夜雨聆风
夜雨聆风





TensorRT-LLM 0.5.0 源码之九
embedding.py
class Embedding(Module): """ The embedding layer takes input indices (x) and the embedding lookup table (weight) as input. And output the corresponding embeddings according to input indices. The size of weight is [num_embeddings, embedding_dim] Four parameters (tp_size, tp_group, sharding_dim, tp_rank) are involved in tensor parallelism. Only when "tp_size > 1 and tp_group is not None", tensor parallelism is enabled. When "sharding_dim == 0", the weight is shared in the vocabulary dimension. tp_rank must be set when sharding_dim == 0. When "sharding_dim == 1", the weight is shard in the hidden dimension. """ def __init__(self, num_embeddings, embedding_dim, dtype=None, tp_size=1, tp_group=None, sharding_dim=0, tp_rank=None): super().__init__() # num_embeddings records the total vocab size no matter using TP or not self.num_embeddings = num_embeddings self.embedding_dim = embedding_dim self.tp_size = tp_size self.tp_group = tp_group self.sharding_dim = sharding_dim self.tp_rank = tp_rank if sharding_dim == 1: self.weight = Parameter(shape=(self.num_embeddings, self.embedding_dim // self.tp_size), dtype=dtype) elif sharding_dim == 0: self.weight = Parameter(shape=(math.ceil( self.num_embeddings / self.tp_size), self.embedding_dim), dtype=dtype) def forward(self, x): return embedding(x, self.weight.value, tp_size=self.tp_size, tp_group=self.tp_group, sharding_dim=self.sharding_dim, tp_rank=self.tp_rank)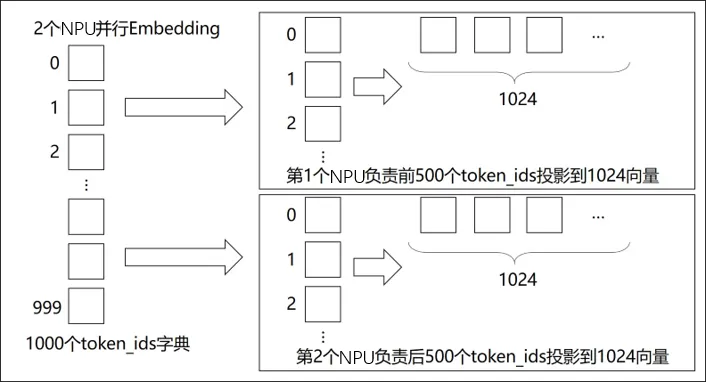
def embedding(input: Tensor, weight: Tensor, tp_size=1, tp_group=None, sharding_dim=0, tp_rank=None) -> Tensor: ''' Add an operation to perform embedding lookup. That operation performs the embedding lookup. The 'input' tensor contains the identifiers of the rows of 'weight' to gather. 1. Distribute the embedding lookup table over multiple GPU When 'tp_size' is greater than 1 and the 'tp_group' is defined, this embedding lookup is distributed among multiple GPUs. When 'sharding_dim==0', each GPU stores a subset of the rows of the embedding table rows(that number of rows per GPU is given by weights.shape[0] and the offset to the 1st row stored on the GPU is given by rank * weights.shape[0]). Each parallel rank will query all the indices and set 0s for the weights that are not stored on the associated GPU. To compute the final result, a parallel all-reduce operation is added to the TensorRT graph. That lookup can be performed using either the plugin or the operators TensorRT support. When'sharding_dim==1', each GPU stores a subset of the embedding table's columns. Each rank can obtain a portion of the embedding results. Then the embedding is collected using the all-gather operation. Related transposition operations are also used to obtain the final results. 2. Store embedding lookup table as a whole When 'tp_size' is not greater than 1, the embedding lookup table will not be divided. In this case, when the default_net().plugin_config.lookup_plugin is set, the operation is implemented using a plugin (without the all-reduce operation). Otherwise, this operation is implemented using the standard IGatherLayer in TensorRT. Parameters: input : Tensor The input tensor the contains the indices to perform the lookup. weight : Tensor The table to gather from. tp_size : int The number of GPUs collaborating to perform that embedding. tg_group : Optional[List[int]] The group of world ranks participating in the all-reduce when tp_size > 1. sharding_dim : int sharding_dim = 0 means that we shard the embedding table in vocab dim; sharding_dim = 1 means that we shard the embedding table in embedding dim. tp_rank : int The tensor parallelism rank. Used to calculate offset in TP on vocab dim. Returns: The tensor produced by the embedding lookup layer. ''' # Distribute embedding lookup table accross multiple GPU if tp_size > 1 and tp_group is not None: if sharding_dim == 0: # TP on vocab_size dimension if tp_rank == None: raise ValueError( "Rank cannot be none for tensor parallelism on vocab dim") if default_net().plugin_config.lookup_plugin: x = _lookup_plugin(input, weight, tp_rank) x = allreduce(x, tp_group) else: shape_weight = shape(weight) vocab_size = slice(shape_weight, starts=[0], sizes=[1]) tmp_input = input - vocab_size * tp_rank # Identify the valid indices is_qualified = op_and(tmp_input >= 0, tmp_input < vocab_size) is_qualified_expand = expand_dims(is_qualified, [is_qualified.ndim()]) # Replace the invalid ones to zero placeholder_input = where(is_qualified, tmp_input, 0) # Get the temporal results layer = default_trtnet().add_gather( weight.trt_tensor, placeholder_input.trt_tensor, 0) tmp_output = _create_tensor(layer.get_output(0), layer) # Set zero for invalid results placeholder_tmp = cast(is_qualified_expand, tmp_output.dtype) placeholder = placeholder_tmp - placeholder_tmp x = where(is_qualified_expand, tmp_output, placeholder) # Use all reduce to collect the results x = allreduce(x, tp_group) elif sharding_dim == 1: # TP on hidden dimension layer = default_trtnet().add_gather(weight.trt_tensor, input.trt_tensor, 0) x = _create_tensor(layer.get_output(0), layer) # 1. [dim0, local_dim] -> [dim0 * tp_size, local_dim] x = allgather(x, tp_group) # 2. [dim0 * tp_size, local_dim] -> [dim0, local_dim * tp_size] # 2.1 split split_size = shape(x, dim=0) / tp_size ndim = x.ndim() starts = [constant(int32_array([0])) for _ in range(ndim)] sizes = [shape(x, dim=d) for d in range(ndim)] sizes[0] = split_size sections = [] for i in range(tp_size): starts[0] = split_size * i sections.append(slice(x, concat(starts), concat(sizes))) # 2.2 concat x = concat(sections, dim=(x.ndim() - 1)) else: raise ValueError( 'Tensor Parallelism only support splitting Embedding lookup along hidden (sharding_dim==1) and vocab (sharding_dim==0) dimensionis' ) # Store embedding lookup table as a whole else: if default_net().plugin_config.lookup_plugin: x = _lookup_plugin(input, weight, rank=0) else: layer = default_trtnet().add_gather(weight.trt_tensor, input.trt_tensor, 0) x = _create_tensor(layer.get_output(0), layer) return xdef _lookup_plugin(input: Tensor, weight: Tensor, rank: int) -> Tensor: ''' Add an operation to perform lookup in a tensor. That operation performs the lookup needed by embedding layers. Given a 'weight' tensor of shape [rows, cols], it produces a tensor of shape [inputs.size(0), cols] where the ith row corresponds to the input[i] row in the weight tensor. It inserts a IPluginV2Layer. Parameters: input : Tensor The input tensor the contains the indices to perform the lookup. weight : Tensor The table to gather from. rank : int The mpi rank. Returns: The output tensor of the lookup layer. ''' plg_creator = trt.get_plugin_registry().get_plugin_creator( 'Lookup', '1', TRT_LLM_PLUGIN_NAMESPACE) assert plg_creator is not None p_dtype = default_net().plugin_config.lookup_plugin pf_type = trt.PluginField( "type_id", np.array([int(str_dtype_to_trt(p_dtype))], np.int32), trt.PluginFieldType.INT32) rank = trt.PluginField("rank", np.array([int(rank)], np.int32), trt.PluginFieldType.INT32) pfc = trt.PluginFieldCollection([pf_type, rank]) lookup_plug = plg_creator.create_plugin("lookup", pfc) plug_inputs = [input.trt_tensor, weight.trt_tensor] layer = default_trtnet().add_plugin_v2(plug_inputs, lookup_plug) return _create_tensor(layer.get_output(0), layer)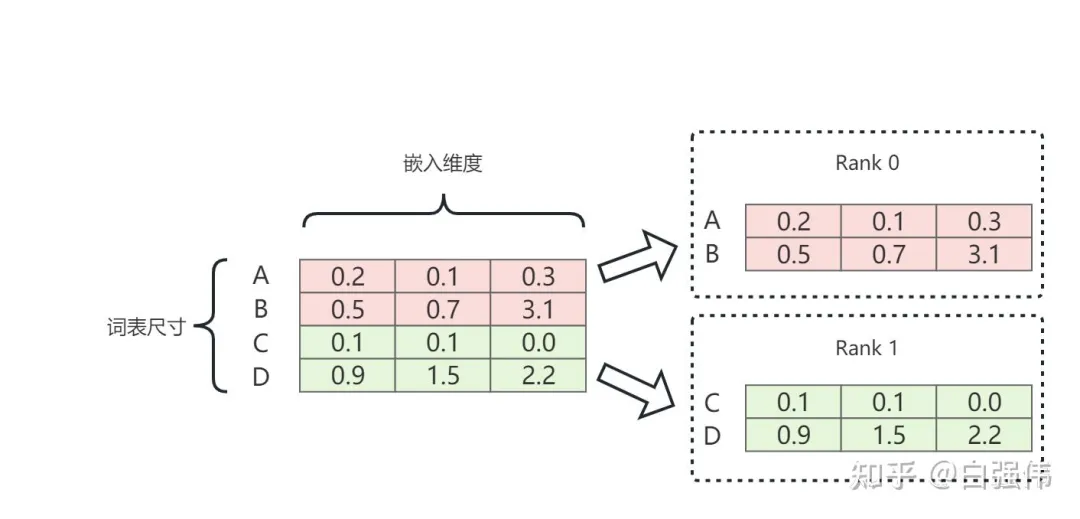
这个嵌入查找函数实现了在TensorRT环境中高效处理嵌入层(Embedding Layer)的核心功能,特别针对分布式张量并行(Tensor Parallelism)场景进行了优化。下面我将从核心原理、分布式处理策略以及实现细节三个层面进行解析。
嵌入查找的基本原理
嵌入查找的本质是将离散的高维稀疏特征(通常是类别ID或词汇ID)转换为低维稠密向量表示。该操作可以理解为一种特殊的全连接层:假设有一个形状为[vocab_size, embedding_dim]的权重矩阵(即嵌入表),当输入一个整数索引i时,嵌入层会返回该矩阵的第i行向量。
从计算视角看,嵌入查找在数学上等价于以下两步:
-
1. 将输入索引转换为One-hot编码(一个长度为 vocab_size的向量,仅在索引对应位置为1,其余为0)。 -
2. 将这个One-hot向量与嵌入矩阵相乘。
然而,直接进行矩阵乘法的计算效率很低。因为One-hot向量极其稀疏,实际实现中通常通过查表(Gather操作) 来直接获取对应的行,从而避免昂贵的矩阵乘法。在神经网络中,嵌入层是可训练的,其参数(即嵌入表)会在反向传播过程中更新,使得语义相近的实体在嵌入空间中的向量表示也更接近。
函数整体逻辑与分布式策略
该函数的核心逻辑根据是否启用张量并行(tp_size > 1)分为两大路径。
当处于分布式模式时(tp_size > 1),函数会根据sharding_dim的值选择两种不同的分片策略,这两种策略的核心区别如下表所示:
|
|
|
|
|---|---|---|
| 分片对象 |
|
|
| 每个GPU存储 |
|
|
| 查找后操作 | All-Reduce
|
All-Gather + 重排
|
关键实现细节剖析
1. 词汇维度分片 (sharding_dim=0)
这种策略下,整个嵌入表在词汇维度被切分,每个GPU只存储一部分词汇的嵌入向量。例如,假设总词汇量vocab_size为10000,tp_size=4,则每个GPU大约存储2500个词向量。
查找过程的挑战在于,输入ID可能指向存储在其它GPU上的词汇。函数的处理逻辑是:
-
• 偏移计算与有效性校验:首先,将输入ID减去当前GPU负责的词汇范围的起始偏移量( tp_rank * vocab_size_per_gpu),得到本地ID。然后检查哪些ID落在本地有效的词汇范围内。 -
• 查询与掩码:对于有效的本地ID,通过Gather操作获取其向量;对于无效ID(不属于本GPU负责的范围),则输出零向量。这确保了只有存储了对应向量的GPU才会产生非零结果。 -
• 结果汇总:最后,通过All-Reduce操作(通常是求和)将所有GPU的结果合并。由于无效位置输出为零,求和后每个位置最终得到的就是正确的嵌入向量。
2. 隐藏维度分片 (sharding_dim=1)
这种策略下,每个GPU存储的是所有词汇的完整向量,但每个向量只包含一部分维度(特征)。例如,如果嵌入维度是512,tp_size=4,则每个GPU存储所有词汇的128维向量。
查找过程相对直接:
-
• 本地查询:每个GPU都能独立完成本地查询,因为所有词汇的”部分向量”都在本地。 -
• 收集与拼接:查询后,每个GPU得到一批单词的部分嵌入向量。通过All-Gather操作,每个GPU收集到其他所有GPU上的部分向量,然后将这些部分向量沿着嵌入维度拼接起来,重构出完整的嵌入向量。
3. 单GPU与插件机制
当不启用张量并行(tp_size <= 1)时,逻辑最简单:直接对完整的嵌入表进行Gather操作。
函数还提供了插件选项(lookup_plugin)。插件通常是针对特定硬件和场景高度优化的内核,可能比使用标准TensorRT算子(如IGatherLayer)具有更好的性能,尤其是在处理大规模嵌入表或特殊数据模式时。
这个函数的设计精妙地平衡了通用性和效率,通过张量并行和插件机制,使得嵌入层能够适应从单卡到大规模分布式训练的各种推理场景。
PromptTuningEmbedding
class PromptTuningEmbedding(Embedding): """ Pass all tokens though both normal and prompt embedding tables. Then, combine results based on whether the token was "normal" or "prompt/virtual". """ def __init__(self, num_embeddings, embedding_dim, vocab_size=None, dtype=None, tp_size=1, tp_group=None, sharding_dim=0, tp_rank=0): super().__init__(num_embeddings, embedding_dim, dtype, tp_size, tp_group, sharding_dim, tp_rank) if vocab_size is None: vocab_size = num_embeddings self.vocab_size = vocab_size def forward(self, tokens, prompt_embedding_table, tasks, task_vocab_size): # do not use ">=" because internally the layer works with floating points prompt_tokens_mask = tokens > (self.vocab_size - 1) # clip tokens in the [0, vocab_size) range normal_tokens = where(prompt_tokens_mask, self.vocab_size - 1, tokens) normal_embeddings = embedding(normal_tokens, self.weight.value, self.tp_size, self.tp_group, self.sharding_dim, self.tp_rank) # put virtual tokens in the [0, max_prompt_vocab_size) range prompt_tokens = where(prompt_tokens_mask, tokens - self.vocab_size, 0) # add offsets to match the concatenated embedding tables tasks = tasks * task_vocab_size # tasks: [batch_size, seq_len] # prompt_tokens: [batch_size, seq_len] prompt_tokens = prompt_tokens + tasks prompt_embeddings = embedding(prompt_tokens, prompt_embedding_table) # prompt_tokens_mask: [batch_size, seq_len] -> [batch_size, seq_len, 1] # combine the correct sources of embedding: normal/prompt return where(unsqueeze(prompt_tokens_mask, -1), prompt_embeddings, normal_embeddings)PromptTuningEmbedding 类是一个专门为多任务提示调优(Prompt Tuning) 设计的嵌入层实现。它通过动态路由机制,在同一个前向传播过程中区分处理常规词汇令牌和虚拟提示令牌,从而高效地结合预训练模型的知识和任务特定的提示信息。
下面是对其实现原理的详细分析。
核心设计思路
这个类的核心目标是处理同时包含正常词汇令牌和虚拟提示令牌的输入序列。其设计基于以下关键思路:
-
1. 令牌类型区分:通过一个预设的 vocab_size作为分界点,自动识别输入令牌中的正常令牌(索引在[0, vocab_size-1]范围内)和虚拟提示令牌(索引 >=vocab_size)。 -
2. 双路嵌入查询:对于识别出的两种令牌,分别从两个不同的嵌入表中查找其向量表示: -
• 正常令牌:从继承自父类的 self.weight(即预训练模型的原始嵌入表)中查询。 -
• 虚拟提示令牌:从外部传入的、专门为提示调优可训练的 prompt_embedding_table中查询。 -
3. 多任务支持:通过 tasks和task_vocab_size参数,支持为不同的任务分配不同的提示令牌块,实现一个模型服务多个任务。 -
4. 结果融合:最后,使用一个掩码将两路查询结果合并成一个统一的嵌入张量输出。
代码实现解析
以下是 forward 方法中关键步骤的解读:
def forward(self, tokens, prompt_embedding_table, tasks, task_vocab_size): # 1. 创建虚拟令牌掩码 prompt_tokens_mask = tokens > (self.vocab_size - 1)-
• 目的:创建一个布尔掩码,标识出哪些输入位置是虚拟提示令牌。 -
• 原理:所有索引大于等于 vocab_size的令牌都被视为虚拟提示令牌。
# 2. 处理正常令牌 normal_tokens = where(prompt_tokens_mask, self.vocab_size - 1, tokens) normal_embeddings = embedding(normal_tokens, self.weight.value, ...)-
• 目的:获取正常令牌的嵌入向量。 -
• 细节: -
• normal_tokens = where(...):这是一个安全措施。它将所有被识别为虚拟提示令牌的位置的索引替换为vocab_size - 1(通常是一个安全值,如填充符或未知令牌的索引),而正常令牌的索引保持不变。这是为了确保在查询预训练嵌入表时不会传入越界的索引。 -
• normal_embeddings = embedding(...):使用修改后的索引从预训练嵌入表中查询正常令牌的向量。
# 3. 处理虚拟提示令牌 prompt_tokens = where(prompt_tokens_mask, tokens - self.vocab_size, 0) tasks = tasks * task_vocab_size prompt_tokens = prompt_tokens + tasks prompt_embeddings = embedding(prompt_tokens, prompt_embedding_table)-
• 目的:获取虚拟提示令牌的嵌入向量,并支持多任务。 -
• 细节: -
• prompt_tokens = where(...):将虚拟提示令牌的全局索引转换为在提示嵌入表中的局部索引,方法是减去vocab_size。例如,全局索引为vocab_size + 5的虚拟令牌,其在提示嵌入表中的局部索引是5。 -
• tasks = tasks * task_vocab_size和prompt_tokens = prompt_tokens + tasks:这是实现多任务支持的关键。假设每个任务最多有task_vocab_size个虚拟令牌。通过将任务ID乘以task_vocab_size,为每个任务在连续的提示嵌入表中分配了一块独立的区域。这样,不同任务的虚拟令牌即使局部索引相同,也会映射到提示嵌入表中完全不同的行,从而学习到任务特定的知识。 -
• prompt_embeddings = embedding(...):使用计算出的最终索引从可训练的prompt_embedding_table中查询虚拟提示令牌的向量。
# 4. 合并嵌入结果 return where(unsqueeze(prompt_tokens_mask, -1), prompt_embeddings, normal_embeddings)-
• 目的:将两路查询的结果合并成最终的嵌入张量。 -
• 原理:将 prompt_tokens_mask增加一个维度以匹配嵌入向量的维度,然后使用where函数进行条件选择。对于掩码为True(虚拟令牌)的位置,选择prompt_embeddings中对应的向量;对于掩码为False(正常令牌)的位置,选择normal_embeddings中对应的向量。
技术特点与优势
|
|
|
|---|---|
| 参数高效性 |
prompt_embedding_table 中的参数,预训练模型的主体参数被冻结,极大降低了训练开销,是典型的参数高效微调方法。 |
| 灵活的多任务支持 |
|
| 动态路由机制 |
|
| 与标准嵌入兼容 |
Embedding 类并利用其分布式功能(如TP),保证了在大模型分布式训练/推理框架中的集成性。 |
总结
这个 PromptTuningEmbedding 类的实现体现了提示调优技术的核心思想:通过引入少量可训练的参数(虚拟提示令牌的嵌入)来引导强大的预训练模型适应下游任务。它通过精巧的掩码机制、索引重映射和多任务偏移,实现了正常令牌与虚拟令牌嵌入的高效、灵活融合,为大模型的参数高效微调提供了一个关键的基础组件。
参考文献
-
• https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/tensorrt_llm/functional.py -
• https://www.mindspore.cn/tutorials/zh-CN/r2.7.1/model_infer/ms_infer/ms_infer_parallel_infer.html -
• https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/tensorrt_llm/layers/embedding.py -
• https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/tensorrt_llm/layers/linear.py