 夜雨聆风
夜雨聆风





Nature:上百个医疗 AI 数据涉嫌造假,且在医院里使用!

数据造假的 AI 模型,已经用到病人身上了
全球多个用于预测脑卒中和糖尿病的 AI 模型,训练数据可能是假的。
这些 AI 工具已经被引用进 124 篇同行评审论文,至少两个模型已在医院里用于真实患者。

数据哪里来的
没人说得清楚
澳大利亚昆士兰科技大学研究团队发表研究指出两个公开 AI 健康数据集存在严重异常,怀疑数据可能是伪造的,研究还登上了 Nature。

图源:Nature
第一个是卒中预测数据集,声称包含 5110 名患者的健康信息。
数据集上传者声称注明数据来自「机密来源」,仅供教育用途,但从未披露具体来源。
研究团队发现,整个数据集中 BMI 变量的缺失率仅有 0.3%,其他变量完全没有缺失值。
在真实的临床研究里,受试者会错过随访、中途退出或死亡,数据缺失几乎不可避免。
第二个是糖尿病预测数据集,声称包含 10 万人的医疗和人口统计数据。
图源:kaggle
上传者被问及数据来源时,以「保密原因」拒绝披露,也没有回应 Nature 的采访请求。
研究团队发现,10 万人的血糖数据里只有 18 个离散取值——在真实人群中,血糖值是连续分布的,这在生物学上根本不可能出现。
BMI 与血糖水平之间理论上存在强相关,但数据里完全看不到这个关联。

AI 工具已被下载超 40 万次
卒中数据集已被下载超过 28.8 万次,104 篇论文用它训练了 AI 模型;糖尿病数据集被下载超过 11.4 万次,21 篇论文使用了它。

图源:medRxiv
作者来自 32 个国家,其中印度第一,中国第三。
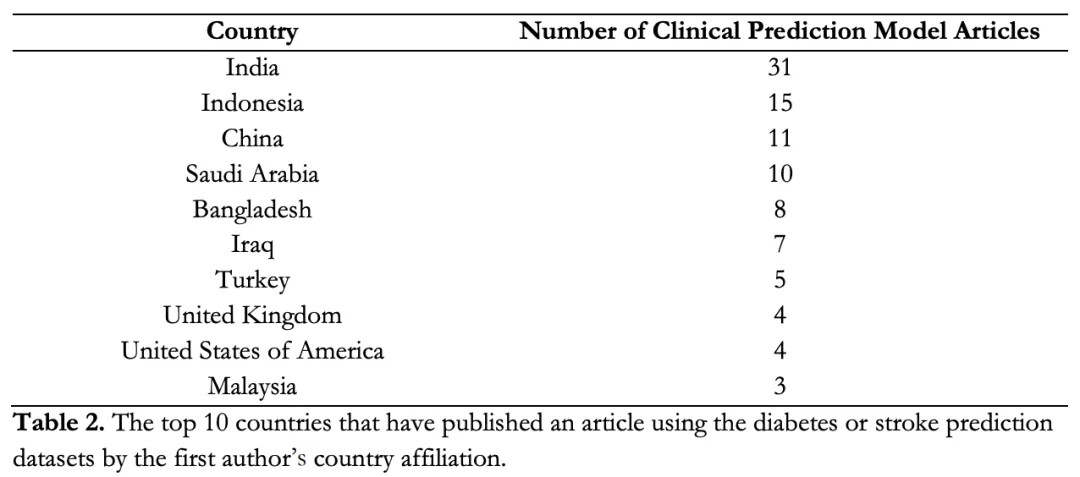
图源:medRxiv
更严重的是,至少一个卒中预测模型已在印度尼西亚某医院部署,另一项研究暗示该模型正在美国某心脏诊所使用。
一个模型出现在 2024 年提交的医疗设备专利申请中,还有两个是公开可访问的网络工具,任何人都可以上传个人信息来检测患病风险。
当被问及为何使用来源不明的数据时,部分论文作者回复说:「在进行研究和提交稿件时,我们没有意识到数据集可能是合成或模拟的。」
目前已有至少三篇相关论文被撤稿,撤稿声明中写明「对研究中使用的数据的来源和有效性表示担忧」。
平台方面则拒绝就是否会对这两个数据集采取行动作出回应。

来源不明的 AI
不应用在任何地方
这不是抽象的数据质量问题。
AI 模型的性能,完全取决于训练数据的质量。
如果数据不代表真实人群——不管是因为伪造、还是因为只反映了特定人群,模型学到的模式就是错的。
用假数据训练出来的卒中风险预测工具,可能在某些真实患者身上系统性地低估风险,也可能在另一些患者身上系统性地高估。
医生看到的是「AI 评分」,但这个数字背后是什么,没有人能追溯。
研究者的呼吁,使用来源不明数据集训练的预测模型,不应在临床决策中使用。
机构和资助方应强制要求披露训练数据来源,期刊应拒绝不符合要求的论文,同时建议将这两个数据集从 Kaggle 下架。
一个模型的可信度,取决于它是用什么数据建立起来的,这件事不应该是事后才去追问的问题。