Harness 工程之拆解 AI 编程助手(四):CoreCoder的五个核心设计模式解析
前面三章我们看完所有模块的代码。这一章从”代码”上升到”设计”——提炼出 CoreCoder 中最重要的 5 个架构模式,分析它们的学术来源、工程取舍和可复用性。
ReAct 模式(Reasoning + Acting)
是什么
ReAct(Reasoning + Acting)是 2022 年由 Yao 等人提出的 AI Agent 范式[论文]。核心思想:让 LLM 交替进行推理(Reasoning)和行动(Acting),通过观察行动结果来修正推理。
CoreCoder 的实现
agent.py 的 chat() 方法就是 ReAct 模式的直接实现:
for _ in range(50): # ← 循环 resp = LLM.chat(messages + tools) # ← Reasoning: LLM 思考下一步 if no tool_calls: return text # ← 思考完毕,返回答案 execute tools # ← Acting: 执行工具 append results to messages # ← Observation: 观察结果 compress if needed # ← 维护记忆
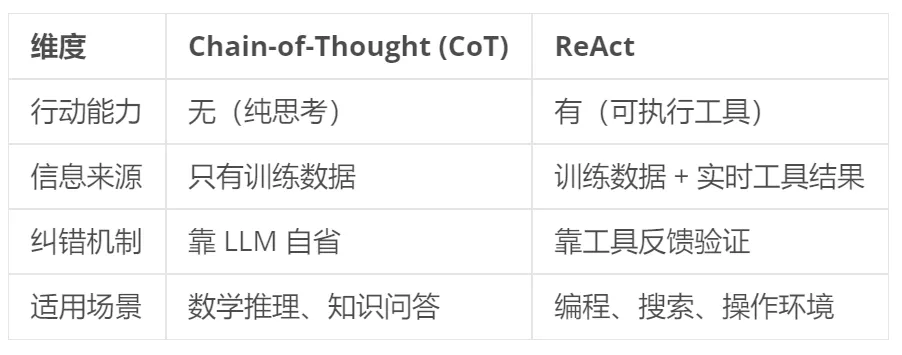
与传统 Chain-of-Thought 的区别
💡 面向 PM:CoT 就像一个只会纸上谈兵的顾问,ReAct 则是一个能亲自下场验证的实干家。你说”这个 import 可能拼错了”,CoT 只能猜,ReAct 可以实际读取文件确认。
策略模式(工具抽象)
是什么
策略模式(Strategy Pattern)是面向对象设计的经典模式——定义统一接口,用不同的具体实现应对变化。
CoreCoder 的实现
Tool (ABC) ← 策略接口├── BashTool ← 具体策略 A├── EditFileTool ← 具体策略 B├── ReadFileTool ← 具体策略 C├── WriteFileTool ← 具体策略 D├── GlobTool ← 具体策略 E├── GrepTool ← 具体策略 F└── AgentTool ← 具体策略 GAgent ← 上下文(Context) → tools: list[Tool] ← 持有策略列表 → get_tool(name) ← 按名查找策略 → tool.execute(**kw) ← 统一调用接口
开闭原则
-
创建新文件,继承 Tool,实现 execute()
-
Agent 的代码完全不需要修改。这就是开闭原则(Open-Closed Principle):对扩展开放,对修改关闭。
渐进式压缩(上下文管理)
是什么
不是一次性截断,而是三层递进,每层都有 fallback。
设计精髓
50% → Snip(免费) → 如果降到 70% 以下,到此为止 ↓ 没降够70% → Summarize(付费)→ 如果降到 90% 以下,到此为止 ↓ 还没降够90% → Collapse(付费)→ 最后防线
每层压缩后都会重新评估是否需要下一层,避免过度压缩。
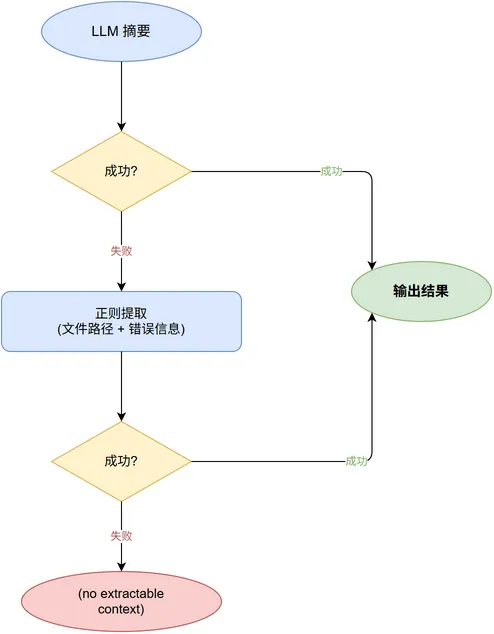
LLM 不可用时的降级链
🔧 这种”优雅降级”的思想贯穿整个系统:llm.py 先尝试 stream_options,失败就去掉;context.py 先尝试 LLM 摘要,失败就用正则。每条关键路径都有零依赖的 fallback。
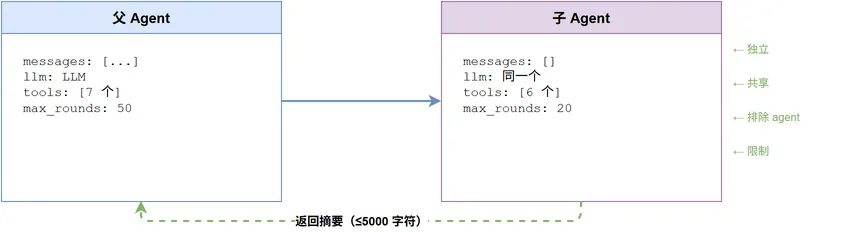
子代理隔离
是什么
为子任务创建独立的 Agent 实例,拥有自己的消息历史,任务完成后只返回摘要。
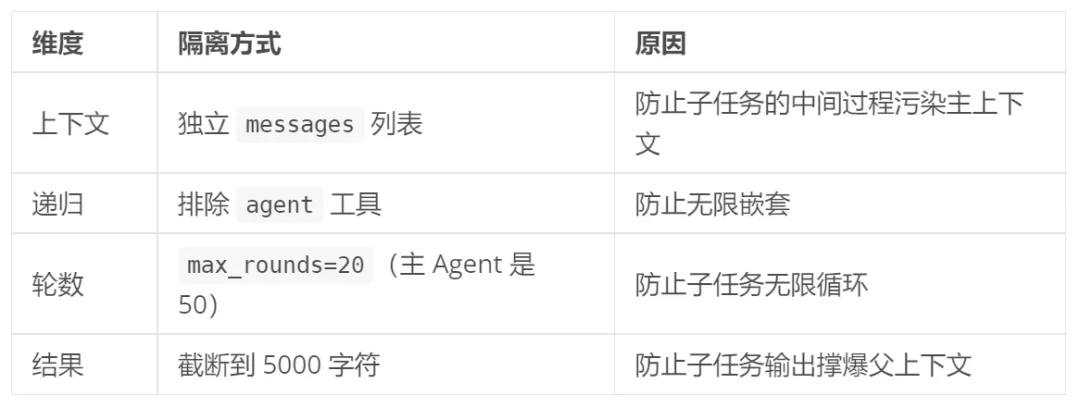
设计决策详解
安全防护
是什么
防护矩阵
所有截断/限制的核心目标只有一个:防止上下文爆炸。任何工具的输出都可能被塞进消息历史,如果某个输出过长,会加速触发上下文压缩甚至导致 API 报错。这些安全阀确保每条工具输出都在合理范围内。
💡 面向 PM:安全防护就像汽车的刹车系统——不是为了限制速度,而是为了在意外发生时保护乘客。AI 不会故意搞破坏,但它可能执行一条”看起来合理但实际危险”的命令。拦截机制给了人类一个审查的机会。
至此,我们对于CoreCoder的拆解就全部结束了。希望这个系列能帮助你快速理解 Harness的设计理念以及实现细节。如果你是开发者,建议克隆仓库后,边读文章边读源码,肯定会有收获。
另,推荐另一款近来热度很高的,类Hermes的一个极简、可自我进化的自主Agent 框架:
Generic Agent(https://github.com/lsdefine/GenericAgent)
 夜雨聆风
夜雨聆风