 夜雨聆风
夜雨聆风





【假日谈AI】DeepSeek-V4低调发布,百万上下文将重塑水务AI底座?


“不诱于誉,不恐于诽,率道而行,端然正己。”
特别认可写在DeepSeek发布公众号推文最后的这句话,它很能体现这个国内优秀大模型的价值坚守!
4月24日,DeepSeek发布V4预览版,宣布将100万token超长上下文做成全系标配——无需额外付费,开源可用。消息一出,不少人直呼:大模型终于从”奢侈品”变成了”日用品”。
这和水务行业有什么关系?关系大了。
水务系统可能是当前AI落地最需要长上下文的行业之一。一座日处理量20万吨的自来水厂,背后是上千页的工程图纸、上万行的SCADA数据记录、数百万字的标准规范——过去的AI模型受限于几十K的上下文,面对这些”大部头”只能截断、碎片化处理,信息断层严重。
而DeepSeek-V4把这个问题解决了,顺手还给水务AI打开了新世界的大门。
一、DeepSeek-V4到底牛在哪?先说技术干货
一句话总结:把百万字上下文从“天花板”变成了”地板价”。
V4系列包含两个版本:
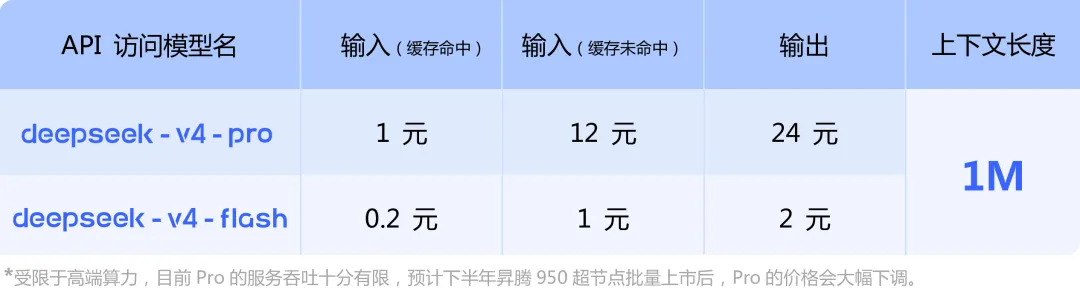
•DeepSeek-V4-Pro:旗舰性能,总参数约1.6T(激活49B),在Agentic Coding等评测中刷新开源模型纪录,超越Claude Sonnet 4.5
•DeepSeek-V4-Flash:高性价比,总参数约284B(激活13B),成本更低,响应更快,适合日常轻量场景
最核心的突破在于三点:
核心技术一:DSA稀疏注意力+混合注意力架构
•传统注意力机制,计算量随上下文长度平方增长,是百万上下文最大的瓶颈
•V4自研DSA稀疏注意力机制,在token维度压缩计算量
•采用CSA(压缩稀疏注意力)+ HCA(重度压缩注意力)交替组合,把计算量和缓存体积同时压下来
•百万token场景下,V4-Pro单token推理FLOPs仅为前代V3.2的27%,KV缓存占用仅为其10%
核心技术二:100万token超长上下文全系标配
•约75万汉字,无需额外配置,无需额外付费
•可直接处理整本书籍、完整代码仓库、大型工程合同与企业知识库
•告别信息截断、逻辑断裂,全局理解成为现实
核心技术三:Agent能力开源领跑
•V4-Pro在Agentic Coding评测中达到开源最佳
•支持复杂任务拆解、多步骤推理与工具调用
•可高效完成代码生成、文档处理、数据分析、自动化工作流等智能体任务
二、水务AI为什么特别需要长上下文?
水务系统的数据和文档有三个特点,让它成为长上下文AI的”天然战场”:
特点一:文档体量超大
•一座净水厂的标准规范文件包,往往超过50万字
•管网GIS数据、SCADA历史记录,动辄数GB
•行业法规、标准图集、应急预案,叠加起来是真正的“大部头”
特点二:上下文关联强,断层代价高
•水锤分析需要整个管段的材质、管龄、接口形式全部纳入分析
•水质异常溯源,要关联从取水口到龙头的全流程数据
•漏损定位如果截断管网前半段,后面的空间关系全部丢失
特点三:专业术语密集,通用模型难以理解
•“浊度NTU””余氯””矾花””水锤瞬变”——专业词汇横亘其中
•短上下文模型往往只能做浅层关键词匹配,无法真正理解水务逻辑
过去,行业普遍的做法是把大文档“切片”——拆成若干小段落,分别分析后再拼接。但这种方法存在根本性缺陷:段落之间的关联逻辑会丢失。打个比方,切片分析就像只看到棋盘上几个散落的棋子,而看不到整盘棋在走什么。
DeepSeek-V4的长上下文,让AI第一次能”看完一整盘棋”。

三、DeepSeek-V4在水务行业的四大应用场景
基于DeepSeek-V4的水务AI应用,目前可见的落地场景主要有以下几个方向:
场景1:全厂工艺资料”超级问答助手”
一座水厂的完整工艺参数、操作规程、设备手册加在一起,往往超过百万字。以往员工遇到异常情况,要么翻纸质手册找不到,要么问老师傅靠经验。
基于V4打造的工艺知识助手,可以一次性”吃下”整本工艺手册,员工提问时,AI直接引用手册原文回答,并标注依据来源——这对于新员工培训、夜间值班应急都有直接价值。
场景2:智能体驱动”无人值守泵站”
V4-Pro的Agent能力已经在代码生成领域超越了Claude Sonnet 4.5,这意味着它有足够强大的任务拆解和工具调用能力。
在泵站自动化场景中,AI智能体可以:基于实时数据判断泵组启停顺序;发现异常工况时自动生成故障报告并调用工单系统;结合气象预报和历史数据,提前预测次日用水曲线,给出调度建议。真正让泵站从”有人值守”过渡到”智能自治”。
场景3:完整工程合同”一稿过”审查
水务行业涉及大量工程合同:管网改造、设备采购、污水厂委托运营——这些合同少则几十页,多则上百页。
过去靠人工逐条审查,容易遗漏关键条款;通用AI因为上下文限制,只能看开头和结尾,核心风险点往往藏在中后段。
V4的百万上下文可以让AI一次性通读整份合同,从建设规模、付款节点、违约责任到水质达标标准,全面审查并标注法律风险——法务+技术的双重视角,这是过去任何工具都做不到的。
场景4:数字孪生+AI,”推演”整座城市的供水网络
数字孪生是水务行业的热门方向,但传统孪生体往往是“静态”的——只能在虚拟环境中展示现状,难以真正做推演预测。
结合V4的长上下文能力,AI可以将整座城市的供水量历史记录、管网拓扑结构、水厂工艺参数全部输入,在虚拟环境中进行多工况模拟:百年一遇暴雨、节假日用水峰值、突发管网故障——在秒级时间内生成最优调度方案,并同步输出到实际调度系统。
这已经不只是“可视化”,而是真正的”可推演、可决策”。
四、水务AI的”iPhone时刻”要来了?
2018年前后,智慧水务的概念开始在国内普及,核心是把传感器和SCADA系统铺进水厂和管网,数据开始上网、上云。
但数据上了云之后,真正的分析决策还是靠人——调度员盯着屏幕看数据,工程师对着Excel做分析。这种模式在水量稳定的时代够用,但在气候变化加剧、用水结构快速变化的当下,已经出现瓶颈。
大模型+长上下文+Agent能力,这三者的组合,正在把”人找数据”变成”数据找人”。不是等人提问,而是AI主动推送:明天用水量预测偏高,建议提前调整出厂水压;某段管网漏损风险上升,建议本周内完成巡检;某个药剂投加比例偏离最优区间2.3%,建议校正。
DeepSeek-V4的开源,给了水务行业一个低成本的AI底座:不需要高昂的API费用,不需要依赖闭源模型,自己部署、自己微调、自己私有化——数据不出门,能力自己留。
从这个角度说,水务AI的”iPhone时刻”不是某一天突然到来的,而是在一次次像V4这样的技术突破中,逐步逼近的。
假日的意义,是让人停下来,看见趋势。这篇文章,希望在你度假归来时,能让你看到:水务AI,正在进入一个新的时间窗口。
结语
DeepSeek-V4的发布,核心不是”又出了一个更强的模型”,而是让高性能AI正式走向普惠。水务行业的特殊性,决定了它特别需要这样的技术:文档大体量、数据高关联、专业强门槛。
百万上下文解决的不只是“更长”,而是”更完整”——完整的水系统认知,才能带来真正有价值的水务决策。
【互动环节】
这可能是水务AI从”玩具”走向”工具”的关键一跃。
你怎么看?欢迎在评论区留下你的判断。
关注 “运通智水研究”
获取更多智慧水务案例解析、技术前沿、政策解读。
点赞、在看、转发,共同打造合作共赢的智慧水务生态!
 扫码关注最新动态
扫码关注最新动态

请在微信客户端打开