 夜雨聆风
夜雨聆风





OpenClaw vs Hermes Agent:用真实数据告诉你该怎么选
如果你用过Claude Code或者Cursor,大概率经历过这种抓狂时刻:花了一下午时间,好不容易让AI助手摸清了你代码库的命名规范、部署流程,还有那些只有老员工才知道的“祖传”数据库schema。结果第二天打开新会话,一切归零——又得从头教起。
这种“上下文失忆症”已经成为AI编程最顽固的痛点。而两个开源项目正在用完全不同的哲学,试图终结这个循环。
先说结论:这不是一场“谁取代谁”的战争,而是两种技术哲学的分道扬镳。 OpenClaw在回答“如何把AI变成一个可运营的系统”,Hermes Agent则在探索“如何让AI在执行中自我进化”。
核心分歧:控制平面优先 vs 学习循环优先
理解这两个框架,首先要看清它们的根假设。
OpenClaw的假设很务实:大多数开发者缺的不是一个“会自己生长的AI”,而是一个可靠的控制平面。这个控制平面要能24/7稳定在线,能接Telegram、微信、Discord,能跑定时任务,能管理工具调用,还要记住你上个月交代的事情。
架构上,OpenClaw就是一个TypeScript单进程网关+Node.js守护进程,作为所有消息、工具、会话的中枢。它赢在系统化运营能力——多群路由映射、定时任务调度、心跳巡检、Webhook外部触发,这些机制组合起来就是一个稳定的生产级AI运营系统。
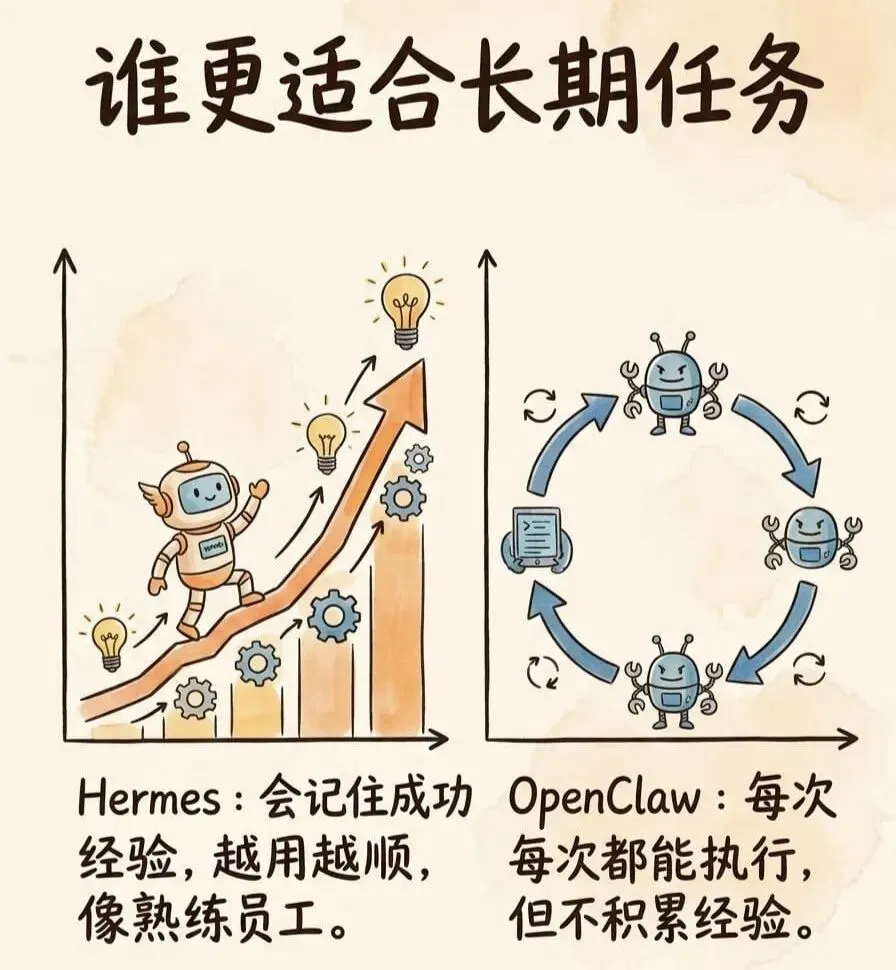
Hermes Agent的假设更激进:它认为很多用户根本不想持续设计AI的行为,只想让AI在真实任务里“越跑越准”。所以它的核心不是控制平面,而是一个封闭的学习循环。
这个学习循环会做一件很酷的事:每次执行完复杂任务,AI会回头分析“这次为什么能成功”,然后把可复用的模式写成可重复使用的规则。Skill(技能)不再是人类手写的文档,而是AI在执行中积累的“程序性记忆”。
技术对比:只看最重要的三个维度
1. 记忆系统:深度vs效率
OpenClaw的记忆系统像是一个精心设计的个人知识库。以笔者的实际数据为例:54天积累了471条记忆记录、3543个向量块,支持语义检索+关键词检索双模式。这套体系几乎没有容量限制,适合需要深度知识积累的场景。
Hermes Agent的记忆系统更“聪明”,但有限制。它采用SQLite FTS5关键词检索+规则匹配,速度快,但语义匹配能力不如向量索引。最现实的结构性约束是:它的核心记忆文件(MEMORY.md)只有约2200字符预算。对轻量助手没问题,对知识密集场景会明显受限。
不过Hermes有个聪明的设计:周期性评估机制。AI会定期评估哪些信息值得固化到长期记忆,哪些可以遗忘。OpenClaw目前没有对等机制,记忆整理完全依赖定时任务+人工规范。
2. Skill系统:生态vs进化
OpenClaw的Skill生态已经相当成熟。笔者实装了66个Skill,涵盖深度调研、技术写作、日报生成等多个场景。ClawHub公共市场上有100+社区贡献的Skill,生态规模类似早期的npm。
但Skill需要人工编写和维护。笔者写一个deep-research Skill花了2-3天,后续微调又花了若干次。迁移成本被严重低估。
Hermes的杀手锏是Skill自动进化。它的自进化子系统基于DSPy(斯坦福声明式LLM编程框架)+ GEPA(ICLR 2026 Oral论文),能够分析执行轨迹、诊断失败根因、生成优化后的Skill变体。
单次优化成本约2-10美元,纯API调用。官方数据称,自改进后重复任务完成速度可提升约40%。但要注意:目前只有Skill文件优化可用,完整的全栈自进化还在路线图中。
3. 安全模型:工程化配置vs激进隔离
OpenClaw的安全更偏工程化配置。用户需要自己决定信任边界,可以选择Docker沙箱隔离,ClawHub市场有审核机制,但早期曾爆发供应链攻击(Koi Security审计发现2857个Skill中有341个恶意条目)。
Hermes在默认安全上更激进:Skill内部生成(避免供应链攻击)、强制容器隔离、自动恶意软件扫描。但它的挑战在于隐私——记忆越持久,可能泄露的敏感信息就越多。
直观理解:两个基础设施的比喻
如果你管理过云原生基础设施,可以这样理解:
OpenClaw像是Kubernetes——它提供了一个强大的控制平面,负责调度、编排、服务发现。你可以部署各种工作负载(Skill),连接各种存储(记忆系统),但它不关心工作负载内部如何进化。
Hermes Agent像是Serverless + 自动调优服务——它更关注函数(Skill)本身的性能优化,会根据每次执行的表现自动调整代码,让函数越跑越快、越跑越准。
迁移成本:为什么我选择“不迁移”
我基于54天OpenClaw实装经验(126个定时任务、66个Skill、10000+篇Obsidian文档)做了详细评估,结论是:短期ROI为负,不建议全量迁移。
迁移成本主要来自三方面:
1. 配置重建:126个定时任务需要逐个重建,语法和行为模型都不同
2. Skill验证:66个Skill需要逐个适配、调试、回归测试
3. 核心资产无法迁移:多群路由体系、AIW流水线(含队列管理、质量门控)、memory-wiki知识管理方法论——这些都是“用出来的资产”,不是“配出来的功能”
总工时估算:3-4周全职等效工作量。
实战建议:并行运行,分阶段验证
更合理的路径不是二选一,而是让两个框架各司其职:
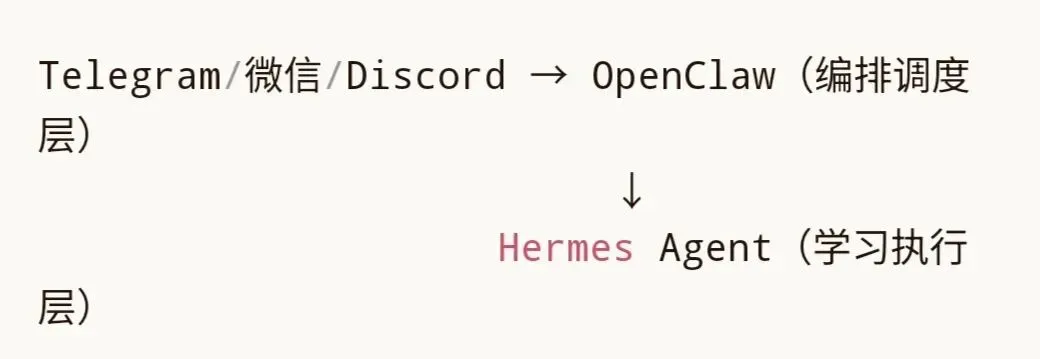
实施路径:
Phase 1(1-2天):部署Hermes实例,用迁移工具导入基础配置
Phase 2(1周):选2-3个任务试点——推荐深度调研、周期性摘要、结构化写作。这三类任务有明确成功标准,适合观察Skill进化效果
Phase 3(2-4周):重点观察:Skill质量是否随使用显著提升?GEPA优化后的Skill是否比手工版本更准更快?
Phase 4(按需):如果效果成立,扩大Hermes职责边界;如果效果不达预期,Hermes降级为实验工具
关键判断
1. Hermes的自学习系统真实可用,但范围有限——目前只有Skill优化可用,不要想象成“AI可以自己写代码优化自己”
2. GEPA的核心价值是“诊断根因”——它通过自然语言反思分析执行轨迹,理解为什么失败,这比传统RLHF的稀疏奖励更高效、更可解释
3. 社区体量差距会在真实使用中放大——OpenClaw 354k stars vs Hermes 47k stars,模板、案例、踩坑经验差一个级别
4. 这不是技术选型,而是哲学选择——要稳定可控的运营系统,选OpenClaw;要自我进化的学习伴侣,选Hermes。但最聪明的做法可能是:让OpenClaw管调度,让Hermes管学习。
AI助手正在从“用时打开、不用关闭”的工具,向“永驻运行、持续学习”的伴侣转变。而作为开发者,我们第一次有了选择权——不是选哪个更好,而是选哪种哲学更契合你的工作方式。