 夜雨聆风
夜雨聆风





OpenClaw更新!DeepSeek V4-flash,凭什么拿下Agent框架首选?
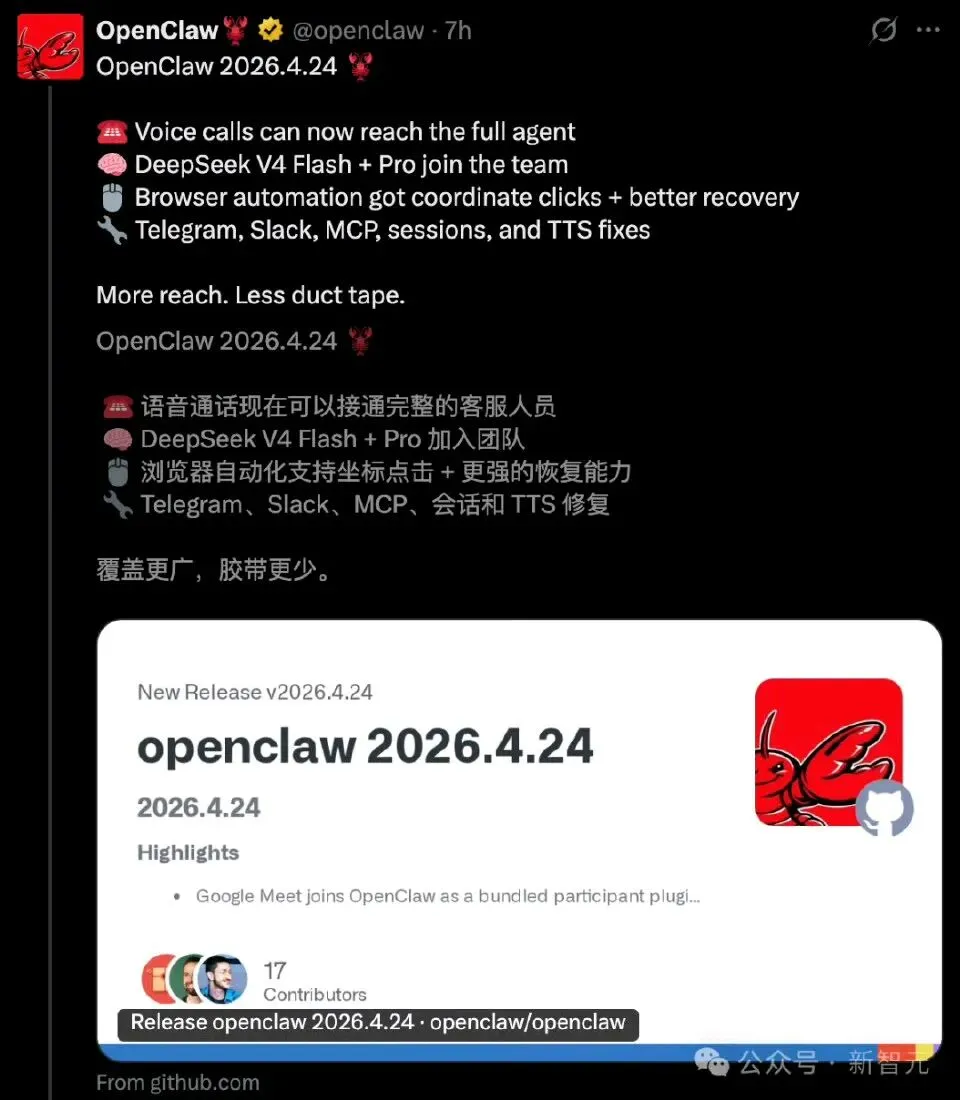
这不是一次普通的模型切换。
2026年4月24日,OpenClaw 在一轮更新中 quietly 完成了一个关键动作:
将默认大模型从 Anthropic Sonnet 4.6 切换为 DeepSeek V4-flash。
风向变了。
为什么是 Flash,不是 Pro?
DeepSeek V4 有两个版本:
🔸 V4-Pro:1.6万亿总参数、490亿激活参数
🔸 V4-flash:2840亿总参数、130亿激活参数
选择 Flash 而非 Pro,表面看像是”降级”,但这一步,恰恰是 OpenClaw 作为 Agent 框架做出的最正确的选择。
原因很简单:
OpenClaw 本质是 Agent 框架,核心模式是多轮工具调用。
用户提出任务 → Agent 拆解步骤 → 调用搜索、代码执行、文件读写、网页浏览等能力,每一步都要跑大模型。
任务越复杂,轮次越多,上下文越长。
在这种场景下,模型选型逻辑彻底变了:
不再追求”单次能力最强”,而是长上下文、低成本、开源透明三者的平衡。
V4-flash 正好站在这个平衡点上:
🔸 两个版本均支持 100万 token 上下文
🔸 开源领域里极少能同时做到”大参数 + 超长上下文”
🔸 推理成本极低,速度显著快于 Sonnet 4.6
在 Max 推理模式下,V4-flash 的编码与路由能力几乎追平 Pro。
对绝大多数日常 Agent 任务而言,Flash 完全够用;只有极少数极限场景才需要切换到 Pro。
这不是降级,是精准选型。
Sonnet 4.6 输在哪?
Sonnet 4.6 很强,但它不适合做 Agent 基座。
第一,上下文窗口不够。
Sonnet 上限约 200K,对需要保留完整历史的多轮 Agent 任务来说,只是起步水平。
第二,闭源生态不可控。
成本不可控,能力天花板由厂商决定,工具调用优化必须等官方更新,框架层无法深度定制。
而 V4-flash 开源,意味着:
🔸 部署方可以自主控制成本
🔸 社区可以持续积累优化经验
🔸 全球 OpenClaw 开发者的数据会持续反哺生态
这是闭源模型永远给不了的自由度。
Agent 时代的大模型新法则
DeepSeek V4 在架构上,做了只有 Agent 框架开发者才能真正读懂的设计:
把工具调用场景,当作一等公民来优化。
1. 完整保留跨轮次推理历史
V3.2 会在新消息到来时丢弃 thinking trace,而 V4 彻底改掉了这个问题。
在工具调用链路中,全部思考内容都会被保留,包括跨用户消息的推理链。
在 OpenClaw 中跑长任务,即便用户中途补充信息,Agent 也不会”失忆重启”,而是延续思考链继续推进。
2. Special Token 附件任务机制
传统方案需要额外小模型负责意图识别、触发判断,每次都要重新 prefill,首字延迟高。
V4 直接通过 special token 附加任务,复用 KV cache,省去冗余 prefill,大幅降低延迟。
3. KV cache 极致优化
V4 采用 CSA + HCA 混合注意力架构:
🔸 100万 token 上下文下,单 token 推理 FLOPs 仅为 V3.2 的几十分之一
🔸 KV cache 体积同样大幅缩减
同样硬件,能支撑更长上下文、更多并发会话。
这不是”更强的模型”,这是为 Agent 量身定做的模型。
为什么这次切换是一个强烈信号?
OpenClaw 的选型转变,标志着一件事:
Agent 框架的竞争,已经进入新阶段——框架开始反向定义大模型。
过去是大模型说了算,框架去适配。
现在是框架明确提出需求:
我要 1M 上下文、低延迟工具调用、可负担的调用成本,
然后社区再去寻找、甚至共同打造最匹配的基座。
DeepSeek V4 从第一天起,就不是为了对标 GPT 类通用模型,
而是为 Agent 时代的工具调用场景而生。
一个值得注意的细节
V4-flash 与 V4-pro 均开源,采用 MIT 协议。
DeepSeek 在技术报告中明确写道:
全球的使用经验,会促进技术持续进步。
这是开源生态最强大的正循环:
用的人越多 → 数据越多 → 模型越好 → 框架更强。
OpenClaw 将默认模型切换为 V4-flash,意味着全球每一次 Agent 调用,都在为这个循环贡献力量。
结尾
Agent 时代需要什么样的大模型?
不是单点性能最强的那一个,
而是在 长上下文、工具调用成本、多轮推理连贯性 三个维度最均衡的那一个。
V4-flash 不是参数最大的模型,
但它是最适配 Agent 框架工作模式的模型。
OpenClaw 用一次沉默的切换,给出了答案。
这不是一次普通的换模型。
这是 Agent 时代,大模型选型逻辑重构的第一张牌。
*本文基于 OpenClaw v2026.4.24 更新说明及 DeepSeek V4 技术报告撰写。*