 夜雨聆风
夜雨聆风





Claude Code 上下文管理机制源码解析
你有没有过这种经历,跟 Claude Code 聊了一下午,它突然忘了你十分钟前说的话,但有时候,一个你自己都记不清的细节,它倒记得门儿清。
这到底是怎么回事?今天我们就来扒一扒Claude Code(以下简称 CC)背后那套精心设计的“上下文管理”系统。
先说结论:CC 不会把内容全塞给模型
你是不是以为每次发消息时,CC 会把之前的所有对话历史打包送给模型?实际上,CC 有一套六层防线,从轻到重,层层递进:能不压缩就不压缩,能小改就不大动,逼不得已才做全量总结。
这套机制的核心是:在有限的“记忆容量”里,让模型记住最重要的东西。
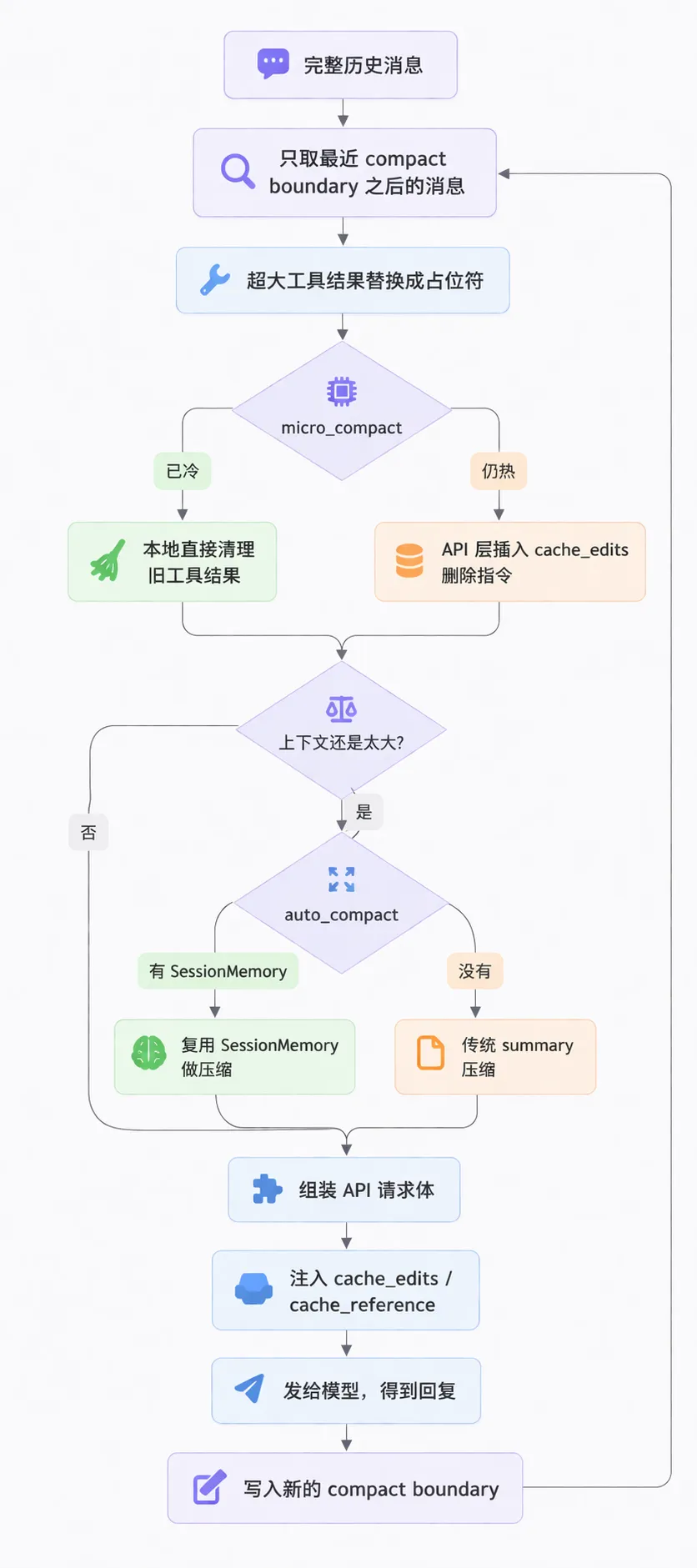
一次对话请求背后发生了什么
每当你发出一条消息,CC 并不是把整段对话历史原封不动地塞给模型,而是经过一套完整的内容压缩流程之后,再组装成真正发出去的请求。
理解这个流程的核心是:CC 有好几道防线,从轻到重依次出手。先做小动作,替换一些存在本地的大文件、清理一些已经失效的旧历史缓存,小动作够了就不做大的压缩。但是如果上下文还是太大,才会触发真正的“压缩”,而压缩本身也有优先级,能复用现成笔记就不做全量的总结。
第一层:画条线,只看“就近”
对话历史有五个不同“视角”。
-
本地原始历史:你在界面上看到的完整聊天记录; -
活跃上下文:从经历上一次压缩后到这次对话,这一轮实际会送给模型的那部分(不是全部); -
API payload:消息在真正发出前,最后拼装好的格式; -
服务端缓存前缀:服务器那边已经缓存住、不需要重新算的部分; -
磁盘辅助状态:存在本地磁盘的“笔记”,压缩摘要、大文件内容、SessionMemory 等。
关键点: CC 每做完一轮大压缩,会在对话历史里插入“分界线”(compact boundary)。之后的请求默认只取这条分界线之后的消息送给模型,之前的原始历史还在磁盘上,模型不看,但可以通过搜索命令读文件读到。
第二层:大文件,只留“摘要”
CC 读一个大文件,不会把完整内容一直带着,也不会直接删除,而是在原位放一个“占位符”,其余的存到本地磁盘。
替换前:
{type: 'tool_result',tool_use_id: 'toolu_123',content: '非常长的输出……'}替换后:
{type: 'tool_result',tool_use_id: 'toolu_123',content: '<persisted-output>\nOutput too large ... Full output saved to: ...\nPreview ...\n</persisted-output>'}----大致意思----<persisted-output>输出太大,完整内容已保存到:/path/to/file以下是前 2KB 预览…</persisted-output>---- 注意 ----这里的2KB预览指的是,就给模型看前2KB的内容,而不做额外的API调用(例如summary)大致概念就是:给你一本书的前几页,让你翻一下知道大概是什么,要看具体细节,请自己去找触发条件也很讲究:不是单个文件太大就替换,而是“分批”。一批工具结果加起来太多了,就从里面挑最大的几个换掉。比如你让 CC 连着看了 20 个文件,每个才 10KB,但加起来 200KB,该压的还是得压。
为了做到这点,CC 内部特意维护两张表。
-
seenIds:记录哪些工具结果已经被模型见过,只有见过的才做替换。
-
replacements:记录哪些结果之前已经被替换过,替换成了什么。
第三层:无感知,“悄悄”清理
这一步叫 Micro Compact,目标是在不改动本地对话历史的情况下,悄悄清理掉服务端缓存里那些旧的、没用的工具结果,减少重复 token 消耗。
-
缓存冷了:如果你隔了很久才回来聊(比如睡了一觉第二天继续对话)
-
服务端缓存基本已经失效了,再去“维护”它没意义
-
直接把旧工具结果本地标记为
[Old tool result content cleared]
-
缓存还热:如果你一直在聊
-
不动本地消息,在请求里悄悄附带一段“删除指令”
cache_edits,告诉服务器删掉指定的缓存条目 -
本地历史看起来没变,但缓存内容已经被裁剪
cache_edits:
删除内容=某个工具id
{"type": "cache_edits","edits": [{ "type": "delete", "cache_reference": "toolu_123" },{ "type": "delete", "cache_reference": "toolu_456" }]}从你的视角看,聊天记录没变,但实际送给模型的东西,已经悄悄瘦身了。
cache_edits vs snip(直接在发送前从请求里裁掉,内部功能):
-
Snip 直接修改要发出去的请求,影响服务端缓存命中,即直接删内容。
-
cache_edits 是在服务器侧操作,尽量避免打乱已有的缓存前缀,即不删内容,但是服务器的缓存被删了。
第四层:达阈值,“大力”压缩
当上下文接近上限,CC 会自动启动大压缩。
有三个相关的数值。
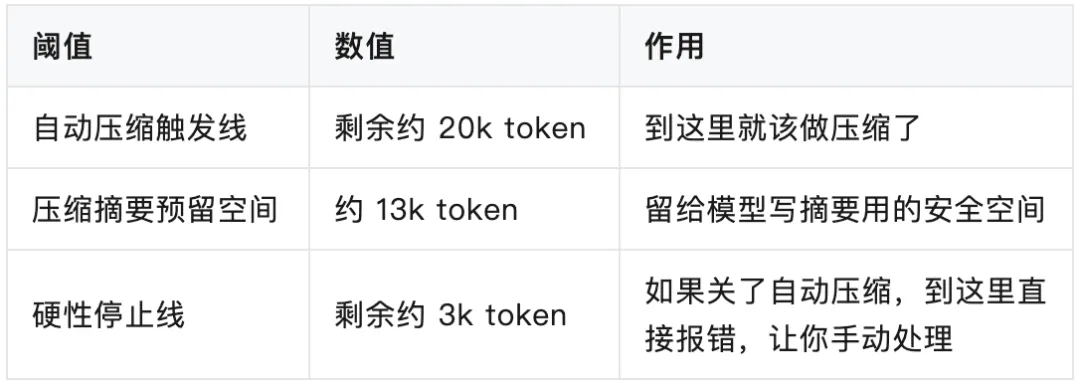
压缩优先级:
-
SessionMemory(如果有的话):后台持续维护的结构化笔记,复用比重新总结更快更好 -
Summary:让模型把历史对话整理成一份摘要
方式一:复用 SessionMemory(如果有的话)
这是 CC 里一个很聪明的设计。它不等到需要压缩时才临时总结,而是在你聊天的过程中,一直在后台默默记笔记。
-
你到底在做什么(任务目标) -
做到哪了(当前状态) -
涉及哪些文件 -
踩过什么坑(报错和修复) -
学到了什么(什么有效、什么没用) -
操作流水账
维护者是一个专门的“笔记 Agent”,只会用编辑工具,不参与你们的对话,就负责看你们聊了什么,然后更新笔记。当需要压缩时,CC 直接把这份结构化笔记拿来用,比临时总结更快更准。
方式二:传统全量总结
如果没有 SessionMemory,就让模型老老实实把整段历史总结一遍。用户意图、技术概念、涉及文件、报错和修复、待办事项等等,一股脑整理成一份摘要。
第五层:用户手动操作
除了自动压缩,CC 还提供了几个手动操作。
局部压缩(Partial Compact):选一条消息,压缩之前/之后的部分。
-
Summarize from here:以选中消息为起点,把之后的内容压缩,之前的原样保留。
-
Summarize up to here:把选中点之前的历史压缩,选中点及之后的内容原样保留。
时光回溯(Rewind):选一条历史消息作为锚点,把对话和代码回退到那个时间点。
-
对话历史 + 代码文件一起回退。
-
只回退对话历史,代码不动。
-
只回滚代码文件,对话不动。
CC 内部会给每条消息绑一个文件快照,回退是真的能恢复代码文件的。
第六层:最终兜底策略
极端情况下,压缩后的摘要加上活跃上下文,还是可能超长。
这时 CC 会从最旧的部分(按 API 轮次分组,从最上面的一批开始)开始裁剪,必要时插一条占位消息保证格式合法,然后重新尝试。
简单说就是:实在不行就丢最老的,保最新的。
为什么要了解这些
知道 CC 的上下文管理机制,能帮你更高效理智地使用它。
-
别怕长对话,CC 会自己管理上下文,不用你手动 /clear。
-
重要的事情重复说,压缩可能丢细节,关键信息多说一遍没坏处。
-
善用 SessionMemory,如果你发现 CC 记忆力特别好,多半是 SessionMemory 在起作用。
-
知道什么时候该开新对话,如果你要开始一个完全不相关的任务,新开一个对话比在旧的里面继续要高效。
本文基于对 Claude Code 源码的分析整理,具体实现可能随版本更新而变化。