夜雨聆风
夜雨聆风





TensorRT-LLM 0.5.0 源码之十二
attention.py
class RotaryScalingType(IntEnum):
none = 0
linear = 1
dynamic = 2
class PositionEmbeddingType(IntEnum):
learned_absolute = 0
rope_gptj = 1
rope_gpt_neox = 2
alibi = 3
alibi_with_scale = 4
relative = 5
def is_rope(self) -> bool:
return self in [self.rope_gptj, self.rope_gpt_neox]
def is_alibi(self) -> bool:
return self in [self.alibi, self.alibi_with_scale]
@staticmethod
def choices() -> List[str]:
return [embedding.name for embedding in PositionEmbeddingType]
class AttentionMaskType(IntEnum):
padding = 0
causal = 1
bidirectional = 2
class LayerNormType(IntEnum):
LayerNorm = 0
RmsNorm = 1
GroupNorm = 2
class LayerNormPositionType(IntEnum):
pre_layernorm = 0
post_layernorm = 1AttentionParams
class AttentionParams:
def __init__(self,
sequence_length: Tensor = None,
context_lengths: Tensor = None,
host_context_lengths: Tensor = None,
max_context_length: int = None,
host_request_types: Tensor = None,
encoder_input_lengths: Tensor = None,
encoder_max_input_length: Tensor = None):
self.sequence_length = sequence_length # 当前已生成的序列长度(Token数量)
# 通常指每个序列的上下文长度。host_前缀可能表明该张量存放在主机内存而非设备上,用于需要CPU参与的逻辑
self.context_lengths = context_lengths
self.host_context_lengths = host_context_lengths
# max allowed context length. Required to
# compute scratch memory size.
self.max_context_length = max_context_length # 当前批次中最大的上下文长度,常用于计算临时内存大小。
self.host_request_types = host_request_types # 标识请求类型,例如判断是"生成"还是"编码"任务。
# 这些参数明确用于交叉注意力,在编码器-解码器架构(如T5)中,它们表示编码器侧输入的长度信息
self.encoder_input_lengths = encoder_input_lengths
self.encoder_max_input_length = encoder_max_input_length
def is_valid_cross_attn(self, do_cross_attention):
if do_cross_attention:
if self.encoder_input_lengths is None:
return False
if self.encoder_max_input_length is None:
return False
def is_valid(self, gpt_attention_plugin, remove_input_padding):
if gpt_attention_plugin:
if self.sequence_length is None:
return False
if self.context_lengths is None:
return False
if self.host_request_types is None:
return False
if self.max_context_length is None:
return False
if remove_input_padding:
if self.host_context_lengths is None:
return False
if not gpt_attention_plugin:
return False
return TrueKeyValueCacheParams
class KeyValueCacheParams:
def __init__(self,
past_key_value: List[Tensor] = None,
host_past_key_value_lengths: Tensor = None,
kv_cache_block_pointers: List[Tensor] = None,
cache_indirection: Tensor = None,
past_key_value_length: Tensor = None):
# 核心缓存数据。通常是一个列表,每个元素对应模型某一层缓存的 Key 和 Value 张量(可能是拼接在一起的)
self.past_key_value = past_key_value
# 存储在主机内存的每个序列当前缓存长度。用于让CPU知晓各序列进度,进行逻辑控制
self.host_past_key_value_lengths = host_past_key_value_lengths
# 高级内存管理指针。用于类似 vLLM 中 PagedAttention的机制,将KV Cache存储在非连续的物理内存块中,通过指针数组来映射,极大减少内存碎片,提升吞吐量
self.kv_cache_block_pointers = kv_cache_block_pointers
# 高级优化指标。在批量推理时,用于处理束搜索或动态序列管理,将逻辑序列位置映射到物理缓存位置
self.cache_indirection = cache_indirection
# self.past_key_value_length = past_key_value_length
def get_first_past_key_value(self):
if self.past_key_value is None:
return None
return self.past_key_value[0]
def get_first_kv_cache_block_pointers(self):
if self.kv_cache_block_pointers is None:
return None
return self.kv_cache_block_pointers[0]
def is_valid(self, gpt_attention_plugin):
if gpt_attention_plugin:
if self.host_past_key_value_lengths is None:
return False
if self.cache_indirection is None:
return False
return TrueAttention
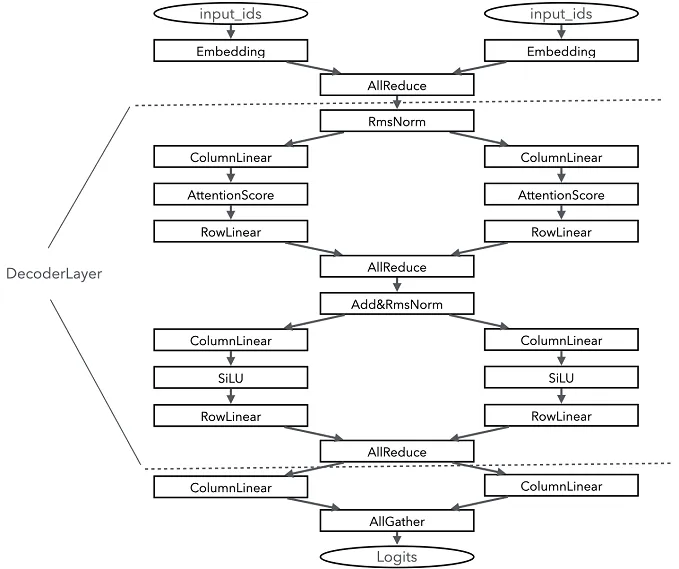
class Attention(Module):
def __init__(self,
hidden_size,
num_attention_heads,
num_kv_heads=None,
max_position_embeddings=1024,
num_layers=1,
apply_query_key_layer_scaling=False,
attention_mask_type=AttentionMaskType.padding,
bias=True,
dtype=None,
position_embedding_type=PositionEmbeddingType.learned_absolute,
rotary_embedding_base=10000.0,
rotary_embedding_scaling=None,
use_int8_kv_cache=False,
rotary_embedding_percentage=1.0,
tp_group=None,
tp_size=1,
tp_rank=0,
multi_block_mode=False,
quant_mode: QuantMode = QuantMode(0),
q_scaling=1.0,
cross_attention=False,
relative_attention=False,
max_distance=0,
num_buckets=0,
instance_id: int = 0):
super().__init__()
self.cross_attention = cross_attention
self.attention_mask_type = attention_mask_type
self.attention_head_size = hidden_size // num_attention_heads
# 安head维度做的tp分解。
# 将注意力头数均匀分配到每个设备。断言 num_attention_heads % tp_size == 0确保划分均匀,避免计算不一致
assert num_attention_heads % tp_size == 0, \
"num_attention_heads must be divisible by tp_size"
self.num_attention_heads = num_attention_heads // tp_size
# 每个设备上的隐藏层维度相应减小。
self.hidden_size = hidden_size // tp_size
# 如果键值头数(num_kv_heads)指定,则按 (num_kv_heads + tp_size - 1) // tp_size划分(向上取整);否则与查询头数相同。这允许使用比查询头更少的键值头(如GQA技术),减少计算量和内存占用
self.num_attention_kv_heads = (
num_kv_heads + tp_size - 1
) // tp_size if num_kv_heads is not None else self.num_attention_heads
self.max_position_embeddings = max_position_embeddings
self.tp_size = tp_size
self.tp_rank = tp_rank
self.num_layers = num_layers
self.apply_query_key_layer_scaling = apply_query_key_layer_scaling
# 用于缩放点积注意力分数,防止梯度消失(公式:softmax(QK^T/d_k))
self.norm_factor = math.sqrt(self.attention_head_size)
self.q_scaling = q_scaling
if self.apply_query_key_layer_scaling:
# 缩放因子会乘以层数(self.norm_factor *= self.num_layers),这有助于深层网络的训练稳定性。
self.norm_factor *= self.num_layers
self.q_scaling *= self.num_layers
# Whether to scale ALiBi bias. Mathematically, it's equivalent to
# normalizing QK after adding bias.
# - False, inv_sqrt_Dh * Q*K^T + alibi_bias
# - True, inv_sqrt_Dh * Q*K^T + inv_sqrt_Dh * alibi_bias
self.scale_alibi_bias = position_embedding_type == PositionEmbeddingType.alibi_with_scale
self.position_embedding_type = position_embedding_type
self.multi_block_mode = multi_block_mode
self.relative_attention = relative_attention
self.max_distance = max_distance
self.rotary_embedding_base = rotary_embedding_base
self.rotary_embedding_scale_type = RotaryScalingType.none
self.rotary_embedding_scale = 1.0
if rotary_embedding_scaling is not None:
assert rotary_embedding_scaling["type"] in ["linear", "dynamic"]
self.rotary_embedding_scale_type = RotaryScalingType.linear if rotary_embedding_scaling[
"type"] == "linear" else RotaryScalingType.dynamic
self.rotary_embedding_scale = rotary_embedding_scaling["factor"]
assert self.rotary_embedding_scale > 1.0
self.rotary_embedding_dim = 0
if self.position_embedding_type.is_rope():
self.rotary_embedding_dim = int(self.attention_head_size *
rotary_embedding_percentage)
# TODO: Once we add RotaryEmbedding outside GPTAttention plugin,
# we need to set it up here
self.dtype = dtype
self.quant_mode = quant_mode
if use_int8_kv_cache:
# TODO: remove use_int8_kv_cache as can be replaced by quant_mode.has_kv_cache_quant()
# Merge int8 setting into quant_mode
self.quant_mode = self.quant_mode.set_int8_kv_cache()
self.use_int8_kv_cache = use_int8_kv_cache
if self.quant_mode.has_kv_cache_quant():
self.kv_orig_quant_scale = Parameter(shape=(1, ), dtype='float32')
self.kv_quant_orig_scale = Parameter(shape=(1, ), dtype='float32')
else:
self.register_parameter('kv_orig_quant_scale', None)
self.register_parameter('kv_quant_orig_scale', None)
# The output feature size is therefore (h/tp + 2*kvh/tp) * d, where h is num_heads,
# d is head_size, kvh is the num_kv_heads and tp is tensor_parallel_size.
# In ColumnLinear op, the output dim is calculated by (h + 2*kvh) * d / tp,
# which matches the desired output size (h/tp + 2*kvh/tp) * d after splitting
self.use_fp8_qdq = self.quant_mode.has_fp8_qdq()
if self.use_fp8_qdq:
self.qkv = FP8Linear(hidden_size,
hidden_size +
(2 * tp_size * self.num_attention_kv_heads *
self.attention_head_size),
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
gather_output=False)
self.dense = FP8RowLinear(hidden_size,
hidden_size,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
instance_id=instance_id)
else:
# 将输入同时投影到Q、K、V空间。输出维度为 hidden_size + (2 * tp_size * num_attention_kv_heads * attention_head_size),对应并行环境下Q、K、V的切分。采用 列并行:权重矩阵按列切分,各设备计算部分输出,最后通过All-Gather通信拼接结果
# 2=kv
self.qkv = ColumnLinear(hidden_size,
hidden_size +
(2 * tp_size * self.num_attention_kv_heads *
self.attention_head_size),
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
gather_output=False)
self.dense = RowLinear(hidden_size,
hidden_size,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
instance_id=instance_id)
# per-layer relative attention table
if relative_attention:
self.rel_attn_table = Parameter(shape=(num_attention_heads //
tp_size, num_buckets),
dtype=dtype)
在Transformer模型中,past_key_value 的 Shape(形状) 和它的 数据结构 紧密相关,理解了它的结构,形状就很好记忆了。它的核心作用是在自回归生成(如文本生成)过程中缓存之前所有时间步计算过的键(Key)和值(Value)张量,以避免重复计算,极大提升推理效率。
为了让你快速把握全局,下面这个表格总结了其核心形状特征。
|
|
|
|
|
|---|---|---|---|
| 单层注意力 (Self-Attention) |
(past_key, past_value) |
(batch_size, num_heads, sequence_length, embed_size_per_head) |
|
| 整个模型 (所有层) |
n_layers |
|
past_key_values = ( (layer1_k, layer1_v), (layer2_k, layer2_v), ... ) |
| 整个模型 (所有输出) |
n_steps |
|
past_key_values = [Step_1( (layer1_k, layer1_v), (layer2_k, layer2_v), ... ), ..., Step_n] |
def forward(
self,
hidden_states: Tensor,
attention_mask=None,
use_cache=False,
kv_cache_params=None,
attention_params=None,
encoder_output: Optional[Tensor] = None,
workspace=None,
):
assert isinstance(hidden_states, Tensor)
alibi_slopes = None
if self.position_embedding_type.is_rope():
if not default_net().plugin_config.gpt_attention_plugin:
raise ValueError(
'RoPE is only supported with GPTAttention plugin')
elif self.position_embedding_type.is_alibi():
dtype = trt.float32
if default_net().plugin_config.gpt_attention_plugin:
dtype = hidden_states.dtype
alibi_scale = 1. / self.norm_factor if self.scale_alibi_bias else 1.
alibi_slopes = generate_alibi_slopes(self.num_attention_heads *
self.tp_size,
dtype=dtype,
tp_size=self.tp_size,
tp_rank=self.tp_rank,
alibi_scale=alibi_scale)
qkv = self.qkv(hidden_states)
paged_kv_cache = default_net().plugin_config.paged_kv_cache
assert attention_params is None or attention_params.is_valid(
default_net().plugin_config.gpt_attention_plugin,
default_net().plugin_config.remove_input_padding)
assert kv_cache_params is None or kv_cache_params.is_valid(
default_net().plugin_config.gpt_attention_plugin)
# step1
past_key_value = None if kv_cache_params is None else kv_cache_params.get_first_past_key_value(
)
if self.cross_attention and (past_key_value is not None):
past_key_value = kv_cache_params.past_key_value[1]
# if cross attention, cross QKV only needs to be calculated once in the
# 1st decoding step --> write to cross KV cache --> remains constant
# during the entire decoding. 1st and >1 steps are distinguished by
# whether past_key_value exists or not
# also, cross KV cache max length is set from encoder output seqlen,
# this maps to the max context length concept in decoder-only models
cross_qkv = None
# get length data in every run
if encoder_output:
assert isinstance(encoder_output, Tensor)
# but only do projection once at 1st decoding step
if self.cross_attention and encoder_output:
cross_qkv = self.qkv(encoder_output)
if default_net().plugin_config.gpt_attention_plugin:
assert self.attention_mask_type in [
AttentionMaskType.causal, AttentionMaskType.bidirectional
], 'Plugin only support masked MHA.'
kv_orig_quant_scale = self.kv_orig_quant_scale.value if self.quant_mode.has_kv_cache_quant(
) else None
kv_quant_orig_scale = self.kv_quant_orig_scale.value if self.quant_mode.has_kv_cache_quant(
) else None
context, past_key_value = gpt_attention(
tensor=qkv,
past_key_value=past_key_value,
sequence_length=attention_params.sequence_length,
host_past_key_value_lengths=kv_cache_params.
host_past_key_value_lengths,
context_lengths=attention_params.context_lengths,
cache_indirection=kv_cache_params.cache_indirection,
host_request_types=attention_params.host_request_types,
num_heads=self.num_attention_heads,
num_kv_heads=self.num_attention_kv_heads,
hidden_size_per_head=self.attention_head_size,
q_scaling=self.q_scaling,
rotary_embedding_dim=self.rotary_embedding_dim,
rotary_embedding_base=self.rotary_embedding_base,
rotary_embedding_scale_type=self.rotary_embedding_scale_type,
rotary_embedding_scale=self.rotary_embedding_scale,
rotary_embedding_max_positions=self.max_position_embeddings,
position_embedding_type=self.position_embedding_type,
multi_block_mode=self.multi_block_mode,
kv_orig_quant_scale=kv_orig_quant_scale,
kv_quant_orig_scale=kv_quant_orig_scale,
kv_cache_quant_mode=self.quant_mode,
max_context_length=attention_params.max_context_length,
mask_type=self.attention_mask_type,
alibi_slopes=alibi_slopes,
tp_size=self.tp_size,
tp_rank=self.tp_rank,
kv_cache_block_pointers=kv_cache_params.
get_first_kv_cache_block_pointers(),
do_cross_attention=self.cross_attention,
cross_qkv=cross_qkv,
cross_qkv_length=attention_params.encoder_max_input_length,
encoder_input_lengths=attention_params.encoder_input_lengths,
relative_attention_bias=self.rel_attn_table.value
if self.relative_attention else None,
max_distance=self.max_distance,
host_context_lengths=attention_params.host_context_lengths,
)
else:
# plain TensorRT mode
assert paged_kv_cache == False
def transpose_for_scores(x, is_kv: bool = False):
_num_attention_heads = self.num_attention_kv_heads if is_kv else self.num_attention_heads
# x [B, T, D] -> [B, T, H, D//H] -> [B, H, T, D//H]
new_x_shape = concat([
shape(x, 0),
shape(x, 1), _num_attention_heads, self.attention_head_size
])
return x.view(new_x_shape).permute([0, 2, 1, 3])
# qkv after projection is of shape
# [bs, seqlen, (num_attention_heads + 2 * num_attention_kv_heads), attention_head_size].
# [bs, seqlen, tp_size, (num_attention_heads + 2 * num_attention_kv_heads), attention_head_size].
# The projected and split qkv after transpose_for_scores():
# Q[bs, num_attention_heads, seqlen, attention_head_size]
# K[bs, num_attention_kv_heads, seqlen, attention_head_size]
# V[bs, num_attention_kv_heads, seqlen, attention_head_size]
# self.hidden_size = num_attention_heads * attention_head_size
kv_size = self.attention_head_size * self.num_attention_kv_heads
query, key, value = split(qkv, [self.hidden_size, kv_size, kv_size],
dim=2)
# in cross attention mode, replace kv by encoder_output
if self.cross_attention and encoder_output is not None:
encoder_qkv = self.qkv(encoder_output) # [B, T, D]
_, key, value = split(encoder_qkv,
[self.hidden_size, kv_size, kv_size],
dim=2)
query = transpose_for_scores(query)
key = transpose_for_scores(key, is_kv=True)
value = transpose_for_scores(value, is_kv=True)
if past_key_value is not None:
def dequantize_tensor(x, scale):
# Cast from int8 to dtype
casted_x = cast(x, self.dtype)
return casted_x * scale
if self.use_int8_kv_cache:
past_key_value = dequantize_tensor(
past_key_value, self.kv_quant_orig_scale.value)
# past_key_value [bs, 2, num_heads, max_seq_len, head_dim]
past_key, past_value = split(past_key_value, 1, dim=1)
key_shape = concat([
shape(past_key, 0),
shape(past_key, 2),
shape(past_key, 3),
shape(past_key, 4)
])
past_key = past_key.view(key_shape, zero_is_placeholder=False)
past_value = past_value.view(key_shape,
zero_is_placeholder=False)
key = concat([past_key, key], dim=2).cast(self.dtype)
value = concat([past_value, value], dim=2).cast(self.dtype)
if use_cache:
key_inflated_shape = concat([
shape(key, 0), 1,
shape(key, 1),
shape(key, 2),
shape(key, 3)
])
inflated_key = key.view(key_inflated_shape,
zero_is_placeholder=False)
inflated_value = value.view(key_inflated_shape,
zero_is_placeholder=False)
past_key_value = concat([inflated_key, inflated_value], dim=1)
if self.use_int8_kv_cache:
def quantize_tensor(x, scale):
scaled = x * scale
rounded = round(scaled)
clipped = clip(rounded, -128, 127)
quantized = cast(clipped, 'int8')
return quantized
past_key_value = quantize_tensor(
past_key_value, self.kv_orig_quant_scale.value)
key_length = shape(key, 2)
# The following code creates a 2D tensor with 0s in the lower triangular (including the diagonal) and
# +INF in the upper triangular parts. This bias tensor will be added to the output of the Q*K^T matrix
# multiplication (BMM1). The +INF elements will be transformed to 0s by the Softmax operator that
# follows. The elements that corresponds to 0s in the bias are unaffected by the bias tensor.
#
# Note that when we added to another bias tensor B (for example, with AliBi), the values in the lower-
# triangular part of the B tensor are not affected and the upper-triangular ones are set to +INF.
if self.attention_mask_type == AttentionMaskType.causal:
query_length = shape(query, 2)
starts = concat([0, 0, key_length - query_length, 0])
sizes = concat([1, 1, query_length, key_length])
select_buf = np.expand_dims(
np.tril(
np.ones((self.max_position_embeddings,
self.max_position_embeddings))).astype(bool),
(0, 1))
select_buf = np.logical_not(select_buf)
mask_buf = np.zeros_like(select_buf, np.float32)
mask_buf[select_buf] = float('-inf')
buffer = constant(mask_buf)
causal_mask = slice(buffer, starts, sizes)
if attention_mask is not None:
attention_mask = expand_mask(attention_mask, shape(query, 2))
bias = attention_mask
if self.position_embedding_type.is_alibi():
alibi_biases = generate_alibi_biases(alibi_slopes, key_length)
bias = alibi_biases if bias is None else bias + alibi_biases
key = key.permute([0, 1, 3, 2])
with precision('float32'):
attention_scores = matmul(cast(query, 'float32'),
cast(key, 'float32'))
attention_scores = attention_scores / self.norm_factor
if self.attention_mask_type == AttentionMaskType.causal:
bias = causal_mask if bias is None else bias + causal_mask
if bias is not None and not self.cross_attention:
attention_scores = attention_scores + bias
attention_probs = softmax(attention_scores, dim=-1)
context = matmul(attention_probs, value).permute([0, 2, 1, 3])
context = context.view(
concat([shape(context, 0),
shape(context, 1), self.hidden_size]))
context = self.dense(context, workspace)
if use_cache:
return (context, past_key_value)
else:
return context@gw.record_signature
def gpt_attention(
tensor: Tensor,
past_key_value: Tensor,
sequence_length: Tensor,
host_past_key_value_lengths: Tensor,
context_lengths: Tensor,
cache_indirection: Tensor,
host_request_types: Tensor,
num_heads: int,
num_kv_heads: int,
hidden_size_per_head: int,
q_scaling: float,
rotary_embedding_dim: int,
rotary_embedding_base: float = 10000.0,
rotary_embedding_scale_type: RotaryScalingType = RotaryScalingType.none,
rotary_embedding_scale: float = 1.0,
rotary_embedding_max_positions: int = 1024,
position_embedding_type: PositionEmbeddingType = PositionEmbeddingType.
learned_absolute,
multi_block_mode: bool = False,
kv_orig_quant_scale: Tensor = None,
kv_quant_orig_scale: Tensor = None,
kv_cache_quant_mode: QuantMode = None,
max_context_length: int = None,
mask_type: AttentionMaskType = AttentionMaskType.causal,
alibi_slopes: Tensor = None,
tp_size: int = 1,
tp_rank: int = 0,
kv_cache_block_pointers: Tensor = None,
do_cross_attention: bool = False,
cross_qkv: Tensor = None, # for cross attention
cross_qkv_length: Tensor = None, # for cross attention
encoder_input_lengths: Tensor = None, # for cross attention
relative_attention_bias: Tensor = None, # for relative attention
max_distance: int = 0, # for relative attention
host_context_lengths: Tensor = None, # for pad-free input mode
qkv_bias: Tensor = None) -> Tuple[Tensor]:
'''
Add an operation that performs the multi-head attention in GPT-like models.
The signature of the function will change in the future release - we are in
the process of simplifying the API. The current version is still
work-in-progress! The following API is provided with hints regarding the
arguments that are likely to be removed or merged with others in the future
release.
See docs/gpt_attention.md for the documentation of that function.
Parameters:
tensor: Tensor
The input QKV tensor. Its shape is [batch_beam_size, max_seqlen, 3
* hidden_dim] in padded mode and [1, num_tokens, 3 * hidden_dim] in
packed mode. See QKV Input in docs/gpt_attention.md.
past_key_value: Tensor
The tensor that stores KV cache data. Its shape is
[max_batch_size * max_beam_width, 2, num_heads, max_seqlen, hidden_dim_per_head]
in contiguous mode and
[max_blocks, 2, num_heads, num_tokens_per_block, hidden_dim_per_head]
in paged mode. See KV Cache in docs/gpt_attention.md,
sequence_lengths: Tensor
The tensor that stores the length of each sequence. Its shape is
[batch_size]. See QKV Input in docs/gpt_attention.md,
host past_key_value_length: Tensor
An INT32 tensor of shape [batch_size].
context_lengths: Tensor
The tensor that stores the context-phase sequence length of each request. Its shape
is [batch_size]. See QKV Input in doc/functional.py,
cache_indirection: Tensor
The tensor to reconstruct the paths when using beam-search. Its
shape is [batch_size, beam_width, max_seqlen]. See Beam-Search in
docs/gpt_attention.md,
host_request_types: Tensor = None
The tensor on the host that indicates if a request is in context or
generation phase. Its shape is [batch_size]. See Inflight Batching
in docs/gpt_attention.md,
num_heads: int
The number of heads,
num_kv_heads: int
The number of KV heads, generic to handle MHA/MQA/GQA,
hidden_size_per_head: int
The hidden size per head,
q_scaling: float
The value used to compute the scaling factor applied to the output
of the Q*K^T product. See Scaling Factors in docs/gpt_attention.md,
rotary_embedding_dim: int
The dimension to compute RoPE. Use 0 when position_embedding_type is not RoPE.
rotary_embedding_base: float
The theta value to use for RoPE. Ignored when position_embedding_type is not RoPE.
rotary_embedding_scale_type: RotaryScalingType
The scaling type of RoPE. Ignored when position_embedding_type is not RoPE.
Possible rotary scaling type:
* RotaryScalingType.none
* RotaryScalingType.linear
* RotaryScalingType.dynamic
rotary_embedding_scale: float
The scale value to use for linear/dynamic scaling in RoPE.
Ignored when position_embedding_type is not RoPE.
Must be set to 1 (default) if rotary_embedding_scale_type is `none`.
rotary_embedding_max_positions: int
Needed only for `dynamic` RoPE scaling. Ignored otherwise.
position_embedding_type: PositionEmbeddingType
The position embedding type:
* PositionEmbeddingType.learned_absolute
* PositionEmbeddingType.relative
* PositionEmbeddingType.rope_gptj
* PositionEmbeddingType.rope_gpt_neox
* PositionEmbeddingType.alibi
* PositionEmbeddingType.alibi_with_scale
multi_block_mode: bool
Do we enable multi-block for the masked MHA. See Generation Phase
in docs/gpt_attention.md,
kv_orig_quant_scale: Tensor
The tensor to store the scaling factor for quantization to INT8/FP8
in the KV cache. Its shape is [1]. See INT8/FP8 KV Cache in
docs/gpt_attention.md,
kv_quant_orig_scale: Tensor
The tensor to store the scaling factor for dequantization from
INT8/FP8 in the KV cache. Its shape is [1]. See INT8/FP8 KV Cache
in docs/gpt_attention.md,
kv_cache_quant_mode: QuantMode (int flags)
Do we enable the INT8 or FP8 KV cache?
max_context_length: int32_t
The length of the longest input sequence. See QKV Input in
docs/gpt_attention.md,
mask_type: int = 1
The type of mask:
* tensorrt_llm.layers.AttentionMaskType.padding for BERT,
* tensorrt_llm.layers.AttentionMaskType.causal for GPT,
* tensorrt_llm.layers.AttentionMaskType.bidirectional for ChatGLM,
alibi_slopes: Tensor
The ALiBi slopes. The ALiBi bias is computed on-the-fly in the kernel
when possible,
tp_size: int
The number of processes/GPUs when tensor parallelism is activated,
tp_rank: int
The rank of that process (when running tensor parallelism),
kv_cache_block_pointers:
The tensor of block pointers for the KV cache. Its shape is
[max_batch_size, max_beam_width, 2, max_blocks_per_sequence * 2]
See KV cache section in docs/gpt_attention.md,
do_cross_attention: bool = False
Do we use this as cross attention instead of self attention,
cross_qkv: Tensor = None
The QKV tensor of encoder output hidden states. Its shape is [batch_size, max_seqlen, 3
* hidden_dim] in padded mode and [1, num_tokens, 3 * hidden_dim] in
packed mode,
cross_qkv_length: Tensor = None
The length of the longest encoder output sequence,
encoder_input_lengths: Tensor
The tensor that stores the length of each encoder input sequence. Its shape is [batch_size],
relative_attention_bias: Tensor = None
The relative attention bias [num_heads, max_seq_len, max_seq_len], or The relative attention embedding table for implicit mode, [num_heads, num_buckets].
max_distance: int = 0
The maximum distance of relative position in attention, for implicit mode.
Default value is 0, meaning to use the regular mode of relative attention bias.
Implicit mode is only enabled when passing in non-zero positive max_distance value.
See relative attention bias in docs/gpt_attention.md
host_context_lengths: Tensor = None
A host tensor that contains the lengths of the different inputs,
qkv_bias: Tensor = None,
Returns:
The tensor produced by that layer.
'''
assert host_request_types is not None
assert (alibi_slopes is not None) == (position_embedding_type.is_alibi())
attn_plg_creator = trt.get_plugin_registry().get_plugin_creator(
'GPTAttention', '1', TRT_LLM_PLUGIN_NAMESPACE)
assert attn_plg_creator is not None
assert host_context_lengths is not None or not default_net(
).plugin_config.remove_input_padding
assert isinstance(max_context_length, int)
paged_kv_cache_flag = default_net().plugin_config.paged_kv_cache
nheads = trt.PluginField("num_heads", np.array(num_heads, dtype=np.int32),
trt.PluginFieldType.INT32)
num_kv_heads = trt.PluginField("num_kv_heads",
np.array(num_kv_heads, dtype=np.int32),
trt.PluginFieldType.INT32)
head_size = trt.PluginField("head_size",
np.array(hidden_size_per_head, dtype=np.int32),
trt.PluginFieldType.INT32)
unidirectional = trt.PluginField("unidirectional",
np.array(1, dtype=np.int32),
trt.PluginFieldType.INT32)
q_scaling = trt.PluginField("q_scaling",
np.array(q_scaling, dtype=np.float32),
trt.PluginFieldType.FLOAT32)
rotary_embedding_dim = trt.PluginField(
"rotary_embedding_dim", np.array(rotary_embedding_dim, dtype=np.int32),
trt.PluginFieldType.INT32)
rotary_embedding_base = trt.PluginField(
"rotary_embedding_base",
np.array(rotary_embedding_base, dtype=np.float32),
trt.PluginFieldType.FLOAT32)
rotary_embedding_scale_type = trt.PluginField(
"rotary_embedding_scale_type",
np.array(rotary_embedding_scale_type, dtype=np.int8),
trt.PluginFieldType.INT8)
rotary_embedding_scale = trt.PluginField(
"rotary_embedding_scale",
np.array(rotary_embedding_scale, dtype=np.float32),
trt.PluginFieldType.FLOAT32)
rotary_embedding_max_positions = trt.PluginField(
"rotary_embedding_max_positions",
np.array(rotary_embedding_max_positions, dtype=np.int32),
trt.PluginFieldType.INT32)
position_embedding_type = trt.PluginField(
"position_embedding_type",
np.array(int(position_embedding_type), dtype=np.int8),
trt.PluginFieldType.INT8)
context_fmha_type = trt.PluginField(
"context_fmha_type",
np.array(np.int8(default_net().plugin_config.context_fmha_type),
dtype=np.int8), trt.PluginFieldType.INT8)
remove_input_padding = trt.PluginField(
"remove_input_padding",
np.array(np.int8(default_net().plugin_config.remove_input_padding),
dtype=np.int8), trt.PluginFieldType.INT8)
p_dtype = default_net().plugin_config.gpt_attention_plugin
pf_type = trt.PluginField(
"type_id", np.array([int(str_dtype_to_trt(p_dtype))], np.int32),
trt.PluginFieldType.INT32)
mask_type = trt.PluginField("mask_type", np.array([int(mask_type)],
np.int32),
trt.PluginFieldType.INT32)
multi_block_mode = trt.PluginField(
"multi_block_mode", np.array(np.int8(multi_block_mode), dtype=np.int8),
trt.PluginFieldType.INT8)
tp_size = trt.PluginField("tp_size", np.array(tp_size, dtype=np.int32),
trt.PluginFieldType.INT32)
tp_rank = trt.PluginField("tp_rank", np.array(tp_rank, dtype=np.int32),
trt.PluginFieldType.INT32)
kv_cache_quant_mode_field = trt.PluginField(
"kv_cache_quant_mode",
np.array(np.int8(kv_cache_quant_mode), dtype=np.int32),
trt.PluginFieldType.INT32)
paged_kv_cache = trt.PluginField(
"paged_kv_cache", np.array(paged_kv_cache_flag, dtype=np.int32),
trt.PluginFieldType.INT32)
tokens_per_block = trt.PluginField(
"tokens_per_block",
np.array(default_net().plugin_config.tokens_per_block, dtype=np.int32),
trt.PluginFieldType.INT32)
max_context_length = trt.PluginField("max_context_length",
np.array(max_context_length, np.int32),
trt.PluginFieldType.INT32)
if qkv_bias is None:
qkv_bias_enabled = trt.PluginField("qkv_bias_enabled",
np.array(0, dtype=np.int8),
trt.PluginFieldType.INT8)
else:
qkv_bias_enabled = trt.PluginField("qkv_bias_enabled",
np.array(1, dtype=np.int8),
trt.PluginFieldType.INT8)
do_cross_attention_field = trt.PluginField(
"do_cross_attention",
np.array(np.int8(do_cross_attention), dtype=np.int8),
trt.PluginFieldType.INT8)
max_distance = trt.PluginField("max_distance",
np.array(max_distance, dtype=np.int32),
trt.PluginFieldType.INT32)
pfc = trt.PluginFieldCollection([
nheads, num_kv_heads, head_size, unidirectional, q_scaling,
position_embedding_type, rotary_embedding_dim, rotary_embedding_base,
rotary_embedding_scale_type, rotary_embedding_scale,
rotary_embedding_max_positions, tp_size, tp_rank, context_fmha_type,
multi_block_mode, kv_cache_quant_mode_field, remove_input_padding,
mask_type, paged_kv_cache, tokens_per_block, pf_type,
max_context_length, qkv_bias_enabled, do_cross_attention_field,
max_distance
])
attn_plug = attn_plg_creator.create_plugin("causal_attn", pfc)
plug_inputs = [
tensor,
sequence_length,
host_past_key_value_lengths,
context_lengths,
cache_indirection,
host_request_types,
]
if paged_kv_cache_flag:
plug_inputs += [kv_cache_block_pointers]
else:
plug_inputs += [past_key_value]
if kv_cache_quant_mode.has_kv_cache_quant():
plug_inputs += [kv_orig_quant_scale, kv_quant_orig_scale]
if alibi_slopes is not None:
plug_inputs += [alibi_slopes]
if relative_attention_bias is not None:
plug_inputs += [relative_attention_bias]
if do_cross_attention:
plug_inputs += [cross_qkv, cross_qkv_length, encoder_input_lengths]
if default_net().plugin_config.remove_input_padding:
plug_inputs += [host_context_lengths]
if qkv_bias is not None:
plug_inputs += [qkv_bias]
plug_inputs = [i.trt_tensor for i in plug_inputs]
layer = default_trtnet().add_plugin_v2(plug_inputs, attn_plug)
output = _create_tensor(layer.get_output(0), layer)
present_key_value = None
if not paged_kv_cache_flag:
present_key_value = _create_tensor(layer.get_output(1), layer)
assert present_key_value is not None
expected_outputs = 2
else:
expected_outputs = 1
assert layer.num_outputs == expected_outputs, \
f"Plugin outputs number mismatch with expected, got {layer.num_outputs}, expected {expected_outputs}"
if kv_cache_quant_mode.has_int8_kv_cache() and not paged_kv_cache_flag:
# past key value
layer.get_input(6).set_dynamic_range(-127, 127)
# present key value
layer.get_output(1).set_dynamic_range(-127, 127)
assert output is not None
return output, present_key_value
BertAttention
class BertAttention(Module):
def __init__(self,
hidden_size,
num_attention_heads,
num_kv_heads=None,
max_position_embeddings=1024,
num_layers=1,
q_scaling=1.0,
apply_query_key_layer_scaling=False,
bias=True,
dtype=None,
tp_group=None,
tp_size=1,
tp_rank=0,
relative_attention=False,
max_distance=0,
num_buckets=0):
super().__init__()
self.attention_head_size = hidden_size // num_attention_heads
self.num_attention_heads = num_attention_heads // tp_size
self.num_attention_kv_heads = (
num_kv_heads + tp_size - 1
) // tp_size if num_kv_heads is not None else self.num_attention_heads
self.hidden_size = hidden_size // tp_size
self.max_position_embeddings = max_position_embeddings
self.norm_factor = math.sqrt(self.attention_head_size)
self.tp_size = tp_size
self.tp_rank = tp_rank
self.num_layers = num_layers
self.apply_query_key_layer_scaling = apply_query_key_layer_scaling
self.norm_factor = math.sqrt(self.attention_head_size)
self.q_scaling = q_scaling
if self.apply_query_key_layer_scaling:
self.norm_factor *= self.num_layers
self.q_scaling *= self.num_layers
self.dtype = dtype
self.relative_attention = relative_attention
self.max_distance = max_distance
self.qkv = ColumnLinear(hidden_size,
hidden_size +
(2 * tp_size * self.num_attention_kv_heads *
self.attention_head_size),
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size,
gather_output=False)
self.dense = RowLinear(hidden_size,
hidden_size,
bias=bias,
dtype=dtype,
tp_group=tp_group,
tp_size=tp_size)
# per-layer relative attention table
if relative_attention:
self.rel_attn_table = Parameter(shape=(num_attention_heads //
tp_size, num_buckets),
dtype=dtype)
def forward(self,
hidden_states: Tensor,
attention_mask=None,
input_lengths=None):
assert isinstance(hidden_states, Tensor)
qkv = self.qkv(hidden_states)
if default_net().plugin_config.bert_attention_plugin:
# TRT plugin mode
assert input_lengths is not None
context = bert_attention(
qkv,
input_lengths,
self.num_attention_heads,
self.attention_head_size,
q_scaling=self.q_scaling,
relative_attention=self.relative_attention,
max_distance=self.max_distance,
relative_attention_bias=self.rel_attn_table.value
if self.relative_attention else None)
else:
# plain TRT mode
def transpose_for_scores(x):
new_x_shape = concat([
shape(x, 0),
shape(x, 1), self.num_attention_heads,
self.attention_head_size
])
return x.view(new_x_shape).permute([0, 2, 1, 3])
query, key, value = split(qkv, self.hidden_size, dim=2)
query = transpose_for_scores(query)
key = transpose_for_scores(key)
value = transpose_for_scores(value)
key = key.permute([0, 1, 3, 2])
attention_scores = matmul(query, key)
attention_scores = attention_scores / self.norm_factor
if attention_mask is not None:
attention_scores = attention_scores + attention_mask
attention_probs = softmax(attention_scores, dim=-1)
context = matmul(attention_probs, value).permute([0, 2, 1, 3])
context = context.view(
concat([shape(context, 0),
shape(context, 1), self.hidden_size]))
context = self.dense(context)
return context# tensor是packed的,即no-padding。
def bert_attention(tensor: Tensor,
input_lengths: Tensor,
num_heads: int,
head_size: int,
q_scaling: float,
relative_attention: bool = False,
relative_attention_bias: Tensor = None,
max_distance: int = 0) -> Tuple[Tensor]:
'''
Add an operation that performs the multi-head attention in BERT.
The multihead-attention (MHA) is the sequence of a batched matmul, a
softmax and a batched matmul as described in
https://arxiv.org/abs/1706.03762. That function adds an operation that
performs those computations using a single GPU kernel.
The input tensor contains the Q, K and V elements. It is a 2D tensor and
its shape is '[sum_of_tokens, 3*hidden_dim]' where the 'sum_of_tokens' is
the sum of the sequence lengths in the batch.
In MHA, the output of the Q*K^T product is scaled by a constant value that
is computed as:
1.f / (q_scaling * sqrt(head_size)).
That 'q_scaling' constant is the last argument of that function.
That layer is implemented using a plugin (see bertAttentionPlugin).
Parameters:
tensor : Tensor
The QKV input tensor.
input_lengths : Tensor
The length of each sequence. It is a 1D tensor of size 'batch_size'.
num_heads : int
The number of heads.
head_size : int
The size of each head.
q_scaling : float
The factor to compute the scaling factor to scale the output of the
'Q*K^T' product.
relative_attention: bool = False
If enable relative attention.
relative_attention_bias: Tensor = None
The relative attention bias [num_heads, max_seq_len, max_seq_len], or The relative attention embedding table for implicit mode, [num_heads, num_buckets].
max_distance: int = 0
The maximum distance of relative position in attention, for implicit mode.
Default value is 0, meaning to use the regular mode of relative attention bias.
Implicit mode is only enabled when passing in non-zero positive max_distance value.
See relative attention bias in docs/gpt_attention.md
Returns:
The tensor produced by that layer.
'''
attn_plg_creator = trt.get_plugin_registry().get_plugin_creator(
'BertAttention', '1', TRT_LLM_PLUGIN_NAMESPACE)
assert attn_plg_creator is not None
nheads = trt.PluginField("num_heads", np.array(num_heads, dtype=np.int32),
trt.PluginFieldType.INT32)
head_size = trt.PluginField("head_size", np.array(head_size,
dtype=np.int32),
trt.PluginFieldType.INT32)
q_scaling = trt.PluginField("q_scaling",
np.array(q_scaling, dtype=np.float32),
trt.PluginFieldType.FLOAT32)
enable_qk_half_accum = trt.PluginField(
"enable_qk_half_accum",
np.array(np.int8(
default_net().plugin_config.attention_qk_half_accumulation),
dtype=np.int8), trt.PluginFieldType.INT8)
context_fmha_type = trt.PluginField(
"context_fmha_type",
np.array(np.int8(default_net().plugin_config.context_fmha_type),
dtype=np.int8), trt.PluginFieldType.INT8)
p_dtype = default_net().plugin_config.bert_attention_plugin
pf_type = trt.PluginField(
"type_id", np.array([int(str_dtype_to_trt(p_dtype))], np.int32),
trt.PluginFieldType.INT32)
do_relative_attention = trt.PluginField(
"do_relative_attention",
np.array(np.int8(relative_attention), dtype=np.int8),
trt.PluginFieldType.INT8)
max_distance = trt.PluginField("max_distance",
np.array(max_distance, dtype=np.int32),
trt.PluginFieldType.INT32)
pfc = trt.PluginFieldCollection([
nheads, head_size, q_scaling, enable_qk_half_accum, context_fmha_type,
pf_type, do_relative_attention, max_distance
])
attn_plug = attn_plg_creator.create_plugin("padding_attn", pfc)
plug_inputs = [tensor, input_lengths]
if relative_attention_bias is not None:
plug_inputs += [relative_attention_bias]
plug_inputs = [i.trt_tensor for i in plug_inputs]
layer = default_trtnet().add_plugin_v2(plug_inputs, attn_plug)
assert layer.num_outputs == 1, \
f"Plugin outputs number mismatch with expected, got {layer.num_outputs}, expected 1"
output = _create_tensor(layer.get_output(0), layer)
assert output is not None
return outputOthers
def generate_alibi_slopes(num_heads: int,
dtype: trt.DataType = trt.float32,
tp_size: int = 1,
tp_rank: int = 0,
alibi_scale: float = 1.0) -> Tensor:
'''
Compute the ALiBi slopes as described in https://arxiv.org/abs/2211.05100.
Parameters:
num_heads : int
The number of heads.
dtype : trt.DataType
The data type of the returned slopes
tp_size : int
The tensor parallelism size
tp_rank : int
The tensor parallelism rank
Returns:
A constant tensor that contains the ALiBi slopes.
'''
start_head_id = 0
end_head_id = num_heads
if tp_size > 1:
rank_heads = num_heads // tp_size
start_head_id = rank_heads * tp_rank
end_head_id = start_head_id + rank_heads
closest_power_of_2 = 2**np.floor(np.log2(num_heads))
# FT's implementation
# https://github.com/NVIDIA/FasterTransformer/blob/main/src/fastertransformer/kernels/gen_relative_pos_bias.cu#L248
slopes_ft = []
for h_id in range(start_head_id, end_head_id):
if h_id < closest_power_of_2:
slopes_ft.append(
np.power(2**(-(2**-(np.log2(closest_power_of_2) - 3))),
h_id + 1))
else:
slopes_ft.append(
np.power(2**(-(2**-(np.log2(closest_power_of_2 * 2) - 3))),
(h_id - closest_power_of_2) * 2 + 1))
slopes = np.asarray(slopes_ft, dtype=np.float32)
slopes = alibi_scale * slopes
# Note that for bfloat16, we cannot case numpy tensor from float32 to bfloat16
# becuases numpy does not support bfloat16. Even if we use custom type to define
# the np_bfloat16, the "astype" here would be undefined.
# So, we must use torch to cast tensor from float32 to bfloat16, and then use torch_to_numpy
# to cast the tensor back.
slopes = torch.from_numpy(slopes)
slopes = slopes.to(trt_dtype_to_torch(dtype))
slopes = torch_to_numpy(slopes)
slopes = constant(slopes.reshape(1, (end_head_id - start_head_id), 1, 1))
return slopes
def generate_alibi_biases(slopes: Tensor, key_length: Tensor) -> Tensor:
'''
Compute the ALiBi biases as described in https://arxiv.org/abs/2211.05100.
The ALiBi biases are added to the result of the Q*K^T product in the
multihead-attention block.
Parameters:
slopes : Tensor
The slopes.
key_length : Tensor
The size of the K vector per head.
Returns:
A constant tensor that contains the ALiBi biases.
'''
# We don't need to care about the batch size or query length since we can just broadcast
# across the batch and query dimensions
trt_0 = constant(int32_array(0))
arange_shape = concat([1, 1, 1, key_length])
arange_tensor = arange(trt_0, key_length, "float32").view(arange_shape)
arange_tensor = cast(arange_tensor, "float32")
return slopes * arange_tensordef expand_mask(mask: Tensor, tgt_len: Optional[Tensor] = None) -> Tensor:
'''
Expand an attention mask.
That function adds the sequence of operations to expand from a tensor of
shape '[batch_size, src_seq_len]' to a tensor of shape
'[batch_size, 1, tgt_seq_len, src_seq_len]'. It can be used to create the
mask applied to the Q*K^T product before the softmax operation in the
multihead-attention block.
Parameters:
mask : Tensor
The input mask
tgt_len : Optional[Tensor]
The dimension of the 3rd dimension in the output tensor. If None,
the 2nd dimension of the input is used.
Returns:
The tensor created by that sequence of operations.
'''
bsz = shape(mask, 0)
src_len = shape(mask, 1)
tgt_len = tgt_len if tgt_len is not None else src_len
mask = mask.view(concat([bsz, 1, 1, src_len]))
mask = expand(mask, concat([bsz, 1, tgt_len, src_len]))
mask = where(mask == 0, float('-inf'), (1 - mask).cast('float32'))
return maskdef gather_last_token_logits(hidden_states: Tensor, last_token_ids: Tensor,
remove_input_padding: bool) -> Tensor:
'''
Extract the logits that correspond to the last token from the hidden states.
That function adds the operations to extract the logits of the last tokens
in a batch of sequences.
Depending on whether 'remove_input_padding' is 'True' or 'False', that
function assumes inputs of different shapes.
When 'remove_input_padding' is 'True', the 'hidden_states' tensor is
assumed to be packed. It has a shape '[num_tokens, hidden_dim]' where
'num_tokens' is the sum of the lengths of the sequences in the batch and
'hidden_dim' is the hidden dimension. The 'last_tokens_ids' is a 1D tensor
that encodes the inclusive prefix-sums of the lengths of the sequences in
the batch.
When 'remove_input_padding' is 'False', the 'hidden_states' tensor is
assumed to be padded. It has a shape '[batch_size, max_seqlen, hidden_dim]'
where 'max_seqlen' is the length of the longest sequence in the batch and
'hidden_dim' is the hidden dimension. The 'last_token_ids' is a 1D tensor
that encodes the length of each sequence in the batch.
In both cases, that function produces a tensor of shape '[batch_size,
hidden_size]' where the row at index 'i' corresponds to the logits of the
last token from the 'i'-th sequence.
Parameters:
hidden_states : Tensor
The hidden states
last_token_ids : Tensor
The inclusive prefix-sum of the lengths or the lenghts of the
sequences in the batch.
remove_input_padding : bool
Indicate if the hidden_states are packed ('True') or padded
('False').
Returns:
The tensor created by that sequence of operations.
'''
if last_token_ids is None:
return hidden_states
if remove_input_padding:
# hidden_states.shape = [1, num_tokens, hidden_dim]
# last_token_ids.shape = (B,)
hidden_states = index_select(hidden_states, 1,
last_token_ids - 1) # [1, seq_len, hidden]
hidden_states = hidden_states.view(
concat([shape(last_token_ids, 0),
shape(hidden_states, 2)])) # [B, D]
else:
# only calculate logits for the last token
# [batch_size, seqlen, hidden_size] -> [batch_size, hidden_size]
last_token_ids = last_token_ids.view(
concat([shape(last_token_ids, 0), 1, 1]))
last_token_ids = expand(
last_token_ids,
concat([shape(last_token_ids, 0), 1,
shape(hidden_states, 2)]))
last_token_ids = last_token_ids - 1
hidden_states = gather(
hidden_states, dim=1, indices=last_token_ids).view(
concat([shape(hidden_states, 0),
shape(hidden_states, 2)]))
return hidden_states参考文献
-
• https://github.com/NVIDIA/TensorRT-LLM/blob/v0.5.0/tensorrt_llm/layers/attention.py