是 claude-mem 最值钱的地方。
它不是给你“省一次解释”。它是在让你以后越来越少做重复劳动。
九、使用 claude-mem 最容易踩的 4 个坑
坑 1:以为装上就等于会用
不是。
真正决定效果的,不是你有没有这个插件,而是你有没有形成新的工作习惯:
-
• 先搜历史,再行动 -
• 重要主题,主动建 corpus -
• 看代码先看结构,再看实现
坑 2:什么都想记
长记忆不是垃圾桶。
如果什么细枝末节都塞进去,最后会变成:
-
• 检索噪音变多 -
• 真正重要的信息被淹没 -
• 你自己也不知道该查什么
真正值得沉淀的是:
-
• 决策 -
• 偏好 -
• 规则 -
• 关键发现 -
• 可复用经验
坑 3:只记不整理
如果 observation 越来越多,但你从来不 build corpus,那就像你疯狂记笔记,但从不建目录。
最后的结果通常是:看起来很多,真正要用时找不到。
坑 4:代码探索还是老路子
明明有 smart_outline、smart_search、smart_unfold,结果还是一上来就全文硬读。
这样不仅慢,还浪费上下文。
记住一句话:
能先看骨架,就别先吞全文。
十、我对 claude-mem 的真实评价:它不是最炫的,但很可能是最容易越用越离不开的
如果你要我很直接地评价:
claude-mem 不是那种“装了立刻全场震惊”的插件。
它不像新模型那样,第一眼就让你兴奋。也不像某些自动化工具那样,第一次跑就特别显眼。
但它解决的是一个更底层、也更致命的问题:
如何让 AI 不只是每次都聪明,而是长期越来越懂你。
这件事你可能第一天感受没那么夸张。
但一个月后你会越来越清楚:
没有长期记忆,你每次都在重复支付“重新解释一遍”的成本。
而且这个成本不是线性的。项目越复杂、任务越长期、协作越深入,这个成本涨得越快。
所以对 Claude Code 用户来说,claude-mem 真正的价值不是锦上添花。
它更像是你从“会用 AI”走向“和 AI 长期协作”时,迟早要补上的那一层基础设施。
十一、如果你今天就想开始,别研究太久,直接这样做
如果你现在就准备试,不要再看一堆概念。
直接照这个顺序来:
第 1 步:确认你的 Claude Code 里已经能看到 claude-mem 相关工具
先确保能力接进来了。
第 2 步:拿当前项目做一次真实搜索
直接问:
-
• “把这个项目之前和发布相关的 observation 找出来。” -
• “把这个模块有关的历史决策按时间线串起来。”
第 3 步:围绕一个未来还会持续做的主题建一个 corpus
别贪大。
先挑一个未来两周你还会反复碰到的主题:
-
• 一个项目 -
• 一条功能线 -
• 一类问题 -
• 一个内容方向
第 4 步:下一次看代码时,强制自己先 outline,再 search,再 unfold
只要你跑通一次,你马上就会感觉出来:
Claude 不再只是“能帮你干活”,而是开始“接得住你之前干过的活”。
这两者差别非常大。
最后一句
很多人以为,AI 工具竞争到最后,比的是模型。
但真正进入深水区后你会发现,差距不只在模型本身,而在于:
这个 AI,能不能承接你的长期上下文。
claude-mem 的意义,就在这里。
它让 Claude Code 从“这次帮你处理一个任务”,慢慢变成“越来越懂你、懂项目、懂历史的长期搭档”。
如果你已经是 Claude Code 的重度用户,我的建议非常简单:
别只是知道它,真的去用它。
因为你很可能会在一周后发现:
不是 claude-mem 多了一个功能,而是你第一次真正开始拥有“会积累的 AI 协作”。
如果您正在学习AI Agent,想利用Coze/dify/n8n做一些RPA方面的工作流搭建,欢迎在评论区留言或入群交流!

喜欢本篇内容请给我们点个在看

欢迎【关注】&【星标】&【转发】