 夜雨聆风
夜雨聆风





企业级OpenClaw安全部署架构指南
在过去十年中,企业安全架构的演进经历了从边界防御到零信任的深刻转型。然而, Agent 的出现正在带来又一次范式级的挑战——这一次,威胁不再单纯来自外部攻击者,而可能由我们自己部署的智能系统主动触发。
传统应用程序遵循确定性的逻辑:给定相同的输入,始终产生相同的输出,攻击面清晰可枚举。OpenClaw 代表的 AI Agent 则截然不同:它能够自主规划任务序列、动态调用外部 Skills(工具插件)、执行 Shell 命令、读写文件系统、发起 API 调用——这些能力在带来生产力革命的同时,也使其成为一个具有高度自主性的行为主体。
2.1 OpenClaw 的能力边界
理解 OpenClaw 的安全风险,首先要理解其能力边界。OpenClaw 作为企业级 AI Agent 平台,具备以下核心能力:
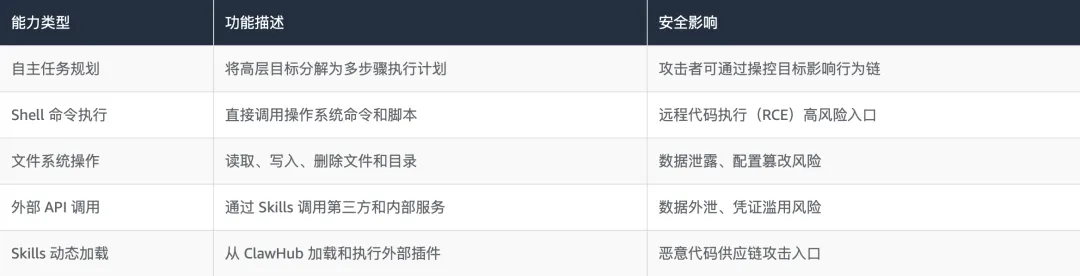
2.2 当前威胁态势:数字不会说谎
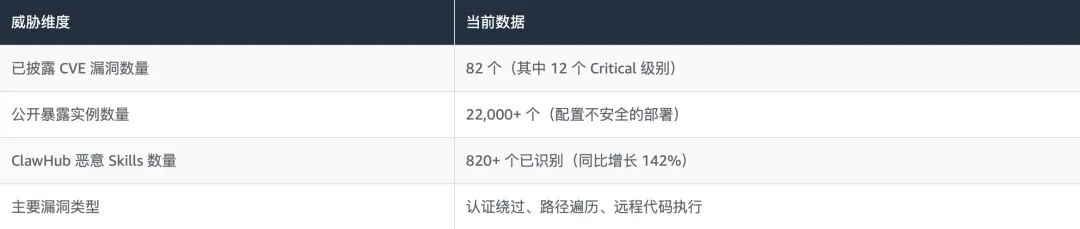
基于 2025-2026 年3月公开安全研究数据,OpenClaw 生态系统面临的威胁态势已超出许多企业安全团队的预期:
在制定防御策略之前,安全架构师必须首先建立完整的威胁认知。OpenClaw 的威胁来源可分为两大类:传统软件漏洞(CVE 形态)和 AI Agent 特有攻击向量(Agentic AI 威胁),如下图所示。

本章以 OWASP Agentic AI Top 10 和 CSA 7 层威胁模型为框架,系统梳理五大核心威胁。
3.1 威胁框架:OWASP 与 CSA 的双重视角
国际安全标准组织已针对 Agentic AI 发布了专门的威胁分类框架,为企业安全评估提供了重要参考基础。OWASP 在 2026 年发布了针对 AI Agent 应用的十大安全风险,OpenClaw 作为典型的 Agentic 应用,面临其中大部分威胁:

云安全联盟 (CSA) 基于 MAESTRO 框架对 OpenClaw 进行了 7 层威胁分析,覆盖从基础模型层到智能体生态系统层的全方位威胁。企业在制定安全策略时,应参考这些框架进行系统性的风险评估。

3.2 五大核心威胁深度分析
3.2.1 威胁一:提示注入攻击(Prompt Injection)
提示注入是 AI Agent 面临的最直接、危害最大的攻击类型。攻击者通过构造恶意文本输入,覆盖 Agent 的原始指令,使其执行未授权操作。提示注入分为两种形态:

典型案例(Zenity Labs 2025):研究人员在一家大型企业的 OpenClaw 部署中,通过在 SharePoint 文档中嵌入隐藏的提示注入指令,成功使 Agent 在处理文档时泄露了企业 HR 数据库的访问凭证。整个攻击链无需接触 Agent 本身,仅通过污染其读取的数据源即可完成。
3.2.2 威胁二:恶意 Skills 供应链(Malicious Skills Supply Chain)
ClawHub 是 OpenClaw 官方 Skills 市场,类似于 npm 或 PyPI 之于软件生态系统。截至 2026 年初,ClawHub 已托管超过 50,000 个 Skills,其中已被识别为恶意的超过 820 个,且数量仍在以每年 142% 的速度增长。
供应链攻击的危险在于信任传递:企业开发者信任 ClawHub,ClawHub 中的 Skill 被信任执行,恶意 Skill 就以合法身份在企业内部环境中执行——不触发任何传统安全告警。
常见恶意 Skills 行为模式:
-
凭证窃取:读取环境变量和配置文件中的 API 密钥
-
数据外泄:将处理结果同步发送至攻击者控制的服务器
-
权限升级:利用 Skills 的执行上下文逃逸沙箱
-
后门植入:在系统中创建持久化访问入口
3.2.3 威胁三:源代码漏洞(Source Code Vulnerabilities)
OpenClaw 核心代码库共披露 82 个 CVE,其中 12 个为 Critical(CVSS ≥ 9.0)级别。这些漏洞集中在三个高危区域:
-
认证绕过(Auth Bypass):攻击者绕过 API 认证机制,直接访问 OpenClaw 管理接口
-
路径遍历(Path Traversal):通过构造特殊文件路径读取系统敏感文件(如 /etc/passwd、AMAZON 凭证)
-
远程代码执行(RCE):在未修补版本中,攻击者可在服务器上执行任意代码
漏洞管理的挑战不仅在于数量,更在于补丁部署的速度。调查显示,企业平均在漏洞披露后 47 天才完成关键补丁的部署,而攻击者通常在 72 小时内即开始利用新披露的漏洞。这一”窗口期”是企业面临的核心风险之一。
3.2.4 威胁四:凭证暴露(Credential Exposure)
22,000+ 个公开暴露的 OpenClaw 实例中,绝大多数问题源于错误的凭证管理:将 API 密钥、数据库密码等敏感凭证以明文形式存储在配置文件、代码仓库或容器镜像中。
凭证暴露的常见模式:默认凭证未修改、凭证硬编码在代码中、凭证通过环境变量传递但未加密、容器镜像中包含生产环境密钥。每一种模式都代表一条通往企业核心系统的直接路径。
3.2.5 威胁五:企业数据泄露(Enterprise Data Exfiltration)
当 OpenClaw 具备访问企业内部系统的权限时,数据泄露的路径多种多样。其中最具代表性的是 Confused Deputy 攻击,以及通过 Agent 身份传递实现的权限越界。

3.3 风险收敛模型:三维风险评估框架
安全风险并非来自单一因素,而是多个维度的叠加效应。基于实际攻击案例分析,OpenClaw 场景中的风险等级由以下三个维度共同决定:

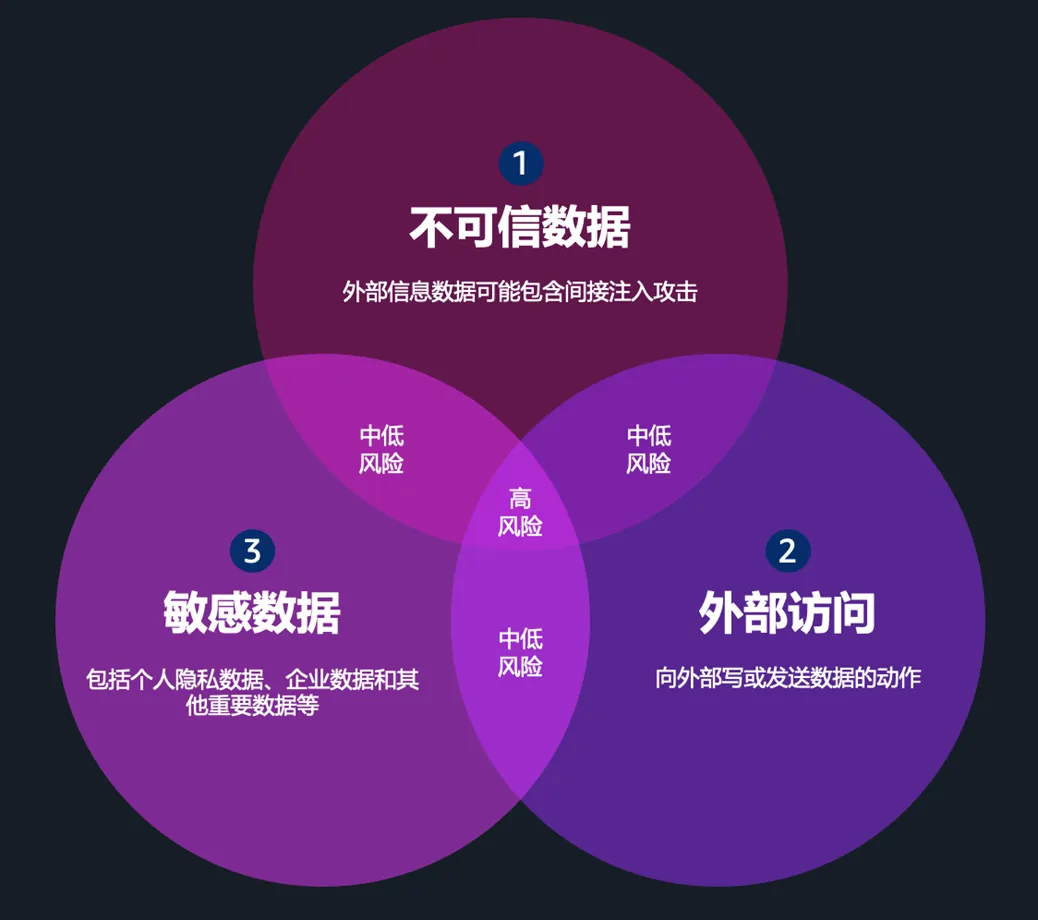
单点安全控制在面对 AI Agent 的复合型威胁时不再足够。纵深防御(Defense in Depth)策略的核心思想是:任何单一控制都可能被绕过,只有多层相互独立的安全机制叠加,才能为企业提供真正可靠的保护。
针对 OpenClaw 的 AMAZON 纵深防御架构分为七个层次,从策略到技术、从外部边界到内部核心,构成完整的安全防御体系:
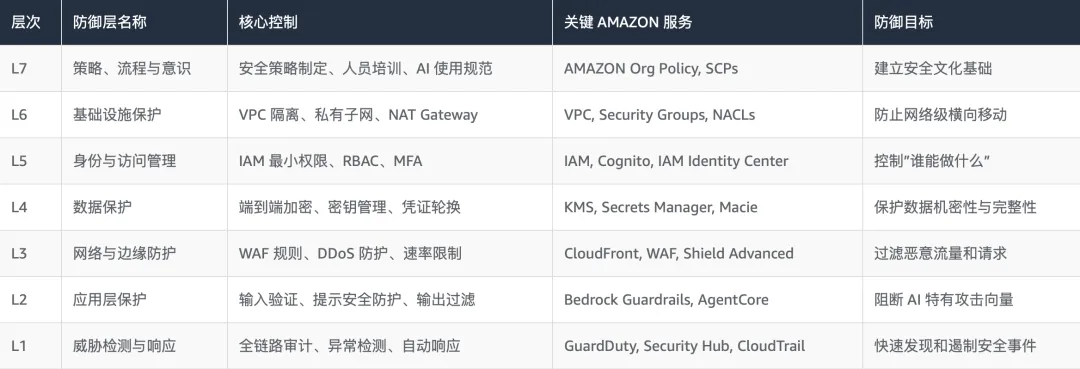
4.1 各层防御的协同效应
七层防御并非独立运作,而是形成相互补充的防御体系。每一层的突破都会触发下一层的防护机制:
-
当攻击者绕过 WAF 规则时(L3 被突破),Bedrock Guardrails 的提示安全过滤(L2)仍能阻断注入尝试
-
当提示注入成功执行时(L2 被突破),IAM 最小权限(L5)限制了 Agent 能够访问的资源范围
-
当权限被滥用时(L5 被突破),KMS 加密数据(L4)确保即使数据被访问也无法被解读
-
任何层次的异常行为都会被 GuardDuty 和 CloudTrail(L1)记录并触发告警
4.2 AMAZON 共担责任模型在 AI Agent 场景的延伸
AMAZON 的共担责任模型在 AI Agent 场景中需要新的诠释。传统上,AMAZON 负责”云的安全”,客户负责”云中的安全”。在 OpenClaw 场景中,这一边界进一步细化:
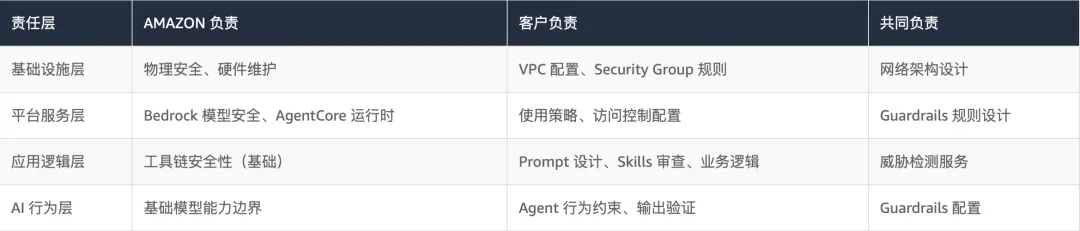
值得特别关注的是:应用逻辑层和 AI 行为层的安全责任几乎完全落在客户侧。这意味着企业需要具备专业的 AI 安全能力,而不能依赖传统的”购买服务等于获得安全保障”的思维模式。
Amazon Bedrock AgentCore 是 AMAZON 专为 AI Agent 工作负载设计的托管安全平台,将五项核心安全能力整合为统一的服务套件。对于希望快速建立企业级 AI Agent 安全基线的团队,AgentCore 是目前最完整的原生解决方案。
5.1 AgentCore Runtime:隔离执行环境
AgentCore Runtime 为每个 OpenClaw 任务提供独立的隔离执行沙箱,从根本上解决了”Agent 越权”和”跨任务污染”问题:
-
执行隔离:每个 Agent 任务在独立的沙箱环境中运行,无法访问其他任务的数据或文件系统
-
自动更新:AMAZON 持续维护运行时环境,自动修复已知漏洞,客户无需手动管理补丁
-
快速漏洞修复:相比自托管环境平均 47 天的补丁周期,AgentCore 可在数小时内完成关键漏洞修复
-
资源隔离:CPU、内存、网络配额独立,防止资源耗尽型 DoS 攻击
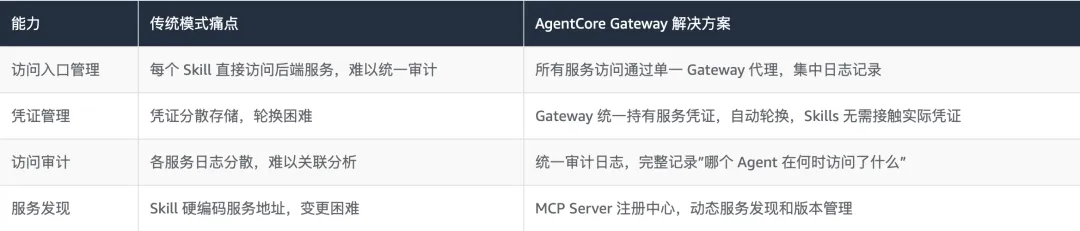
5.2 AgentCore Gateway:统一企业服务访问入口
传统部署模式下,OpenClaw 访问企业内部服务时,每个 Skills 各自管理连接和认证,带来大量分散的攻击面。AgentCore Gateway 通过”统一入口”模式彻底改变这一格局:
5.3 AgentCore Identity:身份传播与委托
Agent 的身份安全是整个体系的核心难题:Agent 需要代表终端用户执行操作,但又不能无限继承用户的所有权限。AgentCore Identity 通过标准 OAuth 协议解决这一困境:
-
Bearer Token 传播:Agent 携带代表终端用户的令牌访问服务,令牌中包含用户身份和授权范围
-
2-Leg OAuth(M2M):适用于后台自动化场景,Agent 以自身身份访问,权限范围由服务账号定义
-
3-Leg OAuth(用户委托):适用于代表用户操作的场景,访问权限严格限定于用户实际持有的权限
-
令牌范围最小化:即使用户是管理员,委托给 Agent 的令牌也只包含该任务所需的最小权限集合
关键安全原则:授权应基于”发起请求的终端用户的实际权限”,而非 Agent 自身的系统权限。
这是防御 Confused Deputy 攻击的核心机制——Agent 不应比代表其操作的用户拥有更多权限。
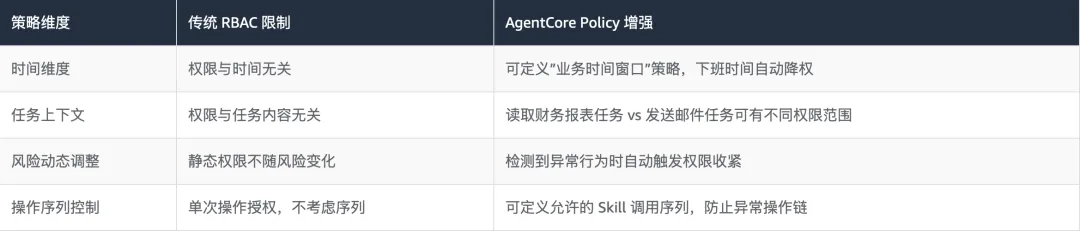
5.4 AgentCore Policy:细粒度上下文感知授权
传统 RBAC(基于角色的访问控制)在 AI Agent 场景中存在明显局限性:角色是静态的,但 Agent 的行为是动态的。AgentCore Policy 引入了上下文感知授权机制:
5.5 Agent Registry:私有化Skills目录
AMAZON Agent Registry 是一项完全托管的发现服务,它提供了一个集中式目录,用于组织、管理和发现组织内的资源。借助 AMAZON Agent Registry,您可以将 MCP 服务器、工具、代理、代理技能和自定义资源发布到可搜索的注册表中,通过审批工作流控制访问权限,并使用户和 AI 代理都能使用语义搜索和关键字搜索来发现合适的工具和代理。
-
集中式发现 – 组织内所有已发布资源的统一查找平台,可供用户和代理搜索
-
治理和管理 – 审批工作流确保只有符合组织安全、合规性和质量标准的记录才能被发现。管理员可以控制组织内的构建者可以发现和使用哪些资源,并可随时移除可发现的资源
-
灵活的资源类型 – 注册 MCP 服务器、代理、技能和任何自定义资源
-
混合搜索 – 结合语义理解和关键字匹配,确保自然语言查询和精确名称查找都能返回相关结果
5.6 AgentCore Observability:完整操作审计
AI Agent 的行为审计是传统 SIEM 系统的盲区。AgentCore Observability 专为 Agent 行为设计,提供业界最细粒度的 AI 操作审计能力:
-
完整 Agent 链路追踪:记录每一步推理决策、每一次 Skill 调用、每一个数据访问事件
-
结构化审计日志:日志包含 Agent 版本、任务 ID、用户身份、操作类型、访问的资源和数据量
-
实时异常检测:基于基线行为模型,实时识别异常 Skill 调用模式和异常数据访问量
-
与 Security Hub 集成:所有安全事件自动汇聚到 AMAZON Security Hub,支持 SOAR 自动响应
-
不可篡改日志:审计日志存储在 S3 + CloudTrail,通过 Object Lock 保证日志不可篡改
架构原则需要在具体场景中得到验证。本章针对五个企业最常面临的安全挑战,提供端到端的解决方案架构视角,帮助安全团队理解从威胁到防御的完整逻辑链。
6.1 防御提示注入攻击
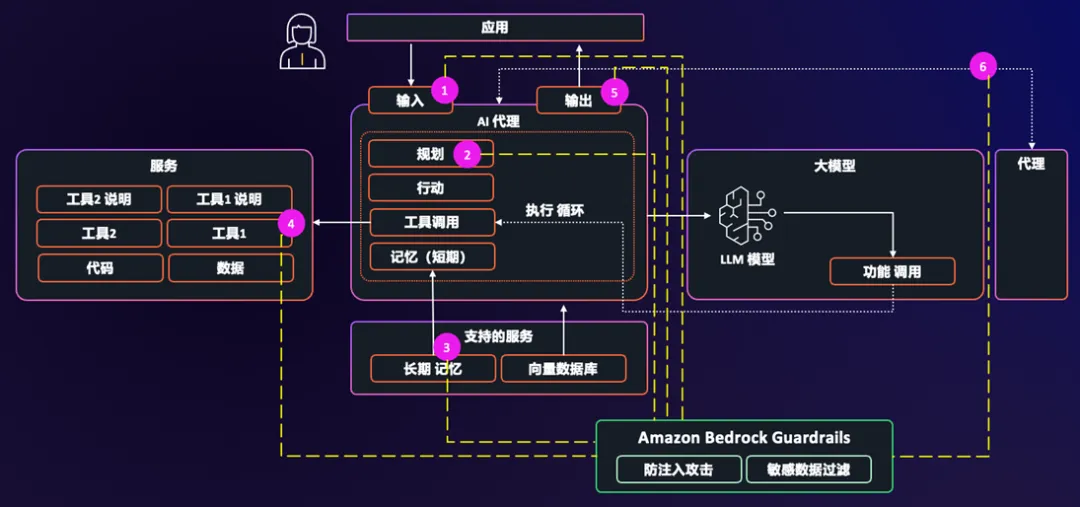
提示注入的根本性挑战在于:AI 模型无法在语义层面区分”合法指令”和”恶意注入指令”——两者对模型来说都是文本。因此,防御策略必须在注入指令到达模型之前,以及在模型输出被执行之前,设置多道屏障。
Amazon Bedrock Guardrails 为 OpenClaw 提供了四层拦截机制,覆盖从输入到输出的完整生命周期:

仅依赖 Guardrails 的单点防护仍然不足。企业级防御的关键在于架构隔离:将处理控制面逻辑的主 Agent 与处理不可信数据的子 Agent 完全隔离,通过结构化 JSON 传递数据而非原始文本,从根本上压缩攻击面。
架构原则:在多 Agent 体系中,主 Agent 负责业务逻辑协调,不直接接触不可信数据;
子 Agent 在隔离沙箱中处理外部数据,仅通过严格定义的结构化接口返回结果。
这一架构使提示注入的影响范围被限制在单个隔离的子 Agent 内,无法扩散到整个系统。
6.2 Skills 供应链安全治理
构建企业私有 ClawHub 是解决 Skills 供应链安全的根本方案。企业私有 ClawHub 可以基于Bedrock AgentCore Registry来构建,将 Skills 的引入、审查、分发全流程纳入企业安全管控。
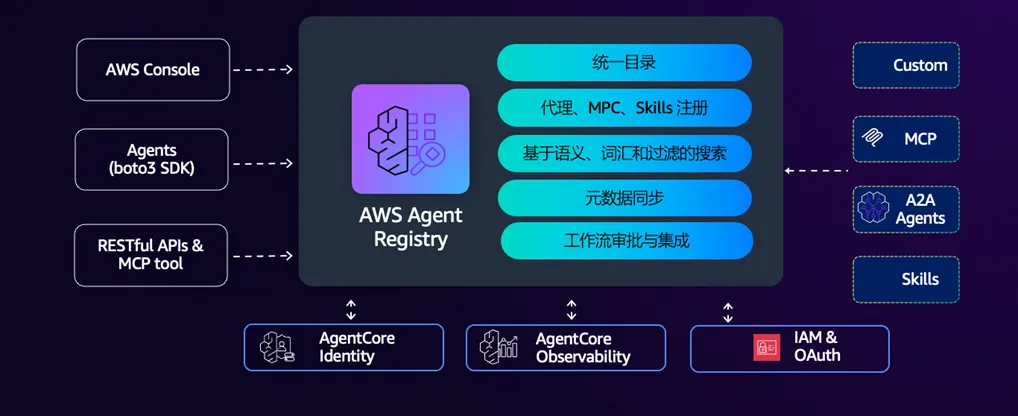
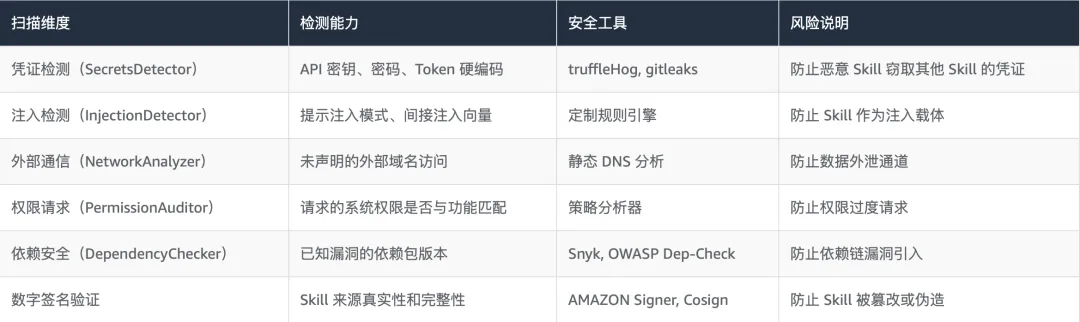
安全治理流水线的核心是 Skill Vetter:一个结合 AI 扫描和静态代码分析的自动化审查引擎,从十个维度对每个 Skill 进行安全评估:
审查通过的 Skill 经过数字签名后发布到企业私有 ClawHub,整个流程通过 CodePipeline 自动化,并在任何检测失败时自动阻断发布,同时通知安全团队人工审查。
6.3 凭证与密钥安全管理
从”裸奔”(明文存储凭证)到企业级凭证安全,是一个需要系统性演进的过程。许多企业的 OpenClaw 部署停留在不安全状态,不是因为不知道风险,而是因为缺乏清晰的改进路径。
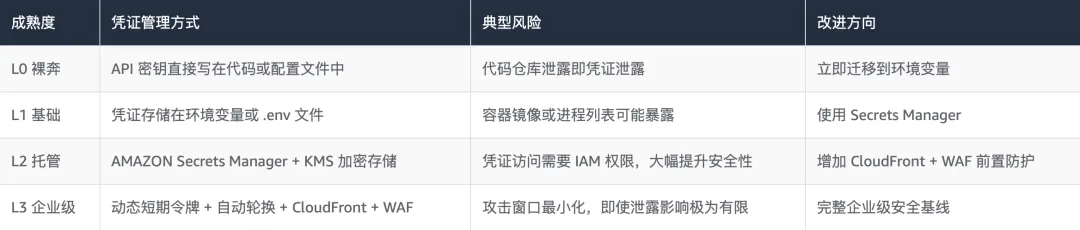
企业级凭证管理的核心是”凭证从不静止”原则:尽可能使用动态生成的短期令牌(如 AMAZON STS AssumeRole),而非长期有效的静态凭证。当凭证有效期仅为 15 分钟时,即使发生泄露,攻击者的利用窗口也极为有限。
6.4 企业数据防泄露架构
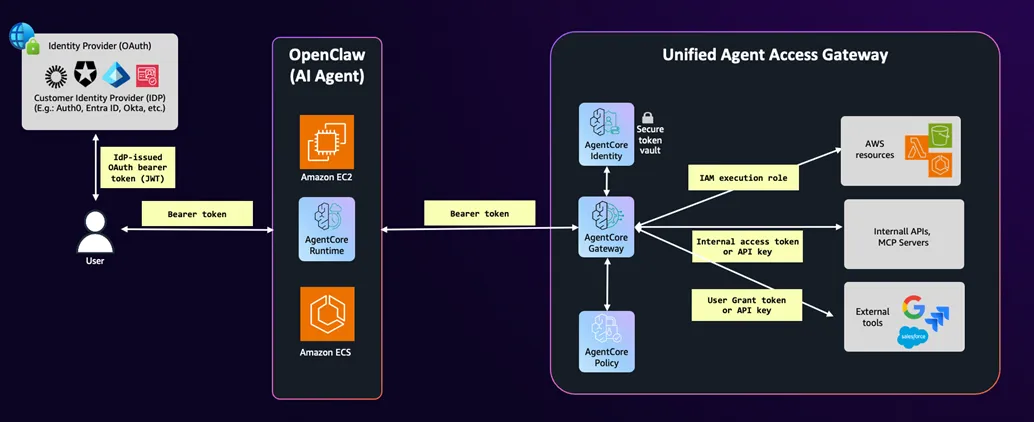
防止 Agent 成为企业数据泄露的载体,需要在访问控制和行为监控两个层面同时发力。AgentCore Gateway 的统一访问网关模式,从架构上消除了最常见的数据泄露路径。
-
终端用户身份授权:API 调用携带终端用户的身份令牌,后端服务按用户实际权限响应,不响应超出用户权限的数据请求
-
防止 Confused Deputy:在 IAM Policy 中明确约束 Agent 角色只能”代表特定用户”访问资源,禁止以 Agent 自身身份获取超范围数据
-
与企业 IDP 深度集成:支持 Azure AD、Okta、Cognito 等主流企业身份提供商,确保 Agent 的身份上下文与企业 HR/权限系统实时同步
-
数据分类标签传播:基于 AMAZON Macie 的数据分类标签,在 Agent 访问数据时自动附加敏感度标记,触发相应的访问策略
6.5 多租户隔离架构
当多个业务部门或外部客户共享同一套 OpenClaw 平台时,租户间的强隔离至关重要。数据泄露事件统计显示,多租户环境中的”邻居效应”是企业数据泄露的重要来源之一。

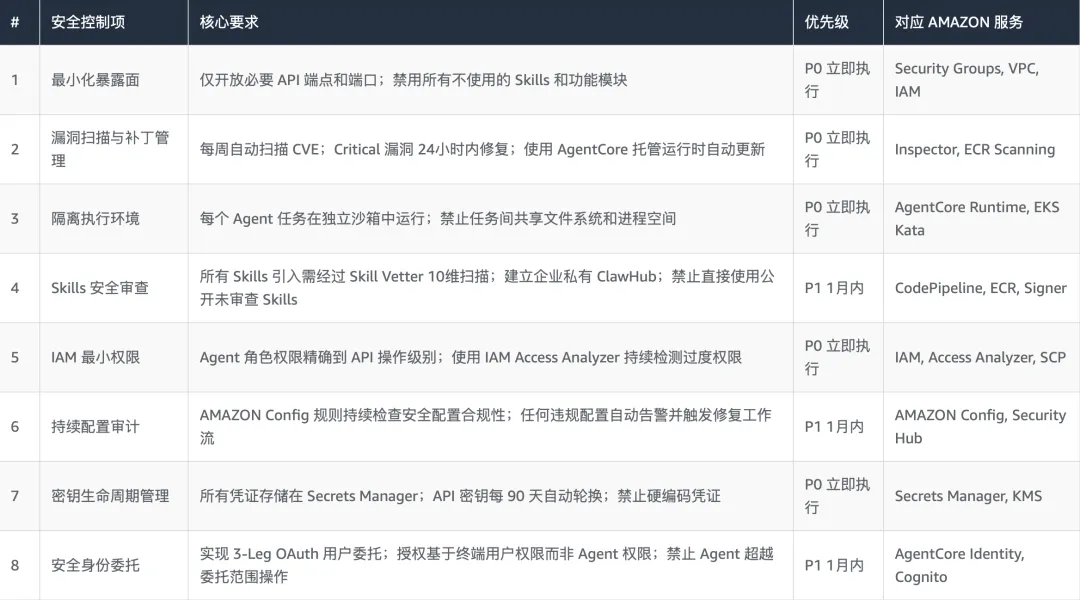
以下 12 项安全控制清单由 AMAZON AI 安全架构实践总结而来,覆盖企业部署 OpenClaw 所需的核心安全基线。每项控制均标注了优先级和所属防御层次,便于安全团队按优先级推进落地。

— END —