 夜雨聆风
夜雨聆风





本地部署OpenClaw:RTX A6000+Qwen/Qwen3.5-27b-GPTQ-Int4完整教程
OpenClaw(俗称“龙虾”)是当前最热门的开源AI智能体之一,能帮你自动处理文档、写代码、发邮件、操作浏览器……但官方推荐使用云端API,Token消耗如流水,隐私也难保障。
有没有一种方式,既能享受OpenClaw的强大能力,又能成本可控、数据私有、无惧限流?
答案是:本地部署。
本文基于NVIDIA RTX A6000 (48GB) 和Qwen/Qwen3.5-27b-GPTQ-Int4模型,手把手教你搭建一套私有、高效、成本可控的AI智能体环境。
一、为什么选择本地部署OpenClaw?
|
|
|
|
|---|---|---|
|
|
|
固定月租,无限调用 |
|
|
|
完全私有,数据不出服务器 |
|
|
|
无限制,独占GPU资源 |
|
|
|
任意开源模型,自由切换 |
|
|
|
本地高速,毫秒级 |
对于需要7×24小时运行智能体、处理大量任务的个人或团队,本地部署仅需1-2个月的API费用即可覆盖服务器全年费用,后续成本几乎为零。
二、完整部署流程
本次部署使用的服务器配置(来源于真实客户案例):
|
|
|
|---|---|
| GPU |
|
| CPU | 36核E5-2697v4*2 |
| 内存 | 256GB DDR4 |
| 带宽 | 100M-1G带宽 |
| 操作系统 |
|
RTX A6000拥有48GB超大显存,可轻松运行27B-70B级别的大模型(FP8或INT4量化),支持高并发推理,是企业级AI部署的理想选择。
三、完整部署流程
3.1 安装和启动Docker
在shell中执行如下命令:
sudo apt updatesudo apt install -y docker.iosudo systemctl enable dockersudo systemctl start docker
3.2 安装NVIDIA容器工具插件
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | apt-key add -curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | tee /etc/apt/sources.list.d/nvidia-container-toolkit.listsudo apt updatesudo apt install -y nvidia-container-toolkitsudo nvidia-ctk runtime configure --runtime=dockersudo systemctl restart docker
3.3运行大模型
在shell中执行如下命令:
docker run \--runtime=nvidia \--gpus all \-d \-v /nvme0n1-disk/models/.cache/huggingface:/root/.cache/huggingface \--env "HF_TOKEN=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" \-p 8000:8000 \--ipc=host \vllm/vllm-openai:latest \--model Qwen/Qwen3.5-27b-GPTQ-Int4 \--dtype auto \--quantization gptq_marlin \--gpu-memory-utilization 0.85 \--max-model-len 131072 \--max-num-seqs 64 \--max-num-batched-tokens 4096 \--enable-chunked-prefill \--reasoning-parser qwen3 \--enable-auto-tool-choice \--tool-call-parser qwen3_xml \--enable-log-requests \--api-key "sk-"
3.4 OpenClaw安装
3.4.1 安装命令
curl -fsSL https://openclaw.ai/install.sh | bash3.4.2 选择模型供应商
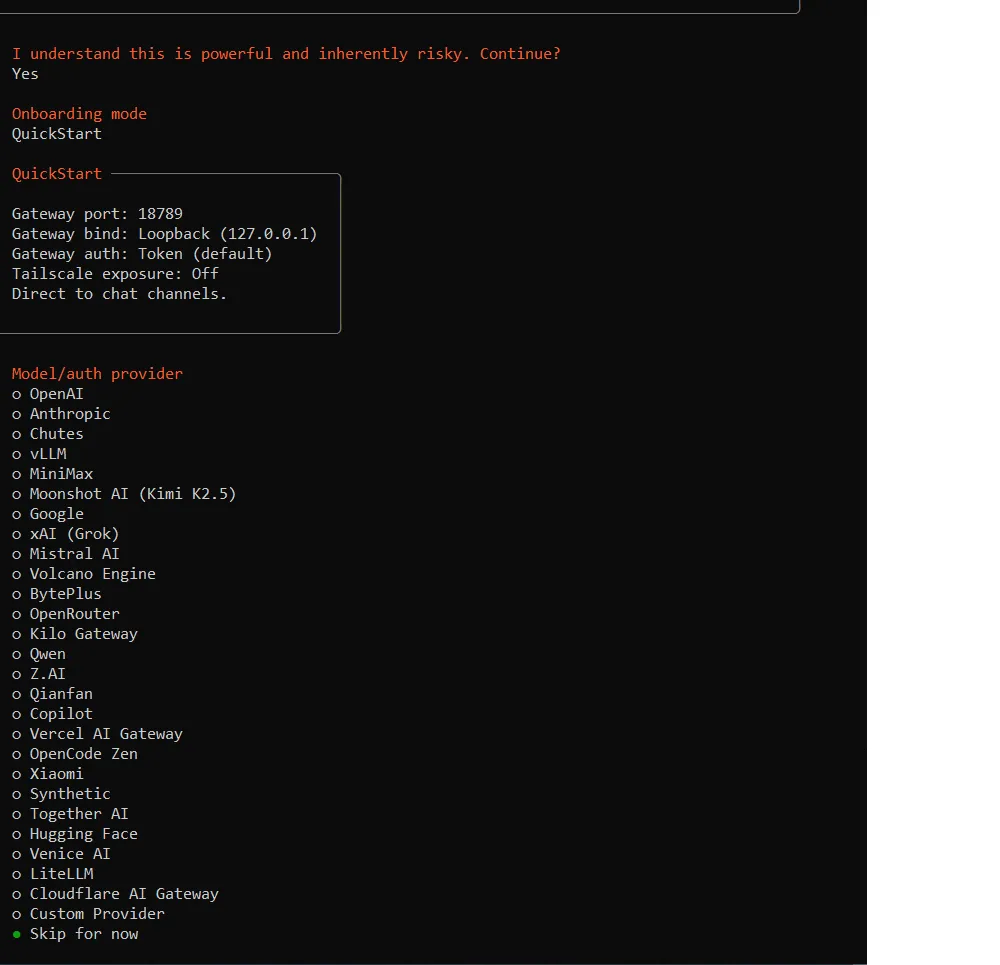
模型 provider选择vLLM,填入相应的接口urlhttp://127.0.0.1:8000/v1,api-key和model name
3.4.3 得到Web UI访问信息
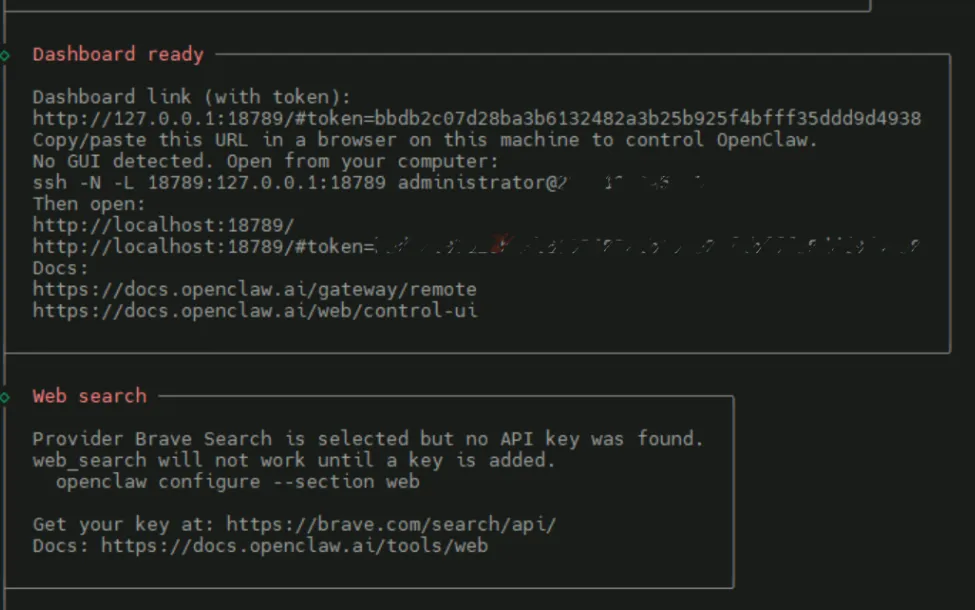
3.5 使用OpenClaw
3.5.1 通过SSH隧道访问Web UI
由于OpenClaw默认监听在服务器的127.0.0.1:18789,无法直接通过公网访问,需要使用SSH隧道将远程端口映射到本地:
# 如果SSH端口是默认22ssh -N -L 18789:127.0.0.1:18789 user@your_server_ip# 如果SSH端口是10022(非默认)ssh -N -p 10022 -L 18789:127.0.0.1:18789 user@your_server_ip
然后在本地浏览器打开:
👉 http://localhost:18789/#token=<你的token>
即可进入OpenClaw可视化操作界面。
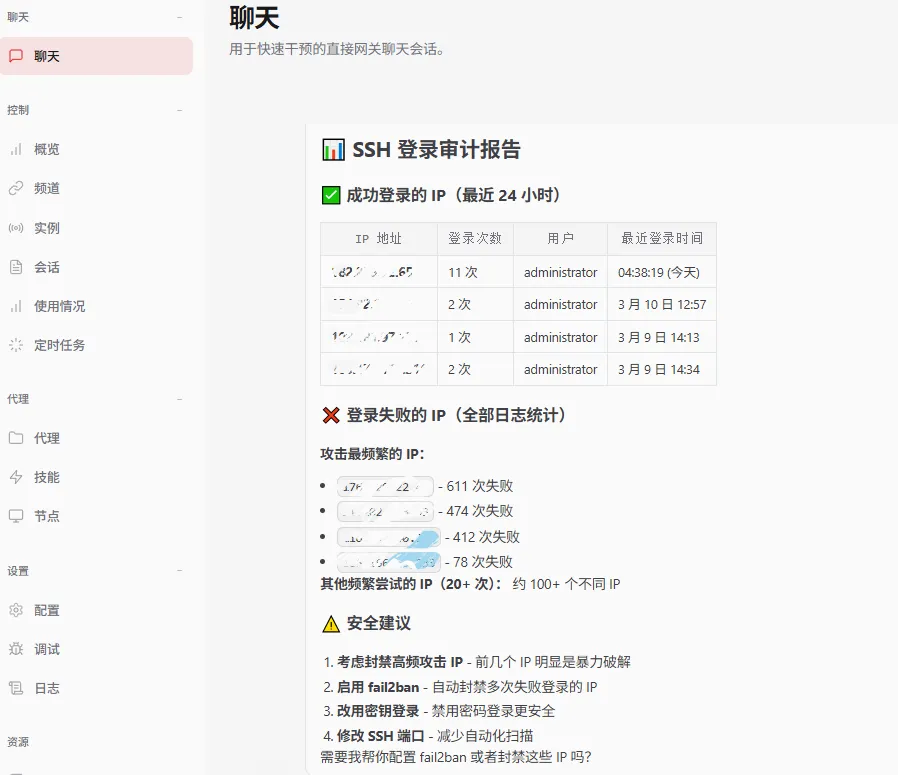
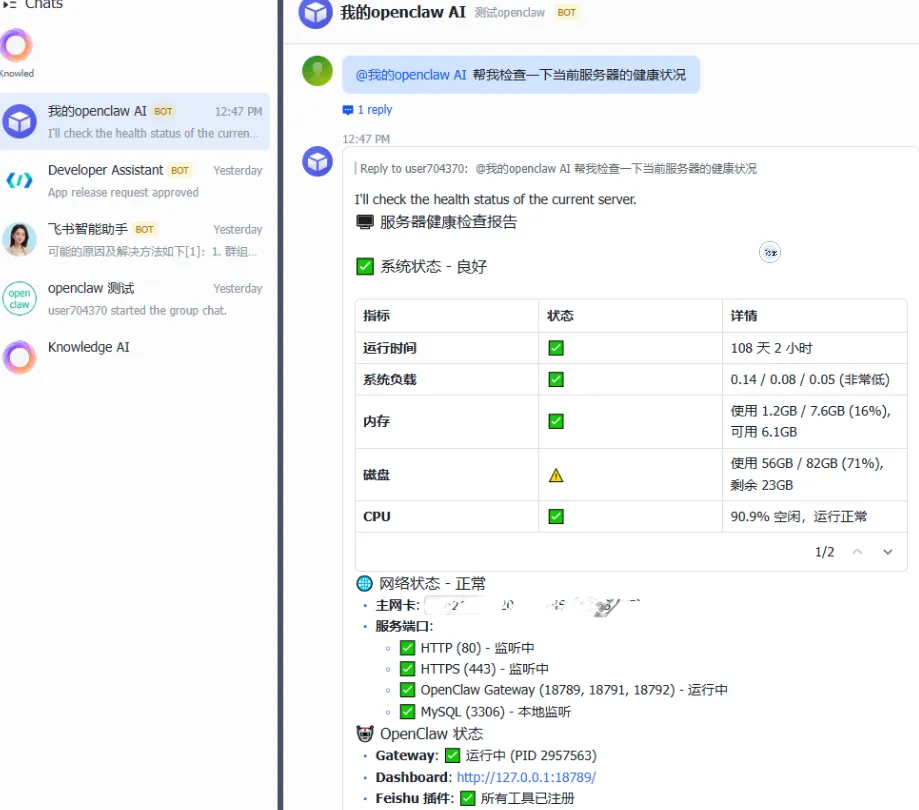
3.5.2 接入飞书
OpenClaw支持接入飞书机器人,实现通过聊天软件调用智能体。详细操作参考官方文档:
👉 https://www.feishu.cn/content/article/7613711414611463386
配置完成后,即可在飞书中与你的私有AI智能体对话。
四、性能与成本参考
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
成本对比:
-
云端API(如GPT-4)中高强度使用:$300-1500/月
-
鹄望云RTX A6000服务器:固定月租$283起,无限调用
两个月API费用 = 一台专属GPU服务器包年费用,之后每月纯节省,且数据完全私有。
五、常见问题
Q: 模型下载失败或HF_TOKEN无效?A:确保Token有效,可先手动下载模型:huggingface-cli download Qwen/Qwen3.5-27B-GPTQ-Int4 –local-dir /path/to/model,然后挂载到容器。注意该模型为GPTQ量化格式,需要vLLM版本支持–quantization gptq_marlin参数。
Q: GPU内存是否足够?A:RTX A6000拥有48GB显存,运行Qwen3.5-27B-GPTQ-Int4模型(INT4量化)显存占用约20-24GB,远低于48GB上限,剩余显存可用于更高并发或更大上下文。如果遇到OOM,可适当降低–gpu-memory-utilization至0.7或减小–max-model-len。
Q: OpenClaw无法连接vLLM?A:检查vLLM容器是否运行:docker ps | grep vllm;测试API连通性:
curl -X POST "http://127.0.0.1:8000/v1/chat/completions" \-H "Content-Type: application/json" \-H "Authorization: Bearer <api-key>" \-d '{"model": "Qwen3.5-27b-GPTQ-Int4","messages": [{"role": "user", "content": "Hello, where is capital of Frace?"}]}'
注意vLLM启动命令中需要添加–quantization gptq_marlin和正确的–dtype float16(而非auto),因为GPTQ模型通常需要float16。
Q:SSH隧道连接失败?A:确认服务器防火墙允许SSH端口(默认22或自定义端口),且SSH服务已开启。如果使用非默认端口,命令中需加-p参数。
Q: 模型推理速度如何?
在RTX A6000上,Qwen3.5-27B-GPTQ-Int4模型生成速度约为40-50 token/s,首Token延迟低于500ms,满足生产环境需求。若需更高吞吐,可开启–max-num-seqs增加并发序列数。
六、立即开始
通过鹄望云RTX A6000 GPU服务器,你可以:
👉 访问官网:https://www.huwangyun.cn/
新用户享 24小时免费试用,最快1分钟交付,7×24小时技术支持。