 夜雨聆风
夜雨聆风





【AI入门拆解04】Embedding到底在干嘛?为什么AI能“看懂相似问题”?
大家好,我是小编~
上一节我们讲了chunk,把长文拆成小段
但问题来了:
AI 怎么知道“哪几段和用户问题最相关”?靠的是Embedding(向量化)
一、什么是Embedding?
我们知道,AI本身是“看不懂”文字的。
对于AI来说,“我想买游戏本”和“求推荐高性能游戏笔记本”,本质上都是一串毫无意义的字符。
就像我们看不懂外星文字一样,AI也无法直接理解人类的语言,它只能处理数字。
Embedding的核心任务,就是“语义转码”——把人类能理解的“语义”,转成AI能计算的“数字向量”。
但这个转码过程绝对不是随便赋值的,而是有一个核心逻辑:
保留语义关联,抛弃无关细节。
举个具体的例子:
句子1:我想买一台适合打游戏的笔记本
句子2:求推荐性能强的游戏本
句子3:我想给手机换个新壳
这三句话中,句子1和句子2字面不同,但语义高度相似;
句子3和前两句语义完全无关。
经过Embedding转码后,它们会变成三串数字向量(比如1536维的数字组合),其中句子1和句子2的向量“距离”非常近,句子3和前两句的向量“距离”则很远。
这里的“距离”,不是我们生活中说的物理距离
而是数学上的相似度
距离越近,语义越相似;距离越远,语义差异越大。
更通俗地说,Embedding就像给每一段内容贴了一张“语义标签”
标签上的数字代表了这段内容的核心含义
AI不需要理解文字本身,只要对比这张“标签”上的数字,就能知道两段内容是不是一个意思。
讲到这里你也许会疑问:为什么语义相近的句子,向量就会挨得近?
向量不是凭空来的,背后全靠Transformer做语义理解。
二、先搞懂Transformer 到底是干嘛的
Transformer 是目前所有现代 AI 的 “语义理解核心”。它唯一的任务:根据整句话,重新理解每个词的真正含义。
看个例子
吃苹果 → 水果苹果手机 → 品牌苹果股价 → 公司
如果只看 “苹果” 两个字,机器根本分不清。
传统模型给每个词一个固定向量,很容易理解错误。
有了Transformer之后
它让每个词,不再孤立存在。
每个词都会 “看一遍句子里所有其他词”,然后重新计算自己在当前语境下的含义。这个机制叫:
Self-Attention 自注意力
你可以理解成:
对每个词,算出它该 “重点关注谁”
相关的词权重高,不相关的权重低
最后每个词都融合了整句话的信息
比如句子:“我喜欢早上跑步”
“跑步” 会高度关注 “早上”
“喜欢” 会关注 “我” 和 “跑步”
模型自动抓住重点,理解整句话的意图
Transformer 结构简单看类似这样
Encoder(编码器):读懂句子 → 用来做 Embedding、搜索、分类Decoder(解码器):生成句子 → 用来做 GPT、对话、写作
生成 Embedding,只需要 Encoder。
三、核心原理
我们以句子为例:
“我喜欢早上跑步”
步骤 1:分词 Tokenization
把句子切成模型能处理的最小单元:
我 / 喜欢 / 早上 / 跑步步骤 2:转成 Token ID
模型不认识字,只认识编号:
我 → 101喜欢 → 233早上 → 489跑步 → 520
步骤 3:初始词向量(查表)
每个编号对应一个固定长度的初始向量(如 768 维)。这一步只是 “字变数字”,还没有上下文理解。
步骤 4:加入位置编码
Transformer 本身不知道顺序,必须给每个词加上 “位置信息”,它才能分清:“我喜欢你”≠“你喜欢我”
步骤 5:进入 Transformer Encoder(核心加工)
这是真正 “读懂语义” 的一步。
模型做的事情:
对每个词计算 Q、K、V 三个向量
Q:我这个词,想问什么K:别的词有什么信息V:别的词真正的内容模型算一遍 “谁和谁更相关”,就懂了整句话的意思
比如:
“跑步” 会高度关注 “早上”“喜欢” 会高度关注 “我” 和 “跑步”
无关的词权重就很低
用 Q 和 K 计算相关性(注意力分数)
用分数加权 V,得到融合上下文的新词向量
多层堆叠后,语义理解越来越深
最终结果:每个词的向量,都带上了整句话的含义。
步骤 6:池化 Pooling → 得到句子 Embedding
Transformer 输出的是每个词的向量,但我们需要一句话一个向量。
常用方式:
取句首 CLS 向量
或对所有词向量取平均(Mean Pooling)
最终得到一串固定长度数字,例如:
[0.124, -0.451, 0.777, 0.223, ... ] (共768/1024维)这就叫:句子 Embedding
四、余弦相似度
那么如何计算两个向量空间的距离?
最常用的就是使用余弦相似度
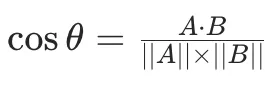
拆成 3 步:
1. 点积 A・B
对应位置相乘,再加起来。
A = [a1,a2,a3]
B = [b1,b2,b3]
点积 = a1×b1 + a2×b2 + a3×b3
意义:方向越一致,点积越大
2. 模长 ||A||、||B||
向量的长度:
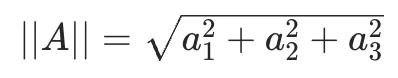
3. 最后相除
把点积除以两个长度的乘积 →把长度影响消除,只保留方向。
举个最简单例子
A = [1, 0]B = [1, 1]
点积 = 1×1 + 0×1 = 1
||A|| = 1
||B|| = √2 ≈ 1.414
cosθ = 1 / 1.414 ≈0.707
意思:有点像,但不是特别像。
拓展 (了解余弦相似度的同学可跳过):
点积 = 方向相似度 + 长度影响除以长度 = 把长度影响 “剥掉”,只留下方向相似度
1. 先看:点积自带 “长度放大效应”
点积公式:
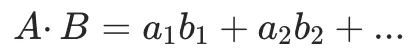
点积同时受两个东西影响:
方向(是否相似)
长度(向量本身多长)
举个极端例子:
同一句话,生成两个 Embedding:
A: [1, 1]B: [2, 2]
它们方向完全一样,只是 B 是 A 的 2 倍长。
算点积:A·B=1×2+1×2=4
再看另两个向量:
C: [1, 0]D: [0, 1]
方向完全垂直,点积:C·D=0
问题来了:如果我把 B 变得更长:[100, 100]
再算 A·B:
A·B=1×100+1×100=200
方向明明没变,点积却从 4 暴涨到 200!
这就说明:点积会被向量长度干扰,不能直接用来比相似度。
除以长度到底在干嘛?
把两个向量都 “强行缩放到长度 = 1”再算点积,就只剩下方向了。几何上叫:归一化(Normalize)

就是先把两个向量都缩成单位长度,再算点积。
回到刚才的例子,一看就懂
A = [1,1] 长度 =√2
B = [2,2] 长度 = 2√2
点积 = 4
余弦相似度:
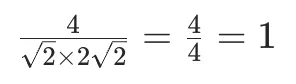
= 完全相似
即使 B 再长:[100,100]余弦相似度依然 =1
方向没变,结果就不变。
五、总结
-
文字先分词、编号,变成初始向量;
-
经过Transformer理解上下文,每个词都融合整句话的含义;
-
输出一串固定长度的数字,就是Embedding 语义向量;
-
用余弦相似度比较向量方向,判断两段话意思像不像;
-
分数越接近 1,语义越相似,AI 就能精准找到相关内容。