 夜雨聆风
夜雨聆风





【OpenClaw】通过 Nanobot 源码学习架构—(9)周期性执行
【OpenClaw】通过 Nanobot 源码学习架构—(9)周期性执行
-
0x00 概要 -
0x01 基本知识 -
1.1 需求 -
1.2 问题 -
1.3 价值 -
1.4 Claw0 -
1.5 ZeroClaw -
0x02 SKILL.md -
2.1 核心工作模式 -
2.2 核心操作 -
2.3 时间配置 -
2.4 代码 -
0x03 核心组件 -
3.1 依赖关系 -
3.2 模块架构 -
3.3 详细流程 -
0x04 CronTool类 -
4.1 核心特色 -
4.2 重点功能 -
4.3 代码 -
0x05 CronService -
5.1 核心特色 -
5.2 AgentLoop与CronService完整集成流程 -
5.3 内部调度流程 -
5.4 代码 -
0xFF 参考
0x00 概要
OpenClaw 应该有40万行代码,阅读理解起来难度过大,因此,本系列通过Nanobot来学习 OpenClaw 的特色。
Nanobot是由香港大学数据科学实验室(HKUDS)开源的超轻量级个人 AI 助手框架,定位为”Ultra-Lightweight OpenClaw“。非常适合学习Agent架构。
Nanobot项目通过 CronService 和 CronTool 实现周期性任务:CronTool 作为面向 LLM 的接口,CronService 作为实际的业务逻辑执行者,两者通过依赖注入的方式协作,形成了一个完整的定时任务管理解决方案。
该方案通过三种模式覆盖:提醒、周期性任务、一次性任务的所有典型调度需求;通过 “简易参数 + 标准表达式” 的双轨时间配置,兼顾普通用户与专业用户的使用习惯;通过完整的任务生命周期管理与时区适配,解决了实际使用中的核心痛点。
该技能的落地,让 AI Agent 真正具备了 “时间驱动的主动执行能力”,是实现 Agent 从 “交互工具” 向 “自动化助手” 升级的关键一步,同时其轻量化的设计思路,也为 AI Agent 体系中其他能力组件的设计提供了参考 —— 贴合真实需求、降低使用门槛、实现能力闭环。
注:因为最近看的文章太多,所以如果有遗漏参考资料,还请读者指出,谢谢。
0x01 基本知识
1.1 需求
传统的定时任务(Cron Job)是僵化的,它只能在固定时间触发固定逻辑。随着大语言模型(LLM)的成熟,智能任务系统已成为AI应用的核心竞争点。这些任务的核心逻辑高度一致:将原本需要用户手动输入的提示词,转化为可在预定时间或周期内自动运行的工作流。这意味着即使用户处于离线状态,任务也会在云端自动执行,并在完成后通过通知系统将结果(如摘要、提醒)精准推送到用户面前。
如果将任务的触发时机由简单的“时间设定”扩展为由“事件变更”驱动,系统便进化为基于AI Agent的智能订阅任务。相比于传统模式,智能订阅任务具备三大核心优势:
-
事件驱动(Event-Driven):不仅支持Cron表达式的时间触发,更支持外部数据(如油价波动、天气预警)的变化触发,灵活性显著提升。 -
智能判断:利用大模型的语义理解能力,系统可以对复杂的触发条件进行逻辑判断,而非简单的阈值匹配。 -
高度个性化:用户可以通过自然语言直接定义任务,系统自动解析并构建个性化的监测流。
1.2 问题
我们先思考下 AI Agent 的原生交互逻辑:常规情况下,Agent 仅能在用户发起明确指令后执行操作,属于 “被动响应” 模式,无法主动在指定时间触发动作,这就导致两类核心需求无法被满足
-
一是个人场景中定点 / 周期性的提醒需求(如定时休息、会议提醒) -
二是工作场景中无需人工干预的周期性任务执行需求(如定时查询项目数据、每日同步信息)。
而cron技能的核心定位,就是为 AI Agent 补上时间驱动的主动执行能力,将 Agent 的操作模式从 “用户指令触发” 拓展为 “时间触发 + 指令触发” 双模式。其本质是在 Agent 体系中嵌入了一套轻量、易用的任务调度引擎,通过标准化的参数配置,让用户无需掌握复杂的调度框架开发知识,即可快速实现提醒、任务的定时 / 周期性调度,同时支持任务的查询与删除,形成完整的调度能力闭环。
简单来说,cron技能解决的核心问题就是:让 AI Agent 能 “记着事、按时做”,摆脱对人工手动触发的依赖,实现轻量操作的自动化执行。传统的定时任务仅是“时间点”的触发,而基于AI Agent的智能任务则实现了逻辑上的质变。
1.3 价值
我们梳理上述所有设计与能力后,能总结出cron技能在 AI Agent 体系中的核心价值与落地意义,主要体现在三个层面:
-
对用户:降低自动化操作门槛,提升效率。普通用户无需掌握编程、调度框架开发等技术,仅通过简单的参数配置,即可实现提醒与任务的自动化调度,将人从 “重复的手动触发操作” 中解放出来,节省时间与精力,同时完整的任务管理能力让使用更省心。 -
对 Agent:丰富能力边界,提升实用价值。让 Agent 从 “被动响应的聊天工具” 升级为 “能主动做事的自动化助手”,突破了原生交互逻辑的限制,丰富了 Agent 的能力边界,让 Agent 不仅能解决 “即时问题”,还能解决 “未来的定时问题”,大幅提升了 Agent 的实际使用价值。 -
对 AI Agent 体系:提供轻量调度方案,适配轻量化场景。相较于专业的分布式调度框架(如 Airflow、XXL-Job),cron 技能做了极致的轻量化设计,无需复杂的部署与配置,直接作为 Agent 的技能组件存在,完美适配了 AI Agent 场景下轻量、高频、简单的调度需求,为 Agent 体系提供了一套高适配性的轻量调度解决方案。
1.4 Claw0
1.4.1 架构
Claw0 的定时任务架构如下:
Main Lane (user input):User Input --> lane_lock.acquire() -------> LLM --> Print(blocking: always wins)Heartbeat Lane (background thread, 1s poll):should_run()?|no --> sleep 1s|yes_execute():lane_lock.acquire(blocking=False)|fail --> yield (user has priority)|successbuild prompt from HEARTBEAT.md + SOUL.md + MEMORY.md|run_agent_single_turn()|parse: "HEARTBEAT_OK"? --> suppressmeaningful text? --> duplicate? --> suppress|nooutput_queue.append()Cron Service (background thread, 1s tick):CRON.json --> load jobs --> tick() every 1s|for each job: enabled? --> due? --> _run_job()|error? --> consecutive_errors++ --> >=5? --> auto-disable|okconsecutive_errors = 0 --> log to cron-runs.jsonl
其要点如下:
-
Lane 互斥: threading.Lock在用户和心跳之间共享. 用户总是赢 (阻塞获取); 心跳让步 (非阻塞获取). -
should_run(): 每次心跳尝试前的 4 个前置条件检查. -
HEARTBEAT_OK: agent 用来表示”没有需要报告的内容”的约定. -
CronService: 3 种调度类型 ( at,every,cron), 连续错误 5 次后自动禁用. -
输出队列: 后台结果通过线程安全的列表输送到 REPL.
1.4.2 CronService — 3 种调度类型
任务定义在 CRON.json 中. 每个任务有一个 schedule.kind 和一个 payload:
@dataclassclass CronJob:id: strname: strenabled: boolschedule_kind: str # "at" | "every" | "cron"schedule_config: dictpayload: dict # {"kind": "agent_turn", "message": "..."}consecutive_errors: int = 0def _compute_next(self, job, now):if job.schedule_kind == "at":ts = datetime.fromisoformat(cfg.get("at", "")).timestamp()return ts if ts > now else 0.0if job.schedule_kind == "every":every = cfg.get("every_seconds", 3600)# 对齐到锚点, 保证触发时间可预测steps = int((now - anchor) / every) + 1return anchor + steps * everyif job.schedule_kind == "cron":return croniter(expr, datetime.fromtimestamp(now)).get_next(datetime).timestamp()
连续 5 次错误后自动禁用:
if status == "error":job.consecutive_errors += 1if job.consecutive_errors >= 5:job.enabled = Falseelse:job.consecutive_errors = 0
1.5 ZeroClaw
我们再看看 ZeroClaw,进行比对。
下图是来自其官方文档的:“How the daemon keeps components alive”。从中看看 Cron 和 Heartbeat 的思路。
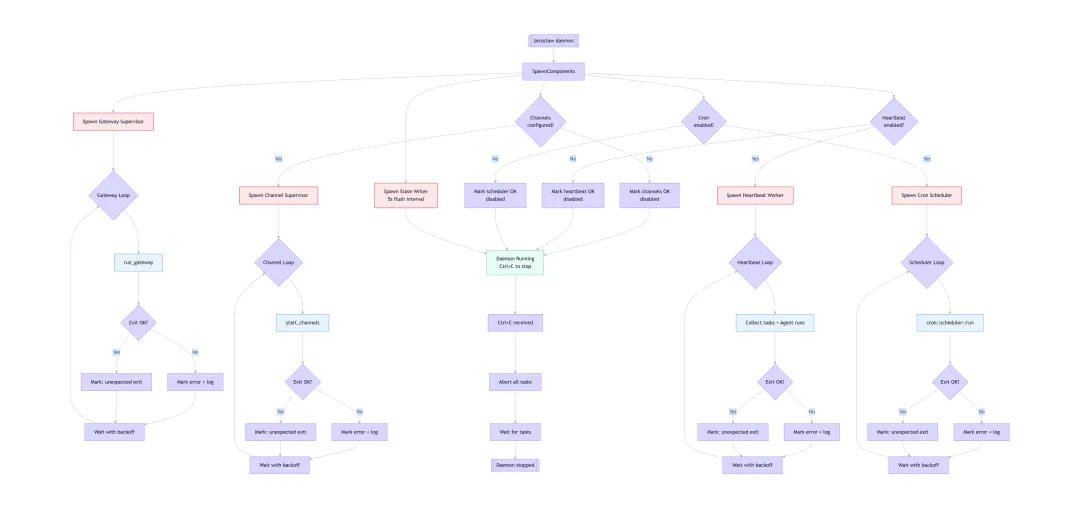
根据 ZeroClaw 的架构设计,这个流程图涵盖了以下核心逻辑:
-
组件并行启动: -
Daemon 启动后会立即并行生成四个核心部分:状态写入器(每5秒刷新)、网关、渠道、心跳和调度器。 -
条件检查:渠道、心跳和调度器会根据配置文件( config.toml)中的设置决定是否启动对应的 Worker。例如,如果未配置 Cron,则直接标记为 OK 并跳过。 -
监督与循环: -
每个核心组件(Gateway, Channels, Heartbeat, Scheduler)都拥有独立的 Supervisor(监督者) 和 Loop(循环)。 -
异常处理:如果组件意外退出或报错,系统会记录错误并进行退避等待(Backoff),随后尝试重新进入循环,确保服务的稳定性。 -
核心功能: -
Gateway:负责 HTTP/WebSocket 服务,处理外部连接。 -
Channels:连接 Telegram、Discord 等聊天平台。 -
Heartbeat:定期执行后台感知任务,赋予 AI “自主意识”。 -
Scheduler:基于 Cron 表达式触发定时任务。 -
优雅退出: -
当接收到 Ctrl+C信号时,Daemon 会中止所有任务并等待线程结束,确保数据完整保存后停止。
0x02 SKILL.md
该技能是实现 Agent定时任务调度与自动化提醒的核心能力组件,通过多模式调度、灵活的时间表达式配置及完整的任务生命周期管理,让 Agent 突破 “即时响应” 的交互限制,具备按指定时间 / 频率自动执行操作的能力,适配个人日常提醒、周期性轻量工作执行等典型业务场景,是提升 Agent 自动化能力与实用价值的关键模块。
cron技能的配置方式做了 **“简易参数 + 标准表达式” 双轨设计 **,同时支持时区适配,既降低了普通用户的使用门槛,又满足了专业用户的精细化调度需求,是其设计的核心亮点。
2.1 核心工作模式
该技能设计了三种核心工作模式,分别对应不同的业务需求,模式的划分遵循 “轻量到复杂、通知到执行” 的梯度设计,覆盖了绝大多数定时调度的典型场景。三种模式并非相互独立,而是可根据用户需求灵活选择,核心设计思路是 “按需匹配调度能力,让简单需求更轻量,让复杂需求更完整”。
我们逐一拆解每种模式的核心逻辑、执行规则与适用场景:
2.1.1 Reminder(提醒模式)
前提背景:用户仅需要 Agent 在指定时间发送纯通知类信息,无需 Agent 执行任何额外的计算、查询、操作等动作,是最基础的调度需求。
核心逻辑:用户配置时间规则与提醒消息后,Agent 按规则触发时,直接将消息推送至用户,无任何后续执行步骤,触发后该次提醒任务完成(若为周期性配置,则循环触发)。
适用场景:个人日常定点 / 周期性提醒,如定时休息、喝水提醒、每日打卡提醒、会议提前通知等纯信息告知场景。
2.1.2 Task(任务模式)
前提背景:用户需要 Agent 不仅在指定时间触发动作,还需主动执行对应的业务操作,并将执行结果反馈给用户,属于 “调度 + 执行” 的复合需求,也是体现 Agent 自动化能力的核心模式。
核心逻辑:用户配置时间规则与任务描述消息后,Agent 按规则触发时,先解析消息中的任务指令、自主执行该任务(如查询 GitHub 星数、统计数据、同步文件等),再将执行结果整理后推送至用户,实现 “定时执行 + 结果反馈” 的一体化。
适用场景:周期性的轻量工作任务执行,如定时查询项目仓库数据、每日统计业务指标、定时检查服务状态并上报、每周同步文件等无需人工参与的自动化工作场景。
2.1.3 One-time(一次性模式)
前提背景:用户存在临时的定点调度需求,仅需 Agent 执行一次提醒 / 任务,无需重复触发,若使用常规周期性配置,还需手动删除任务,增加操作成本。
核心逻辑:用户配置单次触发的具体时间与消息(提醒 / 任务)后,Agent 在指定时间触发对应操作,执行完成后自动删除该调度任务,不会在 Agent 中留存冗余任务,无需用户手动干预。
适用场景:临时的单次提醒 / 任务,如某次临时会议的提醒、某个临时截止时间的任务执行、一次性的数据分析需求等非重复性的调度场景。
2.2 核心操作
cron技能设计了add/list/remove三个核心动作,覆盖了调度任务从创建→查询→删除的完整生命周期,避免出现 “任务创建后无法管理、冗余任务堆积” 的问题:
-
add:创建调度任务,搭配模式、时间、消息等参数,是核心动作; -
list:查询当前已创建的所有调度任务,方便用户核对任务配置与状态; -
remove:根据任务唯一标识job_id删除指定任务,支持精准清理无用任务。
该设计让cron技能不仅具备 “创建调度” 的基础能力,还拥有完整的任务管理能力,适配了实际使用中 “增删查” 的真实需求。
2.3 时间配置
时间配置是调度技能的核心,cron技能针对周期性调度设计了两种配置方式(简易参数与标准表达式),同时为一次性调度设计了专属的时间参数,完美匹配不同用户的配置习惯:
-
简易秒数参数(every_seconds)
针对低频次、简单的周期性调度需求,用户可直接通过 every_seconds 来配置重复间隔的秒数,Agent 自动按该间隔循环触发,无需掌握任何调度表达式,比如 every_seconds=1200 即表示每 20 分钟触发一次。
👉 适用:普通用户的简单周期性调度,配置成本为 0,易上手。
-
标准 cron 表达式(cron_expr)
针对高频次、精细化的周期性调度需求,用户可通过标准的 5 位 cron 表达式配置时间规则,支持按 “分 / 时 / 日 / 月 / 周” 的精细化调度,比如 0 9 * * 1-5 即表示每周一至周五早上 9 点触发。
👉 适用:专业用户的精细化调度,满足复杂的时间规则需求,兼容性强(符合行业通用标准)。
-
一次性时间参数(at)
针对一次性调度需求,设计了专属的 at 参数,用户传入 ISO 标准的时间字符串,Agent 仅在该时间点触发一次,触发后自动删除任务,比如 at=”
” 即表示在指定的 ISO 时间执行。
同时,官方还做了自然语言→配置参数的映射表,将用户的自然语言表述(如 “每天 8 点”“工作日 5 点”)直接对应到具体的配置参数,进一步降低了用户的理解与配置成本,让非技术用户也能快速上手。
2.4 代码
---name: crondescription: Schedule reminders and recurring tasks.---# CronUse the `cron` tool to schedule reminders or recurring tasks.## Three Modes1. **Reminder** - message is sent directly to user2. **Task** - message is a task description, agent executes and sends result3. **One-time** - runs once at a specific time, then auto-deletes## ExamplesFixed reminder:```cron(action="add", message="Time to take a break!", every_seconds=1200)```Dynamic task (agent executes each time):```cron(action="add", message="Check HKUDS/nanobot GitHub stars and report", every_seconds=600)```One-time scheduled task (compute ISO datetime from current time):```cron(action="add", message="Remind me about the meeting", at="<ISO datetime>")```Timezone-aware cron:```cron(action="add", message="Morning standup", cron_expr="0 9 * * 1-5", tz="America/Vancouver")```List/remove:```cron(action="list")cron(action="remove", job_id="abc123")```## Time Expressions| User says | Parameters ||-----------|------------|| every 20 minutes | every_seconds: 1200 || every hour | every_seconds: 3600 || every day at 8am | cron_expr: "0 8 * * *" || weekdays at 5pm | cron_expr: "0 17 * * 1-5" || 9am Vancouver time daily | cron_expr: "0 9 * * *", tz: "America/Vancouver" || at a specific time | at: ISO datetime string (compute from current time) |## TimezoneUse `tz` with `cron_expr` to schedule in a specific IANA timezone. Without `tz`, the server's local timezone is used.
0x03 核心组件
Cron功能的几个组件如下:
-
CronTool:负责接收用户指令 -
CronService:负责任务调度和生命周期管理 -
CronStore:负责持久化 -
CronJob + 子类:数据模型 -
AgentLoop:负责实际执行任务
3.1 依赖关系
类之间的持有关系如下:
-
AgentLoop → CronService → CronStore → CronJob -
CronJob 由三个子数据类组成:CronSchedule, CronPayload, CronJobState -
CronTool 持有 CronService 的引用
具体如下:
-
AgentLoop(AgentLoop ──▶ CronService):负责实际执行任务
-
创建时传入 cron_service 参数 -
用于注册 CronTool 到工具列表 -
持有 CronService 的引用(组合关系,通过 cron_service 参数) -
在 _register_default_tools() 中创建 CronTool,传入 cron_service -
在 gateway 的 on_cron_job 回调中被调用(通过 process_direct()) -
CronService(CronService ──▶ CronStore)/(CronService.on_job (回调) ──▶ AgentLoop.process_direct):
-
持有 CronStore(组合关系,内部存储,通过 _store),通过 _load_store() 加载 -
CronService 管理任务,CronStore 负责持久化 -
持有 on_job 回调函数(类型是 Callable[[CronJob], Coroutine[Any, Any, str | None]]), on_job回调由 Gateway 设置,调用 AgentLoop.process_direct() -
管理多个 CronJob(在 CronStore.jobs 列表中) -
CronTool(CronTool ──▶ CronService ):
-
持有 CronService 的引用(通过 _cron 成员变量),AgentLoop 创建 CronTool 时传入 CronService。 -
CronTool 通过 CronService 添加/查询任务 -
持有 _channel 和 _chat_id(通过 set_context() 设置),用于保存用户上下文 -
CronStore(CronStore ──▶ CronJob (列表)):
-
包含一个 CronJob 列表(jobs: list[CronJob]),包含所有任务 -
序列化到 JSON 文件 -
CronJob:组合了以下对象(CronJob ──▶ CronSchedule / CronPayload / CronJobState):
-
schedule: CronSchedule(调度规则) -
payload: CronPayload (执行内容) -
state: CronJobState (运行状态)
-
CronSchedule: 独立的数据类,定义任务的调度方式 -
CronPayload 是一个专门用于定义任务执行细节的数据类。它详细描述了任务的具体内容和处理方式,包括消息内容、交付方式和目标通道。这个类提供了 CronJob 执行所需的额外参数和上下文信息。 -
CronJobState 是跟踪 CronJob 运行状态的关键数据类。它记录了任务的执行时间、状态和可能出现的错误,为任务监控和故障排查提供了重要信息。通过这个类,可以实时了解每个定时任务的当前运行情况。
3.2 模块架构
Cron 定时任务模块架构如下:
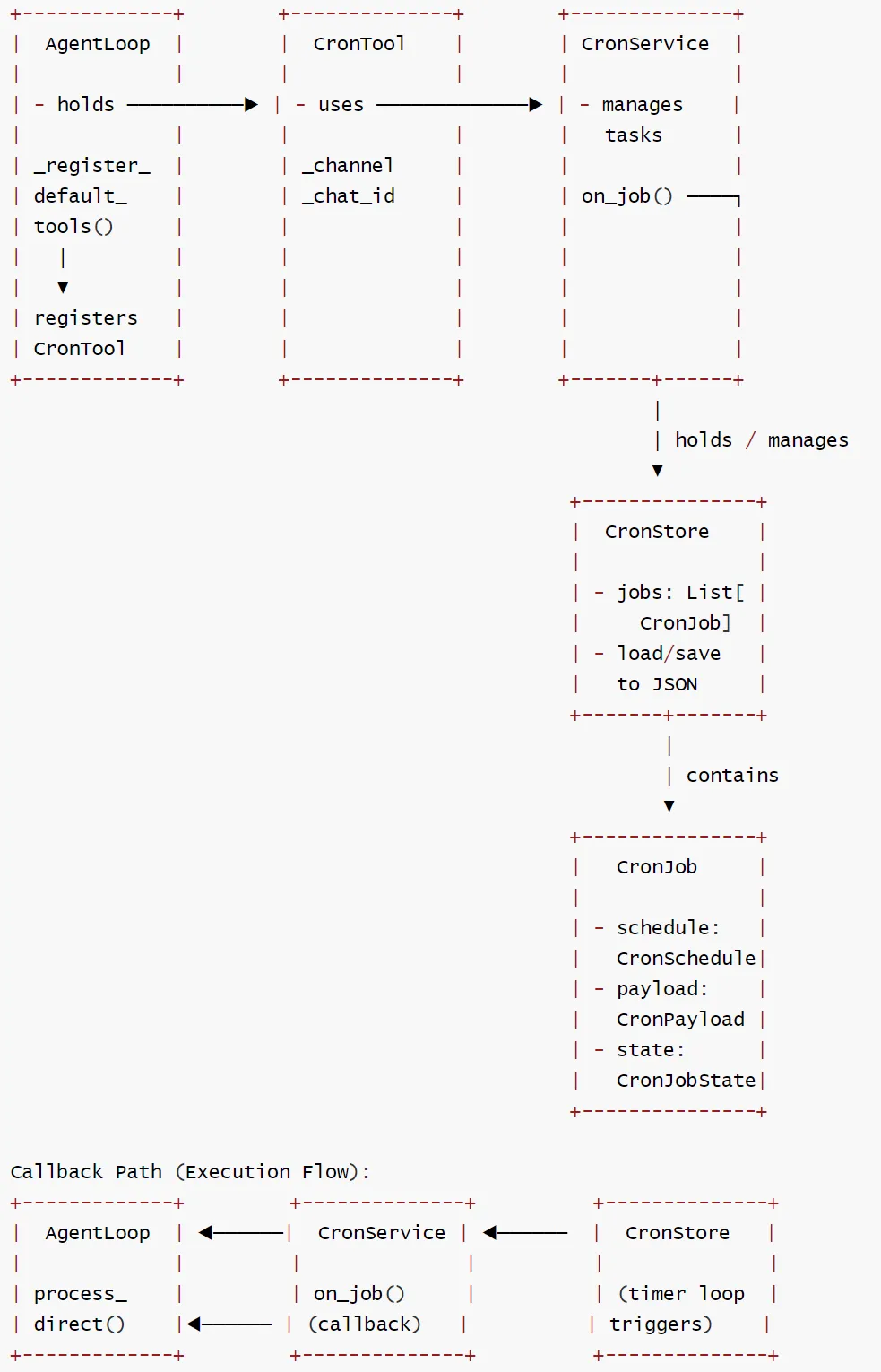
3.3 详细流程
我们接下来看看Cron的详细流程。
3.3.1 定时任务流程
用户设置流程是:用户输入 → CronTool(添加/列表/删除) → CronService(管理)
具体如下:
-
创建任务:用户对话 → LLM 识别意图 → LLM 调用 CronTool.execute(action=”add”, …) → CronService → CronJob → 持久化 到 JSON。
CronTool 不直接判断意图,而是作为命令式操作,其内部调用 CronService.add_job(),这会:
-
创建 CronJob 对象并保存到 cron/jobs.json -
重新计算所有任务的下一次运行时间 -
重新设置定时器 -
执行任务:CronService 定时器 → on_job 回调 → AgentLoop.process_direct()
CronService._on_timer() → _execute_job(job) → on_job(job)↓AgentLoop.process_direct()↓返回结果
-
状态更新:任务执行后 → 更新 CronJobState → 持久化到 JSON
ounter(line_execute_job() → 更新 job.state → _save_store() → JSON
具体如下图所示。

具体也可以用下图进行对照。

3.3.2 CronTool执行操作
我们把 CronTool 的执行操作再进行具体分析。

0x04 CronTool类
CronTool 是 Nanobot 框架中定时任务功能的对外工具封装,将 CronService 的底层调度能力暴露为 Agent 可调用的标准化工具,支持 Agent 通过自然语言指令创建、查询、删除定时 / 周期性任务,是连接 Agent 对话能力与定时调度引擎的关键桥梁。
CronTool 将字符串参数转换为 CronSchedule 对象,传递给 CronService 进行实际处理。CronTool与CronService交互流程如下:
CronTool.execute() → 执行cron工具↓根据action参数判断操作类型:├── add:[CronService:add_job()]├── list:[CronService:list_jobs()]├── remove:[CronService:remove_job()]├── run:[CronService:run_job()]├── enable/disable:[CronService:enable_job()]↓CronService._save_store() → 保存任务到磁盘↓返回操作结果给LLM
4.1 核心特色
-
桥接工具:CronTool 是一个桥接工具,连接 LLM 的意图理解和底层的 CronService 功能,将 LLM 的自然语言指令转换为对 CronService 的结构化调用。 -
标准化工具接口:遵循 Nanobot 的 Tool 抽象类规范,提供统一的 name/description/parameters/execute接口,可被 Agent 的工具调用系统自动识别和使用; -
多类型任务支持:封装了「周期性任务(every_seconds)」「Cron 表达式任务(cron_expr)」「一次性定时任务(at)」三种调度类型,覆盖常见定时场景; -
严格的参数校验:对时区、时间格式、参数组合(如 tz 仅支持 cron_expr)做前置校验,避免无效任务创建; -
会话上下文绑定:通过 set_context绑定渠道 / 聊天 ID,确保定时任务的消息能精准投递到指定会话; -
用户友好的返回值:所有操作返回自然语言格式的结果(如创建成功 / 删除失败提示),适配 Agent 的对话输出场景; -
轻量的依赖处理:按需导入时区 / 时间处理模块,避免不必要的初始化开销; -
参数兼容设计:通过 **kwargs兼容工具调用时的额外参数,保证接口鲁棒性。
4.2 重点功能
三种主要操作
-
添加任务:通过 action=”add” 添加新的定时任务 -
列出任务:通过 action=”list” 查看现有定时任务 -
删除任务:通过 action=”remove” 移除定时任务
具体操作流程
-
添加任务:LLM → CronTool.execute(action=”add”, …) → _add_job() → CronService.add_job() → 保存到存储 -
列出任务:LLM → CronTool.execute(action=”list”) → _list_jobs() → CronService.list_jobs() → 返回任务列表 -
删除任务:LLM → CronTool.execute(action=”remove”, …) → _remove_job() → CronService.remove_job() → 更新存储
4.3 代码
-
核心定位:该类是 Nanobot 定时任务能力的「对外工具层」,将底层 CronService的调度能力封装为 Agent 可调用的标准化工具,实现「自然语言指令→定时任务」的转化; -
关键设计: -
接口标准化:遵循 Tool 抽象类规范,适配 Agent 的工具调用系统; -
参数校验前置:对必填参数、参数组合、格式合法性做严格校验,避免无效任务创建; -
上下文绑定:通过 set_context关联会话信息,确保定时消息精准投递; -
结果人性化:所有操作返回自然语言提示,直接适配 Agent 的对话输出场景; -
核心价值:让 Agent 具备「自主创建 / 管理定时任务」的能力,支持提醒、周期巡检、定时执行指令等场景,是 OpenCLA 定时任务能力的轻量化、易用化封装。
@dataclassclass CronSchedule:"""Schedule definition for a cron job."""kind: Literal["at", "every", "cron"]# For "at": timestamp in msat_ms: int | None = None# For "every": interval in msevery_ms: int | None = None# For "cron": cron expression (e.g. "0 9 * * *")expr: str | None = None# Timezone for cron expressionstz: str | None = None@dataclassclass CronJob:"""A scheduled job."""id: strname: strenabled: bool = Trueschedule: CronSchedule = field(default_factory=lambda: CronSchedule(kind="every"))payload: CronPayload = field(default_factory=CronPayload)state: CronJobState = field(default_factory=CronJobState)created_at_ms: int = 0updated_at_ms: int = 0delete_after_run: bool = False# ===================== 核心类定义 =====================class CronTool(Tool):"""Tool to schedule reminders and recurring tasks."""def __init__(self, cron_service: CronService):# 关联底层定时任务服务实例(核心依赖)self._cron = cron_service# 初始化会话渠道(用于任务消息投递)self._channel = ""# 初始化会话ID(用于任务消息精准投递到指定聊天)self._chat_id = ""def set_context(self, channel: str, chat_id: str) -> None:"""Set the current session context for delivery."""# 设置当前会话的渠道信息(如钉钉/微信渠道)self._channel = channel# 设置当前会话的聊天ID(如群ID/用户ID)self._chat_id = chat_id@propertydef name(self) -> str:# 工具名称(Agent调用时的标识)return "cron"@propertydef description(self) -> str:# 工具描述(告知Agent该工具的作用和支持的操作)return "Schedule reminders and recurring tasks. Actions: add, list, remove."@propertydef parameters(self) -> dict[str, Any]:# 工具参数定义(JSON Schema格式,供Agent生成工具调用参数)return {"type": "object", # 参数整体为对象类型"properties": {# 核心参数:操作类型(add/list/remove)"action": {"type": "string","enum": ["add", "list", "remove"], # 仅支持这三种操作"description": "Action to perform"},# 任务消息(仅add操作需要)"message": {"type": "string","description": "Reminder message (for add)"},# 周期执行间隔(秒,仅add操作的every类型需要)"every_seconds": {"type": "integer","description": "Interval in seconds (for recurring tasks)"},# Cron表达式(仅add操作的cron类型需要)"cron_expr": {"type": "string","description": "Cron expression like '0 9 * * *' (for scheduled tasks)"},# 时区(仅add操作的cron类型需要)"tz": {"type": "string","description": "IANA timezone for cron expressions (e.g. 'America/Vancouver')"},# 一次性执行时间(ISO格式,仅add操作的at类型需要)"at": {"type": "string","description": "ISO datetime for one-time execution (e.g. '2026-02-12T10:30:00')"},# 任务ID(仅remove操作需要)"job_id": {"type": "string","description": "Job ID (for remove)"}},"required": ["action"] # 必选参数:操作类型}async def execute(self,action: str,message: str = "",every_seconds: int | None = None,cron_expr: str | None = None,tz: str | None = None,at: str | None = None,job_id: str | None = None,**kwargs: Any) -> str:# 根据操作类型分发到对应处理方法if action == "add":return self._add_job(message, every_seconds, cron_expr, tz, at)elif action == "list":return self._list_jobs()elif action == "remove":return self._remove_job(job_id)# 未知操作时返回提示return f"Unknown action: {action}"def _add_job(self,message: str,every_seconds: int | None,cron_expr: str | None,tz: str | None,at: str | None,) -> str:# 校验1:添加任务必须提供消息内容if not message:return "Error: message is required for add"# 校验2:必须先设置会话上下文(渠道/聊天ID),否则无法投递消息if not self._channel or not self._chat_id:return "Error: no session context (channel/chat_id)"# 校验3:时区参数仅能与Cron表达式配合使用if tz and not cron_expr:return "Error: tz can only be used with cron_expr"# 校验4:时区参数合法性校验if tz:from zoneinfo import ZoneInfo # 按需导入时区模块(减少初始化开销)try:# 验证时区是否为有效IANA时区ZoneInfo(tz)except (KeyError, Exception):return f"Error: unknown timezone '{tz}'"# 构建调度规则(三种类型互斥)delete_after = False # 标记是否执行后删除(仅at类型为True)# 类型1:周期性任务(every_seconds)if every_seconds:schedule = CronSchedule(kind="every", every_ms=every_seconds * 1000)# 类型2:Cron表达式任务(cron_expr)elif cron_expr:schedule = CronSchedule(kind="cron", expr=cron_expr, tz=tz)# 类型3:一次性定时任务(at)elif at:from datetime import datetime # 按需导入时间模块# 将ISO格式时间转换为datetime对象dt = datetime.fromisoformat(at)# 转换为毫秒级时间戳at_ms = int(dt.timestamp() * 1000)schedule = CronSchedule(kind="at", at_ms=at_ms)delete_after = True # 一次性任务执行后删除# 无有效调度规则时返回错误else:return "Error: either every_seconds, cron_expr, or at is required"# 调用底层CronService添加任务job = self._cron.add_job(name=message[:30], # 任务名称截取前30字符(避免过长)schedule=schedule, # 调度规则message=message, # 任务消息内容deliver=True, # 标记需要投递消息到指定渠道channel=self._channel, # 投递渠道to=self._chat_id, # 投递目标delete_after_run=delete_after, # 执行后是否删除)# 返回创建成功提示(包含任务名称和ID)return f"Created job '{job.name}' (id: {job.id})"def _list_jobs(self) -> str:# 调用底层CronService获取所有启用的任务jobs = self._cron.list_jobs()# 无任务时返回提示if not jobs:return "No scheduled jobs."# 格式化任务列表(名称+ID+调度类型)lines = [f"- {j.name} (id: {j.id}, {j.schedule.kind})" for j in jobs]# 返回用户友好的任务列表return "Scheduled jobs:\n" + "\n".join(lines)def _remove_job(self, job_id: str | None) -> str:# 校验:删除任务必须提供任务IDif not job_id:return "Error: job_id is required for remove"# 调用底层CronService删除任务if self._cron.remove_job(job_id):return f"Removed job {job_id}"# 任务ID不存在时返回提示return f"Job {job_id} not found"
0x05 CronService
CronService 是 Nanobot 框架中定时任务(Cron Job)的全生命周期管理服务,核心职责是实现定时任务的增删改查、持久化存储、自动触发执行,为 Agent 提供「定时 / 周期性执行任务」的核心能力。
CronService 是一个纯应用级别的定时任务系统,它不与操作系统的 crontab 交互,而是使用 Python 的异步功能实现自己的调度机制(类 Linux Cron 的独立调度系统),它将AI从一个“对话窗口”释放出来,变成了一个在后台24小时运行的逻辑引擎。
5.1 核心特色
-
多类型调度支持:兼容「一次性定时(at)」「周期性执行(every)」「Cron 表达式」三种调度类型,覆盖常见定时场景; -
持久化存储:将任务配置 / 状态序列化到 JSON 文件,服务重启后可恢复任务,避免任务丢失; -
精准的定时器机制:通过「计算下次执行时间→设置定时器→触发执行→重新计算」的闭环,实现毫秒级精准调度; -
完整的任务生命周期:支持任务添加、删除、启用 / 禁用、手动触发、状态查询,覆盖调度器全场景需求; -
鲁棒的错误处理:任务执行异常时记录错误状态 / 信息,不影响其他任务执行,保证调度器稳定性; -
灵活的回调机制:通过 on_job回调函数解耦任务执行逻辑,调度器仅负责触发,具体执行逻辑由外部定义; -
精细化状态管理:记录任务的下次执行时间、最后执行时间、执行状态、错误信息,便于问题排查和状态监控。
5.2 AgentLoop与CronService完整集成流程
-
CronTool 注册:AgentLoop 初始化时将 CronTool 注册到工具集 -
System Message:Cron 任务通过 system 消息进入 AgentLoop -
处理逻辑:AgentLoop 检查 msg.channel == "system"并解析 chat_id
5.3 内部调度流程
调度机制:支持三种调度类型(CronSchedule)
-
at:特定时间执行一次 -
every:固定间隔重复执行 -
cron:CRON表达式执行
CronService 的核心调度机制包括:
5.3.1 启动
启动时使用start() 方法:
-
加载任务 ( _load_store()) -
计算所有任务的下一次运行时间 ( _recompute_next_runs()) -
保存存储 ( _save_store()) -
设置定时器 ( _arm_timer())
任务调度算法
CronService._compute_next_run()├── "at": 直接返回指定时间戳(如果未过期)├── "every": 当前时间 + 间隔时间└── "cron": 使用croniter库解析表达式计算下次执行时间_
定时器管理
CronService._arm_timer()├── 计算下一个唤醒时间├── 创建异步任务等待唤醒└── 定时器到期时触发_on_timer()
具体图例如下。

5.3.2 定时器循环
定时器循环使用_run_loop():
-
每待到下次唤醒时间 -
定时器到达后触发 _on_timer() -
收集所有已到执行时间的任务 ( due_jobs) -
逐个调用 _execute_job(job) -
_on_timer()调用后重新设置定时器
任务执行流程
CronService._on_timer()├── 检查哪些任务已到期├── 对每个到期任务执行_execute_job()└── 重新安排下一次唤醒
5.3.3 任务回调流程
-
到时触发 → CronService._on_timer() 触发到期任务 -
调用 on_job 回调 → Gateway.on_cron_job() -
Gateway.on_cron_job() 的逻辑: -
deliver=True:通过 MessageBus 发布 system 消息 → AgentLoop 处理 → ChannelManager 发送给用户 -
deliver=False:直接调用 agent.process_direct(),不发送到用户 -
提取目标渠道(Telegram/Discord等) -
构造带特殊 session_key_override的系统消息 -
发布到 inbound 队列,判断 deliver 参数:
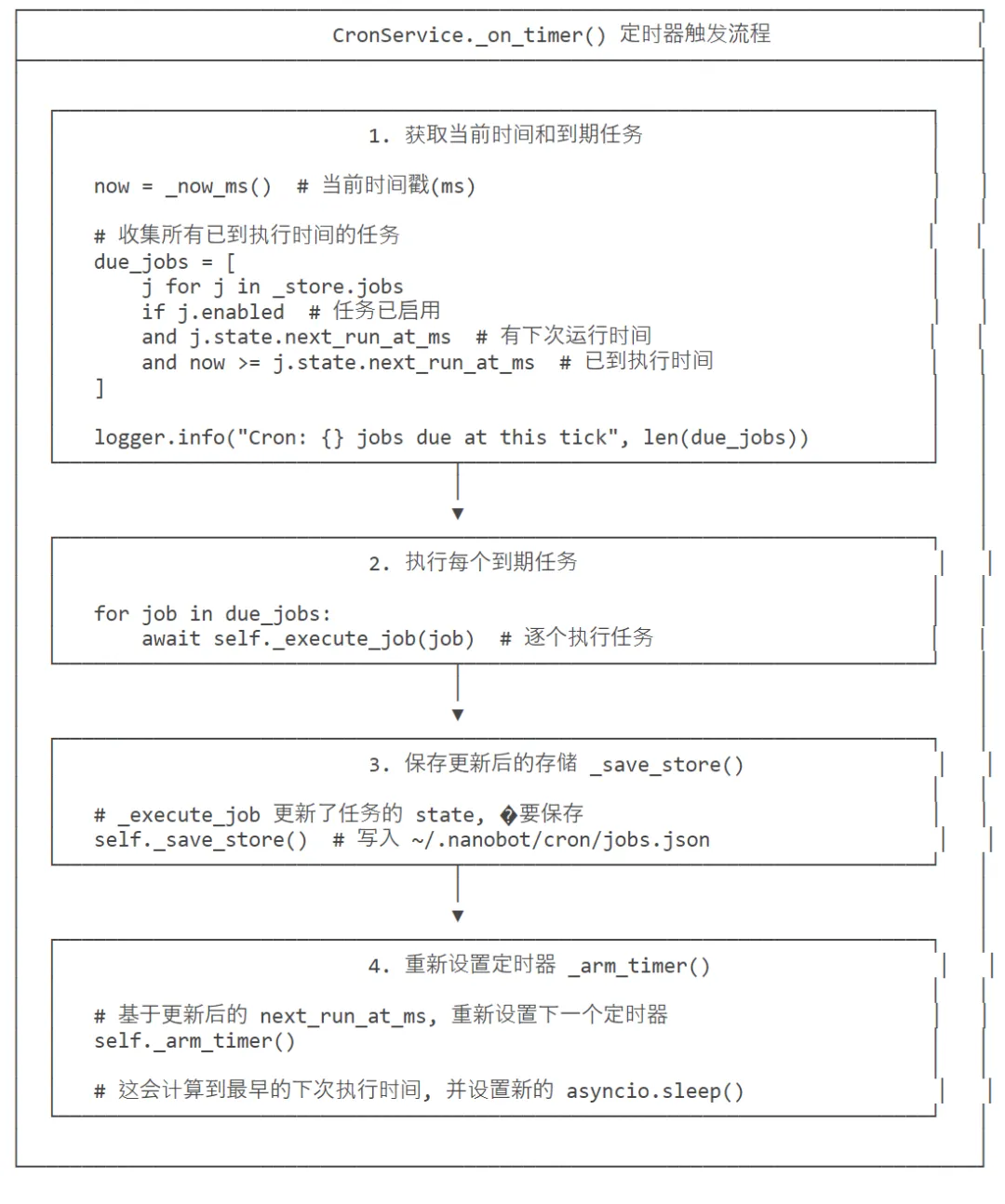
5.3.4 任务执行流程
CronService._execute_job(job) 任务执行流程如下:

5.4 代码
CronService 让 Agent 具备「自动化定时执行」能力,支持一次性 / 周期性任务,覆盖巡检、定时提醒、周期执行脚本等典型场景,是 OpenCLAW 核心调度能力的轻量化实现。
关键设计:
-
调度闭环:「计算下次执行时间→设置定时器→触发执行→更新状态→重新计算」,形成精准的调度闭环; -
持久化:任务配置 / 状态序列化到 JSON 文件,重启后可恢复,保证任务不丢失; -
解耦设计:通过 on_job回调解耦调度器与任务执行逻辑,调度器仅负责「何时执行」,不关心「执行什么」; -
状态管理:精细化记录任务执行状态、错误信息,便于监控和问题排查;
class CronService:"""Service for managing and executing scheduled jobs."""def __init__(self,store_path: Path,on_job: Callable[[CronJob], Coroutine[Any, Any, str | None]] | None = None):# 定时任务存储文件路径(JSON格式)self.store_path = store_path# 任务执行回调函数:外部传入,负责实际执行任务逻辑,返回响应文本self.on_job = on_job# 定时任务存储实例(懒加载,首次使用时加载)self._store: CronStore | None = None# 定时器任务(asyncio.Task):用于调度下次任务执行self._timer_task: asyncio.Task | None = None# 服务运行状态标记:True=运行中,False=已停止self._running = Falsedef _load_store(self) -> CronStore:"""Load jobs from disk."""# 若已加载存储实例,直接返回(避免重复加载)if self._store:return self._store# 存储文件存在时,从文件加载任务if self.store_path.exists():try:# 读取文件内容并解析为JSONdata = json.loads(self.store_path.read_text(encoding="utf-8"))jobs = []# 遍历JSON中的任务列表,转换为CronJob对象for j in data.get("jobs", []):jobs.append(CronJob(id=j["id"], # 任务IDname=j["name"], # 任务名称enabled=j.get("enabled", True), # 是否启用(默认True)# 解析调度规则schedule=CronSchedule(kind=j["schedule"]["kind"],at_ms=j["schedule"].get("atMs"),every_ms=j["schedule"].get("everyMs"),expr=j["schedule"].get("expr"),tz=j["schedule"].get("tz"),),# 解析任务负载payload=CronPayload(kind=j["payload"].get("kind", "agent_turn"),message=j["payload"].get("message", ""),deliver=j["payload"].get("deliver", False),channel=j["payload"].get("channel"),to=j["payload"].get("to"),),# 解析任务状态state=CronJobState(next_run_at_ms=j.get("state", {}).get("nextRunAtMs"),last_run_at_ms=j.get("state", {}).get("lastRunAtMs"),last_status=j.get("state", {}).get("lastStatus"),last_error=j.get("state", {}).get("lastError"),),created_at_ms=j.get("createdAtMs", 0), # 创建时间戳updated_at_ms=j.get("updatedAtMs", 0), # 更新时间戳delete_after_run=j.get("deleteAfterRun", False), # 执行后删除))# 初始化存储实例self._store = CronStore(jobs=jobs)except Exception as e:# 加载失败时记录警告,初始化空存储logger.warning("Failed to load cron store: {}", e)self._store = CronStore()else:# 存储文件不存在时,初始化空存储self._store = CronStore()return self._storedef _save_store(self) -> None:"""Save jobs to disk."""# 存储实例未初始化时直接返回if not self._store:return# 确保存储文件所在目录存在(不存在则创建)self.store_path.parent.mkdir(parents=True, exist_ok=True)# 将存储实例序列化为JSON格式数据data = {"version": self._store.version, # 存储版本"jobs": [{"id": j.id,"name": j.name,"enabled": j.enabled,# 序列化调度规则"schedule": {"kind": j.schedule.kind,"atMs": j.schedule.at_ms,"everyMs": j.schedule.every_ms,"expr": j.schedule.expr,"tz": j.schedule.tz,},# 序列化任务负载"payload": {"kind": j.payload.kind,"message": j.payload.message,"deliver": j.payload.deliver,"channel": j.payload.channel,"to": j.payload.to,},# 序列化任务状态"state": {"nextRunAtMs": j.state.next_run_at_ms,"lastRunAtMs": j.state.last_run_at_ms,"lastStatus": j.state.last_status,"lastError": j.state.last_error,},"createdAtMs": j.created_at_ms,"updatedAtMs": j.updated_at_ms,"deleteAfterRun": j.delete_after_run,}for j in self._store.jobs # 遍历所有任务]}# 将JSON数据写入文件(缩进2格,确保非ASCII字符不转义)self.store_path.write_text(json.dumps(data, indent=2, ensure_ascii=False), encoding="utf-8")async def start(self) -> None:"""Start the cron service."""# 标记服务为运行状态self._running = True# 加载任务存储(从文件读取)self._load_store()# 重新计算所有启用任务的下次执行时间self._recompute_next_runs()# 保存更新后的任务状态到文件self._save_store()# 设置定时器(触发下次任务执行)self._arm_timer()# 记录启动日志:当前任务数量logger.info("Cron service started with {} jobs", len(self._store.jobs if self._store else []))def stop(self) -> None:"""Stop the cron service."""# 标记服务为停止状态self._running = False# 取消当前定时器任务(避免继续触发)if self._timer_task:self._timer_task.cancel()self._timer_task = Nonedef _recompute_next_runs(self) -> None:"""Recompute next run times for all enabled jobs."""# 存储实例未初始化时直接返回if not self._store:return# 获取当前时间戳(毫秒)now = _now_ms()# 遍历所有任务,重新计算启用任务的下次执行时间for job in self._store.jobs:if job.enabled:job.state.next_run_at_ms = _compute_next_run(job.schedule, now)def _get_next_wake_ms(self) -> int | None:"""Get the earliest next run time across all jobs."""# 存储实例未初始化时返回Noneif not self._store:return None# 收集所有启用任务的下次执行时间戳times = [j.state.next_run_at_ms for j in self._store.jobsif j.enabled and j.state.next_run_at_ms]# 返回最早的执行时间(无任务时返回None)return min(times) if times else Nonedef _arm_timer(self) -> None:"""Schedule the next timer tick."""# 取消当前定时器任务(避免重复调度)if self._timer_task:self._timer_task.cancel()# 获取最早的下次执行时间next_wake = self._get_next_wake_ms()# 无执行时间或服务已停止时,不设置定时器if not next_wake or not self._running:return# 计算定时器延迟时间(毫秒):确保非负delay_ms = max(0, next_wake - _now_ms())# 转换为秒(asyncio.sleep接收秒为单位)delay_s = delay_ms / 1000# 定义定时器回调函数:延迟后执行任务检查async def tick():await asyncio.sleep(delay_s)# 服务仍在运行时,处理定时器触发逻辑if self._running:await self._on_timer()# 创建并保存定时器任务self._timer_task = asyncio.create_task(tick())async def _on_timer(self) -> None:"""Handle timer tick - run due jobs."""# 存储实例未初始化时直接返回if not self._store:return# 获取当前时间戳now = _now_ms()# 筛选出已到执行时间的任务:启用 + 有下次执行时间 + 当前时间≥执行时间due_jobs = [j for j in self._store.jobsif j.enabled and j.state.next_run_at_ms and now >= j.state.next_run_at_ms]# 遍历并执行所有到期任务for job in due_jobs:await self._execute_job(job)# 保存任务状态到文件self._save_store()# 重新设置定时器(触发下一次任务执行)self._arm_timer()async def _execute_job(self, job: CronJob) -> None:"""Execute a single job."""# 记录任务开始执行时间戳start_ms = _now_ms()# 记录执行日志logger.info("Cron: executing job '{}' ({})", job.name, job.id)try:response = None# 存在执行回调时,调用回调执行任务if self.on_job:response = await self.on_job(job)# 更新任务状态:执行成功job.state.last_status = "ok"job.state.last_error = Nonelogger.info("Cron: job '{}' completed", job.name)except Exception as e:# 更新任务状态:执行失败job.state.last_status = "error"job.state.last_error = str(e)logger.error("Cron: job '{}' failed: {}", job.name, e)# 更新任务最后执行时间和更新时间job.state.last_run_at_ms = start_msjob.updated_at_ms = _now_ms()# 处理一次性任务(at类型)if job.schedule.kind == "at":# 执行后删除任务if job.delete_after_run:self._store.jobs = [j for j in self._store.jobs if j.id != job.id]# 执行后禁用任务(不删除)else:job.enabled = Falsejob.state.next_run_at_ms = Noneelse:# 周期性任务:计算下次执行时间job.state.next_run_at_ms = _compute_next_run(job.schedule, _now_ms())# ========== Public API ==========def list_jobs(self, include_disabled: bool = False) -> list[CronJob]:"""List all jobs."""# 加载任务存储store = self._load_store()# 筛选任务:是否包含禁用任务jobs = store.jobs if include_disabled else [j for j in store.jobs if j.enabled]# 按下次执行时间排序(无执行时间的排最后)return sorted(jobs, key=lambda j: j.state.next_run_at_ms or float('inf'))def add_job(self,name: str,schedule: CronSchedule,message: str,deliver: bool = False,channel: str | None = None,to: str | None = None,delete_after_run: bool = False,) -> CronJob:"""Add a new job."""# 加载任务存储store = self._load_store()# 校验调度规则合法性_validate_schedule_for_add(schedule)# 获取当前时间戳now = _now_ms()# 创建新任务实例job = CronJob(id=str(uuid.uuid4())[:8], # 生成8位短UUID作为任务IDname=name, # 任务名称enabled=True, # 默认启用schedule=schedule, # 调度规则# 任务负载payload=CronPayload(kind="agent_turn",message=message,deliver=deliver,channel=channel,to=to,),# 任务状态(计算下次执行时间)state=CronJobState(next_run_at_ms=_compute_next_run(schedule, now)),created_at_ms=now, # 创建时间updated_at_ms=now, # 更新时间delete_after_run=delete_after_run, # 执行后是否删除)# 将新任务添加到存储store.jobs.append(job)# 保存到文件self._save_store()# 重新设置定时器self._arm_timer()# 记录添加日志logger.info("Cron: added job '{}' ({})", name, job.id)return jobdef remove_job(self, job_id: str) -> bool:"""Remove a job by ID."""# 加载任务存储store = self._load_store()# 记录删除前的任务数量before = len(store.jobs)# 过滤掉指定ID的任务store.jobs = [j for j in store.jobs if j.id != job_id]# 判断是否成功删除removed = len(store.jobs) < before# 删除成功时,保存并重新设置定时器if removed:self._save_store()self._arm_timer()logger.info("Cron: removed job {}", job_id)return removeddef enable_job(self, job_id: str, enabled: bool = True) -> CronJob | None:"""Enable or disable a job."""# 加载任务存储store = self._load_store()# 遍历任务查找指定IDfor job in store.jobs:if job.id == job_id:# 更新启用状态job.enabled = enabled# 更新任务更新时间job.updated_at_ms = _now_ms()# 启用时重新计算下次执行时间if enabled:job.state.next_run_at_ms = _compute_next_run(job.schedule, _now_ms())# 禁用时清空下次执行时间else:job.state.next_run_at_ms = None# 保存并重新设置定时器self._save_store()self._arm_timer()return job# 未找到任务时返回Nonereturn Noneasync def run_job(self, job_id: str, force: bool = False) -> bool:"""Manually run a job."""# 加载任务存储store = self._load_store()# 遍历任务查找指定IDfor job in store.jobs:if job.id == job_id:# 非强制模式下,禁用的任务无法执行if not force and not job.enabled:return False# 执行任务await self._execute_job(job)# 保存并重新设置定时器self._save_store()self._arm_timer()return True# 未找到任务时返回Falsereturn Falsedef status(self) -> dict:"""Get service status."""# 加载任务存储store = self._load_store()# 返回服务状态:运行状态、任务数量、下次唤醒时间return {"enabled": self._running,"jobs": len(store.jobs),"next_wake_at_ms": self._get_next_wake_ms(),}
0x06 Dream机制
Dream 是nanobot 的异步深度记忆整合器,相当于人类睡眠时大脑对白天记忆的巩固与清理。它不是实时运行的,而是定时或手动触发,对 history.jsonl做批量分析并通过LLM更新长期记忆文件。
6.1 架构
触发方式如下:
-
定时触发:CronService按DreamConfig.interval_h(默认2h)调度dream.run() -
手动触发:用户发送/dream命令,cmd_dream()创建asynciotask立即执行
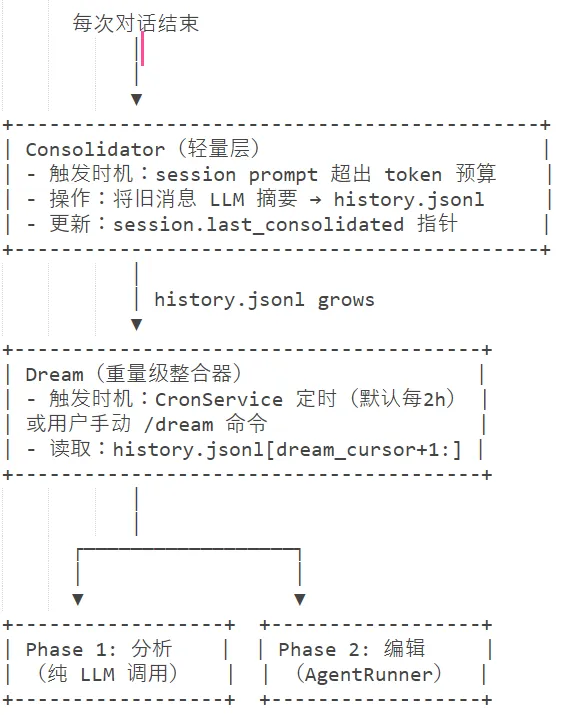
6.2 流程

其关键设计决策如下:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6.3 特色
Cron 任务与 AgentLoop 的关系如下。普通 cron 任务完全经过 AgentLoop, 跟用户手动发消息走的是同一条路, 只是 session key 是 cron:<job_id> 而非用户的对话 key。Dream 则是绕过 AgentLoop 的特殊内部任务。

普通 cron 任务完整流程如下:

两条路径详细对比如下:
|
|
|
|
|---|---|---|
| 创建方式 |
|
|
| 执行路径 |
|
|
| 上下文 |
|
|
| 工具权限 |
|
|
| 结果投递 |
|
|
| 触发方式 |
|
|
继续打广告^_^
0xFF 参考
3500 行代码打造轻量级AI Agent:Nanobot 架构深度解析
【翻译】Anthropic工程博客:长运行Agent的有效利用框架
从被动唤醒到主动守望:基于AI Agent的智能任务架构实践
万字】带你实现一个Agent(上),从Tools、MCP到Skills
3500 行代码打造轻量级AI Agent:Nanobot 架构深度解析
OpenClaw真完整解说:架构与智能体内核
https://github.com/shareAI-lab/learn-claude-code
OpenClaw架构-Agent Runtime 运行时深度拆解