 夜雨聆风
夜雨聆风





Harness 工程之拆解 AI 编程助手(三):深入内核——那条指令背后,六个模块各司其职(2)
上下文压缩(context.py,197 行)
是什么
为什么需要三层
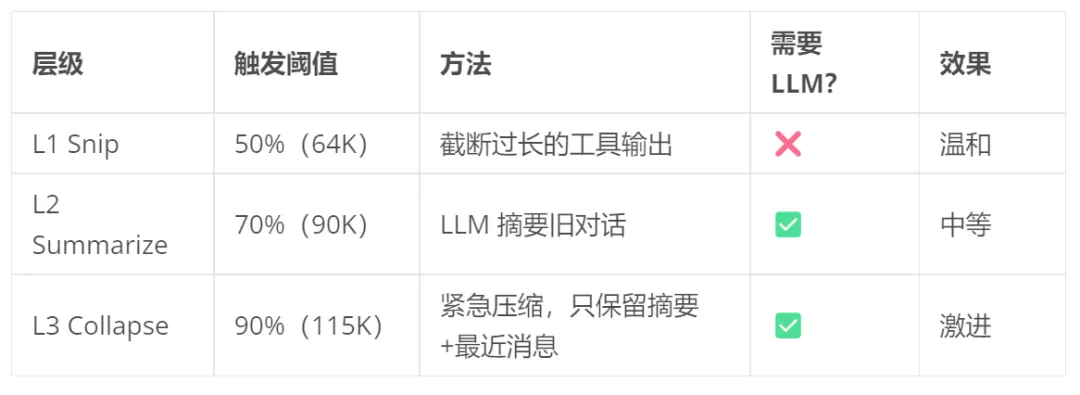
Layer 1: Snip(50% 阈值)
# corecoder/context.py:69-94@staticmethoddef _snip_tool_outputs(messages: list[dict]) -> bool:changed = Falsefor m in messages:if m.get("role") != "tool": # 只处理工具输出continuecontent = m.get("content", "")if len(content) <= 1500: # 短输出不用管continuelines = content.splitlines()if len(lines) <= 6: # 行数少的也不用管continue# 保留前 3 行 + 后 3 行snipped = ("\n".join(lines[:3])+ f"\n... ({len(lines)} lines, snipped to save context) ...\n"+ "\n".join(lines[-3:]))m["content"] = snippedchanged = Truereturn changed
Layer 2: Summarize(70% 阈值)
# corecoder/context.py:96-117def _summarize_old(self, messages: list[dict], llm: LLM | None,keep_recent: int = 8) -> bool:if len(messages) <= keep_recent:return Falseold = messages[:-keep_recent] # 旧消息(除最后 8 条)tail = messages[-keep_recent:] # 最近消息(最后 8 条)summary = self._get_summary(old, llm) # 用 LLM 生成摘要messages.clear()messages.append({"role": "user","content": f"[Context compressed - conversation summary]\n{summary}",})messages.append({"role": "assistant","content": "Got it, I have the context from our earlier conversation.",})messages.extend(tail)return True
# corecoder/context.py:135-161def _get_summary(self, messages: list[dict], llm: LLM | None) -> str:flat = self._flatten(messages)if llm:try:resp = llm.chat(messages=[{"role": "system","content": ("Compress this conversation into a brief summary. ""Preserve: file paths edited, key decisions made, ""errors encountered, current task state. ""Drop: verbose command output, code listings, ""redundant back-and-forth."),},{"role": "user", "content": flat[:15000]},],)return resp.contentexcept Exception:pass # LLM 摘要失败,走降级方案# 降级方案:用正则提取文件路径和错误信息return self._extract_key_info(messages)
# corecoder/context.py:173-196@staticmethoddef _extract_key_info(messages: list[dict]) -> str:import refiles_seen = set()errors = []for m in messages:text = m.get("content", "") or ""for match in re.finditer(r'[\w./\-]+\.\w{1,5}', text):files_seen.add(match.group())for line in text.splitlines():if 'error' in line.lower() or 'Error' in line:errors.append(line.strip()[:150])parts = []if files_seen:parts.append(f"Files touched: {', '.join(sorted(files_seen)[:20])}")if errors:parts.append(f"Errors seen: {'; '.join(errors[:5])}")return "\n".join(parts) or "(no extractable context)"
Layer 3: Hard Collapse(90% 阈值)
# corecoder/context.py:119-133def _hard_collapse(self, messages: list[dict], llm: LLM | None):tail = messages[-4:] if len(messages) > 4 else messages[-2:]summary = self._get_summary(messages[:-len(tail)], llm)messages.clear()messages.append({"role": "user","content": f"[Hard context reset]\n{summary}",})messages.append({"role": "assistant","content": "Context restored. Continuing from where we left off.",})messages.extend(tail)
压缩的入口:maybe_compress()
# corecoder/context.py:45-67def maybe_compress(self, messages: list[dict], llm: LLM | None = None) -> bool:current = estimate_tokens(messages)compressed = False# Layer 1: snip verbose tool outputsif current > self._snip_at:if self._snip_tool_outputs(messages):compressed = Truecurrent = estimate_tokens(messages) # 重新估算# Layer 2: LLM-powered summarizationif current > self._summarize_at and len(messages) > 10:if self._summarize_old(messages, llm, keep_recent=8):compressed = Truecurrent = estimate_tokens(messages) # 重新估算# Layer 3: hard collapseif current > self._collapse_at and len(messages) > 4:self._hard_collapse(messages, llm)compressed = Truereturn compressed
会话持久化(session.py,69 行)
是什么
怎么做
# corecoder/session.py:15-31def save_session(messages: list[dict], model: str, session_id: str | None = None) -> str:SESSIONS_DIR.mkdir(parents=True, exist_ok=True) # 确保 ~/.corecoder/sessions/ 存在if not session_id:session_id = f"session_{int(time.time())}" # 用时间戳生成 IDdata = {"id": session_id,"model": model,"saved_at": time.strftime("%Y-%m-%d %H:%M:%S"),"messages": messages,}path = SESSIONS_DIR / f"{session_id}.json"path.write_text(json.dumps(data, ensure_ascii=False, indent=2))return session_id
# corecoder/session.py:34-41def load_session(session_id: str) -> tuple[list[dict], str] | None:path = SESSIONS_DIR / f"{session_id}.json"if not path.exists():return Nonedata = json.loads(path.read_text())return data["messages"], data["model"]
系统提示词(prompt.py,34 行)
是什么
怎么做
# corecoder/prompt.py(完整代码)import osimport platformdef system_prompt(tools) -> str:cwd = os.getcwd()tool_list = "\n".join(f"- **{t.name}**: {t.description}" for t in tools)uname = platform.uname()return f"""\You are CoreCoder, an AI coding assistant running in the user's terminal.You help with software engineering: writing code, fixing bugs, refactoring,explaining code, running commands, and more.# Environment- Working directory: {cwd}- OS: {uname.system} {uname.release} ({uname.machine})- Python: {platform.python_version()}# Tools{tool_list}# Rules1. **Read before edit.** Always read a file before modifying it.2. **edit_file for small changes.** Use edit_file for targeted edits; write_fileonly for new files or complete rewrites.3. **Verify your work.** After making changes, run relevant tests or commands.4. **Be concise.** Show code over prose. Explain only what's necessary.5. **One step at a time.** For multi-step tasks, execute them sequentially.6. **edit_file uniqueness.** Include enough surrounding context in old_string.7. **Respect existing style.** Match the project's coding conventions.8. **Ask when unsure.** If the request is ambiguous, ask for clarification."""
