 夜雨聆风
夜雨聆风





做Agent产品,你不是在做AI助手,你是在重新分配责任
写在前面
最近和几个做B端Agent产品的朋友聊,发现大家都被同一个问题卡住:
“我Demo跑通了,老板也兴奋,可是一到真用户场景就开始崩——要么乱来,要么不敢用,要么用一次就再也不打开。”
我反复琢磨这件事,越想越觉得:Agent产品翻车的根因,几乎从来不是模型不够聪明,而是产品经理还在用做SaaS的脑子做Agent。
这篇文章不讲Prompt技巧,不讲框架选型,只讲一件事:
做Agent产品的时候,你脑子里那张”产品地图”,到底应该长什么样。
一、先把一个错误的认知拆掉
很多人对Agent的第一印象是:”一个会说话的AI员工”。
这个比喻很性感,但它会让你做错三件事:
-
你会想着”让它像人一样思考” -
你会想着”给它一个岗位” -
你会想着”它出错就是它不够聪明”
错。全错。
我现在更愿意用这个定义:
Agent = 在给定目标、约束和工具权限下,能够自主推进一个任务闭环的软件执行体。
注意四个关键词:目标、约束、工具、闭环。
- 没有目标,
它就是个聊天机器人; - 没有约束,
它就是个不可控的脱缰野马; - 没有工具,
它只会生成文本,不会”行动”; - 没有闭环,
它就只是答了一句话,不是完成了一件事。
所以下次你再想做”一个AI助理”的时候,先问自己:这件事真的需要做成Agent吗?
很多需求其实只是问答系统、Copilot、带AI的Workflow——硬做成自主Agent,结果就是”看起来很聪明,但产出不可控”。
二、Agent该代理什么?不是代理人,是代理一段责任
这是我反复想清楚后最关键的一句话:
不要代理一个岗位,要代理任务链中那些”高频、可观察、可评价、可授权”的部分。
你不是在替用户雇一个员工,你是在帮用户从他每天的工作里,切走一段他不想再亲自做的责任。
什么样的任务适合被切走?同时满足下面四条越多越好:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果你的任务只满足前两条,那大概率它应该是个Copilot,不是Agent。
如果你的任务四条都满足,那才值得你认真去做一个Agent产品。
三、人和Agent的协作边界,要按”决策类型”切,不是按”动作”切
我看过太多PRD写着”人决策,AI执行”,然后做出来发现根本不work。
因为”决策”这两个字太粗了。真正可用的切法,是把决策拆成四层:
第1层:目标定义权 → 必须留在人手里
-
这件事到底要不要做 -
成功标准是什么 -
什么不能碰 -
优先级是什么
Agent永远不该擅自改目标。
第2层:过程规划权 → 可以部分给Agent
-
任务怎么拆 -
先做什么后做什么 -
缺信息时先补什么
前提是目标和约束已经被讲清楚。
第3层:执行权 → 可以大量给Agent
-
检索、汇总、生成、调用API、填表、排程
这是Agent最该接的一段。
第4层:责任签字权 → 高风险动作必须回到人
-
发给客户 -
花钱 -
改正式数据 -
对外承诺 -
发布到生产
这一层一定要有human-in-the-loop,没有商量。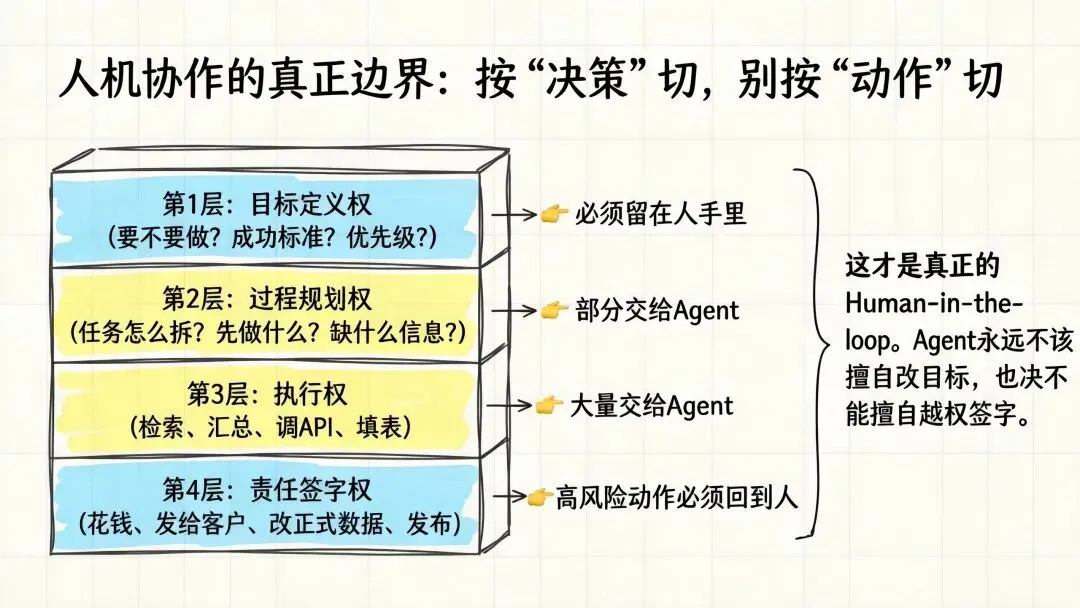
所以”人和Agent的协作边界”这句话,应该改写成:
人定义目标、约束和最终责任;Agent代理信息处理、任务推进和局部决策;涉及高风险不可逆动作时,回到人审批。
这一句话,比”人决策AI执行”靠谱十倍。
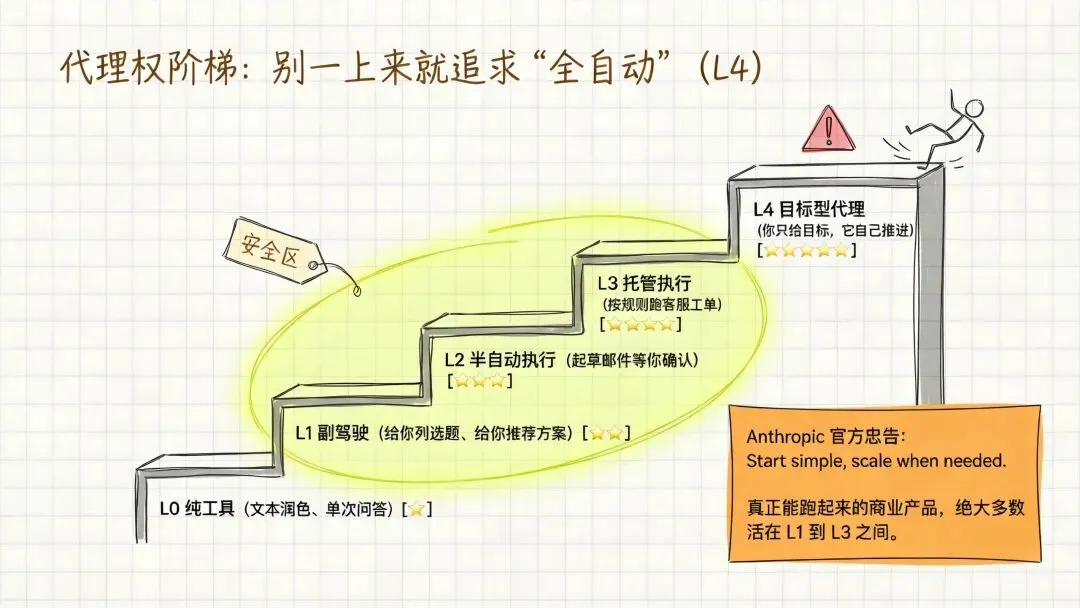
四、别一上来就追求”全自动”,请用代理权阶梯思考
Agent产品最常见的死法之一,是产品经理一上来就想做L4——你只给目标,它自主推进。
性感,但99%会翻车。
我建议你用一个”代理权阶梯”来定位自己的产品到底站在哪一级:
|
|
|
|
|
|---|---|---|---|
| L0 |
|
|
|
| L1 |
|
|
|
| L2 |
|
|
|
| L3 |
|
|
|
| L4 |
|
|
|
真正能跑起来的商业产品,绝大多数活在L1到L3之间。
不是因为L4不好,是因为L4要求你的评估体系、上下文管理、工具稳定性、降级机制都到位——这些东西你做L1到L3的时候都会顺便练出来。直接冲L4,相当于不会爬就想跑。
Anthropic自己的建议也是这句话:start simple, scale when needed。
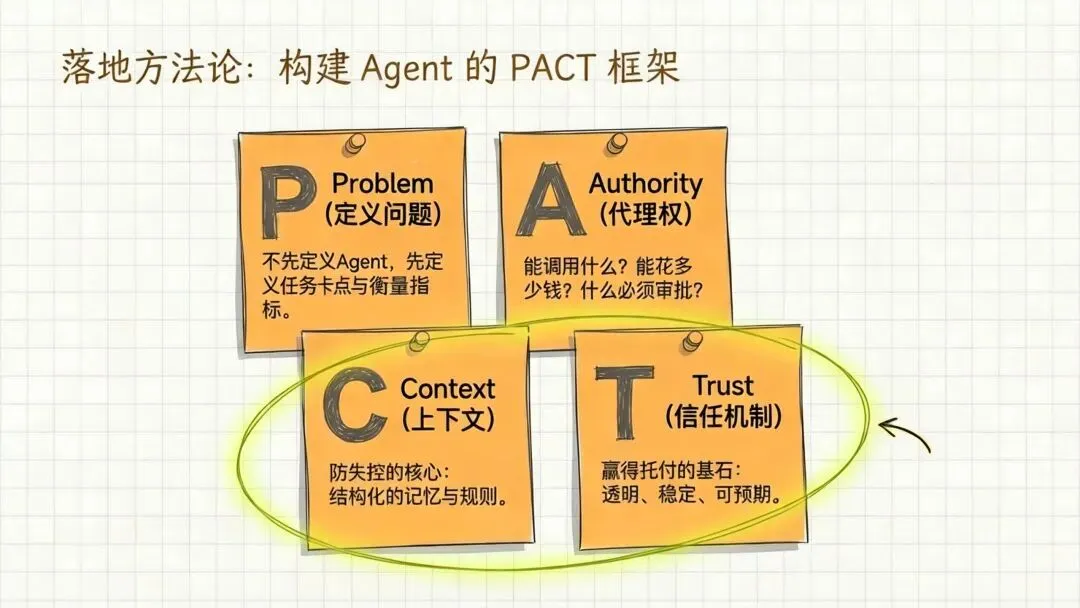
五、一个更实用的Agent方法论:PACT框架
如果让我把整套思考压到四个字母,我会用PACT:
P = Problem(先定义问题,不要先定义Agent)
问自己五个问题:
-
用户到底想完成什么任务? -
这个任务原来的流程是什么? -
卡点在哪里? -
哪一段最值得被代理? -
成功后用什么指标衡量?
A = Authority(定义代理权)
这是Agent设计文档里最容易被漏掉的一节,但它最重要:
-
Agent能决定什么、不能决定什么 -
能调用哪些工具 -
哪些动作必须审批 -
它能花多少钱、耗多少token、跑多久 -
它能不能写入正式系统
C = Context(定义上下文结构)
不要把所有信息一股脑塞进去。上下文至少要拆成:
-
角色规则 -
当前任务目标 -
用户偏好 -
历史动作摘要 -
工具返回结果 -
可引用知识 -
禁止事项 -
当前状态机位置
很多Agent一跑就乱,根源不在模型,在上下文失控。
T = Trust(定义信任机制)
用户为什么敢把事交给它?因为你给了:
- 可见的计划:
它打算怎么做 - 可见的依据:
它为什么这么做 - 可见的工具调用:
它动了什么 - 可回滚:
错了能撤 - 可审批:
关键步骤能拦 - 可追责:
出问题能查 - 可评估:
跑得好不好有数据
Agent不是靠”聪明”赢得信任,是靠透明、稳定、可预期赢得信任。
六、PRD要重写:给你一份Agent PRD的8个新模块
老PRD三件套是:页面、功能、交互。
做Agent,请你在PRD里至少多加这8个模块:
- 任务定义:
任务名、触发条件、完成标准、失败标准 - 代理边界:
什么由Agent负责,什么必须人负责 - 决策分层:
目标/过程/执行/签字四层分别归谁 - 工具权限表:
每个工具的用途、输入输出、风险级别、是否需审批 - 上下文设计:
系统规则、用户偏好、任务态记忆、长期记忆、检索/截断策略 - 状态机:
待命→接收目标→澄清→规划→执行→自检→请求审批→完成/降级 - 失败与降级策略:
工具失败、信息不足、低置信度、超时、越权时怎么办 - 评估体系:
离线评测 + 在线指标 + 人工抽检
如果这8个模块你写不出来,说明你的Agent产品定义本身还没想清楚,先别急着开工。
七、真正决定Agent产品成败的,是”责任切分”,不是”智能”
写到这里,我想说一句容易被误读、但我越想越确信的话:
很多Agent产品失败,是因为它们在卖”像人”。但用户在乎的从来不是它像不像人。
用户在乎的是四件事:
-
你能不能把事推进 -
你会不会乱来 -
你错了我能不能看出来 -
我是不是还得给你擦屁股
所以做Agent的时候,请不要再问:
“它像不像一个员工?”
而是问:
“它接下这段责任后,整个系统是不是更顺了?”
一个好的Agent,几乎从来不是最像人的那个。它是边界清楚、状态清楚、错误清楚、交接清楚的那个。
八、最后留给你的三个问题
如果你正在做Agent产品,先别想”大而全平台”,先把这三件事定死:
- 你的Agent代理的是”信息处理”还是”行动执行”?前者(采集/总结/分析/建议)容易出效果,后者(发消息/改数据/调系统)风险高很多。两条路的难度根本不在一个量级。
- 你的Agent是”单任务强闭环”还是”多任务通用平台”?绝大多数情况下,先做单任务强闭环。评估清楚、工具少、上下文短、用户预期稳定,才有快速迭代的空间。
- 你的Agent失败后,用户还能不能继续做事?如果失败就卡死,产品就是个单点故障。Agent必须是加速器,不能是绊脚石。
一句话总结
做Agent产品,不再是”设计功能给人用”,而是”设计一套人和机器共同承担任务责任的机制”。
方法论的核心不是UI,不是Prompt,不是模型选型。
而是这四步:
-
选对可代理任务 -
划清代理权与审批边界 -
把上下文和工具组织成稳定执行系统 -
用评估、日志、降级机制把它做成可托付的产品
这四步走稳了,你的Agent才有资格被用户”托付”。
而被托付,才是Agent这个词真正的分量。