 夜雨聆风
夜雨聆风





Cursor 是怎么工作的?AI 编码工具底层架构揭秘
大家好,我是James。
上一篇我们聊了 Edge AI 和本地推理,把模型跑在前端,挤掉了网络延迟和云端费用。这一篇我们换个角度——当 AI 编码助手成了开发者的标配,你知道 Cursor 每次给你补代码、解释报错、改 bug,底层到底在干什么吗?
你打开 Cursor,框选一段代码,按下 Cmd+K,它秒级改完了。但你有没有想过:它「看到」的是什么?怎么知道要改哪里、不改哪里?改的时候上下文是怎么拼的?
这些问题不搞清楚,你就只能「盲用」——不知道为什么有时准、有时废,不知道为什么大项目里它突然变笨了。
一句话定义
Cursor 是一个把 IDE 操作转化为结构化上下文,再喂给 LLM 的工程系统——你以为它在「理解代码」,其实它在精心构造一份「现场报告」递给模型。
类比:你不是在和一个住在编辑器里的程序员聊天,而是在和一个每次只能读一张「情报简报」的侦探合作——简报质量决定破案质量。
为什么值得深入研究?
-
Cursor 月活用户突破 100 万,估值 25 亿美元(2024 年) -
用好 Cursor 的开发者和用不好的,效率差距在 3-5 倍 -
理解它的工作原理,你才能主动控制上下文质量,而不是被动等结果
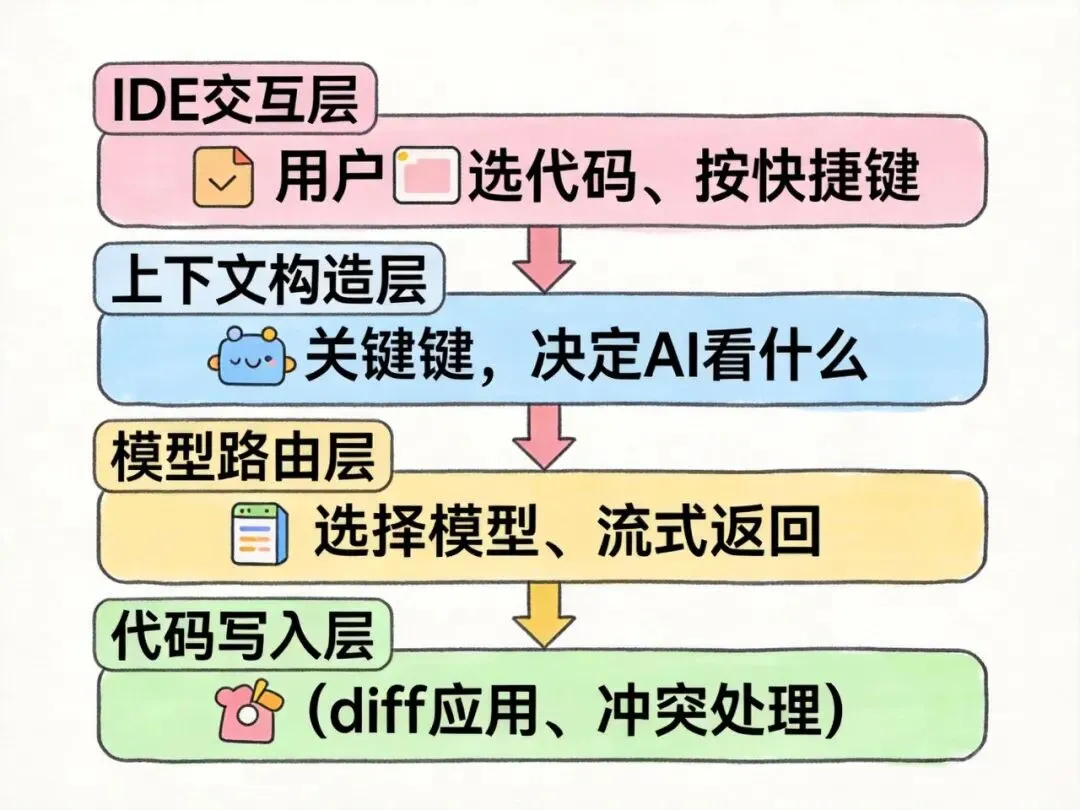
核心架构:四层模型
Cursor 的整体架构可以拆成四层:
┌─────────────────────────────────┐
│ IDE 交互层(用户端) │ ← 框选、输入、快捷键
├─────────────────────────────────┤
│ 上下文构造层 │ ← 最关键!决定 LLM 看到什么
├─────────────────────────────────┤
│ 模型路由层 │ ← 选哪个模型、如何流式返回
├─────────────────────────────────┤
│ 代码写入层 │ ← diff 应用、冲突处理
└─────────────────────────────────┘
大多数人只看到第一层和第四层(输入 → 输出),中间两层才是 Cursor 真正的技术壁垒。
上下文构造层:Cursor 最核心的工程
Cursor 不是把整个项目喂给 AI,而是动态选择「最相关的片段」
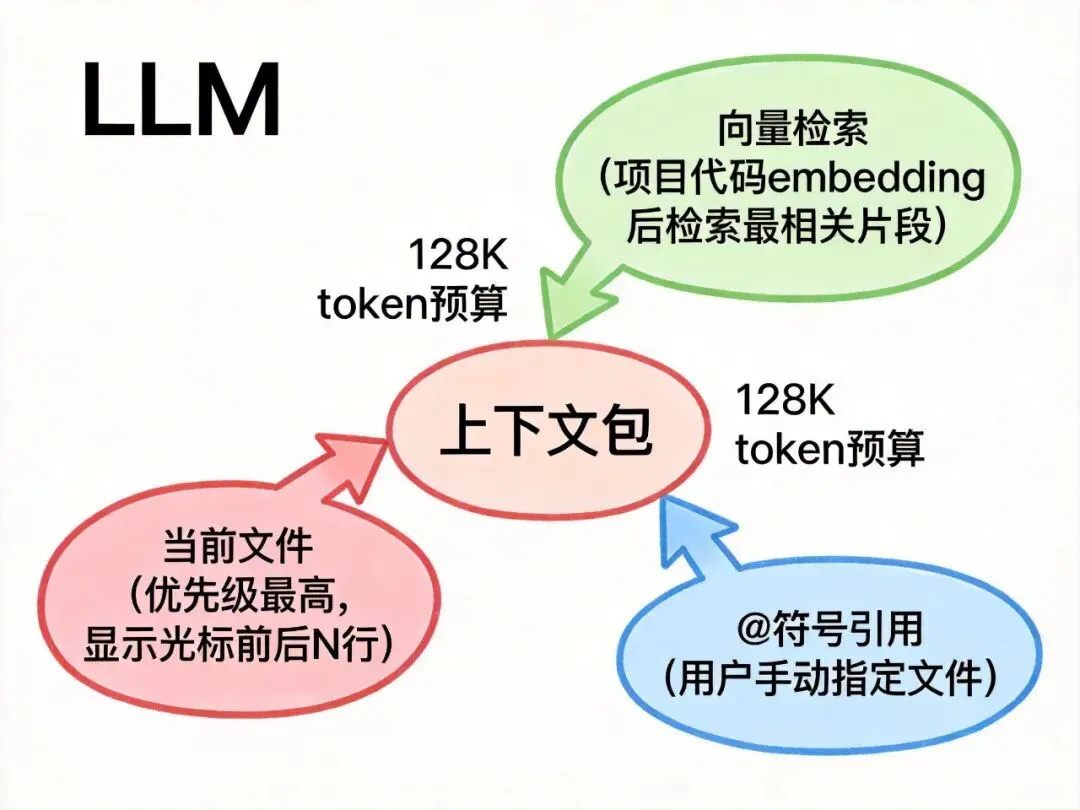
整个项目可能有 10 万行代码,但 context window 只有 128K tokens。怎么选?
Cursor 用了三种机制组合:
1. 当前文件 + 光标位置(必选)
// Cursor 构造上下文的伪代码
function buildContext(editor: Editor): ContextChunk[] {
const chunks: ContextChunk[] = [];
// 1. 当前文件必选,但不是全部——只取光标前后 N 行
const cursorLine = editor.getCursorLine();
chunks.push({
type: 'current_file',
content: editor.getLines(cursorLine - 100, cursorLine + 50),
priority: 10 // 最高优先级
});
return chunks;
}
2. 语义检索(Codebase Indexing)
Cursor 会在后台对整个项目做向量化索引,用的是类 RAG 的检索机制:
async function retrieveRelatedChunks(
query: string,
index: VectorIndex,
budget: number // token 预算
): Promise<ContextChunk[]> {
// 用用户的指令作为 query,检索语义相关的代码片段
const results = await index.search(query, { topK: 20 });
const selected: ContextChunk[] = [];
let usedTokens = 0;
for (const result of results) {
const tokenCount = estimate(result.content);
if (usedTokens + tokenCount > budget) break; // 超预算就停
selected.push(result);
usedTokens += tokenCount;
}
return selected;
}
3. @符号显式引用
你用 @file、@folder、@docs 时,是在手动注入上下文,优先级高于自动检索。
// 这是你实际能控制的部分
@src/utils/auth.ts 帮我把这个函数改成支持 OAuth2
核心:你的 @引用质量 = 你的上下文质量 = 你的输出质量。
Cmd+K 和 Chat 的区别:两种不同的上下文策略
很多人把 Cmd+K(inline edit)和 Chat 当成一回事。它们用的上下文策略完全不同。
Cmd+K(内联编辑)
上下文 = 选中代码 + 前后少量行 + 简短指令
目标 = 精准局部修改,token 用量极小
// Cmd+K 的上下文结构(简化版)
const inlineContext = {
selected: selectedCode, // 你框选的代码
before: codeBeforeCursor(30), // 前30行
after: codeAfterCursor(15), // 后15行
instruction: userInstruction, // 你打的那句话
// ⚠️ 注意:没有项目全局信息
};
Chat(对话模式)
上下文 = 历史对话 + 检索结果 + 显式引用 + 当前文件
目标 = 复杂推理、跨文件理解,token 用量大
// Chat 的上下文结构(简化版)
const chatContext = {
history: conversationHistory, // 历史对话(会被截断)
retrieved: await retrieveRelated(), // 向量检索结果
explicit: parseAtReferences(), // @引用的文件
currentFile: getCurrentFile(), // 当前打开的文件
};
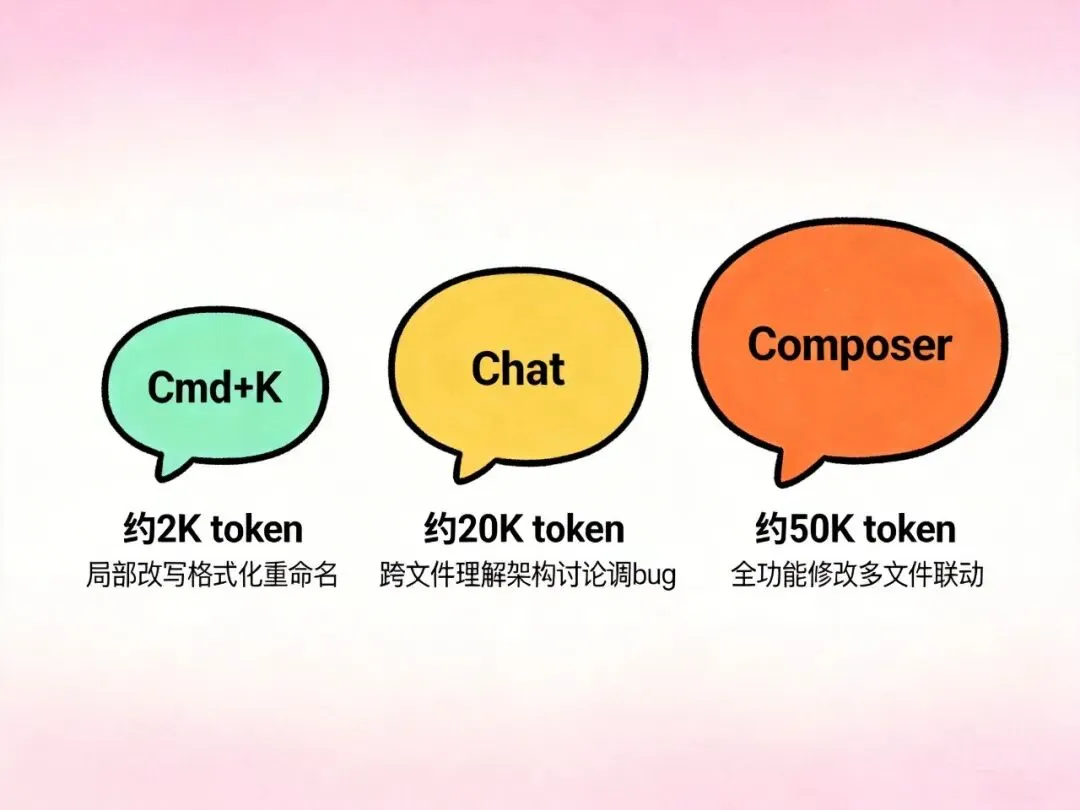
结论:小范围精确改用 Cmd+K,跨文件理解用 Chat + @引用。
| 功能 | Token 消耗 | 适用场景 |
|---|---|---|
| Cmd+K | 低(~2K) | 局部改写、格式化、重命名 |
| Chat | 高(~20K+) | 架构讨论、跨文件重构、调 bug |
| Composer | 最高(~50K+) | 全功能修改、多文件联动 |
Codebase Indexing:它如何「读懂」你的项目
这是 Cursor 的核心差异化能力。它不是真的「读懂」代码,而是做了向量化索引。
项目代码
↓ 分块(chunk by function/class/file)
↓ embedding(转换成向量)
↓ 存入本地向量数据库(类似 FAISS)
↓ 查询时:用自然语言 → 向量 → 找最近邻 → 返回代码片段
# 类似 Cursor 背后索引的简化实现
class CodebaseIndex:
def __init__(self, project_root: str):
self.chunks = []
self.embeddings = []
def index_file(self, file_path: str):
code = read_file(file_path)
# 按函数/类边界分块,不是按行数分块
chunks = split_by_ast(code)
for chunk in chunks:
embedding = embed(chunk.content) # 调 embedding API
self.chunks.append(chunk)
self.embeddings.append(embedding)
def search(self, query: str, top_k=10):
query_embedding = embed(query)
# 余弦相似度检索
scores = cosine_similarity(query_embedding, self.embeddings)
top_indices = scores.argsort()[-top_k:][::-1]
return [self.chunks[i] for i in top_indices]
重要细节:Cursor 的索引是本地存储的,不会把你的代码上传到云端做索引(官方承诺)。
diff 应用层:它怎么「改」你的代码
这层看起来简单,实际上有很多边界情况。
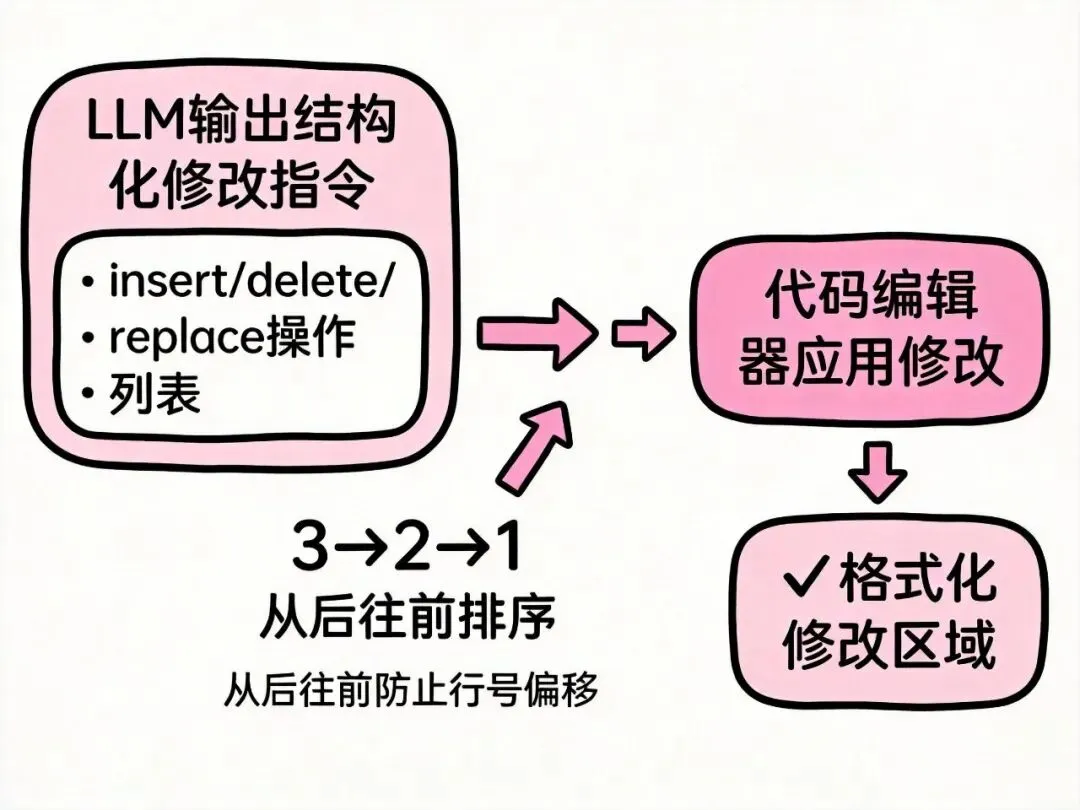
LLM 返回的不是「新代码」,而是结构化的修改指令:
// LLM 返回的 diff 格式(简化)
interface DiffEdit {
type: 'insert' | 'delete' | 'replace';
startLine: number;
endLine: number;
newContent: string;
}
// Cursor 应用 diff 的逻辑
async function applyDiff(editor: Editor, edits: DiffEdit[]) {
// 从后往前应用,防止行号偏移问题
const sorted = edits.sort((a, b) => b.startLine - a.startLine);
for (const edit of sorted) {
if (edit.type === 'replace') {
// 先删后插,保证原子性
editor.delete(edit.startLine, edit.endLine);
editor.insert(edit.startLine, edit.newContent);
}
}
// 格式化修改区域
await editor.format(affectedRange(edits));
}
从后往前应用 diff 是个关键细节——如果从前往后改,后面的行号会因为插入/删除而偏移,导致改错位置。
常见坑(踩过才知道)
坑1:大项目里 Cursor 突然变「笨」了
❌ 原因不是模型差了,是索引没建好或 context 被稀释了:
// 项目有 500 个文件,但只有 10 个和你的需求相关
// 向量检索可能返回了排名靠前但不相关的文件
✅ 解决:主动用 @file 指定相关文件,别指望自动检索:
@src/services/payment.ts @src/types/order.ts
帮我在 processOrder 里加一个超时重试逻辑
坑2:Cmd+K 改出来的代码「上下文断裂」
❌ 错误:框选一个函数改,但它依赖同文件其他函数的类型
// 只选了这个函数
function calculateTax(order: Order): number { ... }
// LLM 不知道 Order 类型在哪定义,可能乱猜
✅ 解决:框选范围包含相关类型定义,或用 Chat + @file 替代
坑3:对话历史太长,Cursor 开始「失忆」
❌ 一个 Chat 窗口用了 50 轮对话,早期的架构决策 AI 已经不记得了
✅ 重要项目每个功能开一个新 Chat,在开头用 @file 重新建立上下文:
@CLAUDE.md @src/architecture.md
我要开始做用户认证模块,先读一下项目约定
坑4:.cursorrules 写了等于没写
❌ cursorrules 太长太泛,AI 优先处理你的具体指令,规则被稀释:
// 100 行的 cursorrules,全是"使用 TypeScript""遵循 SOLID 原则"
// 效果基本等于没有
✅ cursorrules 只写项目特有的约定,越短越好,每条必须有具体场景:
- API 路由统一放 src/api/,不在组件里直接 fetch
- 错误处理统一用 Result<T, E> 类型,不 throw
- 数据库操作必须在 src/services/ 里,不在 controllers 里
坑5:Composer 模式下「改了 A 坏了 B」
❌ Composer 做多文件修改时,不会自动验证改动之间的一致性:
// 它改了 UserService 的接口,但没更新所有调用方
// 代码能 commit,但运行时报错
✅ Composer 用完后手跑 tsc --noEmit 类型检查,别直接信任:
# 让 Cursor 帮你写这个脚本,然后每次 Compose 后跑
tsc --noEmit && echo "✅ 类型检查通过" || echo "❌ 发现类型错误"
可收藏清单
-
小范围改用 Cmd+K,复杂任务用 Chat -
大项目必须手动 @file指定相关文件 -
每个功能开新 Chat,不要在一个窗口堆 50 轮对话 -
.cursorrules保持 < 30 行,只写项目特有约定 -
Composer 改完跑类型检查,不盲信输出 -
@docs引入库的文档,比 AI 凭印象写 API 更准 -
向量索引建好后才开始 Chat,首次打开项目等它索引完
总结
这篇我们从底层拆解了 Cursor 的工作原理:
-
四层架构:交互层 → 上下文构造层 → 模型路由层 → diff 写入层,中间两层才是核心壁垒 -
上下文构造:当前文件 + 向量检索 + @引用三合一,@引用的质量直接决定输出质量 -
Cmd+K vs Chat:前者低 token 精准改,后者高 token 复杂推理,用对场景省钱省时间 -
Codebase Indexing:本地向量数据库 + AST 分块,不是真的「读懂」代码,是相似度检索 -
diff 应用:从后往前应用防止行号偏移,是个工程细节但很关键
理解 Cursor 的核心是:你是在给一个只能读「情报简报」的侦探提供材料,你的 @引用就是情报质量。
下一篇我们进入 CLAUDE.md 实战——把项目的「潜规则」写进 AI 的记忆里,让每次打开项目 AI 都自动知道你们的约定,彻底告别反复交代背景的低效工作方式。
关注我,James 的成长日记,持续分享干货,帮你在 AI 时代少走弯路。