 夜雨聆风
夜雨聆风





GBrain:让AI Agent拥有完美记忆的知识系统
Y Combinator总裁Garry Tan开源的”数字大脑”,能否成为AI助手的关键基础设施?
缘起:一个困扰AI的古老问题
“我Agent经常忘记半小时前说了什么。”
这个看似简单的问题,却是当前AI助手发展最大的瓶颈之一。当我们在与AI对话时,每次都是全新的开始——没有记忆累积,没有知识沉淀,更谈不上智能的进化。
直到Garry Tan在Twitter上扔下了一枚重磅炸弹:
“如果你想让你的OpenClaw或
Hermes Agent能够完美记忆所有10,000+个markdown文件,GBrain来帮忙了。这正是我的OpenClaw/Hermes Agent设置。MIT开源许可。希望能帮助你构建你的迷你AGI。”
这条推文在短短24小时内获得了惊人的3603个赞和381次转发,整个AI社区为之震动。
GBrain是什么?
简单来说,GBrain是Vannevar Bush在1945年构想的”Memex”的现代实现——一个为思考者而生的数字大脑。
但理解GBrain,更需要了解它诞生的背景:
Garry Tan的数字大脑实验
Garry Tan,作为Y Combinator的总裁,开始为自己的OpenClaw Agent构建一个markdown知识库。他采用了一个简单的原则:
-
• 每人一页文档 -
• 每家公司一页文档 -
• 顶部是与时俱进的编译真理 -
• 底部是只追加的时间线
这个简单的模式产生了惊人的效果。Agent知道得越多,就越聪明。于是Garry不断”喂养”它:
-
• 会议记录 -
• 邮件往来 -
• Twitter内容 -
• Apple Notes -
• 日历数据 -
• 原创想法
仅仅一周时间,他的数字大脑就达到了令人震惊的规模:
10,000+ markdown文件被索引和搜索
3,000+ 人物档案和关系历史
13年 的日历数据(21,000+事件)
5,800+ Apple Notes(追溯到2009年)
280+ 会议记录和AI分析
300+ 组织化的原创想法
500+ 媒体页面(视频转录、书籍、文章)
这不仅仅是理论,而是Garry每天真正在使用的系统。Agent在他睡觉时持续运行……字面意义上的”梦境循环”会扫描当天的每次对话,丰富缺失的实体,修复损坏的引用,整理记忆。
第二天早上,大脑比他入睡时更聪明了。
为什么需要Postgres?
当有500个文件时,grep就够了。但当有3,000个人物页面、5,800个Apple Notes和13年的日历数据时,grep就崩溃了。
你需要:
-
• 关键词搜索——精确查找人名 -
• 向量搜索——语义匹配 -
• 融合算法——两者结合
你需要一个能够毫秒级找到”三月份参加董事晚宴的所有人”的索引,而不是30秒的grep等待。
GBrain提供了混合搜索,结合了关键词和向量方法,以及一个将每个页面都视为情报评估的知识模型:
-
• 顶部的编译真理(当前最佳理解,随证据更新而重写) -
• 底部的时间线(永不编辑的证据轨迹)
复合增长的威力
大多数工具只是帮助你找到东西。GBrain让你随着时间的推移变得更聪明。
其核心循环是:
信号到达(会议、邮件、推文、链接)
→ Agent检测实体(人物、公司、想法)
→ 读取:先检查大脑(gbrain搜索、gbrain获取)
→ 带着完整上下文回应
→ 写入:用新信息更新大脑页面
→ 同步:gbrain为下次查询索引更改每次通过这个循环都会增加知识。Agent在会议后丰富人物页面。下次这个人出现时,Agent已经有了上下文——他们的角色、你们的历史、他们关心什么、上次讨论了什么。你永远不需要从零开始。
没有这个循环的Agent从过时的上下文中回答。拥有这个循环的Agent每次对话都会变得更聪明。差异每天都在复合增长。
你可以用GBrain做什么?
Garry Tan展示了一些令人印象深刻的使用场景:
“谁认识Pedro和Diana,我应该邀请谁来晚宴?”
—— 跨3,000+个人物页面引用社交图谱
“我对羞耻感和创始人表现之间的关系说过什么?”
—— 搜索的是你的思考,而不是互联网
“自周二以来,A轮融资有什么变化?”
—— 跨交易和公司页面对比时间线条目
“30分钟后跟Jordan的会议准备”
—— 拉取档案、共同历史、近期活动、开放话题
这个系统不仅仅是搜索工具,它是真正意义上的”第二大脑”。
社区的反响
Garry的开源引发了AI社区的激烈讨论:
SelanVeydris:
“我们基本上正在从无状态提示转向持久记忆系统。像Engraph这样的工具在这里很有趣——它们将原始笔记/数据转化为结构化、可查询的记忆层,Agent可以在其上累积构建。感觉真正的解锁不是更好的提示,而是更好的记忆。🧠”
vishalojha_me:
“我把它扔给Claude进行完整审查。仅梦境循环就值得这个星标。无状态Agent是死路一条,这是缺失的持久层。”
mrsharma:
“Garry这太棒了!!通过3个阶段添加到我的OpenClaw中,砰!”
许多开发者询问了与其他工具的兼容性、性能对比以及实际部署成本等问题,显示出强烈的实际应用兴趣。
技术架构深度解析
知识模型
每个大脑页面都遵循”编译真理 + 时间线”模式:
---
type: concept
title: Do Things That Don't Scale
tags: [startups, growth, pg-essay]
---
Paul Graham认为,创业公司早期应该做不可扩展的事情。
最常见的是手动一个一个招聘用户。Airbnb挨家挨户
在纽约为公寓拍照。Stripe为早期用户手动
安装他们的支付集成。
关键见解:不可扩展的努力教会了你用户真正
想要什么,这是你无法通过其他方式学到的。
---
- 2013-07-01: 发布于paulgraham.com
- 2024-11-15: 在W25启动会议中被引用
- 2025-02-20: 在关于AI Agent入职策略的讨论中被引用---分隔符上方:编译真理。你当前的最佳理解。当新证据改变图景时会被重写。下方:时间线。只追加的证据轨迹。只被添加,从不编辑。
编译真理是答案。时间线是证明。
搜索机制
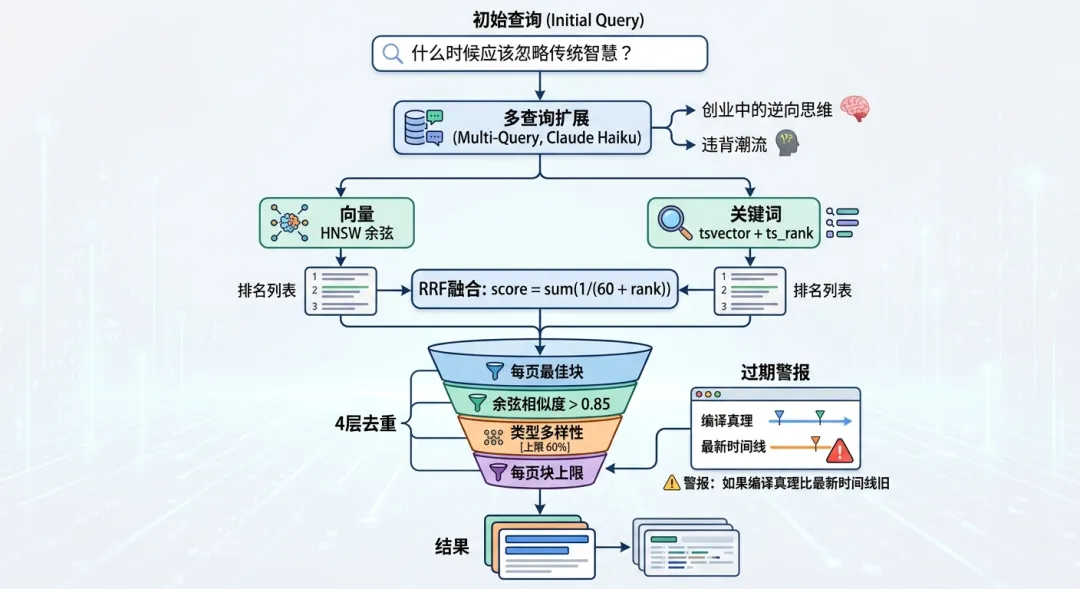
只使用关键词搜索会错过概念匹配。”忽略传统智慧”找不到名为”天才巴士票理论”的文章,尽管这完全就是关于那个主题。只使用向量搜索会在嵌入被周围文本稀释时错过精确短语。RRF融合两者都对。多查询扩展捕捉你没想到了的表述。
与OpenClaw/Hermes 的集成
GBrain是世界知识——人物、公司、交易、会议、概念、你的原创思考。它是你对世界了解的长期记忆。
OpenClaw agent内存(memory_search)是操作状态——偏好、决策、会话上下文、Agent应该如何表现。
它们是互补的:
|
|
|
|
|---|---|---|
| gbrain |
|
gbrain search
gbrain query、gbrain get |
| Agent内存 |
|
memory_search |
| 会话上下文 |
|
|
所有三层都应该被检查。GBrain用于关于世界的事实。内存用于Agent配置。会话用于直接上下文。
实际部署指南
先决条件
没有Postgres,你现在就可以使用GBrain知识模型:技能、模式和编译真理 + 时间线模式适用于任何读取和写入markdown文件的Agent。当grep不再足够时再添加Postgres。
使用Postgres时,GBrain需要三样东西:
|
|
|
|
|---|---|---|
| Supabase账户 |
|
|
| OpenAI API密钥 |
|
|
| Anthropic API密钥 |
|
|
安装步骤
对于OpenClaw或
将gbrain (https://github.com/garrytan/gbrain) 设置为我的
知识大脑。
1. 确保bun已安装:
curl -fsSL https://bun.sh/install | bash
然后运行:bun add github:garrytan/gbrain
2. 运行:gbrain init --supabase
(按照向导连接我的Supabase数据库)
3. 扫描 ~/git/ 和 ~/Documents/ 中的markdown仓库,
选择最好的一个,然后运行:gbrain import <path> --no-embed
4. 对导入的数据运行查询以证明搜索有效
5. 阅读docs/GBRAIN_RECOMMENDED_SCHEMA.md并提议
重构我的知识库
6. 阅读docs/GBRAIN_SKILLPACK.md并用生产Agent模式
更新所有你的技能:大脑-智能体循环、
实体检测、来源归属、铁法则反向链接、
和增强管道
7. 为`gbrain check-update`设置每日cron。
只在新功能时通知我,而不是补丁。
永不自动安装,只告诉我有什么新功能。
8. 设置自动同步,使向量数据库与
大脑仓库保持最新。阅读GBRAIN_SKILLPACK.md第18节
了解方法(cron、--watch、webhook)。选择适合
你环境的。总是链式:
gbrain sync --repo <path> && gbrain embed --stale
验证:推送更改,确认它出现在搜索中。
9. 运行验证手册(docs/GBRAIN_VERIFY.md)
确认一切正常:模式、同步、嵌入、
大脑优先查找。快速体验
GBrain不附带演示数据。它发现你的markdown并使其可搜索。
第一幕:发现 GBrain扫描你的机器寻找markdown仓库:
=== GBrain环境发现 ===
~/git/brain (2.3GB, 342 .md文件, 87个二进制文件)
类型:纯markdown(准备好导入)
~/Documents/obsidian-vault (180MB, 1,203 .md文件, 0个二进制文件)
类型:Obsidian仓库(可用wikilink转换)
=== 发现完成 ===第二幕:导入 你的文件从仓库移动到Supabase。
gbrain import ~/git/brain/
# 导入342个文件到Supabase(1,847个块)。后台嵌入中...
gbrain stats
# 页面:342, 块:1,847, 已嵌入:0(嵌入中...), 链接:0第三幕:搜索 Agent从你的实际内容中选择一个查询。
# Agent读取你的语料库并选择相关查询
gbrain query "我们对竞争动态了解多少?"
# 3个结果,通过混合搜索评分(向量 + 关键词 + RRF融合)
# 30秒后,嵌入完成:
gbrain stats
# 页面:342, 块:1,847, 已嵌入:1,847, 链接:0
# 现在语义搜索也上线了
gbrain query "我们现在的最大风险是什么?"
# 通过意义而不是关键词找到关于护城河、董事会准备和战略的页面你的文件数量会不同。你的查询会不同。Agent根据导入的内容选择它们。这正是重点:这是你的大脑,不是演示。
未来展望
GBrain代表了一个重要的范式转变:从无状态的AI助手到拥有持久记忆和持续学习能力的智能体。
正如社区成员所指出的,我们正在从”更好的提示”转向”更好的记忆”。这可能是AI发展到AGI的关键一步。
Garry Tan的开源举动,为整个AI社区提供了一个成熟的参考实现。这不仅是一个工具,更是一个完整的知识管理系统——从数据模型、搜索算法到Agent技能包的完整解决方案。
对于那些想要在中长期内保持竞争力的AI开发者来说,理解并实施类似的知识管理系统,可能是下一个重要的发展方向。
结语
当大多数人都还在讨论prompt engineering时,Garry Tan已经构建了一个每天都在变聪明的系统。GBrain告诉我们,真正的AI助手需要的不是更聪明的算法,而是更好的记忆。
这种知识的复合增长效应,正是通往更强大AI的关键路径。现在,这个路径向每个人开放。
相关链接:
-
• GBrain GitHub: https://github.com/garrytan/gbrain
如果你对构建自己的知识大脑感兴趣,或者想了解GBrain在你的项目中的应用,欢迎关注公众号「光影织梦」,给我们留言交流。