 夜雨聆风
夜雨聆风





MicroGPT 源码剖析(三):自动微分引擎 Autogard
源码之前,了无秘密。
《STL源码剖析》 By 侯捷
MicroGPT 是 AI 大佬 Andrej Karpathy 纯手搓的极简 GPT(Generative Pre-trained Transformer)实现——用 200 行纯 Python(无任何外部依赖)完成了完整的 Transformer 训练与推理流程。
-
一、MicroGPT 源码剖析(一):全局流程总览 Karpathy 200行 Python 代码实现的极简 GPT -
二、MicroGPT 源码剖析(二):预训练数据处理与分词器 -
三、自动微分引擎 Autograd -
四、模型架构详解 -
五、训练循环与优化器 -
六、推理与文本生成
-
什么是自动微分 -
为什么需要自动微分 -
全微分如何自动计算 -
自动微分引擎源码详解 -
总结
2017 年谷歌八位科学家联合发表一篇里程碑式机器学习论文《Attention Is All You Need》,提出 Transformer 架构,将残差连接(Residual Connection)从计算机视觉迁移到自然语言处理。
yabohe,公众号:yablog理解 LLM 的关键数学概念:残差 Residual
residual = y - f(x)
注:Loss 表示评价残差的某种数学函数。想了解更多残差可前往:理解 LLM 的关键数学概念:残差 Residual
2.2 如何使得 Loss 最小?梯度指引方向
当时正处晚年的麦克斯韦正在撰写他的旷世巨著《电磁通论》(1873年出版),他需要向世人解释法拉第的电磁理论。但他遇到了一个具体问题:电势(标量)的分布,是如何决定电场强度(矢量)的?不久后麦克斯韦发现,哈密顿发明的那个算子简直是为这个问题量身定制的:当把这个算子作用于电势场时,得到的结果正好指向电势下降最快的方向,其大小就是电场强度。
于是他写道:对于空间中任意一点的标量函数,我们可以找到它增加最快的方向和速率,我提议将这个矢量称为该标量函数的梯度(Gradient)。
yabohe,公众号:yablog理解 LLM 的关键数学概念:梯度 Gradient
Loss 损失函数一旦确定,问题就确定了:需要计算出预测值与预训练学习时的实际数据的差值(即损失值),这个 loss 值需要越小越好,而且越快收敛越好。
根据梯度篇(理解 LLM 的关键数学概念:梯度 Gradient)可知:梯度代表增长最快的方向,那么梯度相反的方向则是 loss 函数值下降最快的方向。
于是,计算loss值就转变成寻找梯度(然后取反)。
下面以二元函数为例说明:假设 Loss 目标函数为二元函数 z=f(x,y),它总的微分(即全微分)是由各个变量的偏微分相加而成的:
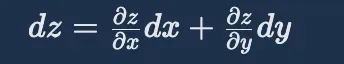
如果把上图中的这个二元全微分方程在对自变量 x 和 y 的偏导数都拎出来,形成一个向量,记为 ∇f(x,y) :
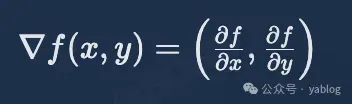
这便是梯度的数学表示(谨记:梯度是一个向量)。
所以,全微分 dz 可以表示为:
dz = ∇f(x,y) · (dx,dy) 再根据内积原理(理解 LLM 的关键数学概念:内积),当 (dx, dy) 移动方向与梯度 ∇f(x,y) 方向一致时,dz 的值最大。
dz = ∇f(x,y) · (dx,dy)dz = |∇f(x,y)|·|(dx,dy)|cos(θ)
-
应该往哪个方向调整:梯度反方向
-
调整多少:学习率 × 梯度(再加上优化器如 Adam 的缩放)
注:如果梯度是告诉我们“往哪走“,学习率决定“走多远”。
3、全微分如何自动计算
L(x,y) = (x*y +2)²∇f(x,y) = (fx, fy)然后,将函数拆开
x, y↓a = x * y↓b = a + 2↓L = b²
对应的链式结构为:
x,y -> a -> b -> L接着,前向计算(Forward)
# 假设:x = 3, y = 4#逐步算:a = x*y = 12b = a+2 = 14L = b² = 196
然后,反向传播(Backward)





-
x_new = 3 – 0.01*112 = 1.88 -
y_new = 4 – 0.01*84 = 3.16
L(a,b,c) = (a * b + c)²# 二元乘法d = a * b# 二元加法e = d + c# 一元幂(指数 2 为常数)L = e²


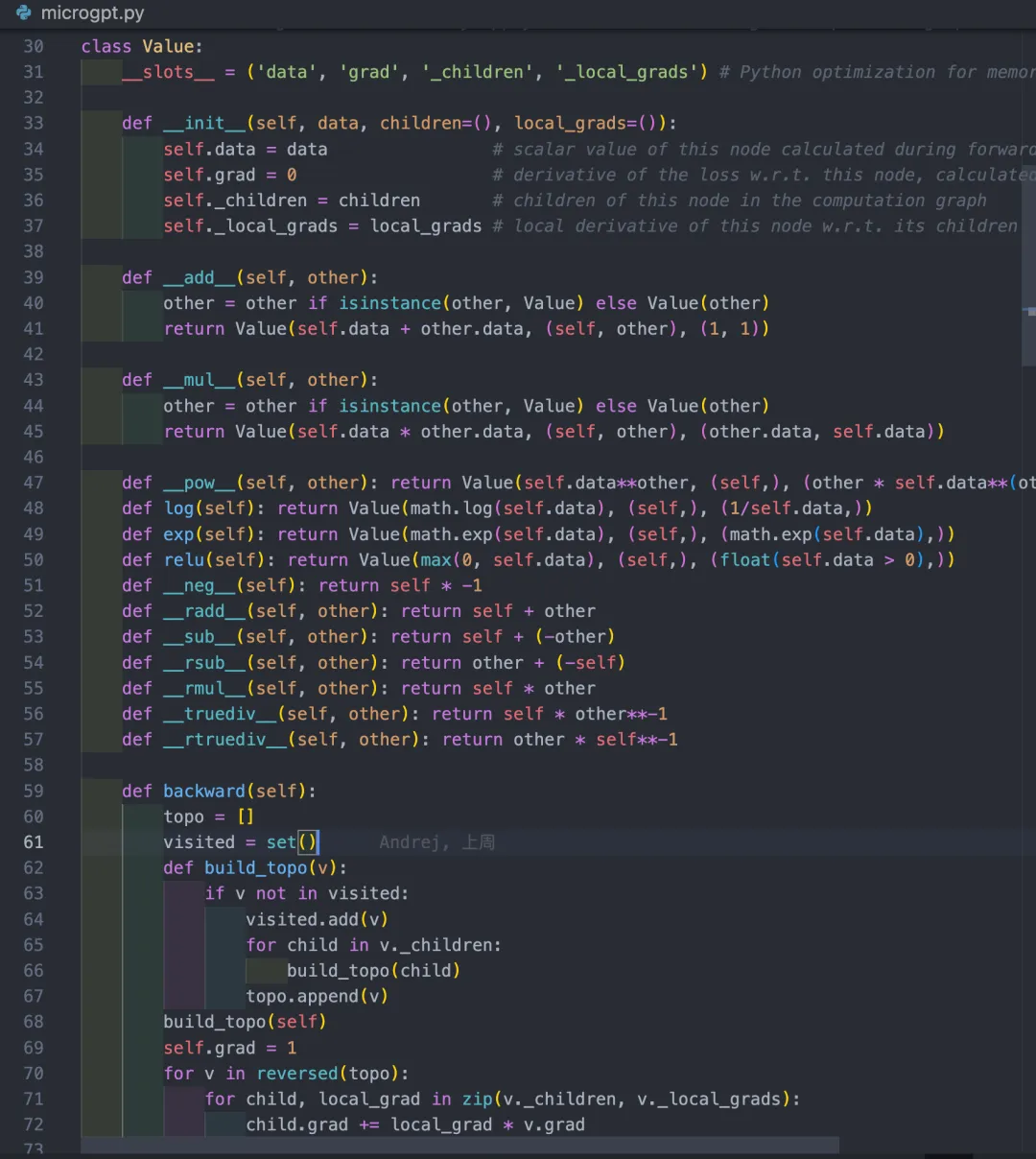
# =============================================================================# 计算图示例(贯穿全文的 L = (a·b + c)²,取 a=2, b=3, c=4)## a(data=2) b(data=3) c(data=4)# \ / |# local=b=3 local=a=2 local=1# \ / |# d(data=6) ───── local=1 ───┐ |# ├──► e(data=10)# │# local=2e=20# │# ▼# L(data=100)## 前向:自底向上算 data# 反向:自顶向下传 grad(链式法则:child.grad += local_grad * v.grad)# =============================================================================# ---- 自动微分引擎:让每个数字"记住"自己是怎么被算出来的 ----# 整个类只做两件事:# 1. 前向时算出数值,顺手建立计算图(_children + _local_grads)# 2. 反向时沿图的拓扑逆序,用链式法则把梯度传回每个叶子class Value:# Python 性能优化:禁用 __dict__,只允许这 4 个属性# 好处:每个实例节省 ~100 字节内存 + 属性访问更快# 代价:不能随意给实例添加新属性(如 self.label = "loss" 会报错)# 训练时会创建几百万个 Value 节点,这个优化非常值得__slots__ = ('data', 'grad', '_children', '_local_grads')# data : 前向计算出的标量值,如 d.data = 6# children : 计算图中本节点的直接依赖(子节点),如 d._children = (a, b)# local_grads: 本节点对每个 child 的局部偏导 ∂self/∂child,如 d._local_grads = (b=3, a=2)# 注意:这是局部导数,不是全局导数 ∂L/∂child!# 局部导数在前向时就能算出来,全局导数要等反向传播才知道def __init__(self, data, children=(), local_grads=()):# 前向值(标量)。例:Value(6).data == 6self.data = data# 全局梯度 ∂L/∂self,初始化为 0# 反向传播时通过 += 累加# 每次训练 step 结束后必须手动清零(见 microgpt.py 第 182 行 p.grad = 0)self.grad = 0# 本节点的 children 元组。叶子节点(用户创建的参数)默认为空 ()# 例:d = a * b 时,d._children = (a, b)self._children = children# 局部导数元组,长度必须与 _children 一致(backward 里用 zip 配对)# 例:d = a * b 时,d._local_grads = (b.data, a.data) = (3, 2)# 含义:∂d/∂a = b = 3,∂d/∂b = a = 2self._local_grads = local_grads# ======================== 二元运算 ========================# 加法:y = self + other# 数学:∂(a+b)/∂a = 1,∂(a+b)/∂b = 1# 所以 _local_grads = (1, 1),加法的局部导数永远是 1def __add__(self, other):# 参数归一化:允许写 x + 1 而不必 x + Value(1)# 如果 other 不是 Value,自动包装成叶子节点(children=(), local_grads=())other = other if isinstance(other, Value) else Value(other)# 返回新节点(不是 in-place 修改!保持计算图为 DAG)# 参数1: 前向值 = self.data + other.data# 参数2: children = (self, other),记录"我是谁算出来的"# 参数3: local_grads = (1, 1),∂y/∂self = 1, ∂y/∂other = 1return Value(self.data + other.data, (self, other), (1, 1))# 乘法:y = self * other# 数学:∂(a·b)/∂a = b,∂(a·b)/∂b = a# 注意 _local_grads 是 (other.data, self.data)——"交叉"存储!# 因为 _children[0]=self 对应的局部导数是 ∂y/∂self = other,排第 0 位# _children[1]=other 对应的局部导数是 ∂y/∂other = self,排第 1 位def __mul__(self, other):other = other if isinstance(other, Value) else Value(other)return Value(self.data * other.data, (self, other), (other.data, self.data))# ======================== 一元运算 ========================# 以下 4 行每行都是一个完整的运算定义# 结构统一:Value(前向结果, (self,), (局部导数,))# 注意 (self,) 的尾随逗号——是单元素元组的必要写法,没有逗号就不是元组# 幂运算:y = self^other(other 必须是普通 Python 数字,不能是 Value)# 数学:d/da (a^n) = n · a^(n-1)(幂法则)# 例:e**2 的局部导数 = 2 · e^(2-1) = 2e = 20(在示例中 e=10)# 约束:不支持 Value**Value(否则还需要 ∂(a^b)/∂b = a^b·ln(a),代码未处理)def __pow__(self, other): return Value(self.data**other, (self,), (other * self.data**(other-1),))# 自然对数:y = ln(self)# 数学:d/da (ln a) = 1/a# 要求 self.data > 0,否则 math.log 会抛异常# 用途:交叉熵损失函数 -Σ y·log(ŷ) 中的 logdef log(self): return Value(math.log(self.data), (self,), (1/self.data,))# 指数函数:y = e^self# 数学:d/da (e^a) = e^a(指数函数的导数等于自身)# math.exp(self.data) 被计算了两次(前向值和局部导数),# 可以优化为 e = math.exp(self.data); return Value(e, (self,), (e,))# 但为了代码极简,保留了当前写法# 用途:Softmax 中的 exp(x_i)def exp(self): return Value(math.exp(self.data), (self,), (math.exp(self.data),))# ReLU 激活函数:y = max(0, self)# 数学:分段导数 —— self>0 时为 1,self≤0 时为 0# float(True)=1.0, float(False)=0.0,一行搞定分段# self=0 处严格不可导,这里按惯例取 0(次梯度 subgradient),工程上完全可用def relu(self): return Value(max(0, self.data), (self,), (float(self.data > 0),))# ======================== 派生运算符 ========================# 以下 7 个运算通过组合上面的原子运算实现,不需要独立推导梯度# 自动微分的组合性保证:只要原子运算的局部导数正确,组合出来的梯度自动正确# 取负:-a = a * (-1),复用 __mul__def __neg__(self): return self * -1# 反向加法:当 Python 执行 2 + x 时,先尝试 (2).__add__(x) 失败,# 再尝试 x.__radd__(2);利用加法交换律直接返回 self + otherdef __radd__(self, other): return self + other# 减法:a - b = a + (-b),复用 __add__ + __neg__def __sub__(self, other): return self + (-other)# 反向减法:b - a(b 非 Value)= other + (-self)def __rsub__(self, other): return other + (-self)# 反向乘法:利用乘法交换律def __rmul__(self, other): return self * other# 除法:a / b = a · b^(-1),复用 __mul__ + __pow__(指数为 -1 是普通数字,合法)def __truediv__(self, other): return self * other**-1# 反向除法:b / a = b · a^(-1)def __rtruediv__(self, other): return other * self**-1# ======================== 反向传播 ========================# 这 14 行是整个文件的心脏:沿计算图的拓扑逆序,用链式法则把梯度从 L 传回每个叶子def backward(self):# ---------- 第一步:拓扑排序(后序 DFS)----------# 目的:生成一个节点列表 topo,满足"任何节点都排在它的父节点前面"# reversed 后就变成"父节点先处理"——反向传播需要的顺序topo = [] # 排序结果容器visited = set() # 防止 DAG 中一个节点被多个父引用时重复访问def build_topo(v):if v not in visited: # 剪枝:已访问的节点跳过visited.add(v) # 标记已访问(用对象 id 做哈希,天然唯一)for child in v._children:build_topo(child) # 先递归处理所有子节点# ★ 关键:append 放在递归之后(后序遍历)# 保证所有子孙先入列,自己最后入列# reversed 后自己就排在前面——反向时先处理# 如果把 append 放在递归之前,反向时叶子会先被处理,# 但那时叶子的 .grad 还是 0(种子还没传到),整个反向传播失效topo.append(v)# 从当前节点(通常是 loss)开始构建拓扑序build_topo(self)# ---------- 第二步:种子梯度 ----------# 数学:∂L/∂L = 1(自己对自己的导数恒为 1)# 这是反向传播的"第一块多米诺骨牌"# 如果改成 2,所有梯度整体放大 2 倍(等效学习率翻倍)# 如果删掉这行(.grad 默认 0),所有乘法都乘 0,反向传播完全失效self.grad = 1# ---------- 第三步:反向循环 = 链式法则 ----------# 从 L 开始(reversed 后的第一个),沿拓扑逆序往源头走for v in reversed(topo):# 对当前节点 v 的每个 child,把 v 对 child 的"责任"分发下去# zip 保证 child 和对应的局部导数一一配对for child, local_grad in zip(v._children, v._local_grads):# ★ 整段代码的灵魂——链式法则的代码形式:# child.grad(∂L/∂child,全局) += local_grad(∂v/∂child,局部) * v.grad(∂L/∂v,上游全局)## 为什么是 += 而不是 = ?# 因为一个 child 可能被多个父节点引用(如 y = a*a 中 a 出现两次),# 每条路径各自贡献一份梯度,必须全部累加(多元链式法则的 Σ)# 如果用 =,后一条路径会覆盖前一条,结果错误## 示例(访问 d,d.grad=20):# d._children = (a, b), d._local_grads = (3, 2)# a.grad += 3 * 20 = 60 ← ∂L/∂a = ∂d/∂a · ∂L/∂d = b · 20 = 60 ✓# b.grad += 2 * 20 = 40 ← ∂L/∂b = ∂d/∂b · ∂L/∂d = a · 20 = 40 ✓child.grad += local_grad * v.grad

class Value 是一个普通的 Python 类。它同时扮演两个角色:
- 一个会算数的数字
: Value(3) + Value(5)要能得到Value(8)(靠__add__)。 - 计算图上的一个节点
:保存”我是谁算出来的”和”局部导数”。
进入 L → 先递归 e → 先递归 d → 先递归 a → a 无 child → append(a)→ 递归 b → append(b) → 回到 d,append(d)→ 递归 c → append(c) → 回到 e,append(e)→ 回到 L,append(L)topo = [a, b, d, c, e, L]reversed(topo) = [L, e, c, d, b, a] ← 从 L 开始往源头走,完美
自动微分最厉害的地方在于它的“组合性”:
只要每一种原子运算的局部导数是对的,任意深的、任意复杂的函数组合都能自动得到正确的全局梯度。
这个性质是链式法则给的数学保证。只基于六个原子运算便可以达到下面的效果:
-
用 +和*组装出矩阵乘法(linear()) -
用 *、**-0.5、+组装出 RMSNorm -
用 exp、+、/组装出 Softmax -
用 log、-组装出交叉熵 -
把上面这些再组合起来,拼出 Attention、MLP、Transformer Block -
最终构建一个完整的 GPT
而 backward() 一个方法,就能把整张图的梯度一次性算出来。这点也印证了Karpathy 在文件开头所说的:”this file is the complete algorithm, everything else is just efficiency“.
相对于 PyTorch、JAX、TensorFlow 这些工业级的自动微分引擎实现,class Value 与它们的核心区别也只是:
- 数据粒度:
:它们的节点是张量(多维数组),Value 是标量 - 底层
:它们用 C++/CUDA,Value 是纯 Python - 优化
:它们做算子融合、内存复用、并行调度, Value只追求代码简洁
而原理则完全一致。
也就是说理解了这 43 行代码,你就理解了 PyTorch 的核心原理。
这也是笔者分析与总结 MicroGPT 源码的意义所在。
本篇完。
下篇第四部分继续分析 MicroGPT的模型架构详解,如果觉的有趣,欢迎讨论关注:)