 夜雨聆风
夜雨聆风





让AI别再飘:给你的智能助手搭一套"工厂流水线"

你有没有过这样的经历:
让AI帮你写一篇文章,第一版出来还挺像样。你说”再改改”,它改了,但改歪了。你说”这不对”,它又改,改得更不像了。几轮下来,你干脆自己上手重写。
或者让它帮你做一个方案。它做了,但每次你都发现它在”忘事”——上次说好的定位,这轮就不认了;上轮说要往东,这轮突然往西。你以为自己在调教助手,结果发现自己在当保姆。
问题出在哪?
不是AI不够聪明,而是它的工作环境太差了。
01 问题本质:AI缺的不是脑子,是”车间”
过去两年,我们花了很多精力在”让AI说得更漂亮”——写更好的Prompt、塞更多的背景材料。这当然有用,但只解决了一半问题。
打个比方:
Prompt Engineering,就像教工人怎么操作机床。你说得越清楚,它干得越利索。但这只管”这一刀怎么切”。
Context Engineering,就像给工人配图纸和说明书。它知道要做什么零件、有什么标准。但这只管”这一批怎么干”。
可真正的问题来了:如果你要的是一个24小时运转的车间,工人换班、机器故障、原料断供,这个车间还能稳定出活吗?
这就是这套方法要解决的事——不是让工人更熟练,而是给工人搭一套可持续运转的”工厂环境”。
有人管这个叫”环境工程”(Harness Engineering),名字不重要,重要的是它的思路:把AI当成工人,给它搭车间、配图纸、定流程、设质检。
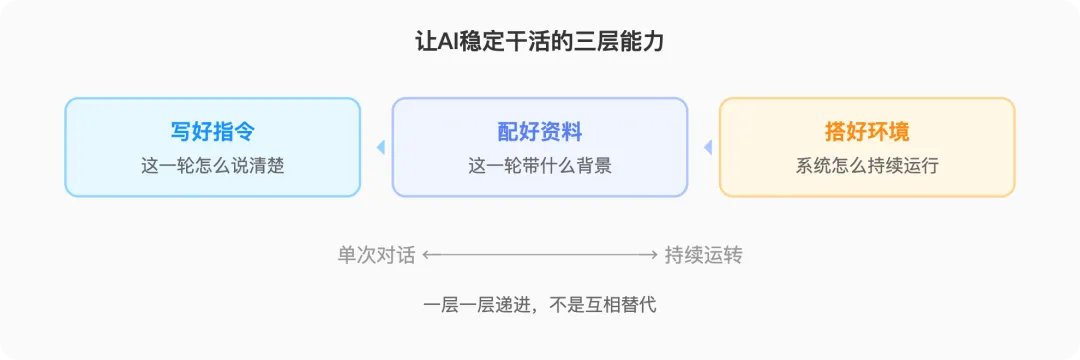
图1:让AI稳定干活的三层能力(一层一层递进)
02 四件事:把AI关进”流水线”
这套方法论的核心就四件事,说人话就是:
第一,角色分开,别让一个人干全流程
你见过哪个工厂是一个人又设计、又生产、又质检的?没有。因为一旦同一个人既干又审,他就会对自己的产出过度自信——”我觉得挺好啊”。
AI也一样。如果你让同一个AI既写方案又审方案,它会越来越”自洽”——每看一遍都觉得”没毛病”,但旁人一眼看过去全是问题。
所以第一件事:写作的人不审稿,审稿的人不改稿。让不同的AI角色各司其职,中间用”问题清单”来交接。
具体怎么做到?
很简单——审稿的时候,开一个新的对话窗口。
就像你写完一篇文章,不自己看,而是交给一个”完全没参与写作的人”来挑刺。这个人没被你的思路”带偏”,所以能看到你看不到的问题。
三种方式,从简单到专业:
1最简单:写完后,你手动开一个新对话窗口,把内容粘贴过去,让AI当”审稿人”。
2进阶:用一些AI工具(比如Claude Code),可以设置”自动开新窗口审稿”。
3专业:写代码实现自动化,每次审稿都重新初始化。

图2:四大角色,各管各的事
第二,给AI配一个”记忆库”,让它知道你是谁
AI每次开工都像”失忆”——它不记得你上次说了什么、你的风格是什么、你关心什么。你得每次重新介绍自己。
解决方法是建一个三层”档案夹”:
1底层档案:你是谁、你的长期定位、你的产品版图——这些是稳定的”人设”,变动频率很低。
2中层档案:你最近在做什么项目、当前重点是什么——这是”工作面”,随项目推进更新。
3上层档案:还没想清楚的草稿、待补的材料——这是”半成品”,最不稳定。
具体怎么做到?
最简单的方式就是建三个文件夹:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
AI每次开工前,先读这三层档案。它就知道:你是谁、在干什么、哪些材料可以直接用、哪些还需要再确认。

图3:三层档案夹(重要性:底层 > 中层 > 上层)
第三,每次停下来,都要写”交班单”
工厂里的工人换班,不是打声招呼就走的。要写交接记录:做到哪了、停在哪了、为什么停、下个人从哪接。
AI也一样。每轮任务结束后,必须输出三样东西:
1计划单:这轮要干什么、成功后往哪走。
2回执单:实际产出了什么、为什么停在这。
3状态清单:当前进度、下一步入口。
交班单模板示例
📋 交班单 [公众号文章生产]
阶段:审稿 → 修复进度:60%本轮完成:初稿撰写、独立审稿产出物:/桌面/公众号_xxx.html阻塞点:审稿发现3个阻断级问题下轮入口:根据问题单修复B-001至B-003
这样,下一轮AI不需要猜”上次做到哪了”,直接从交接点继续。
第四,用”对抗审稿”逼出好内容
一篇好文章,通常不是一次写出来的,而是”被逼出来”的。
让一个独立的AI角色来审稿,覆盖五个视角:
红队视角:如果有人恶意攻击怎么办?(安全边界)
白队视角:技术上能落地吗?(可行性)
小白视角:外行能看懂吗?(易读性)
专家视角:有没有更好的做法?(专业性)
用户视角:这真的是用户想要的吗?(价值感)
审稿不是泛泛说”还不错”,而是输出一个结构化的”问题单”——哪里有问题、什么级别、怎么改。然后退回去,让写作角色按问题单逐条修复。
返修上限与人工边界
重要规则:修复超过3次还不过,就显式阻断,要求人工介入。
这是为了防止系统陷入无限自我改写——有时候问题不是AI能修好的,而是从一开始方向就错了,需要人来判断。
“阻断”意味着:系统停下来,把问题交给人。人可以选择重新规划方向,或者降低标准放行,或者干脆重写。系统不会自主否决人工决策。

图4:对抗收敛流程(返修上限:3次)
03 这套方法适合谁?不适合谁?
不是所有任务都需要这么复杂。先看看你是不是目标用户:
适合用的场景
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
不需要这么复杂的场景
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
成本考量
这套方法会增加一些成本:
Token成本:多角色协作意味着多次调用LLM。一篇公众号文章从选题到发布,可能消耗5-10倍的token(vs 单轮对话)。
时间成本:审稿、返修、交接都需要时间。但对高风险任务,这些时间投入是值得的——避免”写完发现方向错了”。
维护成本:三层Context库需要持续维护。但这个维护本身就是知识沉淀,长期看是资产。
04 一个真实案例:从”飘”到”稳”
这是我自己的实践:
场景:我需要一个公众号文章自动生成,帮我把日常的AI/产品/流程思考整理成可发布的文章。
之前的问题:
让AI写文章,第一版还行,改两轮就歪了。它不记得我的风格、不记得产品的定位、每次都像失忆。最后我发现自己花了大量时间在”重新解释背景”和”纠正跑偏”。
用了Harness之后:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键改变:
1建了三层档案夹,AI每次开工前先”读档案”
2写作和审稿分开,审稿开新对话窗口
3每次停工写交班单,下次直接续上
4返修超过3次就阻断,我来决定要不要降标准
最重要的是:我终于可以睡觉的时候,让AI接着干活了。第二天醒来,看到的是一份经过研究、写作、审稿、修复后相对收敛的结果,而不是一堆需要我从头解释背景的半成品。
05 你可以怎么开始?
如果你想试试这套方法,建议从最简单的开始:
立即可做(不用任何工具)
1建三个文件夹:我的定位 / 当前项目 / 草稿箱。把你的长期定位、当前工作、草稿素材分开放。
2审稿开新窗口:下次让AI写完东西,你开一个新的对话窗口,把内容粘贴过去,让AI当”陌生人”来挑刺。
3每次停下来写几句:做到哪了、为什么停、下回从哪开始。存到”当前项目”文件夹里。
进阶可做(需要一些工具)
1用支持”技能”的AI工具(比如Claude Code),把”写作””审稿””交班”封装成固定流程。
2把你的档案夹挂载到AI工具,让它能自动读取你的定位和当前工作。
常见问题
Q:这套方法跟网上说的”思维链”之类的是什么关系?
A:那些是让AI”想得更清楚”的技巧,这套是让AI”干得更稳定”的环境。可以叠加使用,不冲突。
Q:开新窗口审稿,真的有用吗?不就是同一个AI吗?
A:有用。关键是”新窗口没看过之前的对话”——它只看到最终产出,不知道你中间怎么想的。就像一个陌生人看你的文章,比你自己更容易发现问题。
Q:维护三层档案会不会很麻烦?
A:底层和中层的内容本来就是你工作会产出的(你的定位、你的项目文档),只是分门别类放好。上层就是草稿箱。维护成本不高,但收益明显。
· · ·
这不是什么高深技术,而是一套”工程思维”——把AI当工人,给它搭车间、配图纸、定流程、设质检。
你会发现,AI不再”飘”了,不再”忘”了,不再”断”了。
它开始像一个真正的助手,而不是一个需要你一直盯着的孩子。
核心原则就一句话:不是让AI更聪明,而是给AI搭一套稳定运转的环境。
· · ·