夜雨聆风
夜雨聆风





【统计分析软件SPSS】56、替换缺失值
链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
由于微信公众号已发布文章的内容及排版顺序无法二次编辑,为了方便大家后续查阅、检索,同时便于我对内容进行补充更新与完善,我会将所有已发布的推文,在个人网站上以结构化文档的形式重新整理、归档。欢迎前往查看:
https://www.mizhushare.com/docs/
在数据分析过程中,我们常常会遇到数据缺失的情况。这些缺失值不仅影响样本量,更可能导致分析结果出现偏差。直接删除虽然简单,但会损失宝贵的信息,特别是当样本量本就不足时。
SPSS中的【替换缺失值】功能可以快速、科学地填补这些数据空白。

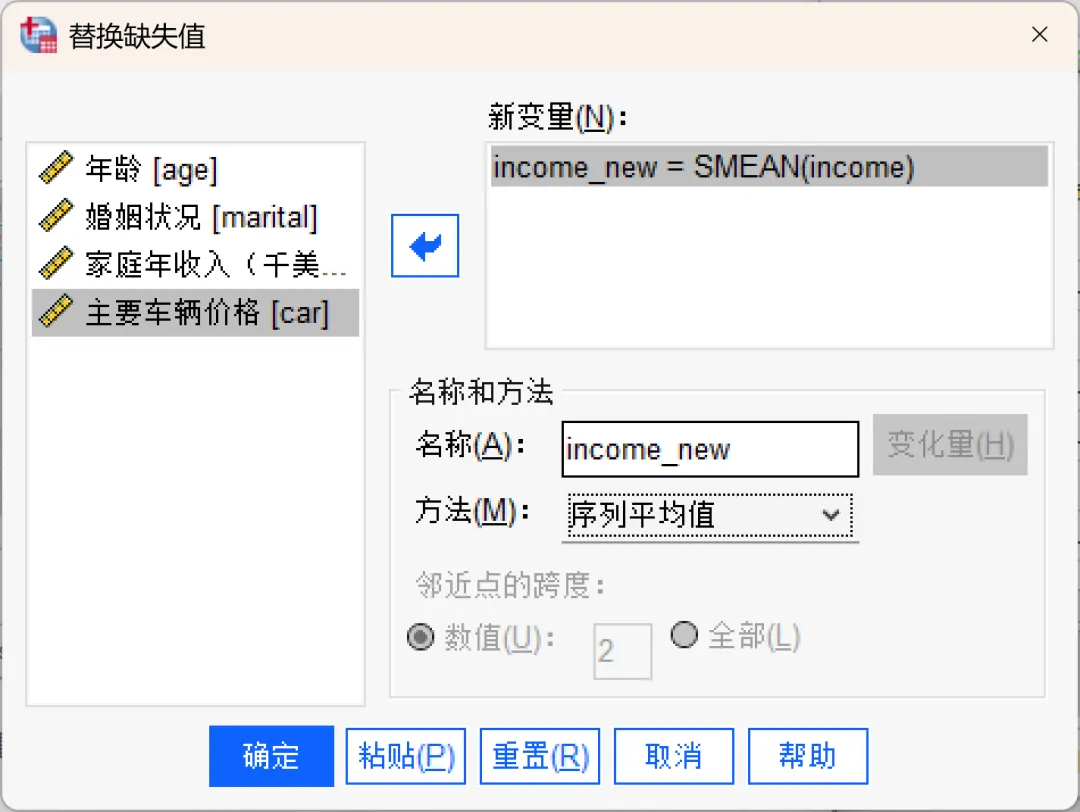
点击顶部菜单栏的【转换→重新编码为相同变量】,在打开的对话框中进行相应设置。
-
名称:默认的新变量名称由用于创建它的现有变量的前六个字符、一个下划线和一个顺序编号组成。例如,对于变量 price,新变量的名称将是 price_1。新变量会保留原始变量中定义的任何值标签。
-
方法:替换缺失值的估计方法包括:
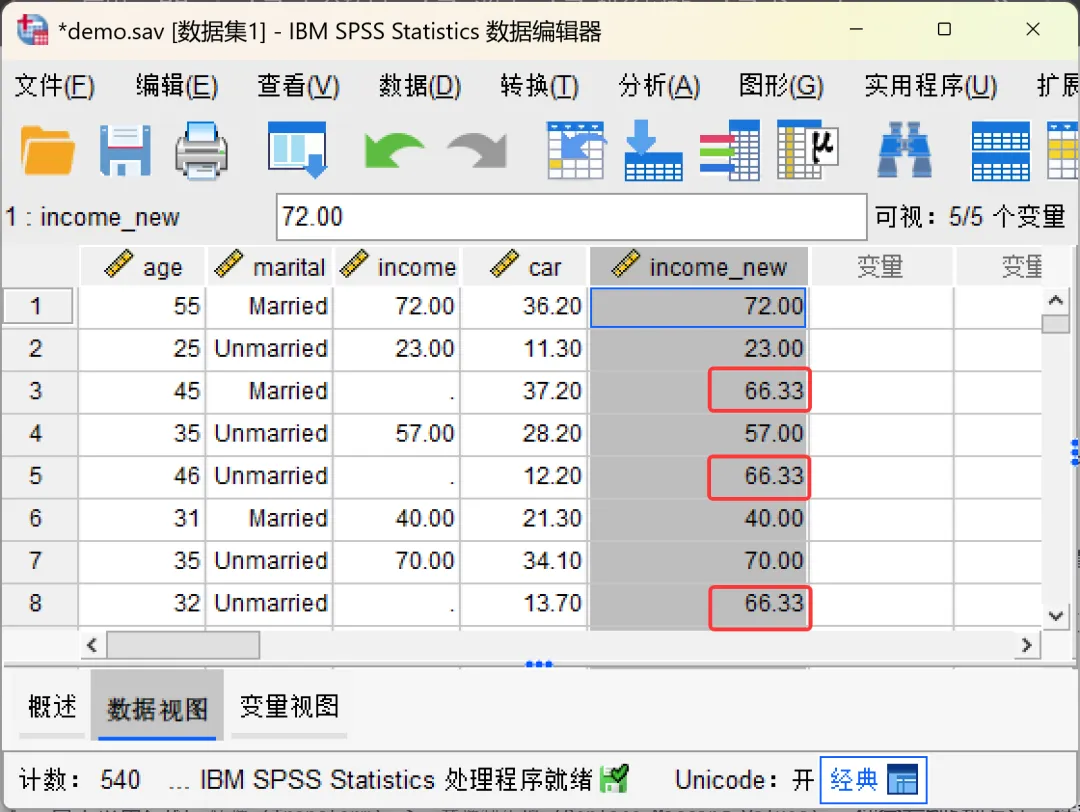
①、序列平均值:用该变量所有有效数据的平均值替换缺失值,适合数据分布均匀、无极端值的场景。
②、临近点的平均值:用缺失值前后相邻的有效数据的均值替换。需设置「临近点的跨度」来指定用于计算的上下方的有效值数量。
③、临近点的中间值:用缺失值前后相邻的有效数据的中位数替换。需设置「临近点的跨度」来指定用于计算的上下方的有效值数量。
④、线性插值:该方法利用缺失值之前最后一个有效值和缺失值之后第一个有效值进行线性插值。如果序列的第一个或最后一个个案为缺失值,则该缺失值不会被替换。
⑤、临近点的线性趋势:用该点处的线性趋势值来替换缺失值。该方法将现有序列对一个按 1 到 n 缩放的索引变量进行回归,然后用预测值来替换缺失值。
本次示例自定义新变量名为「income_new」、选择「序列平均值」,然后点击「变化量」按钮,此时可以看到「新变量」对话框中的信息已更新。