 夜雨聆风
夜雨聆风





ggml 源码剖析(cgraph)
编译调试
上堂课中,我漏掉了一个重要环节,就是 ggml 项目的编译与调试。
编译
还是在习惯的开发环境中操作,Windows 11 + Visual Studio 2022。
需要安装个 Cuda 开发环境,去官网下载自己显卡配套系统的版本即可。我安装的是 v13.1 版本。
啊对,我的 ggml 的版本是 0.9.7 版本。
剩下的交给 AI 完成,让它用 Cmake 生成基于 Cuda 的 VS2022 工程即可。
调试
像 GGML 正是一个深度依赖于底层数据结构和算法设计的机器学习项目。对其进行调试是很有必要的。
针对 GGML 这类底层机器学习项目进行调试,调试过程是深入理解数据结构和算法、了解其运行机制、验证正确性和发掘性能瓶颈的关键手段。
-
• 看透数据结构的实际运行状态和内存布局; -
• 锁定量化、自动微分等关键算法; -
• 解剖多线程与硬件优化代码的真实行为; -
• 缩短从“出现问题”到“理解问题”的认知距离。
这里我我们简单说一下几个工程的调试:simple-ctx 、simple-backend 、mnist-train、mnist-eval
-
• simple 相关工程 :是有最简单的 GGML 项目中的入门级示例程序。它的核心目的是用最少的代码,展示使用 GGML 库最基础的工作流程。对理解和调试 GGML 的基础数据结构(如 ggml_context、ggml_cgraph、ggml_backend)非常有帮助。上节课的内容,就是通过对 simple-ctx 工程的调试而来。 -
• mnist 相关工程 :是 GGML 中一个用于评估 MNIST 手写数字识别模型性能的完整示例工程。这里我简单描述一下 mnist-eval 、mnist-train、mnist-common 这三个工程。 如果你的**全连接网络(Fully Connected Network)或卷积神经网络(CNN)**了解的话,看其代码非常简单明了。
-
• mnist-common:公共基础设施 -
• mnist-train:模型训练 -
• mnist-eval:模型评估
这里搭建一下 mnist-eval 的开发环境,为调试学习做准备:
在项目个根目录由一个 requirements.txt 文件,里面描述了项目所有 Python 依赖,因此先要安装一下:
requirements.txt 文件中,有些小改动,要变更是 sentencepiece 从 ~=0.1.98 改为 0.2.0,因为旧版本无法在当前环境编译。
pip install -r requirements.txt
cd ./examples/mnist
python3 mnist-train-fc.py mnist-fc-f32.gguf gguf 文件可以在 Netron 中打开,查看非常方便,推荐使用!
模型和数据正常下载后,将 mnist-eval 的命令参数设置一下,为了方便这里将三个文件给了全路径:

但运行时还是会崩溃,查看代码发现,mnist_model 有析构函数,但没有禁止拷贝/定义安全移动,函数又按值返回,容易出现浅拷贝后释放原对象导致悬空指针(随后 tensor->op 读到脏值,就会触发你这个断言)。
因此修改 mnist-common.h 中代码:
...
structmnist_model {
std::string arch;
ggml_backend_sched_t backend_sched;
std::vector<ggml_backend_t> backends;
constint nbatch_logical;
constint nbatch_physical;
// 张量,表示输入图像数据,通常是一个二维张量,形状为 (MNIST_NINPUT, nbatch_physical),其中 MNIST_NINPUT 是每个图像的像素数量,nbatch_physical 是物理批次大小
structggml_tensor* images = nullptr;
// 张量,表示模型的输出,即每个类别的预测分数,通常是一个二维张量,形状为 (MNIST_NCLASSES, nbatch_physical),其中 MNIST_NCLASSES 是类别数量,nbatch_physical 是物理批次大小
structggml_tensor* logits = nullptr;
// 张量,表示全连接层 1 的权重,通常是一个二维张量,形状为 (MNIST_NINPUT, MNIST_NHIDDEN),其中 MNIST_NINPUT 是输入特征数量,MNIST_NHIDDEN 是隐藏层神经元数量
structggml_tensor* fc1_weight = nullptr;
// 张量,表示全连接层 1 的偏置,通常是一个一维张量,形状为 (MNIST_NHIDDEN,),其中 MNIST_NHIDDEN 是隐藏层神经元数量
structggml_tensor * fc1_bias = nullptr;
// 张量,表示全连接层 2 的权重,通常是一个二维张量,形状为 (MNIST_NHIDDEN, MNIST_NCLASSES),其中 MNIST_NHIDDEN 是隐藏层神经元数量,MNIST_NCLASSES 是类别数量
structggml_tensor * fc2_weight = nullptr;
// 张量,表示全连接层 2 的偏置,通常是一个一维张量,形状为 (MNIST_NCLASSES,),其中 MNIST_NCLASSES 是类别数量
structggml_tensor * fc2_bias = nullptr;
// 张量,表示卷积层 1 的权重,通常是一个四维张量,形状为 (MNIST_CNN_NCB, 1, 3, 3),其中 MNIST_CNN_NCB 是卷积层的通道基数,1 是输入通道数量(灰度图像),3 是卷积核的高度和宽度
structggml_tensor * conv1_kernel = nullptr;
// 张量,表示卷积层 1 的偏置,通常是一个三维张量,形状为 (MNIST_CNN_NCB, 1, 1),其中 MNIST_CNN_NCB 是卷积层的通道基数,1 是高度和宽度(每个通道一个偏置)
structggml_tensor * conv1_bias = nullptr;
// 张量,表示卷积层 2 的权重,通常是一个四维张量,形状为 (MNIST_CNN_NCB*2, MNIST_CNN_NCB, 3, 3),其中 MNIST_CNN_NCB*2 是卷积层的输出通道数量,MNIST_CNN_NCB 是输入通道数量,3 是卷积核的高度和宽度
structggml_tensor * conv2_kernel = nullptr;
// 张量,表示卷积层 2 的偏置,通常是一个三维张量,形状为 (MNIST_CNN_NCB*2, 1, 1),其中 MNIST_CNN_NCB*2 是卷积层的输出通道数量,1 是高度和宽度(每个通道一个偏置)
structggml_tensor * conv2_bias = nullptr;
// 张量,表示全连接层的权重,通常是一个二维张量,形状为 ((MNIST_HW/4)*(MNIST_HW/4)*(MNIST_CNN_NCB*2), MNIST_NCLASSES),其中 (MNIST_HW/4)*(MNIST_HW/4)*(MNIST_CNN_NCB*2) 是卷积层输出特征图的展平尺寸,MNIST_NCLASSES 是类别数量
structggml_tensor * dense_weight = nullptr;
// 张量,表示全连接层的偏置,通常是一个一维张量,形状为 (MNIST_NCLASSES,),其中 MNIST_NCLASSES 是类别数量
structggml_tensor * dense_bias = nullptr;
// gguf 上下文,表示用于加载和存储模型权重的上下文,通常包含模型权重的张量数据和相关信息
structggml_context* ctx_gguf = nullptr;
// ggml 上下文,表示用于静态分配模型权重和输入数据的上下文,通常包含模型权重和输入数据的张量数据和相关信息
structggml_context * ctx_static = nullptr;
// ggml 上下文,表示用于计算图构建和执行的上下文,通常包含计算图的张量数据和相关信息
structggml_context * ctx_compute = nullptr;
// 后端缓冲区,表示用于存储模型权重和输入数据的后端缓冲区,通常包含模型权重和输入数据的实际内存空间
ggml_backend_buffer_t buf_gguf = nullptr;
// 后端调度器,表示用于调度计算图执行的调度器,通常包含可用后端的信息和调度策略
ggml_backend_buffer_t buf_static = nullptr;
mnist_model(const std::string & backend_name, constint nbatch_logical, constint nbatch_physical)
: nbatch_logical(nbatch_logical), nbatch_physical(nbatch_physical) {
// ggml_backend_dev_t 是一个指向 ggml_backend_device 结构体的指针类型,表示一个物理设备,例如 CPU、GPU 或其他加速器设备。
std::vector<ggml_backend_dev_t> devices; // 物理设备列表
constint ncores_logical = std::thread::hardware_concurrency();
constint nthreads = std::min(ncores_logical, (ncores_logical + 4) / 2);
// Add primary backend:
if (!backend_name.empty()) {
// 通过设备名称获取对应的物理设备,如果设备不存在则打印错误信息并退出程序
ggml_backend_dev_t dev = ggml_backend_dev_by_name(backend_name.c_str());
if (dev == nullptr) {
fprintf(stderr, "%s: ERROR: backend %s not found, available:\n", __func__, backend_name.c_str());
for (size_t i = 0; i < ggml_backend_dev_count(); ++i) {
ggml_backend_dev_t dev_i = ggml_backend_dev_get(i);
fprintf(stderr, " - %s (%s)\n", ggml_backend_dev_name(dev_i), ggml_backend_dev_description(dev_i));
}
exit(1);
}
// 初始化指定设备的后端,如果初始化失败则断言失败
ggml_backend_t backend = ggml_backend_dev_init(dev, nullptr);
GGML_ASSERT(backend);
// 如果后端是 CPU 后端,则设置线程数量以优化性能
if (ggml_backend_is_cpu(backend)) {
ggml_backend_cpu_set_n_threads(backend, nthreads);
}
backends.push_back(backend); // 将初始化的后端添加到后端列表中
devices.push_back(dev); // 将对应的物理设备添加到设备列表中
}
// Add all available backends as fallback.
// A "backend" is a stream on a physical device so there is no problem with adding multiple backends for the same device.
// 添加所有可用的后端作为备用后端。一个“后端”是一个物理设备上的一个流,因此添加同一设备的多个后端没有问题。
for (size_t i = 0; i < ggml_backend_dev_count(); ++i) {
ggml_backend_dev_t dev = ggml_backend_dev_get(i); // 获取第 i 个物理设备
ggml_backend_t backend = ggml_backend_dev_init(dev, nullptr); // 初始化第 i 个设备的后端,如果初始化失败则断言失败
GGML_ASSERT(backend);
// 如果后端是 CPU 后端,则设置线程数量以优化性能
if (ggml_backend_is_cpu(backend)) {
ggml_backend_cpu_set_n_threads(backend, nthreads);
}
backends.push_back(backend); // 将初始化的后端添加到后端列表中
devices.push_back(dev); // 将对应的物理设备添加到设备列表中
}
// The order of the backends passed to ggml_backend_sched_new determines which backend is given priority.
// 排序传递给 ggml_backend_sched_new 的后端决定了哪个后端具有优先权。
backend_sched = ggml_backend_sched_new(backends.data(), nullptr, backends.size(), GGML_DEFAULT_GRAPH_SIZE, false, true);
fprintf(stderr, "%s: using %s (%s) as primary backend\n",
__func__, ggml_backend_name(backends[0]), ggml_backend_dev_description(devices[0]));
if (backends.size() >= 2) {
fprintf(stderr, "%s: unsupported operations will be executed on the following fallback backends (in order of priority):\n", __func__);
for (size_t i = 1; i < backends.size(); ++i) {
fprintf(stderr, "%s: - %s (%s)\n", __func__, ggml_backend_name(backends[i]), ggml_backend_dev_description(devices[i]));
}
}
{
constsize_t size_meta = 1024 * ggml_tensor_overhead(); // 获取元数据大小,通常是每个张量的开销乘以一个常数因子,这里是 1024
// 初始化 gguf 上下文,使用指定的元数据大小,并且不分配内存
structggml_init_params params = {
/*.mem_size =*/ size_meta,
/*.mem_buffer =*/nullptr,
/*.no_alloc =*/true,
};
ctx_static = ggml_init(params); // 初始化静态上下文,使用指定的元数据大小,并且不分配内存
}
{
// The compute context needs a total of 3 compute graphs: forward pass + backwards pass (with/without optimizer step).
// 计算上下文需要总共 3 个计算图:前向传播 + 反向传播(带/不带优化器步骤)。
constsize_t size_meta = GGML_DEFAULT_GRAPH_SIZE*ggml_tensor_overhead() + 3*ggml_graph_overhead();
structggml_init_params params = {
/*.mem_size =*/ size_meta,
/*.mem_buffer =*/nullptr,
/*.no_alloc =*/true,
};
ctx_compute = ggml_init(params); // 初始化计算上下文,使用指定的元数据大小,并且不分配内存
}
}
// 添加 mnist_model 的“禁拷贝 + 安全移动”语义。
mnist_model(const mnist_model &) = delete;
mnist_model & operator=(const mnist_model &) = delete;
mnist_model(mnist_model && other) noexcept
: arch(std::move(other.arch))
, backend_sched(other.backend_sched)
, backends(std::move(other.backends))
, nbatch_logical(other.nbatch_logical)
, nbatch_physical(other.nbatch_physical)
, images(other.images)
, logits(other.logits)
, fc1_weight(other.fc1_weight)
, fc1_bias(other.fc1_bias)
, fc2_weight(other.fc2_weight)
, fc2_bias(other.fc2_bias)
, conv1_kernel(other.conv1_kernel)
, conv1_bias(other.conv1_bias)
, conv2_kernel(other.conv2_kernel)
, conv2_bias(other.conv2_bias)
, dense_weight(other.dense_weight)
, dense_bias(other.dense_bias)
, ctx_gguf(other.ctx_gguf)
, ctx_static(other.ctx_static)
, ctx_compute(other.ctx_compute)
, buf_gguf(other.buf_gguf)
, buf_static(other.buf_static) {
other.backend_sched = nullptr;
other.images = nullptr;
other.logits = nullptr;
other.fc1_weight = nullptr;
other.fc1_bias = nullptr;
other.fc2_weight = nullptr;
other.fc2_bias = nullptr;
other.conv1_kernel = nullptr;
other.conv1_bias = nullptr;
other.conv2_kernel = nullptr;
other.conv2_bias = nullptr;
other.dense_weight = nullptr;
other.dense_bias = nullptr;
other.ctx_gguf = nullptr;
other.ctx_static = nullptr;
other.ctx_compute = nullptr;
other.buf_gguf = nullptr;
other.buf_static = nullptr;
}
mnist_model & operator=(mnist_model &&) = delete;
~mnist_model() {
ggml_free(ctx_gguf);
ggml_free(ctx_static);
ggml_free(ctx_compute);
ggml_backend_buffer_free(buf_gguf);
ggml_backend_buffer_free(buf_static);
ggml_backend_sched_free(backend_sched);
for (ggml_backend_t backend : backends) {
ggml_backend_free(backend);
}
}
...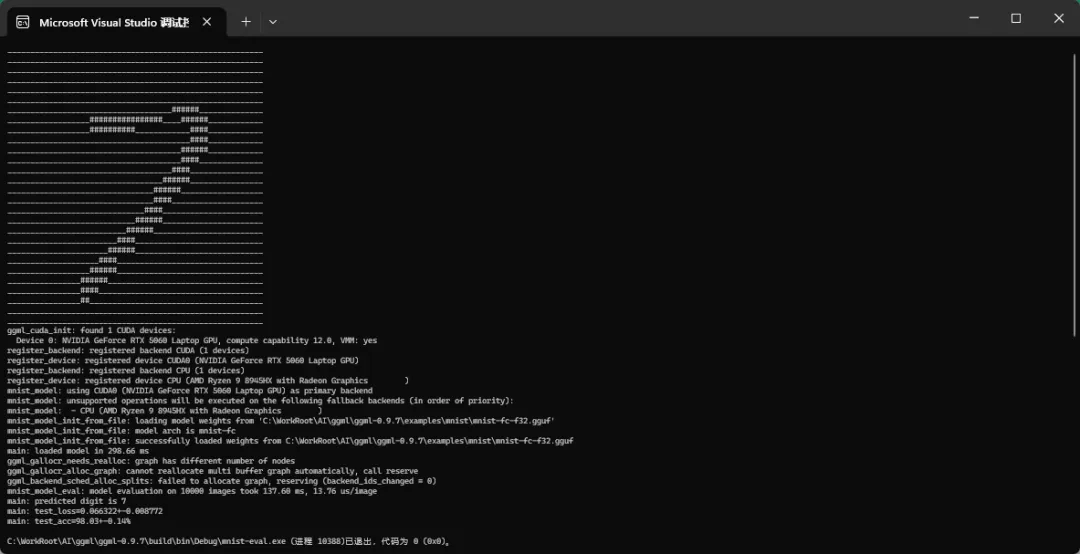
可以看出,运行使用了 Cuda,并且成功的识别出了数字 7。这样便可以调试程序啦~
说得 Cuda,CUDA 是今天 AI Infra 的“钢筋混凝土”——你可以抱怨它、绕开它,但盖起摩天大楼时,绕不开它。后续打算出一个 《Cuda 算子》的系列课程,来实现一些常用的函数算子,敬请期待~
源码剖析
计算图
计算图(Computational Graph) 是一种用有向无环图(DAG) 来表示数学计算过程的形式化方法。
计算图几乎出现在所有现代 AI 基础设施中 — 从 PyTorch、TensorFlow 到 GGML、TensorRT,底层都离不开它。
说到有向无环图,是不是已经不太陌生了,我在讲 Nanite 的时候专门有一节来讲解它,游戏引擎和人工智能中,数学有很多互通的地方,学好线性代数、微积分是必不可少的一环。
对象
GGML 中的一个对象可以是张量、计算图、工作缓冲区,其具体类型由 ggml_object_type 来决定:
ggml.h
enumggml_object_type {
GGML_OBJECT_TYPE_TENSOR, // 张量
GGML_OBJECT_TYPE_GRAPH, // 计算图
GGML_OBJECT_TYPE_WORK_BUFFER // 工作缓冲区
};ggml.c
// GGML 对象结构体,表示 GGML 中的一个对象(如张量、计算图等),包含对象的偏移、大小、类型等信息,并通过链表连接到其他对象
structggml_object {
size_t offs; // 对象在内存中的偏移
size_t size; // 对象的大小
structggml_object * next; // 指向下一个对象的指针
enumggml_object_type type; // 对象的类型
char padding[4]; // 填充字节,确保结构体大小为 32 字节
};
staticconstsize_t GGML_OBJECT_SIZE = sizeof(struct ggml_object);计算图
ggml_cgraph 是 GGML 库的核心数据结构,用于表示一个计算图 (Computation Graph)。
它是一个有向无环图 (DAG),其中节点代表张量数据(ggml_tensor),边代表张量之间的操作(ggml_op)。
GGML 采用了一种延迟计算模型,即先构建完整的计算图,然后再将其分派给后端(如 CPU、CUDA、Metal 等)进行一次性执行,这是其实现高效推理的关键所在。
// computation graph 计算图是一个有向无环图,表示张量之间的计算关系,其中节点表示计算操作,边表示张量数据流动的方向
// 计算图评估顺序枚举,表示在计算图中节点的评估顺序,可以是从左到右或从右到左
enumggml_cgraph_eval_order {
GGML_CGRAPH_EVAL_ORDER_LEFT_TO_RIGHT = 0, // 从左到右评估计算图中的节点,表示按照节点在计算图中的定义顺序进行评估
GGML_CGRAPH_EVAL_ORDER_RIGHT_TO_LEFT, // 从右到左评估计算图中的节点,表示按照节点在计算图中的反向顺序进行评估
GGML_CGRAPH_EVAL_ORDER_COUNT
};
// GGML 计算图结构体,表示一个计算图,其中包含节点、叶子、梯度和梯度累积器等信息
structggml_cgraph {
int size; // maximum number of nodes/leafs/grads/grad_accs // 表示计算图中节点、叶子、梯度和梯度累积器的最大数量
int n_nodes; // number of nodes currently in use // 表示计算图中当前使用的节点数量
int n_leafs; // number of leafs currently in use // 表示计算图中当前使用的叶子数量
// 节点是计算图中的基本单元,表示一个操作或函数,包含输入和输出张量等信息
structggml_tensor** nodes; // tensors with data that can change if the graph is evaluated
// 梯度是计算图中用于反向传播的张量,表示节点的梯度信息,用于计算参数更新
structggml_tensor ** grads; // the outputs of these tensors are the gradients of the nodes
// 梯度累积器是计算图中用于累积节点梯度的张量,表示在反向传播过程中用于累积梯度的张量
structggml_tensor ** grad_accs; // accumulators for node gradients
// 叶子是计算图中的基本单元,表示一个常量张量,包含数据等信息
structggml_tensor ** leafs; // tensors with constant data
int32_t* use_counts;// number of uses of each tensor, indexed by hash table slot // 表示每个张量的使用次数,使用哈希表槽进行索引
structggml_hash_set visited_hash_set; // 哈希集合,用于跟踪计算图中访问过的节点,避免重复访问
enumggml_cgraph_eval_order order; // 计算图的评估顺序,表示在计算图中节点的评估顺序,可以是从左到右或从右到左
};源码
计算图设计意图:显式的计算图表示,支持自动微分和优化。
我们看一下把图真正落到 ggml_cgraph(nodes[]/leafs[])的关键函数是:ggml_build_forward_expand(...)
实际填充函数:ggml_visit_parents_graph(...)把张量分类写入 cgraph->nodes 或 cgraph->leafs
ggml.c
// GGML 构建前向计算图
voidggml_build_forward_expand(struct ggml_cgraph * cgraph, struct ggml_tensor * tensor){
ggml_build_forward_impl(cgraph, tensor, true, true);
}
...
// GGML 构建前向计算图的实现
staticvoidggml_build_forward_impl(struct ggml_cgraph * cgraph, struct ggml_tensor * tensor, bool expand, bool compute){
if (!expand) {
// TODO: this branch isn't accessible anymore, maybe move this to ggml_build_forward_expand
ggml_graph_clear(cgraph);
}
constint n_old = cgraph->n_nodes;
// GGML 计算图的构建是通过访问输出节点的所有父节点来实现的,访问过程中会将每个访问到的节点添加到计算图中,并更新每个节点的使用计数。
ggml_visit_parents_graph(cgraph, tensor, compute);
constint n_new = cgraph->n_nodes - n_old;
GGML_PRINT_DEBUG("%s: visited %d new nodes\n", __func__, n_new);
if (n_new > 0) {
// the last added node should always be starting point
GGML_ASSERT(cgraph->nodes[cgraph->n_nodes - 1] == tensor);
}
}
// GGML 访问计算图中的父节点的实现
staticsize_tggml_visit_parents_graph(struct ggml_cgraph * cgraph, struct ggml_tensor * node, bool compute){
if (node->op != GGML_OP_NONE && compute) {
node->flags |= GGML_TENSOR_FLAG_COMPUTE;
}
// 访问计算图中的父节点的过程是通过递归调用 ggml_visit_parents_graph 函数来实现的。
// 每次访问一个节点时,首先检查该节点是否已经被访问过,如果没有,则将其添加到计算图中,并继续访问其父节点。
// 访问过程中还会更新每个节点的使用计数,以便后续在计算梯度时能够正确地处理共享子图的情况。
constsize_t node_hash_pos = ggml_hash_find(&cgraph->visited_hash_set, node); // 通过哈希表查找当前节点在计算图中的位置
GGML_ASSERT(node_hash_pos != GGML_HASHSET_FULL);
// 如果当前节点已经被访问过,则直接返回其在计算图中的位置,否则将其添加到计算图中,并继续访问其父节点。
if (ggml_bitset_get(cgraph->visited_hash_set.used, node_hash_pos)) {
// already visited
// 如果当前节点已经被访问过,并且 compute 标志为 true,则需要更新该节点的计算标志,并继续访问其父节点,以确保所有相关节点都被正确地标记为需要计算。
if (compute) {
// update the compute flag regardless
for (int i = 0; i < GGML_MAX_SRC; ++i) {
structggml_tensor* src = node->src[i]; // 访问当前节点的每个父节点
if (src && ((src->flags & GGML_TENSOR_FLAG_COMPUTE) == 0)) {
ggml_visit_parents_graph(cgraph, src, true);
}
}
}
return node_hash_pos;
}
// This is the first time we see this node in the current graph.
// 添加当前节点到计算图中,并将其标记为已访问。
cgraph->visited_hash_set.keys[node_hash_pos] = node;
ggml_bitset_set(cgraph->visited_hash_set.used, node_hash_pos); // 标记当前节点为已访问
cgraph->use_counts[node_hash_pos] = 0; // 初始化当前节点的使用计数为0
// 继续访问当前节点的每个父节点,并更新其使用计数,以便后续在计算梯度时能够正确地处理共享子图的情况。
for (int i = 0; i < GGML_MAX_SRC; ++i) {
constint k =
(cgraph->order == GGML_CGRAPH_EVAL_ORDER_LEFT_TO_RIGHT) ? i :
(cgraph->order == GGML_CGRAPH_EVAL_ORDER_RIGHT_TO_LEFT) ? (GGML_MAX_SRC-1-i) :
/* unknown order, just fall back to using i */ i;
// 访问当前节点的每个父节点,并更新其使用计数,以便后续在计算梯度时能够正确地处理共享子图的情况。
structggml_tensor * src = node->src[k];
if (src) {
constsize_t src_hash_pos = ggml_visit_parents_graph(cgraph, src, compute);
// Update the use count for this operand.
cgraph->use_counts[src_hash_pos]++; // 更新当前节点的每个父节点的使用计数,以便后续在计算梯度时能够正确地处理共享子图的情况。
}
}
// 将当前节点添加到计算图中,并根据其类型(叶子节点或非叶子节点)将其分别存储在计算图的 leafs 数组或 nodes 数组中,以便后续在计算梯度时能够正确地处理不同类型的节点。
if (node->op == GGML_OP_NONE && !(node->flags & GGML_TENSOR_FLAG_PARAM)) {
// reached a leaf node, not part of the gradient graph (e.g. a constant)
GGML_ASSERT(cgraph->n_leafs < cgraph->size);
// 如果当前节点是一个叶子节点,并且没有被标记为参数节点,则将其添加到计算图的 leafs 数组中,并根据需要为其生成一个默认名称,以便后续在计算梯度时能够正确地处理不同类型的节点。
if (strlen(node->name) == 0) {
ggml_format_name(node, "leaf_%d", cgraph->n_leafs);
}
cgraph->leafs[cgraph->n_leafs] = node;
cgraph->n_leafs++;
} else {
GGML_ASSERT(cgraph->n_nodes < cgraph->size);
// 如果当前节点是一个非叶子节点,或者被标记为参数节点,则将其添加到计算图的 nodes 数组中,并根据需要为其生成一个默认名称,以便后续在计算梯度时能够正确地处理不同类型的节点。
if (strlen(node->name) == 0) {
ggml_format_name(node, "node_%d", cgraph->n_nodes);
}
cgraph->nodes[cgraph->n_nodes] = node;
cgraph->n_nodes++;
}
return node_hash_pos;
}根据代码可以看出:
如何判断 leaf[] 还是 nodes[]:
-
• 若张量不是由图中算子计算得到(通常 op == GGML_OP_NONE),归为leaf[]。 -
• 若张量由某个算子产生(通常 op != GGML_OP_NONE),归为nodes[]。
调试
为了近一步了解计算图的拓扑排序,我们来调试一下 mnist-eval 工程,看一下手写数字识别模型生成的计算图关系。
在 mnist-eval 工程,main() 函数中调用关系非常简洁明了,主要函数有:
-
• 模型构建函数 mnist_model_build(...) -
• 评估模型函数 mnist_model_eval(...) -
• 评估结果函数 ggml_opt_result_xxx(...)
mnist-common.cpp
...
voidmnist_model_build(mnist_model & model){
if (model.arch == "mnist-fc") {
// 将全连接层的权重和偏置张量设置为模型参数,以便在计算图中使用它们进行前向传播计算
ggml_set_param(model.fc1_weight);
ggml_set_param(model.fc1_bias);
ggml_set_param(model.fc2_weight);
ggml_set_param(model.fc2_bias);
// 构建计算图,首先进行全连接层 1 的矩阵乘法和加法操作,然后应用 ReLU 激活函数,得到隐藏层的输出 fc1。
ggml_tensor * fc1 = ggml_relu(model.ctx_compute, ggml_add(model.ctx_compute,
ggml_mul_mat(model.ctx_compute, model.fc1_weight, model.images),
model.fc1_bias));
// 接着进行全连接层 2 的矩阵乘法和加法操作,得到最终的输出 logits。
model.logits = ggml_add(model.ctx_compute,
ggml_mul_mat(model.ctx_compute, model.fc2_weight, fc1),
model.fc2_bias);
} elseif (model.arch == "mnist-cnn") {
// 将卷积层和全连接层的权重和偏置张量设置为模型参数,以便在计算图中使用它们进行前向传播计算
ggml_set_param(model.conv1_kernel);
ggml_set_param(model.conv1_bias);
ggml_set_param(model.conv2_kernel);
ggml_set_param(model.conv2_bias);
ggml_set_param(model.dense_weight);
ggml_set_param(model.dense_bias);
// 构建计算图,首先将输入图像张量 images 进行形状调整,变为一个四维张量 images_2D,形状为 (MNIST_HW, MNIST_HW, 1, nbatch_physical),以适应卷积操作的输入要求。
structggml_tensor * images_2D = ggml_reshape_4d(model.ctx_compute, model.images, MNIST_HW, MNIST_HW, 1, model.images->ne[1]);
// 接着进行卷积层 1 的卷积操作,使用 conv1_kernel 作为卷积核,对 images_2D 进行卷积计算,并加上 conv1_bias 的偏置项,然后应用 ReLU 激活函数,得到卷积层 1 的输出 conv1_out。
structggml_tensor * conv1_out = ggml_relu(model.ctx_compute, ggml_add(model.ctx_compute,
ggml_conv_2d(model.ctx_compute, model.conv1_kernel, images_2D, 1, 1, 1, 1, 1, 1),
model.conv1_bias));
GGML_ASSERT(conv1_out->ne[0] == MNIST_HW);
GGML_ASSERT(conv1_out->ne[1] == MNIST_HW);
GGML_ASSERT(conv1_out->ne[2] == MNIST_CNN_NCB);
GGML_ASSERT(conv1_out->ne[3] == model.nbatch_physical);
// 然后对卷积层 1 的输出 conv1_out 进行池化操作,使用最大池化(GGML_OP_POOL_MAX)方式,池化窗口大小为 2x2,步幅为 2x2,无填充,得到卷积层 2 的输入 conv2_in。
structggml_tensor * conv2_in = ggml_pool_2d(model.ctx_compute, conv1_out, GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0);
GGML_ASSERT(conv2_in->ne[0] == MNIST_HW/2);
GGML_ASSERT(conv2_in->ne[1] == MNIST_HW/2);
GGML_ASSERT(conv2_in->ne[2] == MNIST_CNN_NCB);
GGML_ASSERT(conv2_in->ne[3] == model.nbatch_physical);
// 接着进行卷积层 2 的卷积操作,使用 conv2_kernel 作为卷积核,对 conv2_in 进行卷积计算,并加上 conv2_bias 的偏置项,然后应用 ReLU 激活函数,得到卷积层 2 的输出 conv2_out。
structggml_tensor * conv2_out = ggml_relu(model.ctx_compute, ggml_add(model.ctx_compute,
ggml_conv_2d(model.ctx_compute, model.conv2_kernel, conv2_in, 1, 1, 1, 1, 1, 1),
model.conv2_bias));
GGML_ASSERT(conv2_out->ne[0] == MNIST_HW/2);
GGML_ASSERT(conv2_out->ne[1] == MNIST_HW/2);
GGML_ASSERT(conv2_out->ne[2] == MNIST_CNN_NCB*2);
GGML_ASSERT(conv2_out->ne[3] == model.nbatch_physical);
// 然后对卷积层 2 的输出 conv2_out 进行池化操作,使用最大池化(GGML_OP_POOL_MAX)方式,池化窗口大小为 2x2,步幅为 2x2,无填充,得到全连接层的输入 dense_in。
structggml_tensor * dense_in = ggml_pool_2d(model.ctx_compute, conv2_out, GGML_OP_POOL_MAX, 2, 2, 2, 2, 0, 0);
GGML_ASSERT(dense_in->ne[0] == MNIST_HW/4);
GGML_ASSERT(dense_in->ne[1] == MNIST_HW/4);
GGML_ASSERT(dense_in->ne[2] == MNIST_CNN_NCB*2);
GGML_ASSERT(dense_in->ne[3] == model.nbatch_physical);
// 将池化后的张量 dense_in 进行形状调整,变为一个二维张量,以便与全连接层的权重矩阵进行矩阵乘法操作
dense_in = ggml_reshape_2d(model.ctx_compute,
ggml_cont(model.ctx_compute, ggml_permute(model.ctx_compute, dense_in, 1, 2, 0, 3)),
(MNIST_HW/4)*(MNIST_HW/4)*(MNIST_CNN_NCB*2), model.nbatch_physical);
GGML_ASSERT(dense_in->ne[0] == (MNIST_HW/4)*(MNIST_HW/4)*(MNIST_CNN_NCB*2));
GGML_ASSERT(dense_in->ne[1] == model.nbatch_physical);
GGML_ASSERT(dense_in->ne[2] == 1);
GGML_ASSERT(dense_in->ne[3] == 1);
// 最后进行全连接层的矩阵乘法和加法操作,得到最终的输出 logits。
model.logits = ggml_add(model.ctx_compute, ggml_mul_mat(model.ctx_compute, model.dense_weight, dense_in), model.dense_bias);
} else {
GGML_ASSERT(false);
}
ggml_set_name(model.logits, "logits"); // 将输出张量 logits 命名为 "logits",以便在计算图中识别和使用它
ggml_set_output(model.logits); // 将输出张量 logits 设置为模型的输出,以便在计算图执行时能够正确地获取和使用它的值
GGML_ASSERT(model.logits->type == GGML_TYPE_F32);
GGML_ASSERT(model.logits->ne[0] == MNIST_NCLASSES);
GGML_ASSERT(model.logits->ne[1] == model.nbatch_physical);
GGML_ASSERT(model.logits->ne[2] == 1);
GGML_ASSERT(model.logits->ne[3] == 1);
}
// 评估模型在给定数据集上的性能,计算损失和准确率等指标,并返回评估结果
ggml_opt_result_tmnist_model_eval(mnist_model & model, ggml_opt_dataset_t dataset){
ggml_opt_result_t result = ggml_opt_result_init();
// 设置优化器参数,包括计算上下文、输入输出张量、构建类型等,并初始化优化器上下文 opt_ctx,以便后续进行模型评估计算。
ggml_opt_params params = ggml_opt_default_params(model.backend_sched, GGML_OPT_LOSS_TYPE_CROSS_ENTROPY);
params.ctx_compute = model.ctx_compute; // 设置计算上下文为模型的计算上下文,即模型构建计算图时使用的上下文
params.inputs = model.images; // 设置输入张量为模型的 images 张量,即模型的输入数据
params.outputs = model.logits; // 设置输出张量为模型的 logits 张量,即模型的预测结果
params.build_type = GGML_OPT_BUILD_TYPE_FORWARD; // 设置构建类型为前向传播(GGML_OPT_BUILD_TYPE_FORWARD),表示在评估过程中只需要构建前向传播的计算图,而不需要构建反向传播的计算图,以节省计算资源和时间
// 优化器上下文 opt_ctx 用于存储模型评估计算的相关信息和状态,包括计算图、损失函数、优化器等,以便在后续进行模型评估计算时使用
ggml_opt_context_t opt_ctx = ggml_opt_init(params);
{
constint64_t t_start_us = ggml_time_us();
// 进行模型评估计算,调用 ggml_opt_epoch() 函数执行一个评估周期,传入优化器上下文 opt_ctx、数据集 dataset、评估结果 result,以及其他相关参数,以便计算模型在数据集上的性能指标,如损失和准确率等。
ggml_opt_epoch(opt_ctx, dataset, nullptr, result, /*idata_split =*/0, nullptr, nullptr);
constint64_t t_total_us = ggml_time_us() - t_start_us;
constdouble t_total_ms = 1e-3*t_total_us;
constint nex = ggml_opt_dataset_data(dataset)->ne[1];
fprintf(stderr, "%s: model evaluation on %d images took %.2lf ms, %.2lf us/image\n",
__func__, nex, t_total_ms, (double) t_total_us/nex);
}
ggml_opt_free(opt_ctx);
return result;
}
...在 ggml_opt_init() 函数初始化优化器调用里,能找到构建图结构的关键函数 ggml_build_forward_expand(...)。
ggml 的代码结构,越来越往 PyTorch 靠近啦,ggml_build_forward_expand(...) 是我们这次要调试的重点,看一看 mnist 模型的计算图的拓扑结构。
...
// 优化器上下文,包含优化器状态和计算图等信息。
ggml_opt_context_tggml_opt_init(struct ggml_opt_params params){
ggml_opt_context_t result = newstruct ggml_opt_context;
result->backend_sched = params.backend_sched;
result->ctx_compute = params.ctx_compute;
result->loss_type = params.loss_type;
result->build_type = params.build_type;
result->build_type_alloc = params.build_type;
result->inputs = params.inputs;
result->outputs = params.outputs;
result->opt_period = params.opt_period;
result->get_opt_pars = params.get_opt_pars;
result->get_opt_pars_ud = params.get_opt_pars_ud;
result->optimizer = params.optimizer;
GGML_ASSERT(result->opt_period >= 1);
result->static_graphs = result->ctx_compute;
if (!result->static_graphs) {
GGML_ASSERT(!result->inputs);
GGML_ASSERT(!result->outputs);
return result;
}
GGML_ASSERT(result->inputs);
GGML_ASSERT(result->outputs);
// 初始化计算图,构建前向传播图,后续根据build_type_alloc的不同可能会构建反向传播图和优化器图。
result->gf = ggml_new_graph_custom(result->ctx_compute, GGML_DEFAULT_GRAPH_SIZE, /*grads =*/true); // Forward pass.
// 前向传播图需要包含输入和输出节点,以便后续构建反向传播图和优化器图时能够正确地找到这些节点。
ggml_build_forward_expand(result->gf, result->outputs);
// 根据build_type_alloc构建计算图,构建过程中会根据需要分配张量和缓冲区。
ggml_opt_build(result);
return result;
}
...在调试之前还有些预备知识要简单讲一讲,从代码中加载模型可以看到,该模型区分为两种模型:
-
• 全连接网络(Fully Connected Network)全连接网络(Fully Connected Network, FCN)是神经网络中最基础的结构形式,通常指多层感知机(Multilayer Perceptron, MLP)。它的核心特征是层与层之间的神经元两两全部相连,即上一层的每个神经元都与下一层的每个神经元有连接权重。 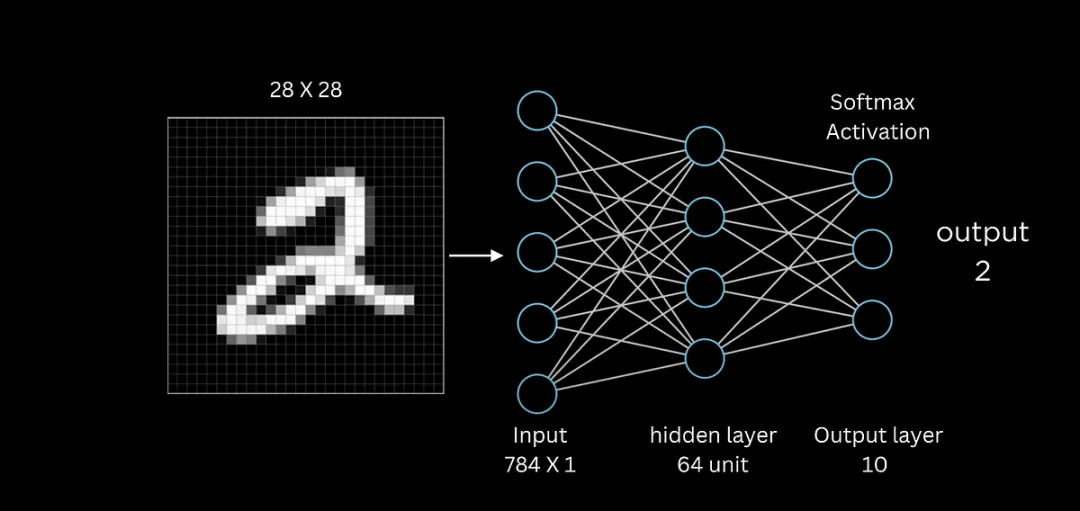
-
• 卷积神经网络(CNN)卷积神经网络(Convolutional Neural Network, CNN)是一种专门为处理网格结构数据(如图像、视频、语音频谱)而设计的深度学习模型。它通过局部连接和权重共享两大机制,极大减少了参数数量,并赋予网络对平移、缩放、旋转的一定鲁棒性。 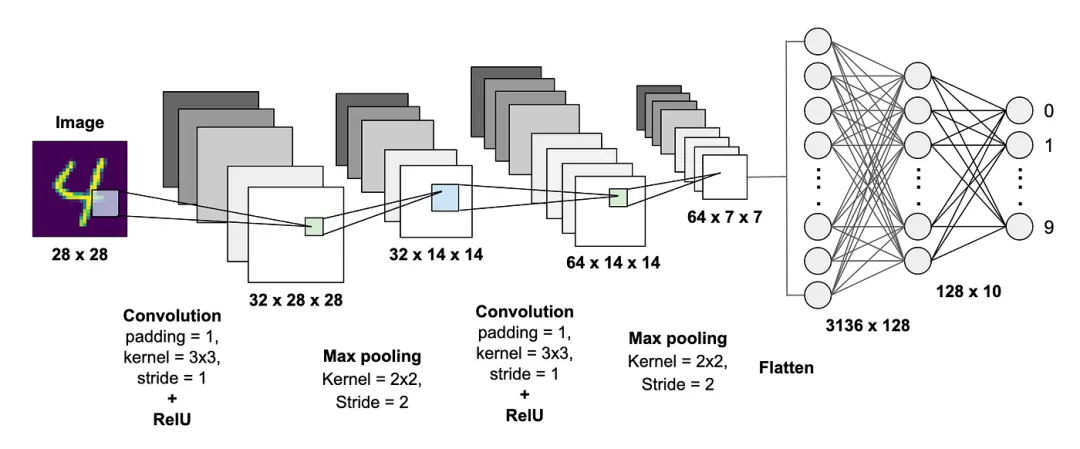
CNN 基本结构:
-
• 卷积层(Convolutional Layer)操作:卷积核与输入局部区域做内积,生成特征图(Feature Map)。参数:核尺寸(Kernel Size,如 3×3)、步长(Stride)、填充(Padding)、输出通道数(即卷积核个数)。效果:不同卷积核学习不同特征,浅层学边缘、角点,深层学复杂语义。 -
• 激活函数(Activation Function)通常使用 ReLU(Rectified Linear Unit),引入非线性,公式: -
• 池化层(Pooling Layer)最大池化(Max Pooling):取区域内的最大值。平均池化(Average Pooling):取区域内的平均值。作用:降维、扩大感受野、抑制过拟合。 -
• 全连接层(Fully Connected Layer)位于网络末端,将卷积提取的分布式特征映射到样本标记空间,完成分类/回归任务。现代架构常使用**全局平均池化(Global Average Pooling, GAP)**替代展平后的全连接层,进一步减少参数。
简单科普一下,回到正题,计算关系图,通过调试,模型是 mnist-fc 的,因此计算关系图简单很多:
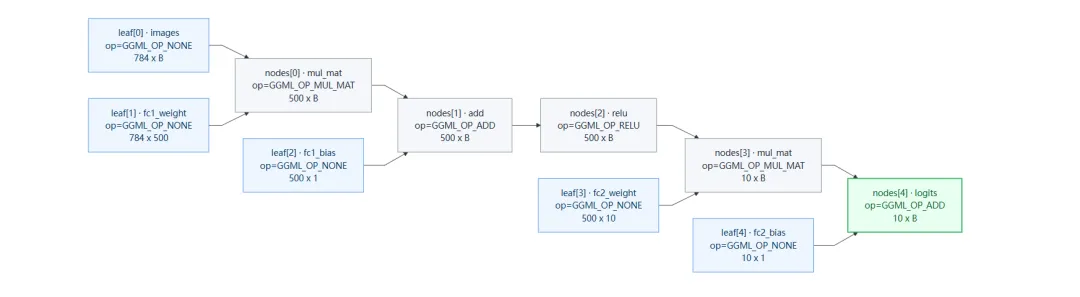
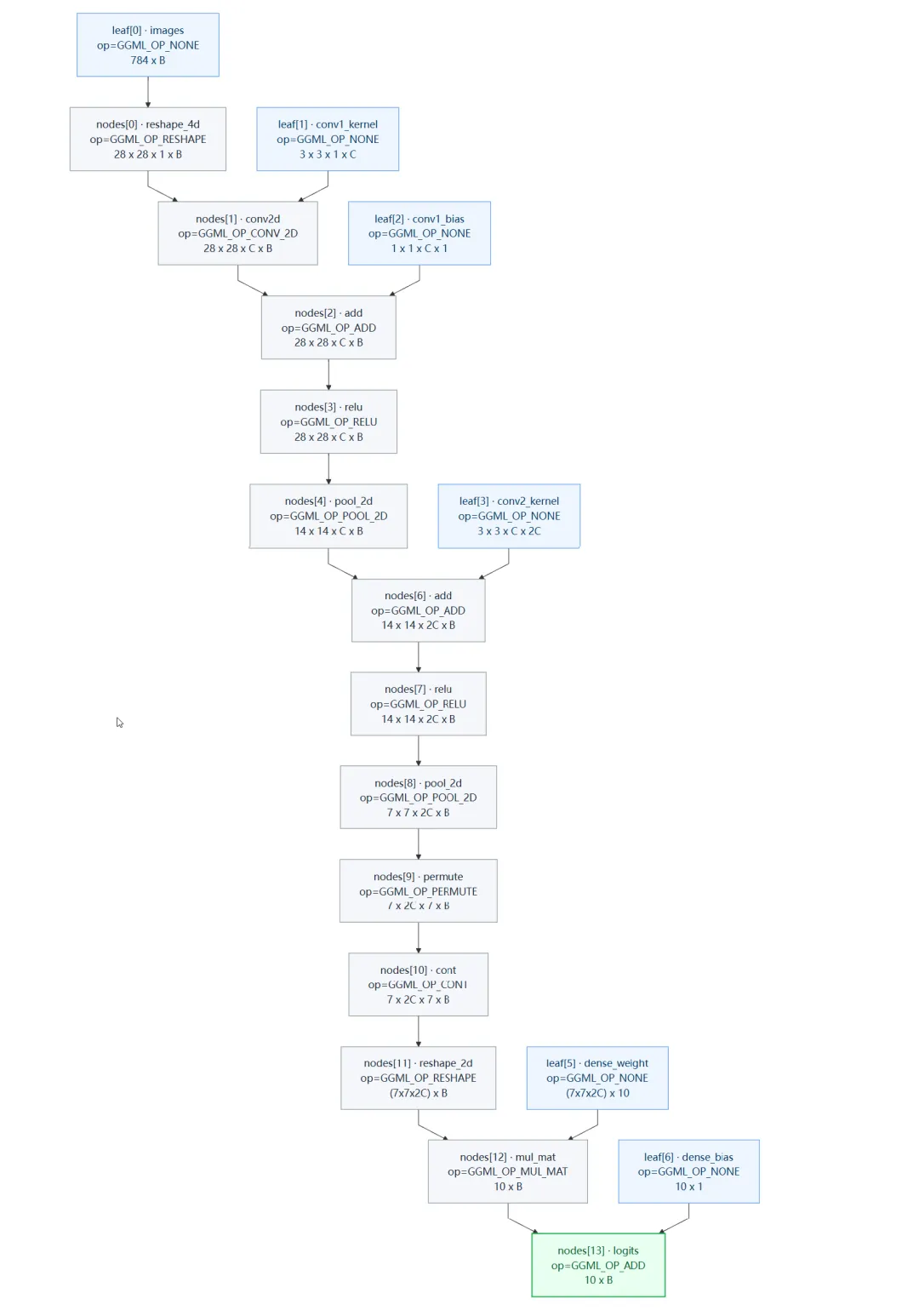
那如果模型是 mnist-cnn 的话,应该是什么样的呢?这里也提供了一下计算关系图供大家参考:
本篇内容不多,但是很重要,后面如果讲后端的内容就比较多啦!看看要不要拆分一下~