【实测】UI自动化用AI断言页面源码怎么搞?(下)
实测系列文章内容均为学员或粉丝实际工作中遇到的技术难点,这些问题各位工作中估计都用的到,先收藏一波等用的时候直接找到!
(本文跟别的攻略不同,会给大家写出思考的整个过程,而非直接给你结果,想锻炼测开思维的必看!就算AI大行其道,你如果连具体的思路都没有,只扔给AI一个粗略大需求,那最终的代码肯定也不行。甚至都生成不了,所以能用好AI的必然是也是懂代码和设计的。等待本功能全部开发完毕后会附赠源码哦~大家不着急用的不用自己照着图一个字母一个字母敲)
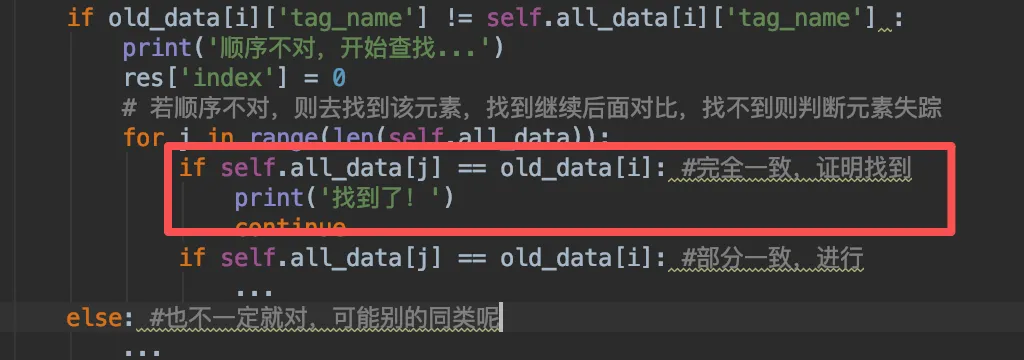
承接上篇,我们在对找到的元素进行逐个比对,刚刚解决了位置顺序变化了,但是可以找到的情况:
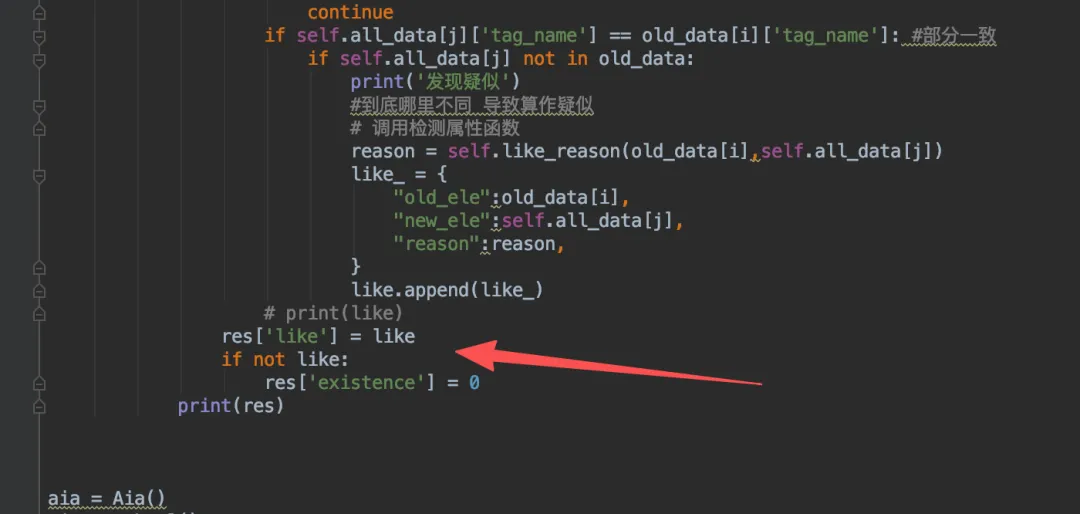
接下来,就是部分一致的情况,这种情况我们很难确保元素属性变化后还是否是之前的元素了,所以要统计出来后交给AI判断。那具体咱就暂时规定只要tag_name一样,就要进行仔细辨别并统计,如果这些疑似是其他的元素本体,那就跳过。只找到那些没人认领的新同类元素即可:
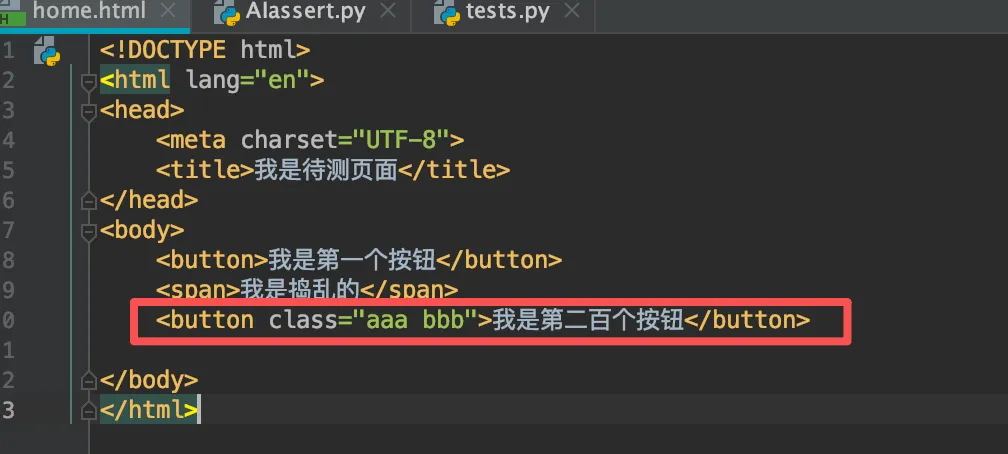
为此,我特意把这个顺序错了的元素:第二个按钮,稍微改了一改。
这里要有一定的测试思维进行辅助开发:这种相似的情况有多少种?我们就需要测试多少种,保证算法可以覆盖:
-
-
-
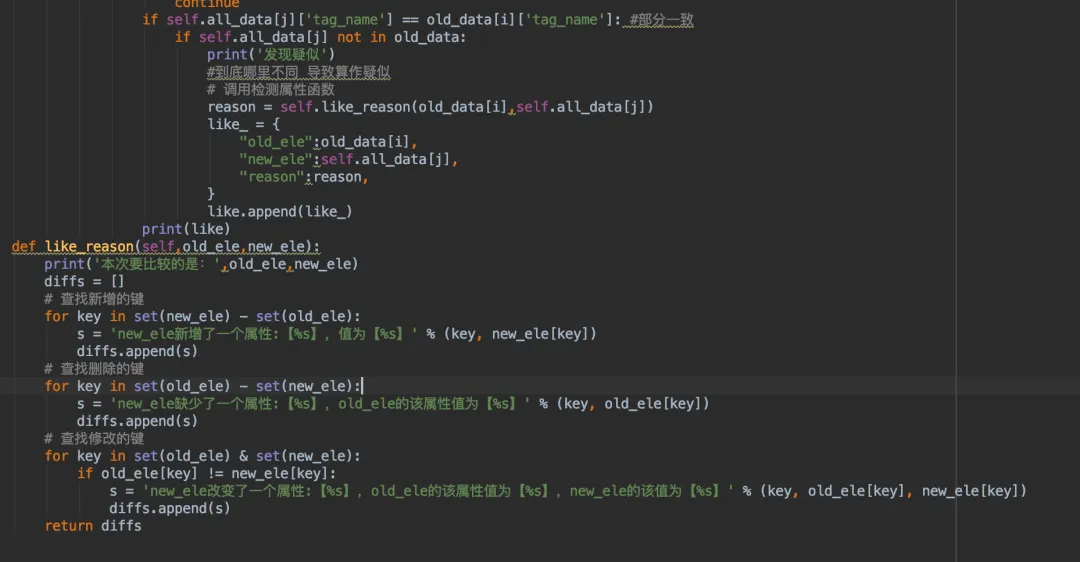
我使用了一个能检测出俩个元素具体有哪些不同的函数like_reason,结果应该是个列表,元素为字符串(后续可能会改),每段字符串阐述了具体不同的点。
为什么要单独拿出来这个比较函数呢?因为后面也会用到,比如顺序对位置对,但属性有变化的情况。
这里发现,其实已经实现了,并且结果都为AI可以看懂的清晰表达。like一直是空列表,当找到疑似后就记录了下来。
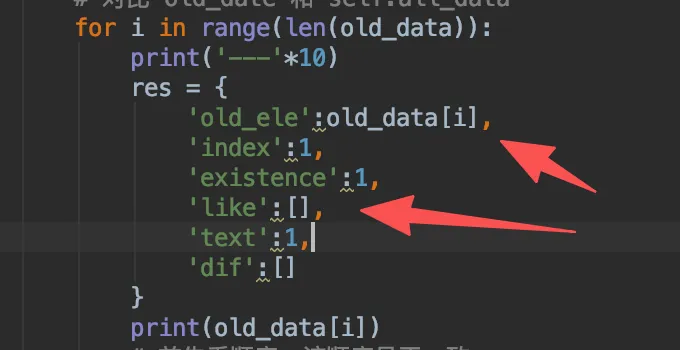
接下来就是,如果全都找完了,也没有个疑似的出现,那么就可以断定该元素无了,而针对该元素的最终结果res中,也要体现疑似的元素也就是like列表。到这里就简单了,我们只需要讨论下最终结果的收纳问题。我们把这个全页面断言功能进行记录到报告上的时候,应该把每一个断言的元素都记录上。但现在的res中,没法提现。所以我们要给res加上断言的old_ele是哪个。
注释掉很多无用的print后,运行一遍后,结果如下:
从中,我们可以明显看到,第三个元素的时候因为顺序变更(顺序会影响了path),导致内容多了不少,其中的index变成0,existence仍然1(这个要后面我们交给AI让AI判断它是否1),like列表充盈,展示了疑似的元素情况。这个列表要交给AI来判断决定existence的值。后面还有个text和dif,这是我们接下来要进行断言的俩个内容。
text为元素标签对中夹着的文案,dif则为标签内的具体属性。
 夜雨聆风
夜雨聆风