 夜雨聆风
夜雨聆风





Hermes Agent 源码深度拆解:111k Star 的"自我成长"到底靠什么?
近期 Hermes Agent 冲到 GitHub trending 第一,单日涨了 22k star。
很多人看到介绍:”一个会自我成长的 Agent”。
也有人在说速度是比龙虾快;还有人说:骗人,根本就没有自我进化。
我花了一些时间深度阅读了下源码
发现它确实有成长机制——不是 AI 自动变聪明,而是三层记忆架构 + 辩证推理引擎,让 Agent 的”经验”能累积。
从 MEMORY.md 开始:最基础的记忆层
Hermes 继承了 Claude Code 的原生记忆系统,两个文件:
-
MEMORY.md:通用记忆(”我喜欢用 TS 语言”) -
USER.md:用户偏好(”K 喜欢简洁回答”)
这层记忆直接写文件,下次对话直接读。看起来很简单,但 Hermes 做了一个关键改进:
每次 memory 工具写入,都会同步到 Honcho。
# agent/memory_manager.pydef on_memory_write(self, action: str, target: str, content: str) -> None:if self._provider:self._provider.on_memory_write(action, target, content)为什么要同步?
因为 Honcho 能做一件事 MEMORY.md 做不了——多轮推理。
上下文压缩前,先抢救对话片段
MEMORY.md 是长期记忆,但很多时候 Agent 需要的是”近期记忆”——你刚才说了什么,上一次讨论了什么。
Hermes 用 SQLite FTS5 全文搜索来解决。
真正让我觉得它不一样的地方,是这个钩子:
def on_pre_compress(self) -> None:"""Called before context compression."""if self._provider:self._provider.on_pre_compress()压缩前先把对话片段同步到 Honcho,防止”短期记忆”丢失。
下次你问”上次我们讨论的那个 bug 怎么解决的”,Honcho 能从被压缩的对话里找到答案。普通 Agent 压缩完就忘了,但 Hermes 还记得。
Honcho:不是向量库,是辩证推理引擎
这是 Hermes 自我成长的关键。Honcho 不是向量数据库,不是简单的语义搜索。
它是一个多轮辩证推理引擎。
Peer Paradigm:双向建模
Honcho 的核心抽象是 Peer——可以是用户,也可以是 AI。
observation:user:observeMe: true# Honcho 构建用户画像observeOthers: true# Honcho 学习 AI 行为ai:observeMe: true# Honcho 构建 AI 自我认知observeOthers: true# Honcho 学习用户习惯这四个开关形成双向建模:
Honcho 不只记住”用户喜欢什么”,还记住”AI 在这个用户面前通常怎么做”。
当 AI 面对不同用户时,会切换不同的”人格”。这个设计很聪明——AI 的行为会跟着用户适应,而不是一刀切。
多轮推理:不是检索,是思考
Honcho 的核心 API 是 peer.chat()——不是简单检索,而是多轮推理。
Hermes 支持 1-3 轮推理深度:
-
Depth 1:单次查询 -
Depth 2:自审计 + 定向综合 -
Depth 3:自审计 + 综合 + 调和
三轮推理流程(depth=3):
-
Pass 0:基础查询(”这个用户是谁?偏好是什么?”) -
Pass 1:自审计(”Pass 0 的结论有什么遗漏或矛盾?”) -
Pass 2:调和(”综合前两轮,给出最终结论”)
每一轮的 reasoning_level 可以独立配置,从 minimal(快速事实)到 max(彻底审计)。
这不是检索,是思考。Honcho 会质疑自己的结论,找遗漏,做调和。
冷启动 vs 热会话
第一轮推理的 prompt 会根据会话状态自动选择:
-
冷启动:“这个人是谁?偏好、目标、工作风格是什么?聚焦能帮助 AI 快速理解的事实。”
-
热会话:“基于本次会话讨论的内容,关于这个用户哪些上下文最相关?优先当前上下文,而非历史画像。”
注意:冷启动和热会话的 prompt 不一样,Honcho 会自动判断会话状态。
上下文注入位置
Honcho 的上下文注入不进 system prompt,而是注入到 user message。
原因很简单:system prompt 会破坏 prompt caching。注入 user message 可以让缓存保持有效,同时每轮自动刷新上下文。
skill_manage:Agent 创建自己的技能
除了记忆,Hermes 还能创建技能——程序性记忆。
当 Agent 完成复杂任务后,会调用 skill_manage 工具:
"Create when: complex task succeeded (5+ calls), errors overcome, ""user-corrected approach worked, non-trivial workflow discovered."技能格式遵循 agentskills.io 标准,存放在 ~/.hermes/skills/ 目录。
下次遇到同类任务,技能会自动激活——Agent 不用重新学习。
为了避免上下文爆炸,技能采用三级加载(Progressive Disclosure):
-
L0:元数据(name + description)—— skills_list()只返回摘要 -
L1:正文—— skill_view()返回完整内容 -
L2:支持文件——按需加载
Agent 先看 L0,需要时才加载 L1/L2,不会每次对话都把所有技能塞进上下文。
会话结束时的记忆闭环
每次会话结束,Hermes 会做三件事:
-
生成 Session Summary:本次会话讨论了什么 -
更新 User Representation:用户在本次会话中的表现 -
更新 AI Representation:AI 在本次会话中的决策模式
这些信息会写入 Honcho,下次对话 Honcho 会读取。
自我成长的完整闭环
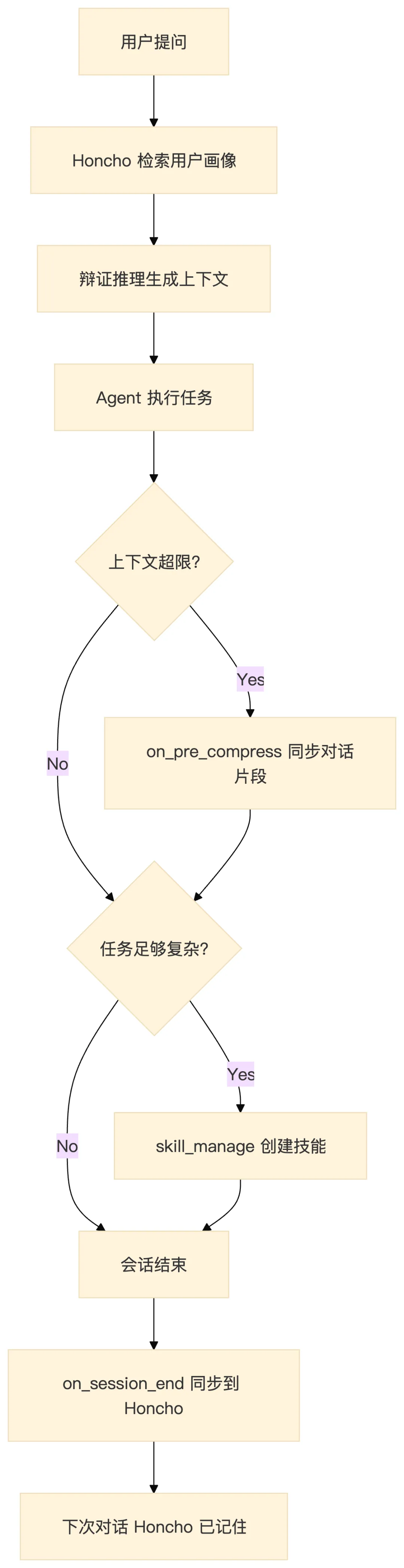
这个闭环让 Hermes 不是”每次对话都从零开始”,而是”越用越懂你”。
这套架构跟普通 Agent 有什么区别?
普通 Agent:每次对话都是新对话,上下文满了就压缩,压缩后内容丢失。
Hermes Agent:
-
短期记忆(Session Search)可以追溯 -
期记忆(Honcho)会累积 -
程序性记忆(Skills)会沉淀
跟 RAG 的区别:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
实际感受是
Hermes 的”自我成长”不是 AI 自动变聪明,而是架构让经验能累积。
三层记忆 + Honcho 辩证推理 + skill_manage 工具,形成了一个完整的闭环。
如果你也在用 AI 编程工具,有几个思路可以借鉴:
-
不要让记忆只存在上下文里——上下文会压缩,记忆会丢失 -
引入外部记忆系统——Honcho 或类似方案 -
让 Agent 有创建技能的能力——程序性记忆比陈述性记忆更实用
这只是我的做法,你可能有更好的。
感谢阅读,如果感觉有用
期待点赞,转发,关注~ 我会持续分享干货内容