 夜雨聆风
夜雨聆风





OpenClaw + 3个Skill + 1个定时任务:典型案例与法律法规的自动监控及入库 (最终篇)
这是案例整理系列的第四篇文章。
第一集是 Dify 工作流版:解决了本地部署的问题,但维护成本高,还得会用 Docker。
第二集是 Claude Code 命令+脚本版:解决了本地操作的问题,但每次还得手动复制粘贴命令,脚本也可能要自己改。
第三集是 两个 Skill 协作版:实现了抓取和格式化的自动化,一键完成,但触发还得手动。
我发4,这1集,是真正的终极版——OpenClaw + 3个Skill + 1个定时任务,全自动、无人值守。
每年4月是知识产权宣传月,各地法院都会密集发布年度典型案例。
对于需要持续跟踪案例动态的知识产权律师来说,这段时间的工作量成倍增加——一个个公众号刷过去,一篇篇文章复制粘贴整理归档。
律师同行,如果你也受够了每天刷公众号找典型案例——这套思路能把你解放出来。
虽然我总说要升级要升级,但一直拖着,但在这个时间节点,必须得优化出来了!
一、”发现”这件事,能不能不让人盯着?
之前三版的共同问题是:抓取之后的流程还是要人参与。
Dify 工作流能跑,但部署维护成本高;Claude Code 命令行需要人在电脑前操作;两个 Skill 协作能自动抓取和格式化,但触发还得手动。
真正的自动化,需要回答一个最基本的问题:谁在负责”发现”新内容?
——答案是:OpenClaw 定时任务 + Skill。
这个组合解决的不只是”怎么做”,而是”什么时候自动做”。
每天早上 8 点,系统自动开始扫描,没有人盯着,没有人催促,有新增内容才通知,没有就安静待命。
这才让人真正放心。
定时任务触发后,Agent 按顺序执行四个步骤:扫描判断 → 格式化 → 复制备份 → 上传飞书。
每步独立记录,文件在每步之间复制传递。
断点续跑:每步独立 JSON 记录,已完成的不重复执行。
二、基础设施:公众号没有 API,FreshRSS 是那条”曲线”
整个流程的最前端是 FreshRSS。
它负责从微信公众号抓取内容,导出为本地 Markdown 文件。
目前订阅了多个公众号,包括最高人民法院知识产权法庭、知产财经、知产力等。
它们会第一时间发布各级法院或行政机关的典型案例汇编——最高法院、各地方知识产权法院、北京互联网法院,国家知识产权局等发布的案例汇总,以及新施行的法规、条例、规定、办法、批复、通知等。
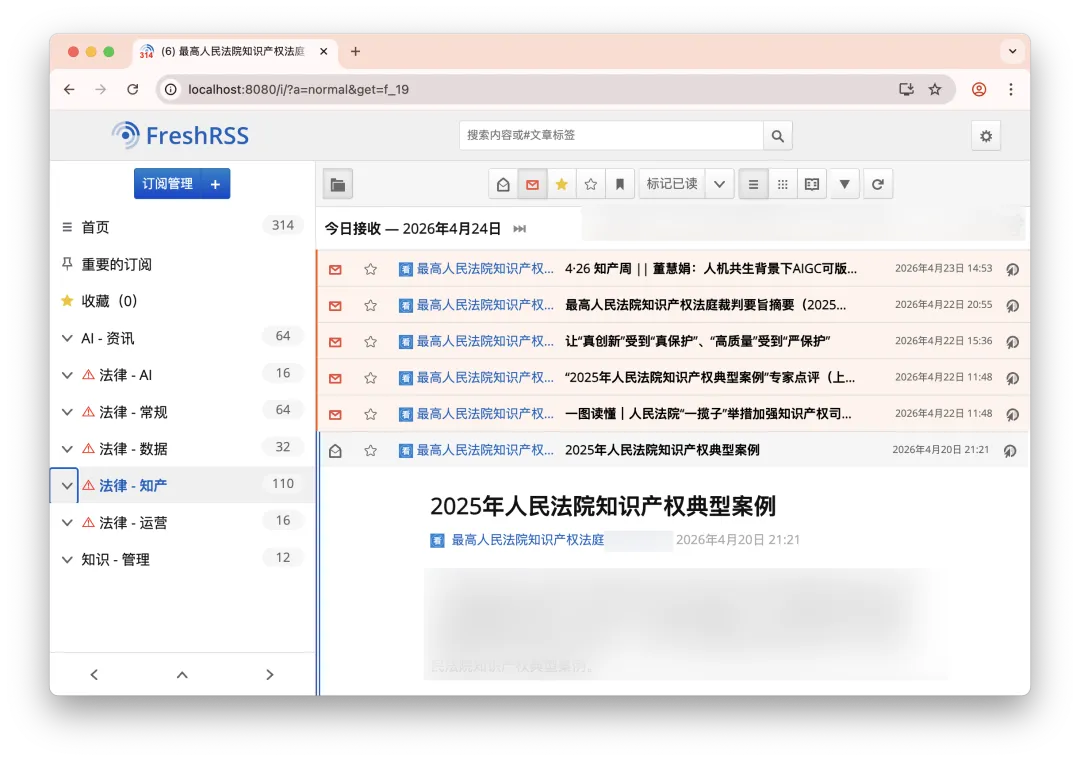
微信公众号没有公开 API,无法直接被抓取。
解决方案:在一台单独的电脑上用 Docker 部署 FreshRSS,订阅法律公众号(具体方案可以看我之前的文章),自动全量导出。导出的文件通过网络共享到工作目录。
这是基础设施,不属于 Skill 的职责范围。
Skill 负责的是”判断和处理”。
三、定时触发:让 Agent 每天主动巡逻,而不是等人来问
流程的驱动来自 OpenClaw 的 cron 定时任务。
每天 8:00(Asia/Shanghai),系统自动触发 legal-rss-monitor skill。Agent 带着 skill 内部的指令开始执行。
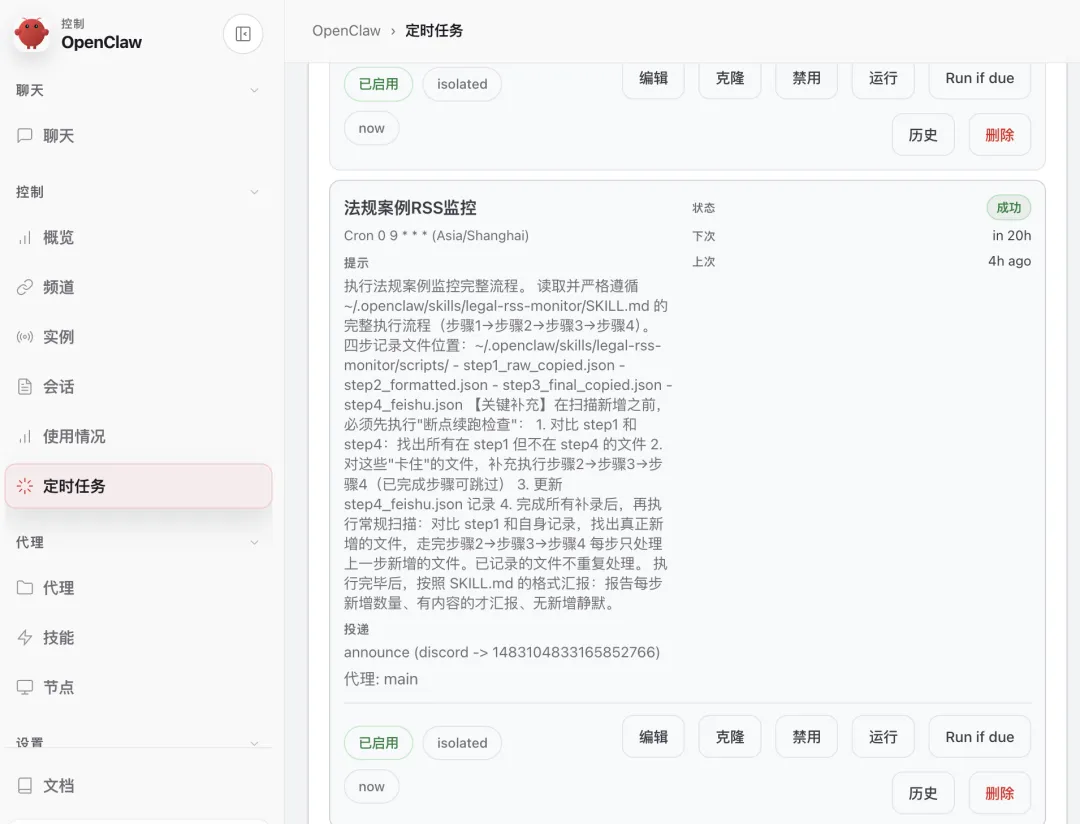
定时任务的配置方式是 delivery 模式设为 none——系统不自动发汇报,由 Agent 在有新增内容时主动发 Discord 消息。
没有新增就安静待命,不打扰任何人。
四、判断层:让 Agent 学会筛选,什么要、什么不要
最高法发布 2025 年度知识产权典型案例(10个)——这是最近刚被抓取的一批。我们用它作为实例,展示步骤1的判断逻辑。
Agent 逐篇读取微信公众号 RSS 导出的 Markdown 文件,判断是否属于以下两类:
类型一:典型案例汇编——各级法院或行政机关正式发布的案例汇总,通常3个案例以上。最高法院、各地方知识产权法院、北京互联网法院,国家知识产权局等发布的案例汇总均属此类。
类型二:重要法规更新——正式发布的法规、条例、规定、办法、批复、通知、公告等。
这个文件(最高法2025年度知识产权典型案例,10个案例)符合类型一,直接复制到「外部同步/法律法规/」,并记录到 step1_raw_copied.json。
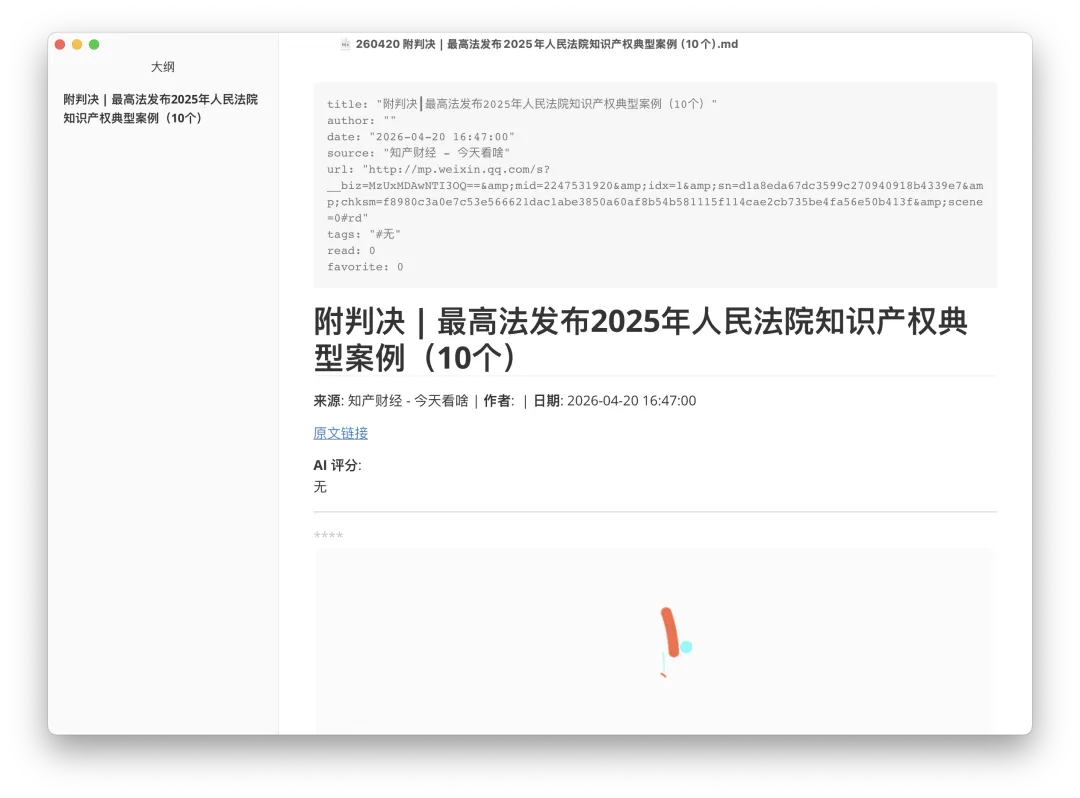
抓取并复制的原始版的文章,带有很多冗余的内容和格式
去重规则:同一批案例可能被两个公众号转载——原始版通常在20KB以上,聚焦解读版通常在5KB以下。Agent 比对字数,保留更完整的版本。
legal-rss-monitor Skill 的设计逻辑
核心不是”抓取”,而是编排——它本身不访问任何外部 API,而是读取 FreshRSS 已经导出的本地 Markdown 文件,按照四步流水线逐层推进。
设计分为三层:
配置层(
config/config.json):定义 RSS 源文件夹路径,知识库存放位置、各步骤输出路径,去重规则。修改配置不需要改代码。记录层(四组 JSON 文件):
step1_raw_copied.json、step2_formatted.json、step3_final_copied.json、step4_feishu.json。每步独立记录,每次只处理”上一步有记录但当前步骤无记录”的文件。已完成的步骤不重复执行。这是断点续跑的保障。执行层(workflow-steps.md):每一步的具体操作指令。Agent 严格按照这个执行。
五、格式化:把”残稿”整理成结构化标准件
经过判断层筛选留下来的文件,送去做格式化——把公众号文章的”残稿感”去掉,变成干净的结构件。
读取 step1 记录的文件,调用 legal-text-format skill 对原文做规范化处理。
公众号法律文章的常见问题:
-
中文标点不统一(全角引号「」混用) -
标题层级缺失或混乱 -
底部大量推广内容(联系方式、订阅提示) -
加粗标记残留( ### 裁\*\*判\*\*要旨)
格式化后的「最高法2025年度知识产权典型案例(10个)」结构清晰,公众号推广信息已清除,正文结构化保留,案例之间层级分明。
格式化文件保存到 skill 的 archive 目录,记录到 step2_formatted.json。

经过
legal-text-format格式化之后的案例文章,顺眼了很多
legal-text-format Skill 的设计逻辑
这个 Skill 的核心职责是格式化和内容清理,它的设计理念是”只做一件事,把这件事做到极致”。
输入类型:接受三种输入——已抓取的文本内容、用户直接粘贴的文本、本地 Markdown 文件。
两步归档机制:每次处理都会在
archive/{时间戳}_{主题}/目录下同时保存*_raw.md(原始内容)和*_formatted.md(格式化结果)。内容范围限定(关键的设计):只保留从第一个案例到最后一个案例的正文,删除文章开头介绍、作者信息、引言等内容。
格式化规则分两类:法律条文和法律案例各有独立的规则集。条文规则核心是”第X条”加粗、章标题加二级标题;案例规则核心是标点全角化、案例名加二级标题等。
六、终点:文档自动入住飞书知识库,有人看才通知
格式化完成之后,文件兵分两路:一路留在本地工作目录做备份,另一路直接送进飞书知识库。
步骤3,读取 step2 记录的文件,先在本地工作目录留一份备份。复制到「工作文档/002-法律法规/」,文件名加日期前缀:
20260420_最高法2025年度知识产权典型案例(10个)_formatted.md
本地保留一份备份,方便后续人工编辑整理。
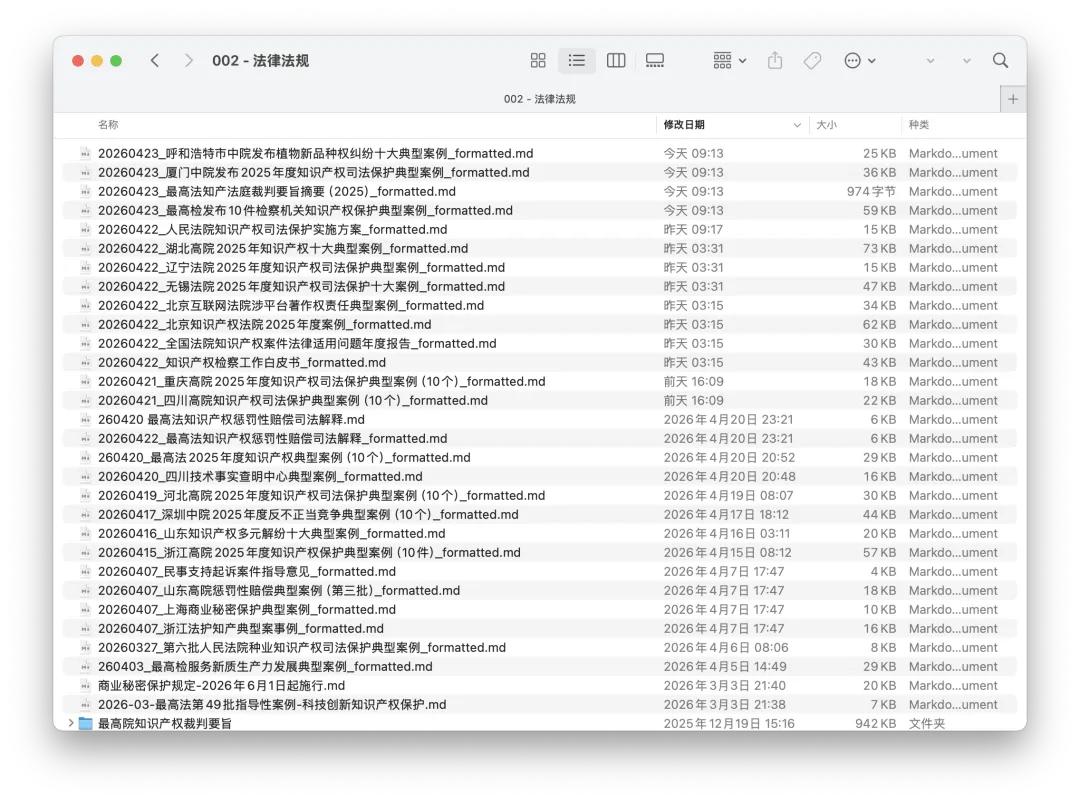
都是这两天自动抓取更新的案例及最新法律法规
步骤4,再读取 step3 的文件,使用飞书 OpenClaw 插件提供的 feishu-create-doc Skill 创建文档,关键参数:
上传完成,记录文档 URL 到 step4_feishu.json。
↓
Discord 汇报(仅步骤1有新增时触发)

汇报格式也已经固定在了 cron 定时任务
feishu-create-doc Skill 的作用
这是飞书 OpenClaw 插件提供的 Skill,负责将 Markdown 内容转换为飞书云文档。
它只负责”创建文档”这一件事,传入标题和内容,返回文档 URL。支持传入 Lark-flavored Markdown,包括高亮块、表格、分栏等富格式。
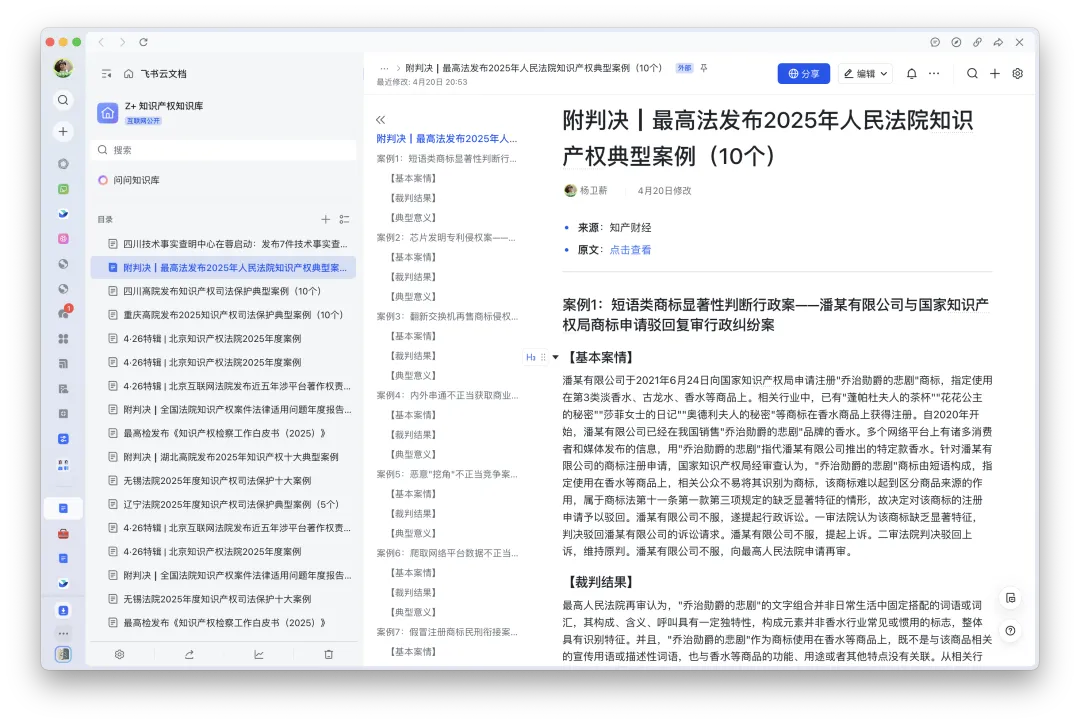 最终汇总到飞书知识库,就是左侧侧边栏和正文的效果。
最终汇总到飞书知识库,就是左侧侧边栏和正文的效果。
所有文章都已自动标准化处理,如果要去核实,可以点击文中的原文链接去查看。
正常来说,只需要删掉最开始的两行,就可以直接入库。
定稿版本欢迎点击查看,只花了半分钟删除一些核实字段和拖动文件编排https://k8cp3rcjj0.feishu.cn/wiki/UTJ7wLUiVixoj4kFINXcePVfnQg
七、核心价值:把”持续监控”变成不用操心的事
核心价值不在于省了多少时间。
而在于没有人盯着的时候,系统依然在运转。
典型案例的价值在于积累,需要持续监控新的发布。人工盯着盯着,总会因为各种事情打断,然后就没有然后了。
Skill + 定时任务,把这件事变成了基础设施。
每天早上 8 点自动跑一遍,有新增才通知,没有就安静。
这套系统的目标不是”炫技”,是让案例监控变成一件不用操心的事。
如果你也在手动跟踪案例动态,不如尝试一下我的这个思路。
PS:也许有人会问,已经有外部的北大法宝、威科先行,为什么要自己花时间去做一个案例库?
这个问题,之前的这篇文章也许可以给你解答:别再造“小号北大法宝”了:越大越废的自建 AI 知识库
相关 Skill 与工具
本文涉及的核心组合:OpenClaw + 3个Skill + 1个定时任务。
-
legal-rss-monitor:RSS 扫描与四步流程编排,断点续跑保障(个人使用) -
legal-text-format:公众号文章格式化,法律场景专用(https://github.com/cat-xierluo/legal-skills) -
FreshRSS:公众号 RSS 导出(https://www.freshrss.org/,非 skill) -
feishu-create-doc:飞书云文档创建 Skill(飞书 OpenClaw 插件内置) -
OpenClaw cron 定时任务:每天 8:00 触发 legal-rss-monitor,有新增内容时主动推送 Discord 消息,无新增则安静待命