 夜雨聆风
夜雨聆风





4个真实开发场景,3款AI编程工具,我替你踩完了所有坑

昨晚哄完娃已经十点四十了。
儿子今天格外难搞,非要我讲第四遍《小猪佩奇去度假》,讲到第三遍的时候我已经开始自动驾驶了——嘴上在说”佩奇一家坐上了飞机”,脑子里在想今天那个接口的并发问题到底怎么改。
终于等到小祖宗睡着,我轻手轻脚摸到书房,打开电脑。倒计时开始——满打满算还有不到两个小时的编码时间,明早七点又要被娃跳醒。
对于我这种”深夜限时编程选手”来说,AI编程工具已经不是什么新鲜玩意的尝鲜了。它是续命。
问题是,Cursor、GitHub Copilot、Claude Code,三个我全买了,加起来一个月小几百块。到底谁真的帮我省了时间,谁是在花式浪费我的时间?用了整整一个月,今天把真实感受写出来。
不搞参数跑分,不贴官方功能表。就按我每天的真实开发场景——写新功能、改Bug、Review代码、写单测——逐个说说体感。
先交代一下测评背景
三个工具我都用的最新版本,配置拉满。Cursor用的Pro版(自带Claude和GPT),Copilot用的Enterprise版(含Chat和Agent模式),Claude Code直接命令行走起。
我的主力语言是Python,后端用FastAPI,偶尔写点TypeScript前端。项目不止一个,几个后端服务加起来小十万行代码,正在往微服务架构迁移。
这个背景很重要——不同工具在不同语言和项目规模下的表现差异极大。我的结论不一定适合所有人,但至少对”写了十年Python、项目有一定复杂度”的同行应该有参考价值。
场景一:写新功能——谁最懂我的项目?
这个场景拉开差距最大。
我试了一个真实需求:给系统加一个消息通知模块,需要对接多种渠道(邮件、企微、钉钉),要求能灵活扩展。
Cursor 的表现让我有点惊喜。开了Agent模式之后,它会先扫一遍项目结构,看我现有的代码风格和分层架构,然后生成的代码居然知道复用我项目里的BaseService基类,连模块结构和命名风格都对上了。感觉像是一个刚入职一周、读完了代码库的新同事。
Copilot 在这个场景下偏”泛”。它给的方案没什么大毛病,但你能感觉到它对你的项目不够了解——生成的代码经常要花时间调整才能跑进现有架构里。就像一个能力不错但没读过你代码的外包。
Claude Code 走的是另一条路。它不会直接给你生成一整套代码,而是跟你对话:先问你想怎么设计接口,再问你对扩展性有什么要求,然后一步步帮你把代码搭出来。过程慢,但出来的东西质量确实高。适合你有整块时间去思考架构的时候用——但对我这种深夜限时选手来说,等不起。
这轮我的选择:Cursor。 对于已有项目加功能,它的上下文理解能力目前是最强的。
场景二:改Bug——谁最快定位问题?
改Bug这事,上周遇到一个绝佳的测试案例。
线上偶发一个AttributeError,Traceback指向一段看起来毫无问题的代码。查了两天没头绪,正好拿来考考三个工具。
我把报错日志、相关代码和上下文丢给它们。
Cursor 很快给出了一个修复方案——加个if obj is not None的防御判断。没毛病但也没惊喜,这是任何一个中级开发都能想到的。它没定位到根因。
Copilot 的Chat模式表现差不多,也是给了个防御性编程的建议。
Claude Code 这次让我刮目相看。它追问了我几个问题:这个对象是在哪个环节初始化的?有没有并发场景?我把多线程相关的代码也贴了进去,它直接指出了问题——一个共享的字典对象在多线程环境下没有加锁保护,两个线程同时调用dict.setdefault()时触发了竞态条件,导致偶发性地拿到未完全初始化的对象。这个根因我自己debug了两天才怀疑到,它通过对话追问,二十分钟就给我捋清了。
这轮我的选择:Claude Code。疑难Bug需要的不是快速补丁,是像一个资深同事陪你捋逻辑。 这正是Claude Code擅长的。
场景三:代码Review——谁最像资深工程师?
我用三个工具分别Review了同一段代码——一个同事写的订单状态机。
Copilot 的Review结果主要集中在代码风格上:命名不规范、缺少注释、函数过长。有用,但说实话,这些flake8加pylint也能干。
Cursor 会指出一些代码结构上的问题,比如建议把某段逻辑抽成独立函数、某段冗长的if-elif链可以用策略模式重构。给的建议比Copilot高了一个档次。
Claude Code 不仅看出了结构问题,还发现了一个状态流转的逻辑漏洞——当订单处于”退款中”状态时,理论上不应该允许”发货”操作,但代码里漏了这个校验。这种业务逻辑层面的Review,说实话,很多人工Review都未必能抓到。
这轮我的选择:Claude Code。 如果你需要的是真正有深度的Review,而不只是lint级别的检查,目前它最强。
场景四:写单测——谁生成的测试最靠谱?
最后这个场景,结果可能出乎你的预料。
给一个用户注册服务写单元测试,要求覆盖正常流程、参数校验、异常处理和边界情况。
Claude Code 的测试写得最”漂亮”——用例划分清晰,命名规范,边界case考虑周全。但问题是,它生成的测试跑不起来。因为它不知道我项目用的是pytest加一套自定义的fixture体系,它生成的测试全是unittest风格,跟我们项目的conftest和fixture写法完全不搭,改适配花了不少时间。
Cursor 生成的测试虽然没那么漂亮,但因为它读了我项目里已有的测试代码,生成的风格和已有测试高度一致——用的fixture对、mock方式对、assert风格也对。基本上生成完微调两下就能跑通。
Copilot 居中,测试能跑但覆盖场景比较基础,边界case基本没考虑。
这轮我的选择:Cursor。写单测不是选美,是要”能跑、能跑对、跑完我放心”。 项目上下文理解力在这里又赢了。
一个月下来,我的真实结论
我不想给一个笼统的排名,因为这三个工具适合的场景和人群真的不一样。直接上我的推荐矩阵:
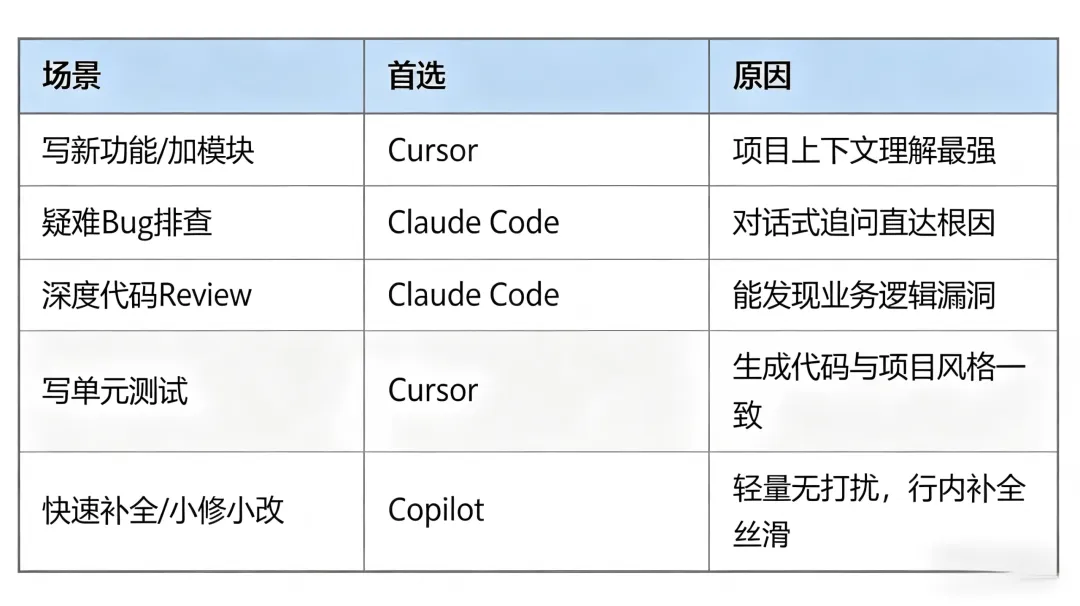
如果预算只够选一个:全栈/后端开发者选Cursor,它在”理解你的项目”这件事上领先明显;如果你经常要处理复杂架构问题或做深度Review,Claude Code是目前最接近”AI资深同事”的存在;Copilot的优势在于和VS Code/GitHub生态的深度整合,如果你重度依赖这套工具链,它的体验最无缝。
对了,说两个让我印象最深的瞬间。
“哇塞”瞬间:Claude Code帮我定位那个并发Bug的时候。二十分钟搞定我两天没查出的问题,我当时真的想给屏幕鞠个躬。
“崩溃”瞬间:Cursor的Agent模式有一次疯狂重构我没让它动的文件,我差点以为项目炸了。虽然有git兜底,但那一刻的心跳加速我至今记得。
写在最后
回到开头那个场景——哄完娃的深夜,两个小时,AI工具确实帮我把产出翻了一倍。
但用了一个月之后,让我感触最深的不是效率提升了多少。而是一个越来越清晰的认知:当AI能帮你写80%的代码时,剩下那20%——架构判断、业务理解、取舍决策——才是你真正值钱的东西。
工具会越来越强,这一点毫无疑问。程序员不会被AI取代,但不会用AI的程序员,大概率会被会用AI的程序员取代。
这句话虽然说了很多遍,但当你真的用了一个月之后,体感完全不一样。
你在用哪个AI编程工具?哪个场景下的体验让你最惊喜?评论区聊聊,说不定下一篇我就写你踩过的坑。