 夜雨聆风
夜雨聆风





告别OpenClaw运维盲区:火山引擎日志服务TLS一键开启全景观测
概述
当一个 OpenClaw 应用从本地 Demo 走向生产环境,Agent助手/xClaw企业的开发和运维团队面临的挑战便不再是“能不能跑”,而是“跑得稳不稳、贵不贵、出了事能不能查清”。Agent 运行过程如同一个黑盒,这导致了一系列现实问题:
-
Token 成本不明:无法精细化衡量不同模型、不同技能(Skill)或不同业务场景下的 Token 消耗,成本账单模糊,优化无从下手。
-
多轮对话追踪困难: Agent 与大模型交互过程复杂,多轮对话如同“黑盒”,出现问题时难以追踪每一轮的上下文与根因。
-
无法监控系统状态: OpenClaw 在运行态会涉及消息队列、Webhook 处理、会话管理等多个环节。当用户说“它怎么不回我了”,问题可能出现在任何一层,运维团队将陷入“盲人摸象”的困境。
-
安全审计难题:高危命令执行、敏感文件访问等无法审计和追溯,造成严重的安全事件。
针对这些痛点,火山引擎日志服务(TLS)面向Agent助手/xClaw企业的开发和运维团队,提供开箱即用、全方位的OpenClaw运维观测方案。通过一键式安装的插件,实现对 OpenClaw 日志、指标和链路数据的零侵入、全量采集,并自动生成覆盖成本、运维、性能、安全四大核心场景的观测大盘。帮助Agent助手/xClaw企业的开发和运维团队,用最低的接入成本,换取最全面的系统洞察力,让每一次模型调用、每一次工具执行、每一笔 Token 开销都有据可查。
一键接入:3分钟点亮你的观测大盘
日志服务TLS提供与 OpenClaw 框架原生集成的日志采集插件,通过一行命令,即可自动、无侵入地采集所有相关的可观测数据,无需修改任何业务代码。
前提条件
-
OpenClaw 版本不低于2026.3.8。
-
已开通火山引擎日志服务(TLS),并确定服务所在的 Region和 Endpoint。
-
准备好用于鉴权的 AK/SK 或 API Key(任选其一)。
鉴权模式如何选?
我们支持两种鉴权模式,以适应不同安全级别的部署需求。
|
模式 |
适用场景 |
使用说明 |
|
AK/SK (访问密钥) |
希望安装器自动创建和关联所有 TLS 资源(如项目、应用、日志主题),适合初次试用、单机开发与快速验证场景。 |
在访问控制台中创建具备资源创建权限的 API 访问密钥。安装器将使用此密钥自动完成所有云上资源的配置。 |
|
API Key |
希望严格收敛权限,由运维团队统一预先创建 TLS 资源并分发日志主题 ID。适合生产环境、多实例部署及权限强管控场景。 |
在 TLS 控制台预先创建 OpenClaw 应用,获取各类日志对应的 Topic ID 和用于数据写入的 API Key。此方式权限最小,最为安全。 |
安装命令示例
我们推荐使用非交互式的命令行进行批量部署,尤其适合多实例场景。
💡以下示例以推荐的 API Key 模式为例。你只需将命令中的占位符替换为你的真实信息即可。
npm exec -y --package=@volcengine/diagnostics-tls-install -- diagnostics-tls-install \--non-interactive \--region <your-region> \--api-key <your-api-key> \--topic-id-app-log <app日志TopicID> \--topic-id-audit-log <配置审计日志TopicID> \--topic-id-cache-trace <CacheTrace日志TopicID> \--topic-id-session <Session日志TopicID> \--topic-id-trace <Trace日志TopicID> \--topic-id-metric <Metric指标TopicID>
安装完成后,只需重启 OpenClaw Gateway,即可完成数据采集。
openclaw gateway restart观测大盘:从全局视角看懂 OpenClaw
数据接入后,TLS 会自动生成预置观测大盘,分别对应成本、运维、性能、安全这四个最受关注的运维场景。你无需手动配置图表,即可直观地洞察系统正在发生什么。
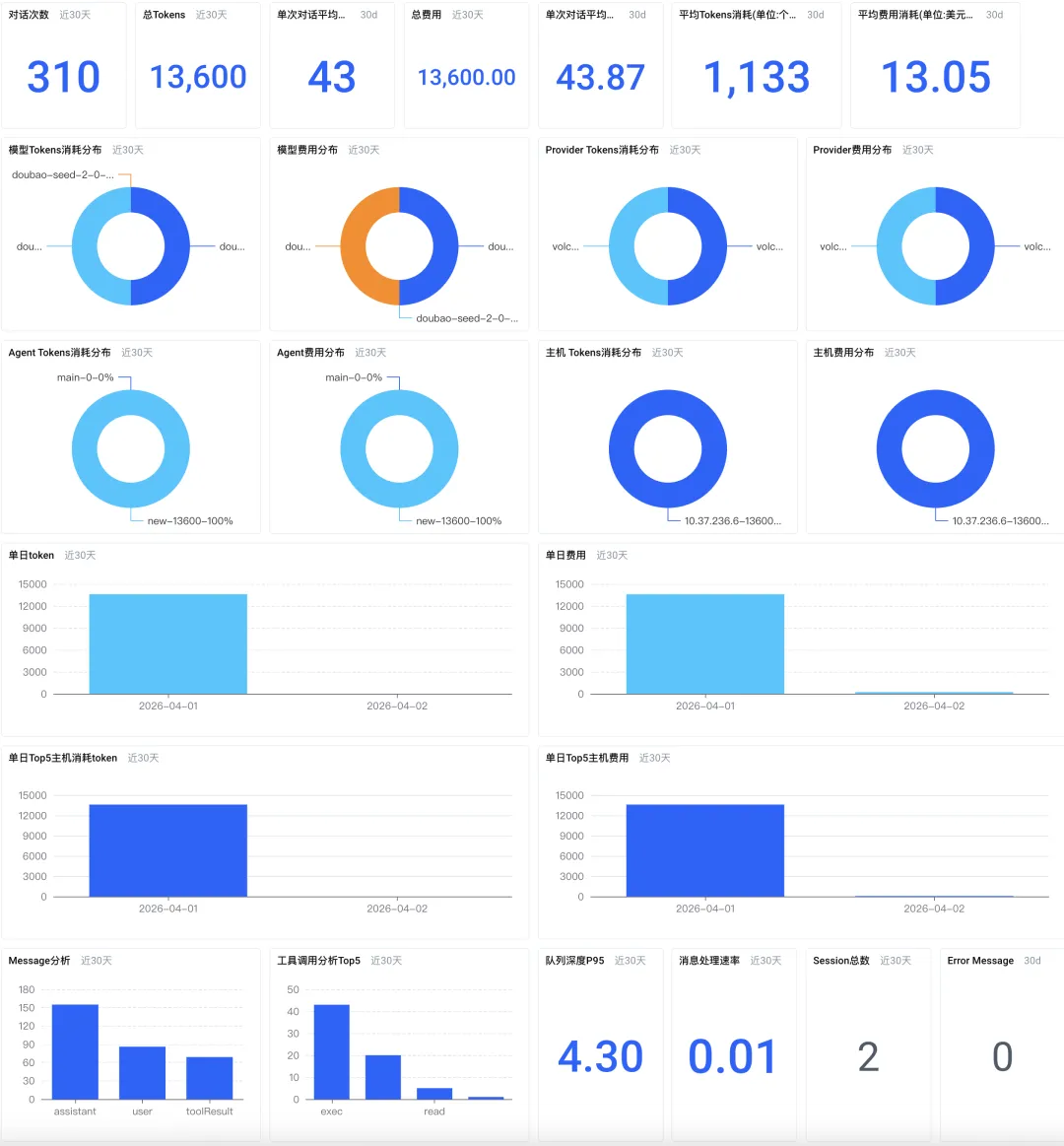
成本分析大盘:钱花在哪了?
-
核心指标概览:直观展示总调用次数、总 Token 消耗、总费用以及单次调用的平均成本,让你对整体开销一目了然。
-
多维度成本下钻:支持按模型、 Provider、Agent 甚至是主机等多个维度对 Token 消耗和费用进行拆解分析。你可以快速发现是哪个大模型或哪个业务 Agent 贡献了绝大部分成本。
-
成本趋势分析:通过按天聚合的趋势图,清晰地看到成本随时间的变化。如果某天费用突然上涨,可以迅速定位到异常时间点,为进一步排查提供线索。
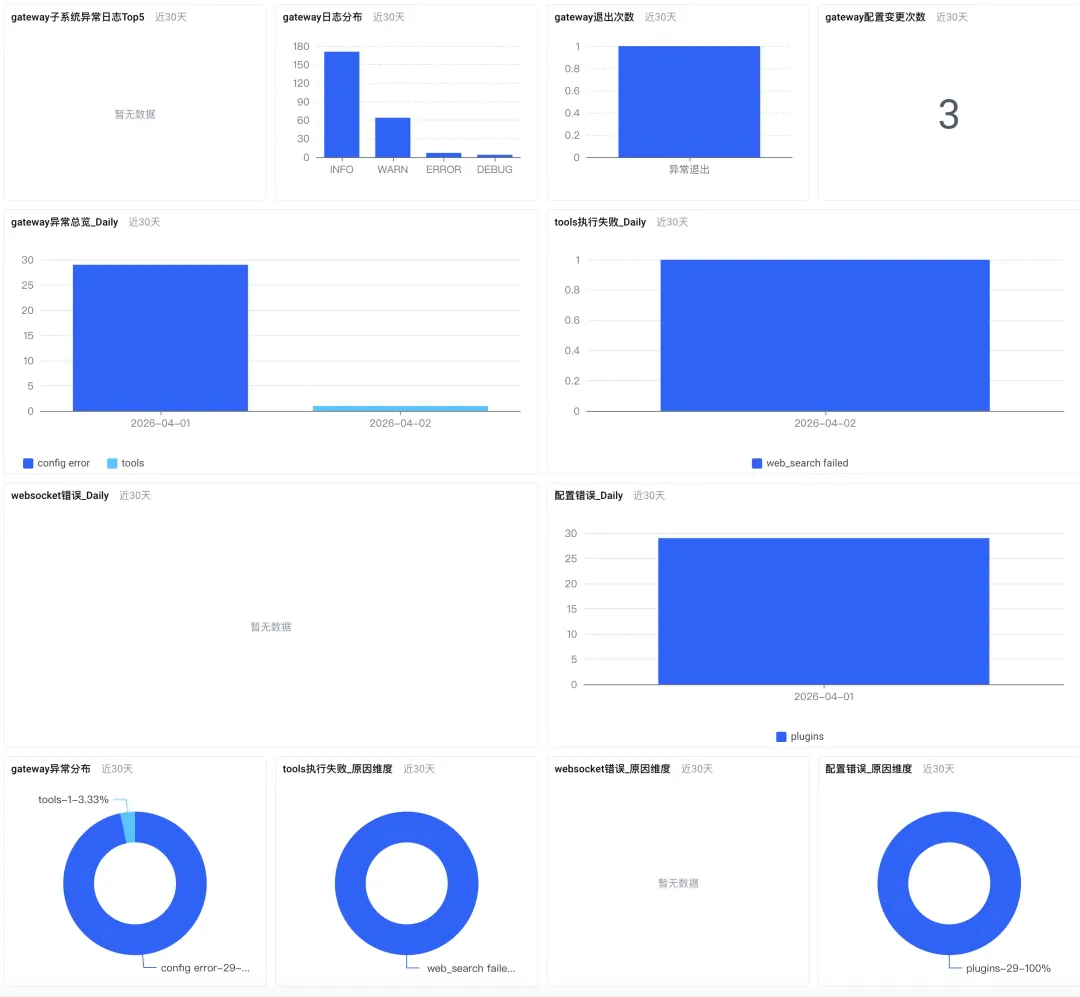
运维分析大盘:系统健康吗?
-
异常根因下钻:当 Gateway 出现异常时,大盘会自动将其按“配置异常”、“ WebSocket 异常”、“工具调用异常”等原因分类,并展示各自的趋势和占比。你可以快速判断是哪一类问题导致了服务不稳定。
-
服务状态监控:实时统计 Gateway 的退出次数、配置变更次数,以及 Error、Fatal 级别日志的分布情况,让你对系统的整体健康度有宏观把握。
-
多实例对比:如果你管理着多个 OpenClaw 实例,大盘可以清晰地展示不同实例的异常分布,帮助你快速识别出“问题最严重”的那个实例。
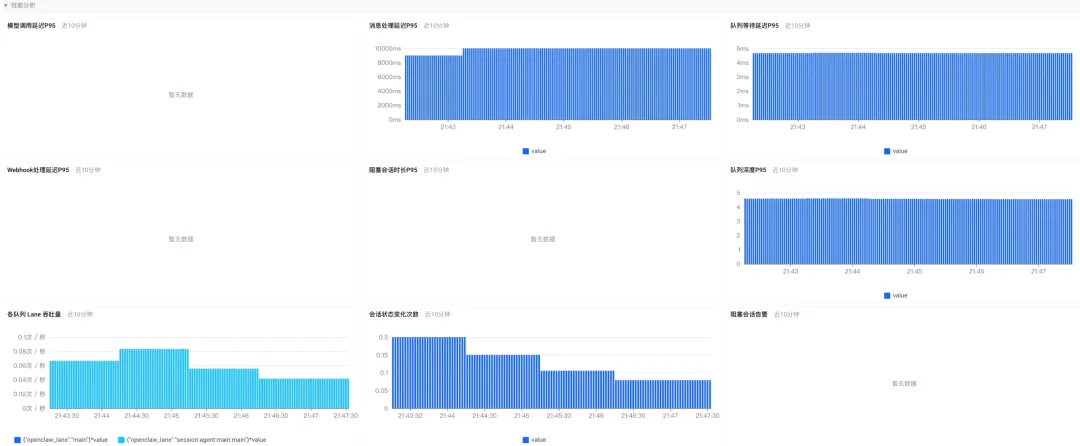
性能分析大盘:哪里变慢了?
-
关键延迟监控:实时展示模型调度的端到端延迟、消息在队列中的处理延迟。如果用户反馈“响应慢”,你可以第一时间判断瓶颈是在模型推理还是在内部任务处理。
-
系统吞吐与压力:通过 Webhook 的接收速率、错误次数,以及任务队列的深度变化,评估系统当前是否处于高负载状态,是否存在任务积压。
-
会话卡死检测:自动发现并统计那些长时间没有进展的“卡死”会话。这对于排查 Agent 陷入逻辑死循环或等待外部资源超时等问题至关重要。
安全审计大盘:谁在做危险操作?
-
高危行为追溯:对 exec 执行危险命令、 fs_write 写入敏感路径等行为进行审计。你可以清晰地看到谁(用户/会话)在什么时间,执行了什么危险操作。
-
鉴权与访问监控:统计鉴权失败、连接失败的次数,帮助发现潜在的恶意探测或配置错误。
-
配置变更留痕:每一次对 OpenClaw 核心配置的修改都会被记录下来,方便追溯和审计。

从仪表盘到原始证据:用 SQL 追溯根因安全审计大盘:谁在做危险操作?
仪表盘帮助我们从宏观上发现“可能存在问题”,而日志服务 TLS 强大的检索和 SQL 分析能力,则让我们能从“可能”走向“确定”,实现从现象到证据的完整追溯。
当观测大盘亮起红灯时,你可以直接跳转到原始日志,通过几次简单的查询,层层下钻,直至找到问题根源。
场景示例 :Token消耗异常分析
-
问题现象:成本大盘显示某个 Agent 的 Token 消耗异常高,似乎 Prompt Caching(提示词缓存)完全没有生效。
-
排查思路:缓存失效的一个常见原因是 System Prompt(系统提示词)本身不稳定,比如在其中嵌入了当前时间、用户 ID 等动态信息。我们可以通过一条 SQL 来全局巡检这个问题。
-
查询示例:
* | SELECTsessionKey AS "会话键",COUNT(*) AS "请求数",COUNT(DISTINCT systemDigest) AS "System版本数",DATE_FORMAT(FROM_UNIXTIME(MAX(__time__) / 1000), 'yyyy-MM-dd HH:mm:ss') AS "最近时间",MAX_BY(runId, __time__) AS "示例runId"WHERE stage = 'session:loaded'GROUP BY sessionKeyORDER BY "System版本数" DESCLIMIT 20
💡解读:该查询统计了每个会话(sessionKey)中,System Prompt 的指纹(systemDigest)出现了多少个不同的版本。理想情况下,一个会话中的 System Prompt 应该是固定不变的,版本数应为 1。如果查询结果中出现版本数大于1的会话,就意味着存在“缓存杀手”,需要立即检查对应 Agent 的代码逻辑。
总结:让线上数万个 OpenClaw 跑得更稳、更省、更安全
通过火山引擎日志服务 TLS ,为Agent助手/xClaw企业的开发和运维团队提供了一个从数据采集、全局监控到深度追溯的完整 OpenClaw 可观测性闭环,让我们可以观测线上数万个OpenClaw的整体运行健康状态,及时发现异常和快速定位问题。