 夜雨聆风
夜雨聆风





Anthropic 的源码,是被自己的技术债搞崩的
事情是这样的。
2026年3月31号,安全研究员 Chaofan Shou 在 X 上发了一条帖子,大意是,Anthropic 把 Claude Code 的完整源码给放出去了。
不是被黑客攻击,不是内部员工泄密。
是他们自己在 npm 上发版本更新的时候,把一个 59.8MB 的 source map 调试文件打包进了生产包。这个文件里头,包含了 4756 个源文件的完整原始代码。任何人只要一行命令,就能把整个 Claude Code 的 TypeScript 源码还原出来。
51.2万行代码。
系统提示词、44 个功能开关、沙箱配置、安全验证逻辑,全在里面。
几个小时之内,代码被镜像到了好几个 GitHub 仓库,疯狂涨星。
Anthropic 赶紧发声明,说这是「人为错误导致的发布打包问题,不是安全漏洞」。
不是安全漏洞?
你把自家产品的完整源码公开了,然后告诉全世界这不是安全漏洞?
但说实话,我看完这个新闻之后,第一反应不是震惊。
是觉得,这事儿迟早会发生。
一个被忽视的真相。

我们聊 AI 编程工具的时候,所有人都在说效率、速度、10倍生产力。
没人聊技术债。
或者说,聊了,但没当回事。
2026年3月,中山大学和阿里巴巴联合发了一篇论文,首次用大规模数据量化了 AI 生成代码的质量问题。结论挺扎心的。
AI 生成的代码,模块间耦合度比人工代码高出 35%。
技术债务的积累速度是人类代码的 2 倍以上。
在边界条件处理、异常处理这些「细节」上,AI 代码的表现远低于人类平均水平。
还有另一组数据。arXiv 上有一篇论文叫「Debt Behind the AI Boom」,研究了真实世界中 AI 生成的代码。发现 AI 写的代码引入的问题中,89.1% 是代码异味,就是那种不会立刻报错但会让代码越来越难维护的东西。
更狠的是,有研究显示 AI 生成的代码到第二年,维护成本会飙升到正常的 4 倍。
4 倍。
你想想看,一个项目用 AI 写了一年代码,第二年光维护就要花掉原来 4 倍的时间和精力。第三年呢?没人敢算。
但这些数字,在「AI 让我效率提升了 300%」的叙事面前,显得特别苍白。
谁会在意两年后的事呢?先爽了再说。
软件的熵增定律。
物理学有个概念叫熵,说的是一个封闭系统的混乱程度只会增加,不会减少。除非你从外面输入能量去维持秩序。
软件也一样。
Lehman 软件演化定律里有一条,复杂软件系统需要持续修改才能保持相关性,而每一次修改都会增加系统的熵,除非你专门花力气去降低它。
注意这个「除非」。
大多数时候,我们不会专门花力气去降低熵。因为降低熵不产生新功能,不带来新收入,老板看不到 ROI。所以技术债就这么一点一点地堆上去。
以前还好,因为人类程序员写的代码虽然慢,但至少脑子里有个全局观。他知道改这个模块可能会影响那个模块,所以会谨慎一点。
AI 不一样。
AI 写代码的方式是,你给它一个需求,它生成一段代码。这段代码可能能跑,可能测试能过。但它不知道这个项目里还有哪些模块跟它有隐含的依赖关系。它不知道三个月前有人写了一个 hack,那个 hack 恰好依赖它现在要改的这个函数的某个边界行为。
它不知道,因为它没有全局记忆。
所以每一个 AI 生成的代码片段,都像一颗小小的定时炸弹。单独看都没问题,但它们之间的交互,没有人真正理解过。
蝴蝶效应。
你听说过蝴蝶效应吧。
一只蝴蝶在巴西扇动翅膀,可能在德克萨斯引发一场龙卷风。
软件系统里的蝴蝶效应比这个可怕得多。
一个微小的 bug,可能在系统里潜伏几个月甚至几年都不被发现。因为它只在某个非常特定的条件下才会触发,而这个条件在日常使用中几乎不会出现。
但随着时间推移,越来越多的代码被加进来,越来越多的模块被连接在一起,越来越多的隐含依赖被建立。那个特定条件被触发的概率,就在不知不觉中变大。
不是线性变大。
是指数级变大。
中山大学那篇论文里有一句话我印象特别深,「前期看似高效的修改,后期可能引发系统级雪崩」。
雪崩。
你想想雪崩是怎么发生的。
一开始只是一片雪花落在了一个不稳定的雪面上。然后又一片,又一片。每一片单独来看都微不足道。但它们在不断积累,直到某个临界点,整个雪面突然崩塌。
Claude Code 的源码泄露,其实就是一场雪崩。
只不过崩塌的不是代码,是流程。
2025年2月,Claude Code 预览版就因为同样的 source map 问题泄露过一次。那次泄露之后,正常来说应该做什么?
应该把这个检查加到 CI/CD 流程里,确保以后每次发布都自动检测 source map 文件有没有被误打包。
但 14 个月之后,同样的事情又发生了。
为什么?
因为修复这个问题的优先级不够高。它不产生新功能,不影响用户体验,不带来收入。在 Anthropic 的任务列表里,它可能排在一百名开外。
这就是技术债的真正代价。
它不是让系统变慢,不是让功能出错。它是让你在某个看似无关紧要的环节上,犯一个低级到不可思议的错误。而这个错误,恰好击穿了整个系统的防线。
审查的悖论。
你可能会说,那加强代码审查不就行了?
对,理论上是这样。
但现实是,代码审查这件事本身也在被 AI 侵蚀。
我自己的感受是,自从开始用 AI 写代码之后,我对代码的敬畏心明显下降了。以前自己一行一行敲的时候,每改一个函数都会想一想会不会影响别的地方。现在让 AI 生成一段代码,看着测试过了就提交了。
因为审查 AI 的代码太累了。
AI 生成的代码往往看起来非常规范,变量命名清晰,结构整齐,注释完善。你扫一眼觉得没问题。但真正的 bug 藏在逻辑深处,藏在边界条件里,藏在它跟其他模块的交互里。要发现这些 bug,你必须真正理解整个系统的架构。
但问题是,随着 AI 越来越多地参与代码生成,真正理解整个系统架构的人越来越少。
这是一个死循环。
AI 写了越来越多的代码 → 没有人能完全理解这些代码 → 审查变得越来越形式化 → 更多有隐患的代码被放行 → 系统越来越脆弱。
总有一天,会有人在一个他不完全理解的系统上,做一个他不完全理解的操作,然后整个系统就崩了。
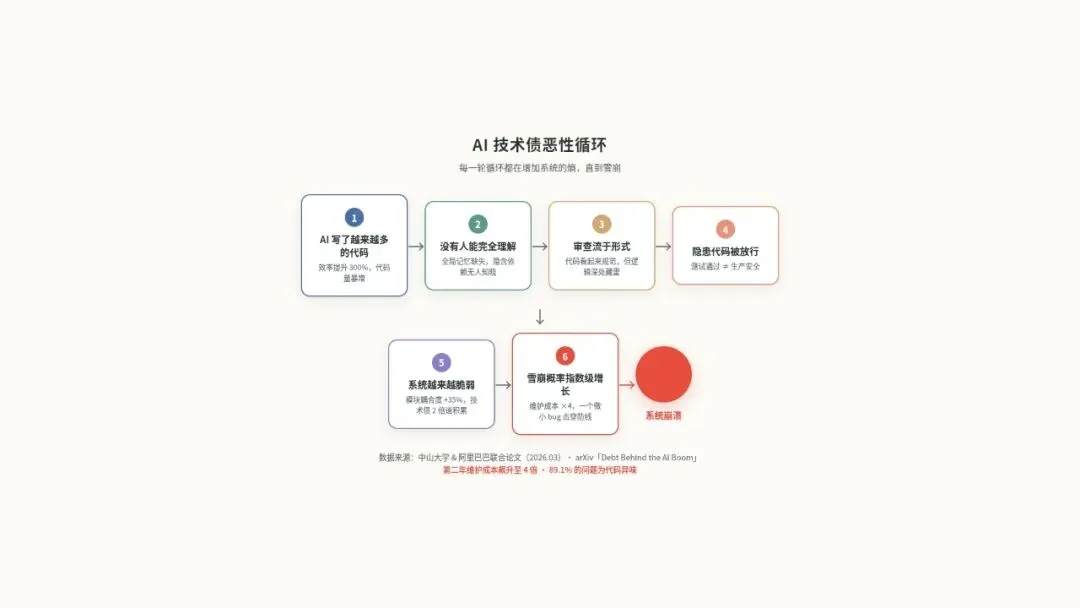
不是可能,是一定。
Anthropic 的讽刺。
回到 Claude Code 泄露这件事。
我觉得最讽刺的地方在于,Anthropic 是做 AI 安全的公司。
他们的使命是让 AI 安全可靠。他们的产品 Claude Code 是用来帮人写代码的 AI 工具。但恰恰是这个工具的源码,因为一个最基础的流程失误被公开了。
而且这不是第一次。
14 个月内,同样的错误犯了两次。
你说 Anthropic 没有能力避免这个问题吗?当然有。加一行 CI 检查就行了。
但他们没加。
为什么没加?因为技术债。
不是代码层面的技术债,是流程层面的技术债。第一次泄露之后,修复这个问题的工单可能被创建了,但优先级不够,被排到了后面。然后新的功能需求不断涌进来,旧的工单就沉下去了。
直到第二次泄露发生。
这跟 AI 写代码造成的技术债是同一个模式。每一个被推迟的修复,每一个被跳过的审查,每一个被忽略的边界条件,都在增加系统的熵。它们单独来看都不重要,但它们在积累。
然后某一天,一个 59.8MB 的 source map 文件被误打包进了生产包,半个互联网的源码就这么泄露了。
蝴蝶扇了一下翅膀。
龙卷风来了。
我们都在堆雪。
我最近一直在想一个问题。
当 AI 让写代码变得足够简单的时候,我们是不是正在进入一个「代码过剩」的时代?
以前写代码是瓶颈,所以代码量跟项目复杂度大致匹配。现在 AI 可以在几分钟内生成几百行代码,代码量的增长速度远远超过了人类理解能力的增长速度。
所以呢?
意味着每一行代码被真正理解的概率在降低。
意味着每一个 bug 被发现的概率在降低。
意味着系统的熵在加速增长。
我们正在用 AI 高效地堆雪。每一行代码都是一片雪花,单独看都很美,但它们正在形成一个越来越大的、越来越不稳定的雪面。
没有人知道哪一片雪花会触发雪崩。
但每个人都知道,雪崩一定会来。

Claude Code 的源码泄露只是一个缩影。一个做 AI 安全的公司,被自己流程中的技术债击穿了防线。如果 Anthropic 都挡不住,那些用 AI 写了成千上万行代码却连完整架构图都没有的创业公司呢?
那些让 AI 重构了三次代码却从来没有做过全面审查的项目呢?
那些代码库里 70% 的代码是 AI 生成的团队呢?
我不是在唱衰 AI 编程。
我自己每天都在用 Claude Code,用 Cursor,用各种 AI 工具。它们确实让我快了很多。
但我越来越觉得,AI 编程工具给了我们一把更锋利的铲子,让我们能更快地堆雪。但如果我们不花同样多的精力去理解、审查、维护这些雪,那雪崩就不是会不会发生的问题,而是什么时候发生的问题。
时间。流逝的本身。
只不过在软件的世界里,流逝的不是时间,是确定性。
如果你也在用 AI 写代码,这篇文章应该能帮你少踩一些坑。点个赞、转发给同事,他们可能正好需要。关注我,后面还会分享更多 AI 实战中的发现。
下次聊。