 夜雨聆风
夜雨聆风





Splice 今日发布三款生成式AI工具, 将创作者收益补偿机制延伸至AI创作场景 | 2026.04.19
Splice 今日发布三款生成式AI工具, 成功激发了本喵的技术嗅觉. 马上带铲屎官们来深入探索音乐生成的技术原理~🐱喵~
🔥 重磅发布:三款生成式 AI 工具(2026.04.19)
今天 Splice 正式发布了三款全新 AI 工具,把采样创作带入了 AI 时代:
|
|
|
|
|---|---|---|
| Variations |
|
|
| Craft |
|
|
| Magic Fit |
|
|
关键亮点:
-
接入 Splice Sounds 与 INSTRUMENT 插件,DAW 内直接使用
-
输出均获得商业授权
-
原作者收益保护 — 所有 AI 生成的变体下载时,原作者依然获得收益分成
-
平台 300 万+ 人工采样全部可追溯至原作者
📌 其他近期动态
2025年8月 — Splice 收购了英国顶尖音色库开发商 Spitfire Audio(汉斯·季默御用合作方),其产品已上架 Splice 插件市场
2025年10月 — 发布移动端应用 Splice: Make more music,让音乐人在手机上几秒钟内勾勒新歌创意
2025年7月 — Studio One Pro 7 成为首个原生集成 Splice 的 DAW,支持”Search with Sound”声音搜索,AI 自动匹配工程节拍和调性
Splice 这一波操作很有意思:别人搞 AI 音乐生成是”替代创作者”,Splice 是“赋能创作者+保护原创收益”。采样原作者能在 AI 变体被使用时继续赚钱,这个机制可能会成为行业新标准。🎵
喵呜~ 接下来让我为铲屎官们🐱来详细拆解 Splice 三款 AI 工具背后的技术原理喵~ 🎛️
Splice AI 音乐生成技术解析
一、核心技术架构
Splice 的三款工具(Variations、Craft、Magic Fit)建立在一套分层式音频智能系统之上:
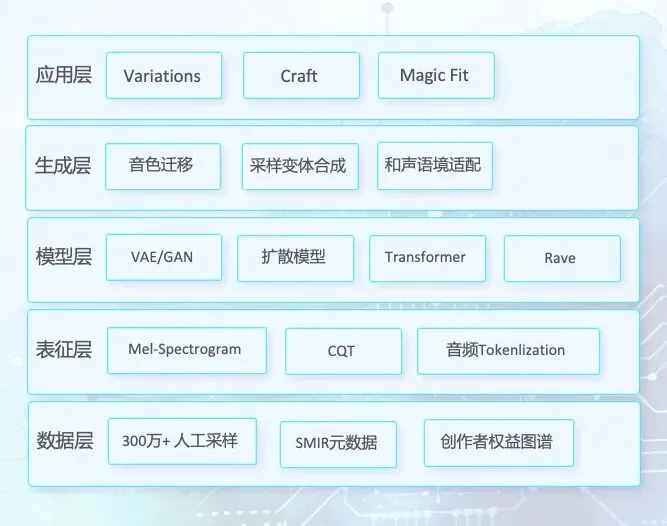
二、Variations 技术原理
核心任务:采样变体生成(Sample Variation Generation)
1. 音频表征选择
Splice 采用 梅尔频谱图(Mel-Spectrogram)+ CQT(恒Q变换) 双轨表征:
-
梅尔频谱:模拟人耳听觉感知,优化低频分辨率,适合捕捉音色质感
-
CQT:在音乐音高上均匀分布,便于音高追踪和调式分析
CQT vs STFT 的关键差异:STFT 时频分辨率均匀,CQT 在低频有高频率分辨率(分辨相近音符),高频有高时间分辨率(追踪快速泛音变化)
2. 音色迁移(Timbre Transfer)技术
根据 Splice AI 研究副总裁 Alejandro Koretzky 的背景,Variations 很可能采用 VAE + GAN 混合架构:
变分自编码器(VAE)路径:
原始采样 → Encoder → 潜在空间(Latent Space)→ Decoder → 变体采样 ↓ 条件注入(调式、BPM、结构)-
Encoder:将音频压缩为低维潜在向量,保留核心音色特征
-
条件注入:用户调整的结构、调式、BPM 参数作为条件向量(Conditioning Vector)介入采样过程
-
Decoder:从修改后的潜在表示重建音频波形
关键创新点:Splice 的 “保留核心特质” 意味着他们在潜在空间中实现了音色-结构解耦——可以单独调整结构而不破坏音色辨识度。
3. 创作者权益追踪的技术实现
这是 Splice 区别于其他 AI 音乐平台的核心:
每个采样 → 唯一标识符(Fingerprint)→ 区块链/数据库记录 ↓ AI变体生成时溯源 → 原作者权益自动分配技术上可能采用 音频指纹(Audio Fingerprinting) + 智能合约 的组合,确保任何变体都能追溯到原始采样。
三、Craft 技术原理
核心任务:采样 → 可演奏乐器(采样合成器化)
1. 采样合成(Sampling Synthesis)
Craft 将静态采样转换为 多采样乐器(Multi-sampled Instrument):

技术要点:
-
音高变换算法:使用 相位声码器(Phase Vocoder) 或 时频域拉伸 实现高质量变调
-
循环点智能检测:AI 分析采样找到最佳循环位置(避免突兀接缝)
-
ADSR 包络生成:根据采样特性自动生成 Attack/Decay/Sustain/Release 参数
2. 频谱平滑处理
为避免音高变换带来的 “芯片音效”,Craft 可能采用了 RAVE(Real-time Audio Variational autoEncoder) 类似的神经声码技术——这是 IRCAM 开发的实时音频合成模型,能在 CPU 上实现 48kHz 高品质合成。
四、Magic Fit 技术原理
核心任务:和声与节奏语境适配(Harmonic & Rhythmic Context Adaptation)
1. 音乐信息检索(MIR)分析
Magic Fit 首先需要理解目标工程的音乐语境:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2. 语境适配算法
当用户拖入采样时,Magic Fit 执行:
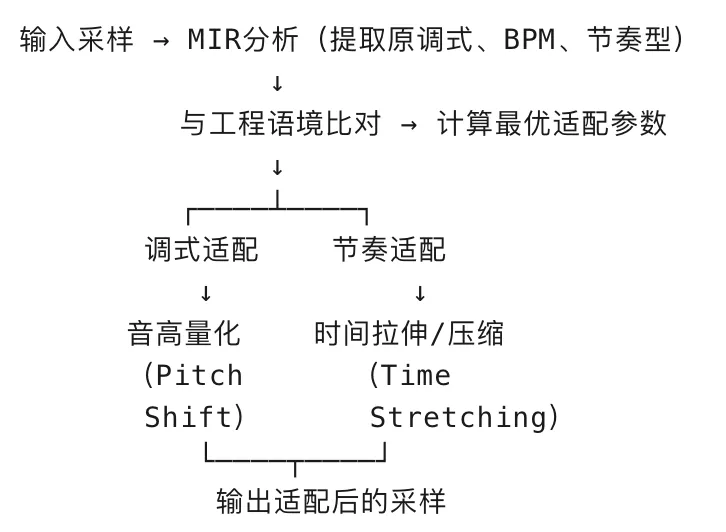
技术亮点:”自动适配”意味着算法需要在 保持采样原有感觉 和 融入工程语境 之间找到平衡点,这可能用到了 强化学习(RL) 来优化适配决策。
五、底层模型推测
基于 Alejandro Koretzava(Splice VP of Applied AI Research)的背景和当前音频 AI 前沿,Splice 可能采用了以下技术组合:
|
|
|
|
|---|---|---|
|
|
CLAP(Contrastive Language-Audio Pretraining)
|
|
|
|
潜在扩散模型(Latent Diffusion)
|
|
|
|
RAVE
|
|
|
|
SMIR(Structured Music Information Representation) |
|
六、技术差异化分析
Splice 的技术选择体现了明确的产品哲学:
|
|
|
|
|---|---|---|
| 生成对象 |
|
|
| 可控性 |
|
|
| 创作者角色 |
|
|
| 版权机制 |
|
|
技术上,Splice 走了 “可控音频生成” 的路线——不是让 AI 替你写歌,而是让 AI 帮你重塑、适配、扩展已有的声音素材。
这里有几个具体的技术细节我们继续展开分析: Latent Space、MIR工作原理、音频生成框架两大门派、以及和弦检测算发细节🐱🎵
Part一、 Latent Space以及MIR工作原理
1.1、Latent Space(潜在空间)
通俗理解:声音的”基因图谱”
想象你有一首复杂的歌,包含旋律、音色、节奏、情感无数细节。Latent Space 就是把这些高维复杂信息压缩成低维向量的空间。
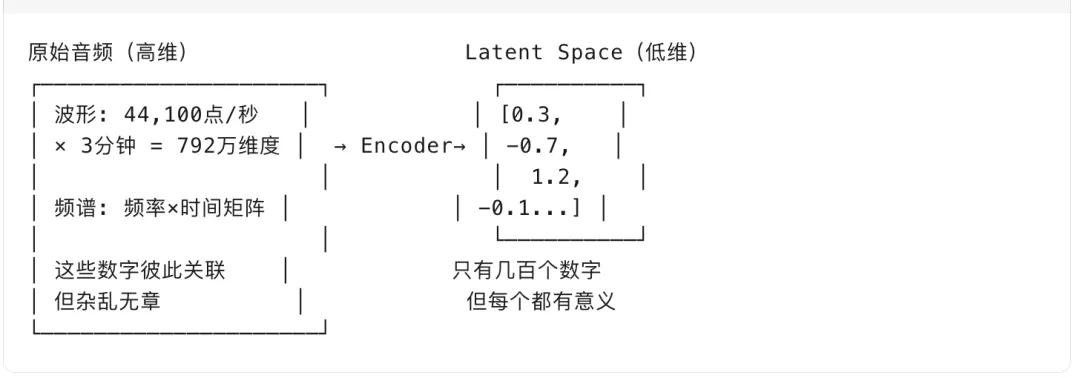
为什么叫”潜在”(Latent)?
因为这些压缩后的数字不代表具体可解释的东西(比如”这是C大调”),而是隐藏的特征组合:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
模型通过海量数据自己”悟”出这些维度,人类不一定能命名它们。
Splice 中的关键应用
Variations 的核心魔法就发生在 Latent Space:

这就像在基因层面编辑声音——不改变”这是鼓声”的本质,但改变它的”生长方式”(节奏结构)。
类比:Latent Space 像是一张世界地图。原始音频是地球表面的真实地形(复杂无比),Latent Vector 是地图上的坐标(简单)。你可以在地图上移动(调整参数),再映射回真实地形(生成新音频)。
1.2 MIR(音乐信息检索)分析
什么是 MIR?
Music Information Retrieval,简单说就是“让计算机听懂音乐”的技术。不是播放音频,而是理解其中的音乐元素。
核心分析维度
MIR 系统会从音频中提取这些”音乐指纹”:
|
|
|
|
|---|---|---|
| 音高/旋律 |
|
|
| 节奏/节拍 |
|
|
| 和声/调式 |
|
|
| 音色/乐器 |
|
|
| 结构 |
|
|
技术流程详解
以 Splice Magic Fit 为例,分析流程是:

关键技术详解
1. MFCCs(梅尔频率倒谱系数)这是音频AI的”通用语言”:
原始波形 → 分帧 → FFT → 梅尔滤波器组 → 对数 → DCT → MFCC系数
为什么用梅尔(Mel)?因为人耳对低频敏感(100Hz到200Hz的差异比1000Hz到1100Hz更分明)。MFCC 模拟了这种感知特性。
2. Chromagram(色谱图)只关心音级(C, C#, D… 共12个),不关心八度:
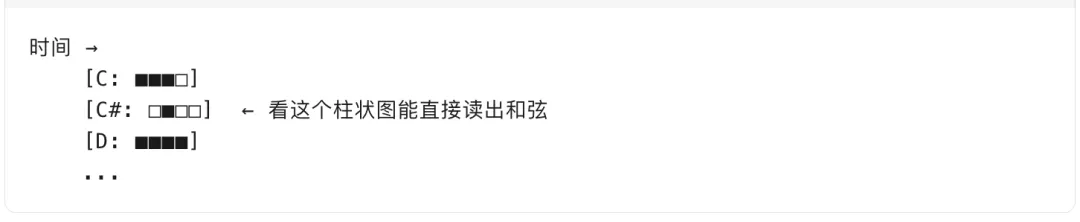
比如 C Major 和弦 = C(1) + E(0.6) + G(0.8) 的能量分布模式。
3. 节拍跟踪(Beat Tracking)检测音乐的”脉搏”:

Splice Magic Fit 的 MIR 应用
当用户拖入一个采样到工程中:

关键:MIR 提供”音乐语境”,让 AI 知道该怎么变,而不是盲目处理。
两者的关系
Latent Space 和 MIR 是互补的:
|
|
|
|
|---|---|---|
| 性质 |
|
|
| 可解释性 |
|
|
| 用途 |
|
|
| Splice角色 |
|
|
Splice 的聪明之处是把两者结合:用 MIR 理解”工程需要什么”,用 Latent Space 操作”采样能变成什么”。
Part二、VAE vs GAN:音频生成技术的两大门派
两大门派各有所长, 我来细细拆解 🥷🎭
核心思想差异
| VAE(变分自编码器) | GAN(生成对抗网络) | |
|---|---|---|
| 哲学 |
|
|
| 目标 |
|
|
| 训练逻辑 |
|
|
| 类比 |
|
|
架构对比
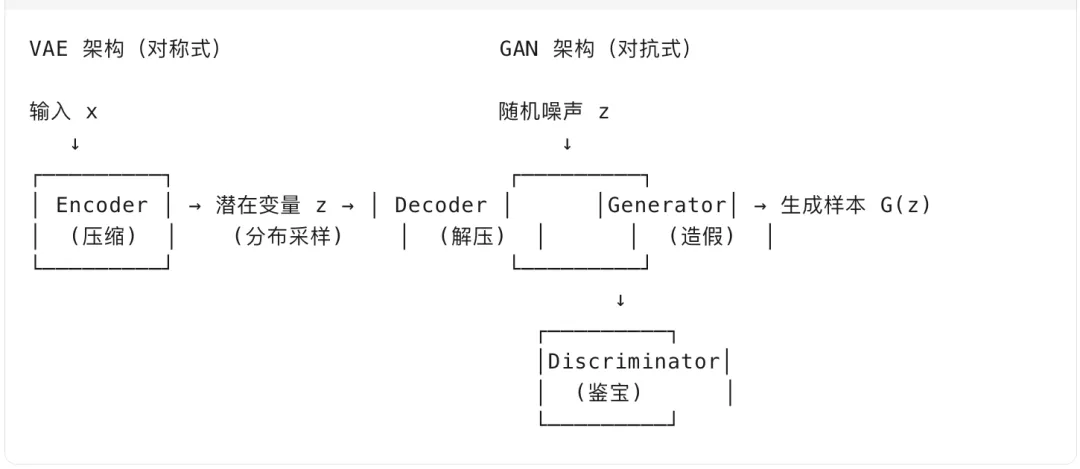
训练过程详解
VAE 训练(单网络,数学优化):

GAN 训练(双网络,博弈对抗):

|
|
|
|
|---|---|---|
| 训练稳定性 |
|
|
| 生成质量 |
|
|
| 潜在空间 |
|
|
| 模式覆盖 |
|
|
| 可控性 |
|
|
| 训练速度 |
|
|
在音乐生成中的应用
VAE 更适合 Splice 的场景:
为什么 Splice 用 VAE(或 VAE+GAN 混合)?
1. 采样变体需要”可控变形”
– VAE 的潜在空间是连续的,可以插值
– 从采样A渐变到采样B,中间每一步都有意义
示例:鼓声采样
Latent A: [0.2, -0.5] → 紧实鼓点
Latent B: [0.8, 0.3] → 混响鼓点
中间点 [0.5, -0.1] → 中等混响的鼓点
2. 需要条件生成(指定BPM、调式)
– 条件VAE:把BPM作为条件向量c输入
– z → Decoder(z, c) → 指定BPM的采样
3. 版权溯源要求
– VAE的Encoder是可逆映射
– 可以追踪”这个生成结果来自哪个原始采样”
GAN 在音乐中的典型应用:
案例:实时音色迁移(如 Google NSynth)
Generator: 输入小提琴音频 → 输出钢琴音色音频
Discriminator: 判断”这是真钢琴录音还是生成的?”
优势:音质通常更真实
劣势:难控制具体参数,难解释生成过程
Splice 可能采用了两全其美的方案:
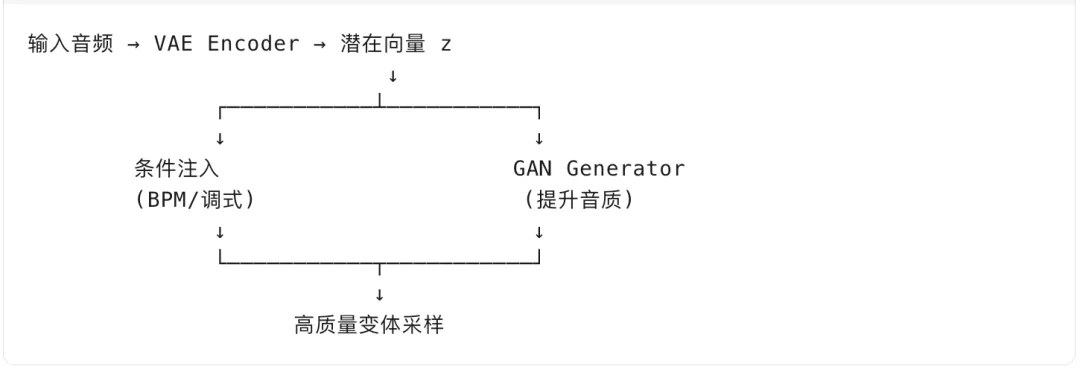
-
用 VAE 的潜在空间保证可控性和结构
-
用 GAN 的判别器提升生成质量
Part三、和弦检测算法细节
整体流程

步骤详解
步骤1: 时频分析 —— CQT(恒Q变换)
为什么用 CQT 而非普通 FFT?
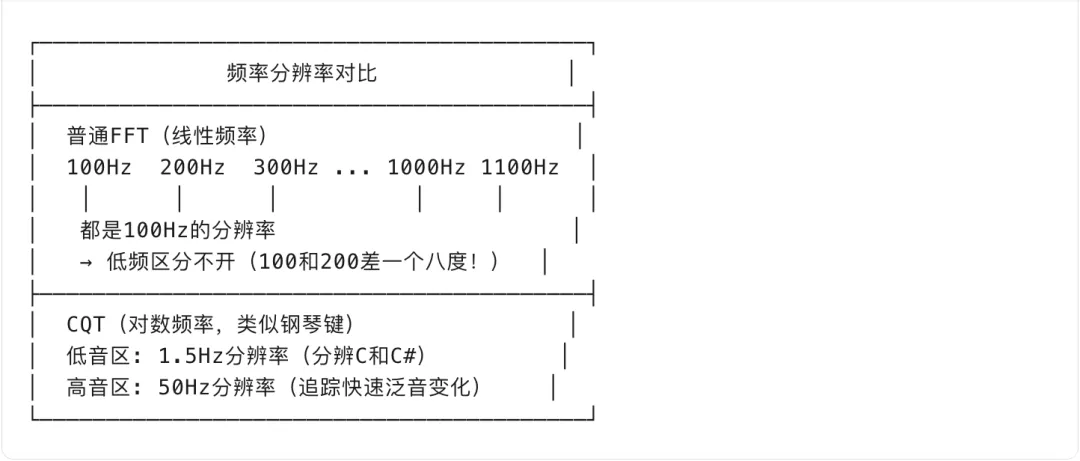
CQT 计算公式:
f_k = f_min × 2^(k/b)
其中 b 是每八度的频带数(通常12或36)
k 是频带索引
步骤2: 色谱图(Chromagram)提取
这是和弦检测的核心表示:

可视化理解:

步骤3: 和弦模板匹配(Template Matching)
模板定义(以12维向量表示):
Python
# 大调和弦模板(C Major = C-E-G)major_template = [1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0]# 索引: C C# D D# E F F# G G# A A# B# 小调和弦模板(C Minor = C-Eb-G)minor_template = [1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0]# 索引: C C# D D# E F F# G G# A A# B# 属七和弦(C7 = C-E-G-Bb)dom7_template = [1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0]
匹配算法:
对于每一帧的 Chromagram 向量 c(归一化后):对于每个和弦模板 t ∈ {C, C#, ..., B} × {maj, min, ...}: 计算余弦相似度: score = c · t / (||c|| × ||t||) 或 相关系数: score = correlation(c, t)选择 score 最高的和弦作为该帧的识别结果步骤4: 时间平滑与维特比解码(Viterbi Decoding)
原始匹配结果有噪声:

维特比算法(隐马尔可夫模型解码):

算法核心:
Python
# 动态规划for t in 时间帧:for s in 所有和弦状态:# 当前帧最佳路径 = 前一帧所有路径 + 转移概率 + 观测概率dp[t][s] = max(dp[t-1][prev_s] +transition(prev_s, s) +observation(s, chromagram[t]))
效果:消除孤立噪声,保证和弦进行符合音乐理论。
深度学习方法(进阶)
传统模板匹配有局限(爵士和弦、转位、高叠和弦难识别)。现代系统可能用神经网络:
输入: Chromagram序列 (12 × T) ↓CNN层: 局部模式识别(捕捉和声音程特征) ↓Bi-LSTM: 时序建模(捕捉和弦进行上下文) ↓全连接层: 分类到 170+ 和弦类型 ↓CRF层: 序列约束(最后优化输出) ↓输出: 和弦标签序列关键指标
和弦检测系统通常评估:
|
|
|
|
|---|---|---|
| 根音准确率(Root) |
|
|
| 三音性质(Maj/Min) |
|
|
| 完整和弦类型 |
|
|
| 切分准确率 |
|
|
总结:两者的关系

#AI学习 #音乐生成#AI技术科普 #Splice #音乐模型#和弦检测算法#AI科普#AI学习#AI技能#云绽科技#云绽渣渣喵 #zazaMeow